
Résumés
Résumé
Cet article se veut une étude originale d’application des méthodes d’analyse de données textuelles à des corpus musicaux. Aucune étude en musicologie moderne n’a encore décrit en détail le système modal en usage dans le répertoire des charagan, chants liturgiques arméniens. Dans ce répertoire, on peut déceler une vingtaine de modes musicaux qui semblent avoir été classés par convention dans un système symbolique d’oktoechos (huit modes). Ceci donne à chacun des modes de l’oktoechos le caractère d’une famille de modes plutôt que d’un seul mode spécifique. Dans cet article, nous présentons une première étape de la description de six versions différentes de 42 chants. En tout, 728 versets découpés en unités de phrases, formules, motifs, degrés ont été analysés avec le logiciel Sphinx. Notre analyse avec Sphinx permet une première description de la structure modale des charagan, faisant ressortir les spécificités des différentes versions, des degrés et des motifs propres aux différentes formules initiales, médiane et finale de ces chants.
Mots-clés :
- Charagan,
- chant liturgique arménien,
- oktoechos,
- structure modale,
- mélodie-type,
