
Abstracts
Résumé
La recherche informatique traite souvent de problèmes qui relèvent des sciences sociales. Cet article propose d’examiner la façon dont ces travaux, souvent très formalisés sur le plan mathématique et algorithmique, reprennent de fait des points de vue standards sur le social. À cette occasion, il est en effet proposé de réduire les choix de points de vue effectués par les sciences sociales à trois distributions du pouvoir d’agir (agency ou agentivité) à des entités différentes : structure, préférences individuelles et réplications (sans ignorer leurs diverses combinaisons). Une discussion approfondie de ces approches dans la tradition sociologique permet de situer la pertinence d’une telle réduction à trois points de vue. Le terrain Twitter constitue un prototype très attractif pour les recherches en informatique qui veulent traiter de processus sociaux : malgré son caractère de haute fréquence qui favoriserait spontanément l’étude du pouvoir d’agir des conversations ou des messages, les trois points de vue (structure, préférences individuelles et réplications) se révèlent être utilisés dans cette littérature, ce qui montre a fortiori la puissance des points de vue que les sciences sociales ont réussi à diffuser chez tous les publics. La présentation d’articles remarquables pour chacune de ces distributions d’agentivité permet d’accéder à la fécondité de ces travaux, trop souvent ignorés des sciences sociales.
Mots-clés :
- Twitter,
- agency,
- sciences sociales,
- structure,
- réplications
Abstract
Computer sciences often address problems that are familiar for social sciences. The article proposes to examine how these works, which are often highly formalized in mathematical and algorithmic terms, take up standard social views. On this occasion, it is proposed to reduce the choices of viewpoints made by the social sciences to three distributions of power of action (agency) to different entities : structure, individual preferences and replication (without ignoring their various combinations). An in-depth discussion of these approaches in the sociological tradition makes it possible to advocate the relevance of such a reduction in three points of view. Twitter is a very attractive prototype field for computer sciences that want to deal with social processes : despite its high-frequency nature, which spontaneously would favor the agency of conversations or messages, the three points of view (structure, individual preferences and replications) are used in this literature, which shows, all the more so, the power of the points of view that the social sciences have succeeded in disseminating to all audiences. The presentation of remarkable articles for each of these agency distributions allows us to display the fruitfulness of these works, too often ignored by the social sciences.
Keywords:
- Twitter,
- agency,
- computer sciences,
- social sciences,
- structure,
- influentials,
- replications,
- networks
Resumen
En informática, con frecuencia la investigación trata acerca de problemas al interior de las ciencias sociales. Este artículo se propone examinar la forma en que estos trabajos, a menudo muy formales en el plano matemático y algorítmico, repiten de hecho los puntos de vista estándar acerca de lo social. En esta ocasión, en efecto se propuso reducir las opciones de los puntos de vista efectuados por las ciencias sociales a tres distribuciones del poder actuar (agency o agentividad) de entidades distintas : estructura, preferencias individuales y replicaciones (sin ignorar sus diversas combinaciones). Una discusión detallada de estos enfoques en la tradición sociológica permite situar la pertinencia de dicha reducción a tres puntos de vista. El terreno del Twitter constituye un prototipo muy atractivo para aquella investigación en informática que busca tratar procesos sociales : a pesar de su carácter de alta frecuencia que favorecería espontáneamente el estudio del poder de actuar de las conversaciones o mensajes, los tres puntos de vista (estructura, preferencias individuales y replicaciones) son utilizados en esta literatura, lo que demuestra, a fortiori, el poder de los puntos de vista que las ciencias sociales han logrado difundir en todos los públicos. La presentación de artículos destacados para cada una de estas distribuciones de agentividad permite acceder a la fecundidad de estos trabajos, muy a menudo ignorados por las ciencias sociales.
Palabras clave:
- Twitter,
- agency,
- ciencias sociales,
- estructura,
- replicaciones
Article body
Depuis les années 2000, les recherches en apprentissage automatique (machine learning) introduisent une nouvelle ère dans les pratiques de quantification. Comme les études de STS (science, technologie et société) l’ont montré (par exemple : Shapin et Schaffer, 1993 ; Latour, 1990), un changement d’instrument apporte avec lui des changements conceptuels, qui concernent les objets traditionnels de la sociologie. Les époques équipées par les instruments sont en fait porteuses de points de vue différents sur le monde social. Les « points de vue » (Vasquez Campos et Gutierrez, 2015) s’entendent ici dans la lignée du « savoir situé » (Haraway, 2007) ou des « perspectives » (Viveiros de Castro, 2009) et plus précisément dans le sens où la connaissance du monde est mise en forme (framed) par les positions du sujet connaissant, et dans notre cas, d’un sujet équipé d’instruments spécifiques selon les époques, dans une approche délibérément nominaliste. Ces points de vue ont souvent été présentés en concurrence alors qu’ils traitent seulement d’entités différentes et de processus que nous dirons de longueurs d’onde variées. Dans cet article, nous nous attachons aux approches adoptées dans les études de Twitter réalisées par des chercheurs en informatique. Nous soulignons à quel point ces études véhiculent, parfois sans l’expliciter, des concepts du social et, ce faisant, endossent nécessairement des « points de vue » sur le monde social, certains traditionnels, d’autres plus nouveaux en raison des potentiels du numérique. Les choix conceptuels faits en informatique ressemblent alors étrangement à ceux que font les chercheurs en sciences sociales. Ils consistent en réalité à distribuer du pouvoir d’agir (des agencies) entre trois types d’entités ou d’actants : la société et ses effets de structure ; les individus et les effets de leurs préférences ; et, phénomène plus récent et amplifié par le numérique, les réplications et leurs effets de propagation.
D’une généalogie à une différence de points de vue
Nous avons développé ailleurs (Boullier, 2015a, b) une approche historique des époques de quantification, inspirée des travaux de Desrosières (1993) et donnant une place spécifique à l’époque numérique que nous avons nommée « époque des traces »[1]. Alors que les propriétés classiques de l’exhaustivité et de la représentativité ne peuvent plus s’appliquer à des univers dynamiques tels que les réseaux sociaux et le web, le big data en a produit des ersatz, comme le volume et la variété. Une autre qualité a cependant émergé, la vélocité (qui constitue ainsi les 3V – volume, vitesse et variété – du big data), qui n’avait jusqu’ici pas d’équivalent dans les sciences sociales, notamment dans la quantification du social. Nous avons proposé d’en faire un critère de scientificité, encore à construire, celui de traçabilité. Cette notion permet de rendre compte d’entités nouvelles que sont les « réplications », ces contenus qui circulent et qui jusqu’ici n’avaient guère de place dans la société (calculée grâce à l’usage de l’exhaustivité des registres) et dans l’opinion (calculée grâce à la construction d’une représentativité par les sondages) (Blondiaux, 1998).
Cet inventaire historique que nous avons formulé en termes de générations, dans la mesure où des époques techniques et méthodiques précises lui correspondent, nous apparaît rendre compte d’une diversité d’approches du social qui ont en fait toujours coexisté. La division des disciplines (notamment entre sociologie, économie et psychologie) ainsi que l’absence de méthodes empiriques fiables dans certaines approches expliquent l’ignorance ou la prétention hégémonique de certaines d’entre elles. Le seul « ancêtre » porteur de l’approche des traces et des propagations, Gabriel Tarde, pourtant quantitativiste qualifié, n’a jamais bénéficié d’une reconnaissance académique comparable à celle de Durkheim ou de Weber. Le numérique ne fait pas émerger ces entités inédites ; il se contente de les rendre visibles, calculables, alors qu’elles faisaient déjà partie de l’expérience ordinaire (comme les conversations et les rumeurs) et avaient été conceptualisées par Tarde (1897) dans sa théorie de l’imitation (qui comporte aussi, rappelons-le, les notions d’opposition et d’invention). Il est donc préférable de proposer un tableau synchronique des approches concernées : chacune d’elles propose un point de vue sur le monde, sachant qu’il reste impossible de saisir tous les points de vue à la fois. Chacun d’entre eux dépend entièrement des instruments qu’il mobilise, qui cadrent le monde et mettent en perspective sa saisie en même temps (Latour, 1990). Mais ces points de vue se focalisent sur des entités particulières qui ont, dans chaque cas, un statut privilégié qu’il nous faudra caractériser. La focalisation sur les « structures », associée à l’exhaustivité des recensements, diffère nettement de la focalisation sur les « préférences individuelles » associée à la représentativité des sondages mobilisés dans le marketing, dans les études d’opinion publique mais aussi dans toutes les grandes enquêtes d’attitude utilisées par les économistes, par exemple sur le sentiment de bonheur ou de confiance en l’avenir, etc. (cf. Algan et al., 2016). Ces deux entités (structure sociale et préférences individuelles agrégées sous le nom de marché) sont elles-mêmes bien différentes des entités circulantes qui peuvent être des messages, des biens ou des êtres qui ont leurs propriétés spécifiques analysées parfois en sémiotique mais traitées avant tout dans la mémétique.
Tableau des trois points de vue sur le social
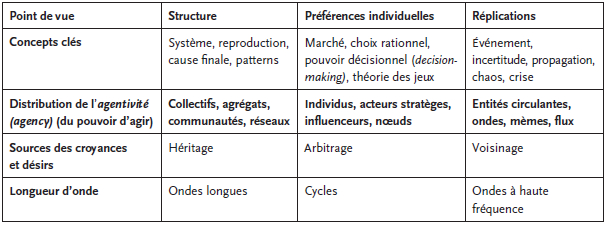
Prenons des exemples classiques de la littérature sociologique pour mieux comprendre la portée de cette proposition. L’opposition entre Durkheim et Tarde prend son sens dans ce cadre. Lorsque Durkheim étudie le suicide, il n’entre pas dans une analyse du choix par des individus quand bien même ses catégories peuvent apparaître de portée psychologique. Les suicides égoïstes, altruistes ou anomiques dépendent tous de la pression qu’exerce la société, en tant que structure sociale, sur ces individus, selon des intensités diverses (le degré d’intégration sociale). Les méthodes statistiques mobilisées par Durkheim ont été considérées par la communauté scientifique comme suffisantes pour faire apparaître ces effets de structure, sur la longue durée. Elles ne traitent pas des processus d’influence ni des croyances ni des valeurs, par exemple, qui auraient pu expliquer les choix et les préférences de ces individus pour le suicide, à la mode de Weber. Ces méthodes ne permettent pas non plus de capter des processus de contagion rapide, à haute fréquence et beaucoup moins « choisis », comme on peut l’observer dans certaines situations de propagation du suicide, en public, en entreprise ou dans des sociétés entières comme en Micronésie dans les années 1970 (Rubinstein, 1983). Pour Durkheim, « l’exemple est la cause occasionnelle qui fait éclater l’impulsion ; mais ce n’est pas lui qui la crée et, si elle n’existait pas, il serait inoffensif » (Durkheim, 1897 : 135). Tarde lui réplique que « tous les phénomènes sociaux, toutes les influences sociales, comme les influences physiques et physiologiques, consistent en répétition d’actes semblables, répétition-ondulation ou répétition-hérédité » (Tarde, 1897 : 41). On comprend que l’affrontement soit irréductible, alors qu’en fait, ils étudient chacun différents moments du social (à haute fréquence et « en train de se faire », ou de longue durée et « déjà fait ») avec des points de vue différents sur des entités agissantes bien spécifiques.
Plus radicale encore est l’opposition entre Malinowski et Mauss sur la question des entités que les sociétés primitives font exister. Dans son essai sur le don, Mauss (1950) reprend notamment les travaux de Malinowski sur la kula (1922), les échanges rituels entre tribus dans les îles Trobriand. Malinowski y voit une forme d’obligation morale permettant de maintenir la paix entre les différents groupes et de générer des échanges à caractère économique (marché et stratégies). Sahlins (1976) a lui construit un modèle historique des types de réciprocité, pour souligner les effets de structure. Mauss, de son côté, s’est focalisé sur le hau, c’est-à-dire sur les attributs de l’entité circulante, à laquelle il confère un pouvoir d’obligation en raison de « l’esprit de la chose donnée » toujours présent dans les échanges. Lévi-Strauss (1950) considérera que « l’ethnologue se laisse mystifier par l’indigène en adoptant cette théorie du hau » alors que lui-même fondait pourtant toute sa théorie sur les échanges (de biens, de femmes et de signes) mais à la condition de dégager la structure de ces échanges et non un quelconque pouvoir des attributs ou entités échangés.
La place attribuée aux non-humains par la théorie de l’acteur-réseau (ANT) produisit elle aussi des réactions de rejet identiques à ses débuts (Callon, 1986). L’opposition semblait relever d’un enjeu ontologique, d’un refus de l’écrasement des distinctions humain/nature ou humain/artefact. Mais la question clé était en fait méthodologique. Là où l’ANT restituait une forme d’agentivité (agency) aux entités circulantes, puisqu’elles pouvaient contribuer à la constitution d’un réseau, voire émerger en tant qu’acteur-réseau, les approches structurelles se concentraient sur les effets de position, de hiérarchie, de reproduction, et de domination qui enregistrent de fait l’asymétrie entre humains et objets. Cela n’invalidait pas pour autant l’approche par les structures et par l’héritage des positions et des attributs, malgré la tendance des auteurs de l’ANT à la disqualifier en montrant le caractère artificiellement construit de ce « dispatcher » (Latour, 2006).
L’analyse structurale de réseaux plus récente dans la tradition sociologique, et plus formalisée (Mercklé (2004), Degenne et Forsé (1994), Burt (1992), Granovetter (1995), Grossetti (2011), met aussi en oeuvre la diversité de ces points de vue qui orientent l’attention sur certaines entités. Ainsi, la focalisation sur des réseaux de petite taille a souvent été justifiée par la nécessité de reconstituer la totalité du réseau pour effectuer certains calculs comme sur la densité dans les travaux de diffusion d’innovations ou d’analyse des organisations notamment. Mais cette totalité peut être prise en compte dès l’apparition d’une triade, le plus petit réseau concevable (Mercklé, 2004). Cette recherche de la totalité n’a de sens que parce que ce sont des effets de structure qui doivent être calculés, lesquels auront un impact sur les échanges au sein du réseau (analyse dite structurale). Les méthodes de topologie des réseaux et leur mathématisation grâce aux théories des graphes renforcent encore cette focalisation sur la structure puisqu’il est possible de repérer des clusters, d’identifier des densités et des connexités, des trous structuraux (Burt, 1992), des ponts (bridges) ou des gardiens (gatekeepers), ensemble de propriétés qui relèvent des positions dans la structure globale du réseau.
D’autres approches privilégient le rôle des noeuds du réseau, notamment en traitant de « réseaux personnels » et d’étoiles de degrés divers (Barnes, 1972). Les noeuds renvoient alors à des individus dont on peut mesurer les propriétés grâce à leurs scores de centralité, mais dont on peut aussi identifier le poids de l’influence sur les comportements des autres membres du réseau. Comme le dit P. Mercklé, « les réseaux personnels peuvent présenter un véritable intérêt en raison justement de ce subjectivisme : dans une perspective compréhensive, quand il s’agit d’analyser l’influence des proches sur les opinions de l’acteur, et de constituer un modèle décisionnel (...) » (2004 : 35). Leur statut d’influenceur indique qu’ils sont eux-mêmes des sélecteurs, des filtres. Cette propriété avait été déjà relevée par Katz et Lazarsfeld (1955) à propos des « leaders d’opinion » dont les préférences leur font choisir de transférer tel goût, telle opinion ou de filtrer telle autre. Il est alors possible de mesurer leur effet propre sur tout le réseau. S’intéresser aux effets de structure et aux poids des influenceurs n’est pas contradictoire, mais ne peut, d’une part, être réalisé avec les mêmes méthodes et surtout n’attribue pas, d’autre part, le pouvoir d’agir aux mêmes entités. Pour Degenne et Forsé, il faut même expliquer l’émergence des structures des réseaux par les choix individuels : « établir une relation, c’est faire un choix » (1994 : 14). Les deux approches peuvent s’emboîter dans un débat très classique entre approche individualiste et approche structurale. On cherchera toujours à reconstituer le tout et à traiter les entités (structures et préférences ou choix) comme des causes à combiner de façon généalogique, et non comme des points de vue permanents et équivalents. Lazega et al. (2007) ont proposé une méthode élégante, qu’ils qualifient de néo-structurale, pour combiner ces deux approches. Ils associent l’étude de la structure de réseaux complets avec une approche par niveaux (inter-organisationnel et inter-individuel) qui rend plus dynamiques les positions des acteurs et des organisations, notamment par effet de la prise en compte des préférences des acteurs (sous forme de conseils personnels, entités circulantes dont les attributs ne sont cependant pas pris en compte).
Cette approche par niveaux prolonge les analyses de Granovetter (2008) qui pointait les différences de descriptions selon qu’on adopte une vision macro (relations entre groupes) ou micro (au sein d’un petit groupe). Selon nous, Granovetter (1995) constatait en fait l’existence de points de vue différents, notamment lorsqu’il critiquait le modèle Davis-Holland-Leinhardt (DHL), qui affirme que « les choix interpersonnels sont en général transitifs ». Granovetter a précisément montré que sa théorie des liens faibles admet l’existence d’une intransitivité dans ces « gros bouts informes de la structure sociale » (2008 : 71), qui deviennent pourtant des ressources utiles pour trouver un travail par exemple. « Le modèle DHL est construit à partir du concept du “choix”, tandis que nous avons bâti le nôtre sur la notion de liens » (2008 : 70). Il ne s’agit donc plus seulement d’une question d’échelle, même si en se focalisant sur la structure de liens, on privilégie spontanément une observation à plus grande échelle. Ces choix de méthodes renvoient en réalité à une distribution du pouvoir d’agir que Granovetter a précisé auparavant dans le même article : « Certaines […] études ont mis en évidence les moyens par lesquels le réseau d’un individu modèle et contraint son comportement (Bott, 1957 ; Mayer, 1961 ; Frankenberg, 1965), d’autres, à l’inverse, ont mis l’accent sur les façons dont les individus peuvent manipuler ces réseaux afin d’atteindre des buts particuliers (Mayer, 1966 ; Boissevain, 1968 ; Kapferer, 1969) » (Granovetter, 2008 : 59-60).
Une troisième entité — les contenus, les messages qui sont échangés — pourrait pourtant être analysée par les approches des réseaux, mais apparaît très rarement dans cette littérature. Ainsi, Katz et Lazarsfeld, bien que préoccupés à l’origine par les statuts sociaux des influenceurs et leaders d’opinion, observaient finalement que l’intérêt subjectif, le goût, étaient déterminants. Ils indiquaient également que les leaders d’opinion n’étaient jamais des leaders dans tous les domaines (les achats, la mode, la politique et le cinéma étaient pris en compte dans leur étude) et qu’il n’existait pas de « leader généraliste ». Cette distinction en sujets (topics) ou en problèmes (issues) est devenue classique mais ses conséquences n’ont pas toujours été anticipées. Elle conduit en effet à dire que les propriétés des contenus qui sont échangés affectent le réseau, les influenceurs et leurs statuts, et qu’il est donc important de rendre compte de leur part d’agentivité. Il est même alors nécessaire d’entrer dans une description plus fine des attributs des entités circulantes dans les conversations, dans les avis ou dans tout autre échange. E. Rogers (1963) le faisait à propos des innovations et de leurs attributs (features). Il adoptait certes la courbe en S, typique de tous les phénomènes de transition de phases et qui peut servir de formalisme élémentaire pour toutes les propagations, mais il entrait dans le détail des attributs des innovations (Boullier, 1989) pour comprendre de façon comparative la différence entre les innovations dans leurs capacités de propagation. Il distinguait ainsi entre les avantages perçus (et non intrinsèques), la compatibilité entre les techniques et les valeurs, l’expérimentation sur une échelle réduite, les clusters, la visibilité. Certains de ces attributs font clairement appel à des préférences individuelles, mais d’autres sont seulement des propriétés caractéristiques de dynamiques de propagation comme la visibilité ou l’expérimentation sur une échelle réduite.
La physique sociale de Pentland (2014) mobilise aussi l’analyse sociologique des réseaux. Elle parvient à simplifier les situations sociales en adoptant seulement deux des points de vue classiques en sciences sociales. Deux facteurs sont identifiés comme prédictifs (plus qu’explicatifs) de la dynamique des organisations : « l’engagement » qui relève de la pression sociale ou de l’apprentissage social (social learning) (extrait à partir d’indicateurs de connexion interne aux groupes sociaux) et « l’exploration » qui relève de l’initiative individuelle (telle celle d’un gardien (gatekeeper) ou d’un pont (bridge)dans les analyses de réseaux sociaux comme celle de Granovetter (1973) sur les liens faibles), cadre d’analyse préféré de Pentland pour cette approche de l’exploration. Lorsque Pentland prétend étudier les flux d’idées, on pourrait s’attendre à un traitement des entités qui circulent, à une analyse des contenus des échanges, au suivi d’innovations spécifiques et à leurs transformations. En fait, « l’estimation chiffrée du flux d’idées correspond à la proportion d’utilisateurs qui sont susceptibles d’adopter une nouvelle idée introduite dans le réseau social. Ce flux d’idées prend en compte tous les éléments d’un modèle d’influence : la structure du réseau, la force de l’influence sociale et la susceptibilité des individus aux nouvelles idées » (2014 : 83-84). Cet exemple est assez frappant par sa simplification qui permet le calcul. Toute la sociologie est ainsi résumée à l’agentivité des structures sociales (les réseaux) et à celles des préférences individuelles (ici pour les nouvelles idées). Rien n’est dit sur les idées en question ni sur leurs patterns de propagation. Pentland et ses équipes mobilisent des capteurs ad hoc pour collecter leurs données auprès des collectifs. Échappant aux contraintes des plates-formes pour cette collecte, les messages ne semblent pourtant pas faire partie des entités recueillies, si ce n’est sous la forme des métadonnées qui les entourent. On peut comprendre ce choix car il est nettement plus compliqué de suivre les transformations linguistiques d’un mème par exemple, entité culturelle élémentaire chez Dawkins (1976), devenue fameuse sur internet (voir les sites 9gag ou meme generator), que de dénombrer les contacts entre deux membres d’une organisation indépendamment de toute autre information sur la situation.
Quels enseignements tirer de ce parcours (auquel il eût fallu ajouter la scientométrie pour être complet) ? De Mauss (et son hau) à l’ANT (et ses non-humains), émergent les cadres conceptuels qui permettent de penser l’agentivité d’autres entités que les structures sociales ou les préférences individuelles. Mais les méthodes des analyses sociales de réseaux, c’est-à-dire les plus susceptibles d’exploiter les ressources nouvelles du numérique, ont toujours privilégié le pouvoir d’agir des structures (de réseaux) et des préférences individuelles (les noeuds, les influenceurs). Il nous faut donc éviter de considérer les réseaux comme le mot clé de toute sociologie numérique, pour développer une théorie des réplications et des entités circulantes, comme nous allons le voir à propos des études informatiques de Twitter.
Quand les chercheurs en informatique font des sciences sociales : le cas des études de Twitter
Le tableau que nous venons de dresser des trois points de vue mobilisés par différents courants des sciences sociales peut en fait s’étendre assez aisément aux études en informatique, aux « computational social sciences » (Lazer et al., 2009, Alvarez, 2016), en particulier aux études de Twitter qui offrent un potentiel important pour une perspective centrée sur les réplications ou les propagations. Nous voulons cependant montrer qu’en fait, sur ce terrain nouveau et « nativement numérique » (Rogers, 2013), les choix de points de vue, loin de se focaliser sur une approche en termes de réplications, opèrent aussi de façon systématique, avec la même diversité. Étudier Twitter, nous le verrons, c’est étudier la structure du réseau, les rôles des influenceurs et la sensibilité des noeuds aux influences diverses et, plus rarement, suivre les cascades et les rafales (bursts) qui sont générées par certains tweets, qu’on peut alors caractériser comme des mèmes.
Sur ce terrain pourtant favorable aux approches des réplications, ce sont paradoxalement encore les modèles conceptuels classiques du social qui dominent (structures et préférences individuelles). Cela s’explique assez bien puisque les entités étudiées par les sciences sociales et la distribution classique d’agentivité sont désormais passées dans le sens commun, donc aussi chez les chercheurs en informatique. Cela ne les invalide pas à ce titre, cela donne seulement la mesure de l’effort à faire pour adopter, même sur ces nouveaux terrains, un point de vue émergentiste[2] qui viendrait compléter les précédents. Twitter constitue de ce point de vue un terrain d’expérimentation à ciel ouvert, une « machine à réplications » construite à dessein, la drosophile de notre théorie des réplications en quelque sorte, quand bien même nous limitons la portée des phénomènes étudiés à cette plate-forme, avec une prudence encore plus radicale que celle des méthodes numériques (digital methods) de R. Rogers (2013) et N. Marres (2017). L’autre terrain idéalement construit pour les études de réplications est constitué par la propagation des mèmes. Nous y ferons référence puisque nous développons notre propre memetracker. Si Twitter réduit les messages à une propagation, les mèmes les réduisent à une réplication. Et lorsque Twitter en vient à propager des mèmes, nous obtenons une machine expérimentale totale, combinant une face « trajectoire » pour la plate-forme Twitter avec une face « particule » pour les mèmes. Nous réduisons donc délibérément Twitter et les mèmes à ces fonctions expérimentales, pour éviter toute interprétation abusive sur leurs liens avec un supposé « vrai » monde social.
Nous prendrons pour commencer un certain nombre d’articles assez diffusés, souvent bien informés sur Twitter, articles tous issus des sciences sociales (partie 2.1). Nous irons plus loin en observant comment la communauté des chercheurs en informatique publiant sur ArXiv (l’archive qui permet aux chercheurs de déposer leurs articles avant leur publication dans les revues scientifiques) est spontanément prête à adopter l’un de ces trois points de vue (partie 2.2), et cela de façon quasi exclusive (certaines combinaisons sont cependant observables). Pour ce faire, nous avons collecté tous les articles (N = 1013) traitant de Twitter publiés en 2015 et 2016 dans la catégorie « computer sciences » sur ArXiv[3].
La distribution d’agency dans quelques articles réputés dans les études de Twitter
Deux articles de l’ouvrage Twitter and Society présentent des méthodologies différenciées pour traiter trois dimensions qui se trouvent être assez voisines de nos trois points de vue. Bruns et Moe (2014) distinguent ainsi trois couches de communication sur Twitter : le niveau micro de la communication interpersonnelle, le niveau méso des réseaux « follower-followee », et le niveau macro des échanges basés sur les hashtags. La qualification en échelles d’observation est assez étonnante mais elle leur permet de distinguer des effets de structure au niveau méso, des effets d’influence au niveau micro, celui des noeuds, et des effets mémétiques sur des thèmes propres au niveau macro. Ce niveau des thèmes (topics) est considéré comme la pointe de l’iceberg déjà largement étudiée. Pourtant, de notre point de vue, c’est confondre l’entrée par les thèmes et la distribution d’agentivité, car la plupart des articles traitant des thèmes identifiés par les hashtags (ou étendus aux termes des tweets eux-mêmes) s’empressent d’expliquer les « clusters » et les processus de propagation par des propriétés structurelles, voire de préférences des influenceurs. Le plaidoyer des auteurs contre « l’étude d’une seule couche ou d’un seul médium (Twitter par exemple !) qui risque de faire perdre une importante dimension de la dynamique communicationnelle » (2014 : 27) est somme toute assez fréquent mais voué à l’échec dès lors que les points de vue adoptés et la distribution d’agentivité ne sont pas clarifiés : le fantasme du « tout » n’a guère de chances de servir de guide méthodologique à l’époque des réseaux distribués et dynamiques.
Toujours dans ce même ouvrage (Twitter and Society), Maireder et Auserhofer (2014) analysent les discours politiques sur Twitter à partir de situations de controverses en Autriche et proposent trois perspectives de mises en réseaux très pertinentes pour notre propos : « 1/ la mise en réseau des thèmes (topics), en termes d’inclusion d’information, d’interprétation et de points de vue dans un débat, 2/ la mise en réseau d’objets médiatiques, propulsée par les pratiques d’hyperliens et produisant ainsi une reconfiguration de la webosphère, 3/ la mise en réseau des acteurs, appuyée sur les pratiques de @mention, produisant de nouveaux modèles d’interaction entre les acteurs politiques et les citoyens qui donnent une nouvelle forme à la structure de participation dans l’espace public » (2014 : 306). Les acteurs attachés par les mentions relèvent clairement de l’analyse par structure ; l’analyse des hyperliens permet de voir le poids et l’influence de certains médias (traditionnels ou blogues par exemple), ce qui décrit des préférences pour certains médias ; les flux analysés selon les cas de controverses (trois affaires ont été comparées) font entrer dans le domaine des réplications.
Au-delà de ces tableaux génériques, reprenons quelques articles significatifs présentés selon la distribution d’agentivité spécifique qu’ils adoptent avant de traiter les articles issus de notre corpus ArXiv.
Quand la structure agit
Parmi les études de Twitter, Lin et al. (2014) tentent de rendre compte des « rising tides » (comment l’attention collective se concentre sur certains événements spécifiques) dans une vision qui pourrait se rapprocher des réplications. Mais les auteurs retrouvent finalement la répartition inégale de la renommée pour expliquer le rôle spécifique de certaines « étoiles » sur Twitter : « Elites also appear to guard their status, indicated by their restraint in retweeting others at times when both rookies and typicals increase retweeting behaviour, suggesting a reluctance to “anoint” others as worthy of attention through retweeting their content[4]. » Ils se réfèrent certes à une forme de flux à deux niveaux (two-step flow), mais simplement pour confirmer la structure des liens sociaux et non pour suivre une influence réelle ou une propagation d’opinion. Lorsque Weng et al. (2010) essayent de détecter les utilisateurs influents, ils expliquent cette influence par l’homophilie, une caractéristique structurelle basée sur la réciprocité au sein du réseau et non sur une capacité propre aux individus. Même l’influence est ainsi réduite à un effet de structure et non de préférences.
Les conclusions de Weng sont explicitement contestées par Cha et al. (2010) et plus tard par Bakshy (2011, voir ci-dessous). Cha et al. critiquent l’idée fausse dite du « million de followers » (comme Avnit l’a fait, en 2009) en démontrant que le calcul de centralité (in-degree) (le nombre de followers dans le graphe de Twitter) « est peu révélateur de l’influence d’un utilisateur ». Cela permet de remettre en cause les équivalences fréquemment annoncées entre audience et influence, entre effet de structure et influence véritable. En modifiant le type de métriques adopté (retweets et mentions au lieu du degré), ils montrent que les médias de masse (pour les retweets) et les célébrités (pour les mentions) sont les influenceurs véritables. Cela leur permet de proposer des stratégies de marketing ciblant ces personnalités influentes (Watts et Dodds, 2007). À trop prendre à la lettre les effets de structure révélés par leur méthode, Cha et al. semblent paradoxalement s’interdire de comprendre l’influence. Les problèmes posés nécessitent en effet des choix de méthodes et de techniques adaptées, sans quoi on n’enregistre que la reproduction des structures (les médias et la presse et les magasines people sont les plus suivis, donc ils seraient les plus influents).
L’influence et les préférences au centre
L’étude réalisée par Bakshy et al. (2011), par exemple, vise à calculer la répartition de l’influence parmi tous les utilisateurs de Twitter avec ce slogan accrocheur : « tout le monde est un influenceur ». Leurs résultats sont cohérents avec de nombreuses autres études : l’influence ne peut être détectée que dans des domaines spécifiques et non en général. Les auteurs discutent en détail de la valeur respective de l’utilisation des retweets ou des reposts comme indicateurs car ils essaient d’éviter une réduction de la propagation à un effet de structure du réseau. Leur article étudie l’influence individuelle en général, puis le rôle du contenu. Si l’analyse de Bakshy et al. fait penser à une approche en termes de réplications, elle ne trouve cependant aucune caractéristique de contenu qui pourrait expliquer les profils de propagation. Prudemment, ils relativisent le poids des influenceurs en conseillant aux spécialistes du marketing « plutôt que d’essayer d’identifier des individus exceptionnels, (…) d’adopter plutôt des stratégies de style de portefeuille en ciblant de nombreux influenceurs potentiels en même temps et de s’intéresser plutôt à la performance moyenne » (Bakshy et al. 2011).
Les réplications : quand les entités circulantes agissent
L’article de Leskovec et al. (2009), fondateur sur les questions de mémétique, repose sur la conception d’un memetracker qui suit les cascades générées dans les médias (sociaux et traditionnels) par des citations lors de la campagne d’Obama de 2008. Leur définition des mèmes est très ouverte par rapport à celles des fondateurs de la mémétique (Dawkins, 1976 ; Blackmore, 1999). Leskovec et al. ont cependant réussi à construire des graphes de phrases qui représentent les relations (arêtes) entre différentes versions de la même citation réparties chronologiquement, même si leurs caractéristiques linguistiques sont différentes. Ils se réfèrent de toute évidence à un modèle d’imitation, mais leurs hypothèses théoriques conduisent à dégager un « attachement préférentiel » à des sources qui sélectionnent le contenu pour le propager. Cela ressemble de fait à un modèle davantage centré sur les préférences, même si les auteurs mentionnent l’attractivité propre aux contenus. La même limite peut être trouvée dans les articles qui tentent d’évaluer la façon dont la concurrence entre mèmes fonctionne (Weng et al., 2012) en l’expliquant uniquement par les structures comparées des réseaux et en refusant explicitement de prendre en compte l’attractivité intrinsèque d’un mème.
Une approche plus ouverte à l’émergence et basée sur la différence entre événements a été utilisée par Lehman et al. (2012). Un événement sportif, une fusillade dans une école, la sortie d’un film à gros budget et un discours politique présentent des modèles de propagation très différents sur Twitter.
Figure 1
Modèles de propagation des tweets en fonction de quatre événements

Légende : Lehman et al., 2012. Modèles de propagation contrastés à partir de quatre hashtags se référant à des événements très différents : le master de golf, une fusillade dans une école en Allemagne, la sortie d’un film, un discours du président Obama. En haut l’activité quotidienne du réseau, au milieu l’activité des comptes, en bas le nuage de mots des termes des tweets.
Cependant, les patterns détectés font référence à des thèmes (topics), qui sont des événements du « monde IRL (in real life) », et non aux caractéristiques sémiotiques des hashtags ou des tweets qui en rendent compte.
Pour terminer ce premier examen d’articles significatifs, l’article de Chen et al. (2016), « Why do cascades recur ? », souligne plusieurs enjeux de cette étude des réplications. Cet article est écrit par les auteurs de référence sur le « memetracker » que sont Kleinberg et Leskovec, ici associés à Lara Adamic, chercheure éminente chez Facebook. Les volumes de données collectées sont sans commune mesure avec ce qu’un chercheur en sciences sociales pourrait traiter au cours de sa vie : 39 M de comptes suivis, 5 MM de « Partage », pour 105 M d’images de mèmes. Ce volume permet sans nul doute de tester des modèles pour des problèmes de haute complexité, en l’occurrence très formels mais aussi très révélateurs d’une dynamique collective… à condition de les faire parler ! Les métriques testées dans ce cas se focalisent avant tout sur les formes de la propagation. L’un des résultats majeurs consiste à montrer comment une émergence très vive (volume et rythme) et très diverse (plusieurs sources, très rapidement) au départ peut tendre à assécher le vivier potentiel des futures récurrences. La simplification du corpus testé (voir l’exemple « How to be skinny » ci-dessous) et des questions ainsi que le volume disponible tendent de fait à privilégier la viralité et non la mémétique qui supposerait des variations.
Figure 2
Récurrence du mème « how to be skinny » sur Facebook
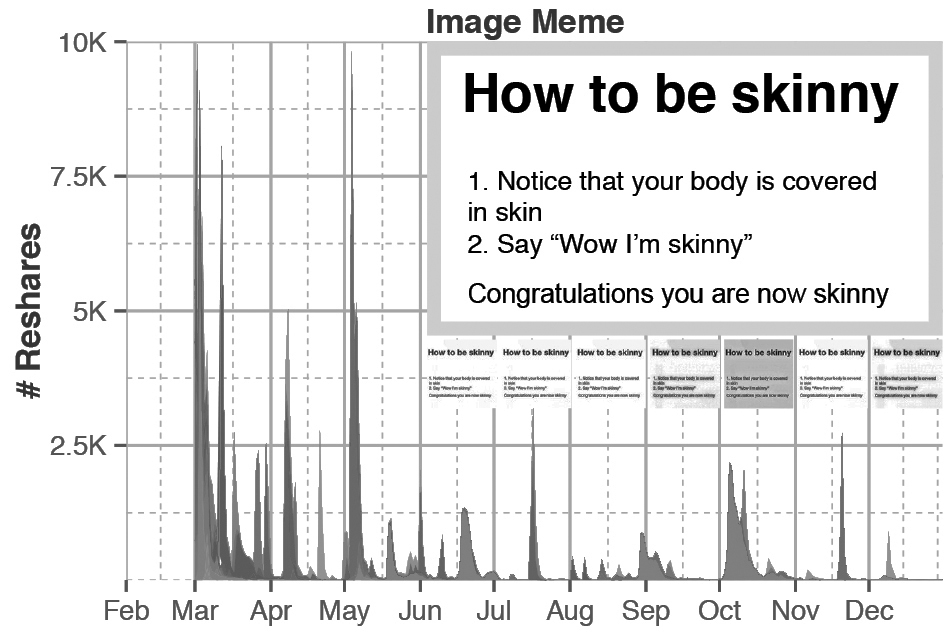
Légende : Chen et al., 2016. Récurrence d’un mème dans le temps sur Facebook. Les couleurs se réfèrent à la source du mème qui se propage car plusieurs sources peuvent contribuer. En incrustation, le mème étudié (How to be skinny) tel qu’il est diffusé sous forme d’image.
L’épidémiologie devient la métaphore principale : tout est question de contagion. Le formalisme des modèles tend à privilégier la propagation per se sans réellement distribuer d’agentivité aux entités circulantes, en l’occurrence les mèmes. Or, cette question est essentielle à traiter pour la construction d’une théorie des réplications. Il nous paraît nécessaire de définir les entités élémentaires agissantes de façon plus fine en empruntant plutôt à Limor Shifman (2014) lorsqu’elle traite des mèmes. De façon qualitative, elle identifie cinq traits facteurs de propagation : « humor, simplicity, whimsical content, emotion, participation ». Voilà un point de départ intéressant pour entrer dans ce qui constitue le pouvoir d’agir de ces mèmes, et qui suppose une approche sémiotique très fine. Nous avons procédé de la même façon pour analyser le « punctum » d’une image (le détail qui attire), à la mode de Barthes (Boullier et Crépel, 2013), punctum qui permet des connexions avec d’autres images sur Flickr qui présentent pourtant un « studium » totalement différent (un thème, un sujet, une intention). Cependant, le risque existe, dans cette lignée mémétique, de se focaliser abusivement sur les entités au point de leur définir des propriétés intrinsèques et donc des positions dans une sorte de structure des possibles sémiotiques alors que la trajectoire, et non la position de la particule, est essentielle dans cette approche.
Le corpus ArXiv des articles sur Twitter et leur distribution d’agentivité
Nous présentons ici trois articles idéal-typiques de chacun des points de vue en y associant la description des thèmes traités par les autres articles significatifs du corpus.
Tout le pouvoir aux structures !
Nous avons sélectionné un article[5] (Omodei et al., 2015) à la fois classique et original dans sa façon de mobiliser une approche par les structures pour analyser les échanges sur Twitter. Il est classique, car il exploite la topologie des liens entre comptes pour en faire un calcul de centralité (in-degree) le plus fréquemment utilisé. Il est original, car il prend en compte les types d’interaction sur Twitter (mention, réponse, retweet) pour montrer comment ils génèrent des structures de réseaux variées. Il utilise pour cela des réseaux multicouches pour valider la différence de topologie entre les comptes selon le type d’interaction. L’expression utilisée « i (compte) retweet j (compte) » est significative de la focalisation sur les noeuds et sur leurs relations alors qu’une expression « i (compte) retweet z (nom du tweet) » aurait montré le choix d’une entrée par les contenus susceptible d’ouvrir des pistes vers les réplications. Montrer qu’il existe des réseaux différents selon les types d’interaction est en soi un résultat très intéressant pour toutes les études structurales de Twitter qui ont tendance à se focaliser soit sur les relations de followers soit sur les retweets uniquement. Plus encore, le fait de comparer des événements différents (Festival de Cannes en 2013, découverte du boson de Higgs en 2012, 50e anniversaire du discours de Martin Luther King en 2013, Championnat du monde d’athlétisme à Moscou en 2013, marche du climat à New York en 2013, visite d’Obama en Israël en 2013) introduit à la prise en compte de contenus, de thèmes différents. Les auteurs considèrent que les patterns sont identiques entre les événements, en grande partie parce que la comparaison porte sur la structure des interactions selon les événements, alors qu’une approche entrant dans le détail des propriétés des tweets et centrée sur la propagation aurait certainement fourni d’autres résultats. On peut cependant retrouver des tentatives de connecter structures du réseau et structures des contenus dans d’autres articles[6].
Un article sur le thème des événements et de la structure mérite d’être mentionné : il est écrit par Myers, Leskovec et al. (2014), (publié depuis), qui mobilisent leur expertise en analyses des cascades et des surgissements (bursts), qui relèvent plutôt de la dynamique de propagation, pour analyser comment ces mouvements peuvent affecter la structure même du réseau (attirer des followers ou au contraire en faire fuir). Ce retournement vers la structure qui devient elle-même agie par d’autres entités constitue un cas très intéressant d’interactions entre points de vue, entre agencies, qui reprend en fait des discussions fort anciennes en sociologie (Tarde demandant à Durkheim d’expliquer comment sa « société » et sa force d’imposition ont pu émerger).
Dans le reste du corpus, parmi ces approches en termes de structure, l’analyse des propriétés topologiques du réseau, des communautés qui sont censées apparaître et faire référence à des groupes sociaux hors ligne ou socialement significatifs, fait partie des plus courantes. La détection de ces communautés est un classique dans tout traitement d’un set de données, puisque la clustérisation est une des tâches de base pour organiser des ensembles dont on testera la pertinence des frontières[7].
Comme dans beaucoup d’analyses sociales de réseaux, la question de l’homophilie est posée, dans un contexte où il reste pourtant difficile d’obtenir des informations à caractère sociodémographique. Cela n’empêche pas les chercheurs de tenter d’approximer ces statuts sociaux et de trouver des attributs détectables sur le réseau pour pouvoir définir cette homophilie ou encore pour étudier un capital social[8].
Les métadonnées fournies par la géolocalisation sont en outre aisément disponibles et permettent de produire des inférences sur les propriétés sociales des comptes qui communiquent sur Twitter. Cette approximation, très souvent grossière, semble suffire pour la plupart des problèmes traités, alors que le souci de complétude des sciences sociales devient parfois contre-productif selon les types de problèmes à traiter. Les chercheurs en informatique sont de ce point de vue beaucoup plus pragmatiques et peuvent dès lors traiter rapidement beaucoup de problèmes simples en se contentant d’approximations astucieuses[9].
Les influenceurs et leurs préférences aux commandes
Les thématiques autour des préférences se traduisent en fait le plus souvent par une détection, une étude et une mesure du rôle des influenceurs. Plusieurs autres thèmes auraient pu relever de cette approche mais la thématique de l’influence l’emporte largement. Notons d’emblée que, pour les auteurs, la discussion sur le concept d’influence est extrêmement rapide et ne semble pas mériter de recherche fondamentale. Nous avions fait (Boullier et Lohard, 2012) l’effort d’une description détaillée des conditions de félicité de l’influence qui doit comporter : exposition (visibilité), réputation, spécialisation (domaine par domaine), captation durable, propagation, discussion, orientation de la discussion. On se doute que la chaîne complète est rarement observable et surtout que les chercheurs en informatique ne se sont pas préoccupés de distinguer tous ces attributs de l’influence. Nous devrons donc nous contenter de faire avec ce « positivisme algorithmique » qui affecte trop souvent ces sciences. Ce positivisme les conduit de fait à reprendre sans grande précaution les trois approches que nous avons identifiées et en particulier celle des préférences, traduites en rôle des noeuds pour orienter l’attention du public de Twitter.
Nous avons écarté de cette présentation tous les articles qui combinaient influence et structure car dans tous les cas, l’influence se trouvait déterminée par la structure et les noeuds (les influenceurs) n’avaient donc plus de rôle particulier à jouer. Sans tenter de purifier le domaine, il nous faut bien reconnaître que les approches en termes de réplication (pouvoir d’agir des contenus qui circulent) sont toujours sous-estimées par rapport au rôle des influenceurs (préférences individuelles) qui sont eux-mêmes souvent réduits à une position dans une structure qui agit à leur place (structure). C’est tout au moins ce que les études en informatique donnent à voir mais il serait aisé de le montrer de façon identique dans le cas des sciences sociales en raison du poids des traditions et des rapports de force entre courants académiques.
L’article que nous avons sélectionné est cependant plus clairement focalisé sur les différents types d’influenceurs que l’on peut détecter, sans les réduire à un effet de structure et sans non plus entrer du tout dans les contenus ou les thèmes propagés. Varol et al. (2014), dans un article de ArXiv finalement publié, étudient les changements de rôles parmi les utilisateurs de Twitter durant la protestation de Taksim/ Parc Gezi à Istanbul au printemps 2013. Ils se fondent sur la collecte de 2,6 millions de tweets auprès de 855 000 comptes pendant 27 jours, dont 4 jours avant le début du mouvement pour pouvoir étalonner la distribution des rôles. Celle-ci se fait selon le rapport entre connectivité (followers/followees) et engagement (retwitter/être retwitté). Ils dégagent quatre statuts différents selon l’influence qu’ils exercent : les utilisateurs ordinaires, les rediffuseurs, les influenceurs et les influenceurs cachés (qui ont en fait peu de followers).
Les mouvements sociaux, comme dans le cas de l’article que nous avons présenté, sont un des deux terrains privilégiés par les chercheurs, l’autre étant les demandes des marques et du marketing. Dans ce cas, les métriques deviennent beaucoup plus cruciales pour aider à détecter les influenceurs qui vont jouer un rôle dans la propagation des messages des marques, et l’un des articles fait même l’inventaire des méthodes de mesure de ces influences[10].
La qualification des rôles de chaque noeud peut devenir beaucoup plus complexe dès lors qu’on admet que l’influence peut circuler de façon indirecte. Ce thème de recherche pourrait assez aisément dériver vers l’étude de ce qui circule dans cette influence indirecte. À l’inverse, l’identification de noeuds influents qui prend en compte leur position de pont entre communautés dans le réseau a tendance à attribuer leur rôle à cette structure du réseau, comme c’est le cas aussi lorsque l’article cherche à détecter les « superspreaders »[11]. On pourrait s’attendre à la mobilisation des concepts de « bridges » et de « structural holes » de Burt (1992) par exemple, puisqu’on en revient à une analyse structurale mais la fracture entre les communautés de recherche des sciences sociales et de l’informatique semble importante.
L’agentivité des réplications
Détecter les articles qui adoptent un point de vue de réplications peut s’avérer assez complexe, car, au sein même de cette approche, il est possible de basculer à nouveau vers une approche structurale, celle des courbes et des patterns du processus de diffusion par exemple, qui en fait un pur objet mathématique (comme l’exemple du mème « How to be skinny » » l’a montré plus haut). Il est aussi possible de détecter des bifurcations tout en attribuant ces bifurcations à l’agentivité des noeuds en cause. Enfin, traiter des thèmes (topics) et réaliser une topologie des liens entre thèmes, comme nous l’avons vu plus haut, ne permet en rien de décrire les capacités d’agir des réplications mais seulement des ensembles thématiques. Les approches par « content », « topics », « flows », « cascades » en particulier constituent de bons points d’entrée, sous réserve de validation prudente. Précisons cependant que lorsque nous cherchons à rendre compte du pouvoir d’agir des réplications, nous ne visons pas à identifier de grandes causes ou des influences déterminantes mais seulement à constater le fait que ces entités qui circulent, ces contenus ou ces mèmes, parviennent à survivre, à se propager et ainsi à traverser un réseau social et les esprits de ses membres (Dennett 2017).
Les approches mathématiques des propriétés des courbes visent à caractériser les pics, les positions d’un tweet dans une séquence, la morphologie des cascades (taille, forme, etc.) dans la lignée des travaux de Kleinberg (2002)[12]. Pour rester dans la veine des mouvements sociaux, nous avons choisi un cas de formalisme de description de la coordination à distance entre des villes participant au mouvement espagnol anti-austérité, « les Indignés », à partir du 15 mai 2011 (15M). L’approche de M. Aguilera[13], très orientée par la physique des ondelettes notamment, permet de détecter des phases dans les ondes de propagation des tweets (1,5 million de tweets pour 180 000 utilisateurs). Il peut paraître totalement exotique de voir un physicien modéliser ces processus en utilisant le modèle de physique statistique dit d’Ising qui permet de rendre compte d’effets collectifs produits par des interactions locales entre particules à deux états, plus encore lorsqu’il évoque l’idée d’un cerveau collectif. Dans cet article, l’auteur montre la synchronisation qui se réalise à distance entre les mouvements du 15 mai dans 15 villes (à partir des corpus Twitter), de façon différenciée selon la fréquence d’émission des tweets : à haute fréquence, la synchronisation entre villes est brève et moins souvent observable ; à basse fréquence, elle est plus durable. L’auteur estime alors que les deux fréquences sont complémentaires, la haute fréquence permettant la propagation rapide dans tout le réseau alors que la seconde permet de gérer des états plus locaux et plus spécifiques. Il explore même les interactions entre ces fréquences. L’auteur conclut en estimant qu’il rend compte de l’émergence d’une « agency » (terme qu’il utilise) du mouvement 15M sur le plan national grâce à ou malgré la diversité des fréquences d’émission selon les villes. Si l’agentivité en question est bien celle d’une entité émergente, la démonstration s’appuie avant tout sur une formalisation de physique statistique issue de la thermodynamique et appliquée à des phénomènes sociaux à large échelle grâce à l’accès aux traces laissées par l’usage de Twitter. C’est donc la propriété des ondes et des rythmes de propagation qui permet de constituer un effet de synchronisation du mouvement 15M. Ce critère de la fréquence des messages peut être considéré comme la version structurale d’une approche des réplications, ce qui n’est guère étonnant car les points de vue se démultiplient eux-mêmes de façon fractale. Les sciences sociales devront cependant être vigilantes pour garder ce formalisme dans des proportions raisonnables, c’est-à-dire interprétables à travers les concepts qui leur sont propres. Et l’exploration de l’agentivité des messages, ou des particules si l’on veut, reste indispensable à effectuer, quand bien même on sait qu’on ne peut observer les deux en même temps.
L’analyse de la conversation sous une forme structurale que l’on retrouve dans plusieurs articles du corpus permet de renouer avec les thèmes (topics) tout en évitant de les réduire à cette structure du réseau social. Il est ainsi possible de s’approcher un peu plus de ce qui circule, notamment pour l’étude des points de vue contradictoires et des controverses, qui sont analysées dans leur dynamique conversationnelle[14]. En entrant dans la dynamique des conversations par les thèmes, la question des entités qu’il convient de suivre émerge immédiatement. C’est une question clé pour la théorie des réplications que nous cherchons à bâtir, car l’étude empirique devra s’appuyer sur la traçabilité précise et vérifiable de ces entités. Les approches par les hashtags sont les plus courantes dans notre corpus ArXiv mais on peut aussi trouver des travaux centrés sur les sous-histoires, les flux de thèmes et les patterns textuels[15].
Le principe des sous-histoires est intéressant à étudier, en particulier car il ne se limite pas à la détection des thèmes, il prend en compte des dérivations dans la conversation sur Twitter et propose un formalisme pour repérer leurs parentés malgré de faibles cooccurrences de termes. L’une des études de cas d’un autre article sélectionné (Srijith et al., 2017) porte sur les émeutes de Ferguson en 2014 lorsqu’un jeune Noir, Michael Brown, avait été abattu par un policier blanc alors qu’il fuyait les mains en l’air. Cette histoire principale (ou thème) est en fait déclinée en plusieurs sous-histoires, parmi lesquelles les preuves vidéo ou la couverture médiatique par Fox News, dont les tweets peuvent ne plus mentionner les termes « Ferguson » ou « Brown » ou « police », tant le thème va de soi pendant ces pics d’échanges en ligne. Les autres études de cas réalisées portent sur les émeutes de Londres en 2012, la fusillade d’Ottawa en 2014 et un match de football Chelsea-Liverpool en 2012. Les auteurs utilisent ici la variante d’une analyse sémantique latente probabiliste appelée processus Dirichlet hiérarchique (HDP) qui permet de grouper progressivement les thèmes traités selon une hiérarchie, ce qui n’est pas simple lorsque les histoires se chevauchent dans le temps et dans les documents. Dans ce cas, les propagations différenciées des sous-histoires permettent de sortir des effets de structure de réseaux pour rendre compte de la capacité d’une sous-histoire à se propager plus que d’autres, toutes choses étant égales par ailleurs. Les propriétés sémiotiques des contenus sont ici les agents de la propagation et portent leur pouvoir d’agir.
Figure 3
Profil temporel des sous histoires issues des données sur les émeutes de Ferguson

Légende : Srijith et al., 2017. Lors des émeutes de Ferguson en août 2014, plusieurs sous-histoires se sont développées sur Twitter qui ont eu des propagations différentes. Au-delà des hashtags, l’identification des thèmes permet de reconstituer les réplications qui captent l’attention.
On le voit, l’émergence de la traçabilité comme qualité statistique permise par les réseaux numériques constitue une ouverture de possibles tout à fait inédits pour revisiter des modèles de la propagation, de l’imitation et des conversations qui n’avaient jamais trouvé leurs outils de quantification. Cependant, l’étude des travaux sur Twitter, la plate-forme la plus adaptée, pourrait-on penser, à l’observation de ces réplications, de leur pouvoir d’agir par leur circulation, nous a montré la tendance quasi naturelle à négliger leur pouvoir d’agir pour se focaliser sur les structures du réseau et sur les rôles des influenceurs. Le travail à réaliser reste considérable pour fonder une théorie des réplications qui rende compte de ces dimensions du social (la haute fréquence), qui sont désormais traçables grâce au numérique. Les inspirations de la mémétique devront cependant sans nul doute être dépassées, à la fois dans leur inspiration biologique somme toute déjà datée ou dans leur version analyses du web (web studies) où les mèmes prolifèrent comme industrie virale ad hoc, ce qui restreint considérablement la portée des réplications. Les travaux des chercheurs en informatique ont déjà permis d’en dégager deux dimensions, les patterns des courbes de propagation d’un côté et les variations des entités qui circulent de l’autre, même si la très grande partie des points de vue adoptés relève des conventions établies en sciences sociales, qui ont, depuis leurs débuts, distribué le pouvoir d’agir aux structures ou aux préférences individuelles.
Conclusion : des points de vue à une distribution d’agentivité (agency)
De la mise en regard des travaux en sociologie ou en informatique en matière d’études de Twitter, il nous faut tirer une leçon de portée plus générale. Les entités observées (structure, préférences ou réplications) constituent des points d’entrée incontournables dans le social, des points de départ qui formatent les questions et les méthodes. Ces choix annoncent nécessairement les points de sortie, les analyses et les interprétations à partir de données et de résultats construits par ces approches. Car, indépendamment des outils numériques, étudier une crise (par exemple un mouvement de la foule de supporters dans un stade, Boullier, Chevrier et Juguet, 2012) ne mobilisera pas les mêmes méthodes que, par exemple, la distribution sociale des étudiants du supérieur selon les filières. Les entités observées ne sont pas les mêmes, le rythme des processus est sans rapport (la haute fréquence et l’intensité brève contre la longue durée d’une reproduction des positions sociales héritées). Mais au-delà, les questions posées et les problèmes ne sont pas de même nature non plus. On peut certes étudier les déterminants sociaux de longue durée de l’hooliganisme ou la composition sociale des tribunes du vélodrome de Marseille (Bromberger, 1995), mais cela sera de peu d’utilité pour comprendre comment une émeute se déclenche à ce moment-là dans ce stade précis. Braudel avait insisté sur la portée de ces points de vue différents sur le temps social : « une conscience nette de cette pluralité du temps social est indispensable à une méthodologie commune des sciences de l’homme » (1958 : 726). Il avait ainsi distingué les événements, les cycles et la longue durée en précisant bien que « la seule erreur, à mon avis, serait de choisir l’une de ces histoires à l’exclusion des autres » (1958 : 734).
L’apprentissage automatique (machine learning), de son côté, a certes besoin que le volume des données soit suffisant pour apprendre, mais cet impératif du big data ne signifie pas pour autant exhaustivité ni totalité, et les chercheurs en informatique adoptent d’ailleurs UN seul point de vue sur le social, comme nous l’avons montré. Lorsqu’ils posent une hypothèse ou lorsqu’ils explorent les données de façon inductive, ils découpent le monde à partir d’un point de vue, et fonctionnent alors « toutes choses étant égales par ailleurs », c’est-à-dire en ignorant délibérément (ou involontairement !) certaines dimensions de l’univers de données ou du problème que l’on traite. C’est le prix à payer pour pouvoir explorer ce monde avec des méthodes et des outils opérationnels et donc analytiques, à moins d’adopter certaines postures qui caricaturent le systémisme en empilant les flèches des causalités sans jamais être capables d’en mesurer une seule, à la recherche d’un « tout » irrémédiablement perdu.
Nous dirons que les structures relèvent d’un processus d’héritage, bien mis en évidence par Bourdieu (1982). Rien ne sert de vouloir les contester ou les aplatir : l’héritage social a ses lois propres qui font effet de structure, il « leste » les comportements, quand bien même on pourrait suivre à la trace les médiations par lesquelles il est propagé. Les réplications relèvent du voisinage, des imitations par proximité, par mouvement de foule ou de public mais toujours grâce à la puissance spécifique de ce qui circule : une passion, un désir, une croyance, une idée, un message, un mème, le hau, un climat, etc. C’est parce que ces entités ont cette puissance d’agir, cette agentivité (agency), qu’elles provoquent ces émergences irréductibles aux héritages des structures, quand bien même des paramètres de la situation peuvent en relever. Enfin, les préférences individuelles, les choix, les décisions sont des moments d’arbitrage qui pondèrent les possibles influences, qui entrent en conflit en permanence, comme le disait Tarde. Mais ces moments de décision, qu’on attribue souvent à un agent rationnel, calculateur ou stratégique, n’interviennent que dans certaines situations, sans pour autant invalider les effets des héritages et des voisinages. On peut même dire que c’est un arbitrage entre ces deux types d’influence qui détermine souvent la décision, si elle est possible. Les intentions des agents, leurs stratégies et leurs états intérieurs peuvent alors être convoqués comme le font l’économie ou la psychologie cognitive, pour rendre compte de ces préférences. Mais les problèmes soulevés sont alors totalement différents à cause de ce cadrage conceptuel, méthodologique, qui constitue un point de vue parmi les trois disponibles selon nous. Héritage, arbitrage et voisinage (Boullier, 2010) ne sont donc en rien contradictoires mais ne peuvent être saisis ensemble car les méthodes pour en rendre compte sont radicalement différentes. Le numérique n’y change rien mais amplifie l’une d’elles plus que les autres, au point de rendre enfin accessible tout un pan du social, celui des réplications, faites de viralité et de mémétique, de propagations et de vibrations, grâce à l’amplification des traces de l’agentivité des entités circulantes.
Aucun de ces points de vue n’est contradictoire des autres, à condition d’admettre qu’il n’est qu’un point de vue et qu’il ne peut prétendre rendre compte de la totalité des phénomènes sociaux. Il serait sans doute possible d’en détecter d’autres, mais, à l’examen empirique, il s’avère qu’ils peuvent tous être regroupés dans ces trois points de vue ou dans leurs combinaisons, et ce principe d’économie conceptuelle opère alors comme le rasoir d’Occam. Cette agentivité distribuée constitue sans doute aussi une proposition diplomatique qui tranche avec les oppositions, récemment ravivées, entre Bourdieu et Boudon par exemple, ou entre la théorie de l’acteur-réseau (ANT) et ces deux prédécesseurs.
Appendices
Notes
-
[1]
Nous ne pouvons pas développer ici la parenté bien réelle avec les propositions de Ginzburg (1980).
-
[2]
Nous qualifions d’émergentistes les points de vue qui, sous diverses formes, ne se contentent pas d’un appel aux structures ou aux préférences individuelles mais considèrent que les situations, les habitudes, les événements, les non-humains, génèrent des perturbations dans tous les systèmes sociaux par la coordination inédite d’entités dont on avait sous-estimé le pouvoir d’agir et font apparaître de nouveaux possibles. L’émergence est ici à la fois tout ce qui reste et dont ne peut rendre compte classiquement, et aussi tout ce qui relève de processus d’auto-organisation.
-
[3]
Les articles publiés dans d’autres rubriques comme « Physics and Society » par des physiciens, sont à 98 % classés en même temps dans les rubriques de « Computer Sciences », ce qui nous permet de couvrir les études de Twitter de façon quasi complète. Il est même possible de pousser plus loin encore dans cette logique fractale des points de vue. Les articles qui traitent Twitter depuis l’agentivité des réplications (c’est-à-dire une portion réduite de ces articles) sont parfois eux-mêmes orientés structures (des propagations), préférences (des noeuds de bifurcation et des types de messages) ou réplications (les attributs intrinsèques des messages qui se propagent indépendamment de leur forme d’origine), ce que Limor Shifman (2014) identifie comme le coeur même de la mémétique. Mais cela nous entraînerait trop loin dans le cadre de cet article.
-
[4]
Traduction personnelle : « Les élites semblent également garder leur statut, indiqué par leur faible activité de retweet alors que les nouveaux et les typiques augmentent leur activité de retweeting, ce qui suggère une réticence à “consacrer” les autres comme dignes d’attention en retweetant leur contenu. »
-
[5]
Cet article a été finalement publié sur Frontiers in Physics, www.frontiersin.org/articles/10.3389/fphy.2015.00059/full
- [6]
-
[7]
Nous listons ici les références qui relèvent de ces approches et qui permettent au lecteur de retrouver les articles en question sur ArXiv, http://arxiv.org/abs/1607.04747v2
-
[8]
http://arxiv.org/abs/1006.1702v1
- [9]
-
[10]
http://arxiv.org/abs/1605.07990v3
-
[11]
http://arxiv.org/abs/1202.6601v2
-
[12]
http://arxiv.org/abs/1609.09028v2
http://arxiv.org/abs/1606.09446v2
-
[13]
« Rhythms of the collective brain : Metastable synchronization and cross-scale interactions in connected multitudes », http://arxiv.org/abs/1611.06831v2
- [14]
-
[15]
http://arxiv.org/abs/1508.03607v1
http://arxiv.org/abs/1606.03561v1
Bibliographie
- Algan, Y., P. Cahuc et M. Sangnier (2016), « Trust and the welfare State : the twin peaks curve », The Economic Journal, vol. 126, n° 593, June 2016, p. 861-883.
- Alvarez, R. M. (dir.) (2016), Computational Social Sciences. Discovery and Prediction, New York, Cambridge University Press.
- Avnit, A. (2009), « The Million Followers Fallacy », Internet Draft, Pravda Media. http://blog.pravdam.com/the-million-followers-fallacy-guest-post-by-adi-avnit/, consulté le 8 décembre 2017.
- Bakshy, E., J. Hoffman, W. Mason et D. Watts (2011), « Everyone’s an Influencer : Quantifying Influence on Twitter », WSDM’11, February 9-12, Hong Kong.
- Barbier, R. et J. Trépos (2007). « Humains et non-humains : un bilan d’étape de la sociologie des collectifs », Revue d’anthropologie des connaissances, vol. 1, n° 1, p. 35-58.
- Blackmore, S. (1999), The meme machine, Oxford, Oxford University Press.
- Blondiaux, L. (1998), La fabrique de l’opinion. Une histoire sociale des sondages, Paris, Seuil.
- Boullier, D. et A. Lohard (2012), Opinion mining et sentiment analysis. Méthodes et outils, Marseille, OpenEdition Press.
- Boullier, D. (2004), La télévision telle qu’on la parle. Trois études ethnométhodologiques, Paris, L’Harmattan.
- Boullier, D. (1987), La conversation télé, Rennes, LARES.
- Boullier, D. (1989), « Du bon usage d’une critique du modèle diffusionniste. Discussion-prétexte des concepts de E. M. Rogers », Réseaux, vol. 7, n° 36, p. 31-51.
- Boullier, D. (2010), La ville-événement. Foules et publics urbains, Paris, PUF.
- Boullier, D.,S. Chevrier et S. Juguet (2012), Événements et sécurité. Les professionnels des climats urbains, Paris, Les Presses des Mines.
- Boullier, D. et M. Crépel (2013), « Biographie d’une photo numérique et pouvoir des tags : classer/circuler », Revue d’Anthropologie des Connaissances, vol. 7, n° 4, p. 785-813.
- Boullier, D. (2016), Sociologie du numérique, Paris, Armand Colin, coll. « U ».
- Boullier, D. (2015a), « Les sciences sociales face aux traces du Big Data. Société, opinion ou vibrations ? », Revue française de science politique, vol. 65, n° 5-6, oct-déc, p. 805-828.
- Boullier, D. (2015b), « Vie et mort des sciences sociales avec le Big Data », Socio, n° 4, p. 19-37.
- Bourdieu, P. (1982), « Les rites comme actes d’institution », Actes de la recherche en sciences sociales, n° 43, juin 1982.
- Bromberger, C. (1995), Le match de football. Ethnologie d’une passion partisane à Marseille, Naples et Turin, Paris, éditions de la Maison des sciences de l’homme.
- Bruns, A. et H. Moe (2014), « Structural Layers of Communication on Twitter », inWeller, K., A. Bruns, J. Burgess, M. Mahrt et C. Puschmann (dir.), Twitter and Society, New York, Peter Lang, p. 15-41.
- Burt, R. (1992), Structural Holes, Cambridge, Mass., Harvard University Press.
- Callon, M., J. Law et A. Rip (1986). « Qualitative Scientometrics », inCallon, M., J. Law et A. Rip (dir.), Mapping the Dynamics of Science and Technology, London, Macmillan, p.103-123.
- Callon, M. (1986), « Éléments pour une sociologie de la traduction. La domestication des coquilles Saint-Jacques et des marins-pêcheurs dans la baie de Saint-Brieuc », L’année sociologique, n° 36, p. 169-208.
- Cha, M., H. Haddadi, F. Benevenuto et K. P. Gummad (2010), « Measuring user influence on twitter : The million-follower fallacy », 4th Int’l AAAI Conference on Weblogs and Social Media, Washington, DC.
- Cheng, J., L. A.Adamic, J. M. Kleinberg et J. Leskovec (2016), « Do cascades recur ? », in Proceedings of the 25th International Conference on World Wide Web, p. 671-681.
- Dawkins, R. (1976), The Selfish Gene, Oxford, Oxford University Press.
- Degenne, A. et M. Forsé (1994), Les réseaux sociaux. Une approche structurale en sociologie, Paris, Armand Colin, coll. « U ».
- Dennett, D. (2017), From Bacteria to Bach and Back. The Evolution of Minds, Londres, Penguin Books.
- Desrosières, A. (1993), La politique des grands nombres. Histoire de la raison statistique, Paris, La Découverte.
- Durkheim, É. (1897), Le suicide, Paris, Alcan.
- Eisenstein, E. L. (1991), La révolution de l’imprimé dans l’Europe des premiers temps modernes, Paris, La Découverte.
- Ginzburg, C. (1980), « Signes, traces, pistes. Racines d’un paradigme de l’indice », Le Débat, n° 6, p. 3-44.
- Granovetter, M. (1995), Getting a Job, Chicago, University of Chicago Press.
- Grossetti, M. (2011), « Les narrations quantifiées. Une méthode mixte pour étudier des processus sociaux », Terrains et Travaux, no 19, p. 161-182.
- Haraway, D. (2011,) Manifeste cyborg et autres essais. Sciences, fictions, féminismes. Anthologie établie par Allard, L., D. Gardey et N. Magnan, Paris, Exils.
- Kapferer, J. N. (1986), Rumeurs, Paris, Le Seuil.
- Katz, E. et P. Lazarsfeld (1955), Personal Influence : The Part Played by the People in the Flow of Mass Communication, Glencoe, Free Press.
- Kleinberg, J. (2002), « Bursty and Hierarchical Structure in Streams », Proc. 8th ACM SIGKDD Intl. Conf. on Knowledge Discovery and Data Mining.
- Latour, B., B. Jensen, T. Venturini, S. Grauwin et D. Boullier (2012), « The Whole Is Always Smaller Than Its Parts. A Digital Test of Gabriel Tarde’s Monads », British Journal of Sociology, vol. 63, n° 4, p. 590-615.
- Latour, B. (2010), « Steps Toward the Writing of a Compositionist Manifesto », New Literary History, vol. 41, p. 471-490.
- Latour, B. (2006), Changer de société — Refaire de la sociologie, Paris, La Découverte.
- Latour, B. (1990), La science en action, Paris, La Découverte.
- Lazega, E., M.-T. Jourda, L. Mounier et R. Stofer (2007), « Des poissons et des mares : l’analyse de réseaux multi-niveaux », Revue française de sociologie, vol. 48, n°1, p. 93-131.
- Lazer D. et al. (2009) « Life in the network : the coming age of computational social science », Science, vol. 323, n° 5915, p.721-723.
- Le Béchec, M. et D. Boullier (2014), « Communautés imaginées et signes transposables sur un « web territorial » », Études de communication, vol. 1, n° 42, p.113-125.
- Lehman, J., B. Gonçalvez, J. Ramasco ET C. Cattuto (2012), « Dynamical Classes of Collective Attention in Twitter », WWW 2012, April 16-20, Lyon, https://arxiv.org/abs/1111.1896, consulté le 8 décembre 2017.
- Leskovec, J., L. Backstrom et J. Kleinberg (2009), « Meme-Tracking and the dynamics of the news cycle », ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD).
- Lévi-Strauss, C. (1950), Introduction à l’oeuvre de Marcel Mauss, Paris, PUF.
- Lin, Y.-R., B. Keegan, D. Margolin et D. Lazer (2014), « Rising Tides or Rising Stars ? : Dynamics of Shared Attention on Twitter during Media Events », PLoS ONE vol. 9, n°5, p. e94093.
- Maireder, A. et J. Auserhofer (2014), « Political Discourses on Twitter : Networking Topics, Objects, and People », inWeller, K., A. Bruns, J. Burgess, M. Mahrt et C. Puschmann, (dir.), Twitter and Society, New York, Peter Lang, p. 305-318.
- Malinowski, B. (1963 [1922]), Les Argonautes du Pacifique occidental, Paris, Gallimard.
- Marres, N. (2017), Digital Sociology, Cambridge, Polity Press.
- Mauss, M. (1950), « Essai sur le don », inMauss, M.,Sociologie et Anthropologie, Paris, PUF.
- Mercklé, P. (2004), Sociologie des réseaux sociaux, Paris, La Découverte (3e édition 2016).
- Myers, S. A. et J. Leskovec (2014), « The bursty dynamics of the Twitter information network », WWW 14, April 7-11, 2014, Seoul, Korea.
- Nagler, J., J. Tucker, P. Barbera, M. Metzger, D. Penfold-Brown et R. Bonneau (2016), « Big Data, Social Media, and Protest : Foundations for a Research Agenda », inAlvarez, R. M. (dir.), Computational Social Science, New York, Cambridge University Press.
- Omodei, E., M. De Domenico et A. Arenas (2015), « Characterizing interactions in online social networks during exceptional events », Front. Phys., vol. 3, n° 59.
- Pentland, A. (2014), Social Physics. How Good Ideas Spread. The Lessons From a New Science, New York, Penguin Press.
- Rogers, E. M. (1983 [1963]),Diffusion of Innovations, New York, Free Press.
- Rogers, R. (2013), Digital Methods, Cambridge, Ma, MIT Press.
- Rubinstein, D. H. (1983), « Epidemic Suicide Among Micronesian Adolescents », Social Science and Medicine, vol. 17, n° 10, p. 657-665.
- Sahlins, M. (1976), Âge de pierre, âge d’abondance : L’économie des sociétés primitives, Paris, Gallimard.
- Shapin, S. et S. Shaffer (1993), Léviathan et la pompe à air. Hobbes et Boyle entre science et politique, Paris, La Découverte.
- Simon, H. A. (1971), « Designing Organizations for an Information-Rich World », inGreenberger, M., Computers, Communication, and the Public Interest, Baltimore, MD, The Johns Hopkins Press.
- Shifman, L. (2014), Memes in Digital Culture, Cambridge, MIT Press.
- Srijith, P. K., M. Hepple, K. Bontcheva et D. Preotiuc-Pietro (2017), « Sub-story detection in Twitter with hierarchical Dirichlet processes », Information Processing & Management, vol. 53, n° 4, p. 989-1003.
- Tarde, G. (1890), Les lois de l’imitation, Paris, Alcan.
- Tarde, G. (1897), Contre Durkheim. À propos de son « suicide », in Berlandi, M. et M. Cherkaoui(dir.), Le Suicide un siècle après Durkheim, 2000, Paris : Les Presses Universitaires de France, p. 219-255.
- Varol, O., E. Ferrara, C. L. Ogan, F. Menczer ET A. Flammini (2014), « Evolution of Online User Behavior During a Social Upheaval », Proceedings of the 2014 ACM conference on Web science, p. 81-90.
- Vázquez Campos, M. et A. Gutiérrez (2015), « The Notion of Point of View », inTemporal Points of View : Subjective and Objective Aspects, Springer.
- Viveiros de Castro, E. (2009), Métaphysiques cannibales, Paris, PUF.
- Watts, D. J. et P. S. Dodds (2007), « Influentials, networks, and public opinion formation », Journal of Consumer Research, vol. 34, n° 4, p. 441-458.
- Weng, J., E. P. Lim, J. Jiang et Q. He (2010), « Twitterrank : Finding Topic-Sensitive Influential Twitterers », ACM International Conference on Web Search and Data Mining (WSDM 2010), 261. Research Collection School of Information Systems.
- Weng, L., A. Flammini, A. Vespignani et F. Menczer (2012), « Competition among memes in a world with limited attention », Nature —Scientific Reports, vol. 2, n° 335, p. 1-8.
List of figures
Figure 1
Modèles de propagation des tweets en fonction de quatre événements
Légende : Lehman et al., 2012. Modèles de propagation contrastés à partir de quatre hashtags se référant à des événements très différents : le master de golf, une fusillade dans une école en Allemagne, la sortie d’un film, un discours du président Obama. En haut l’activité quotidienne du réseau, au milieu l’activité des comptes, en bas le nuage de mots des termes des tweets.
Figure 2
Récurrence du mème « how to be skinny » sur Facebook
Légende : Chen et al., 2016. Récurrence d’un mème dans le temps sur Facebook. Les couleurs se réfèrent à la source du mème qui se propage car plusieurs sources peuvent contribuer. En incrustation, le mème étudié (How to be skinny) tel qu’il est diffusé sous forme d’image.
Figure 3
Profil temporel des sous histoires issues des données sur les émeutes de Ferguson
Légende : Srijith et al., 2017. Lors des émeutes de Ferguson en août 2014, plusieurs sous-histoires se sont développées sur Twitter qui ont eu des propagations différentes. Au-delà des hashtags, l’identification des thèmes permet de reconstituer les réplications qui captent l’attention.
List of tables
Tableau des trois points de vue sur le social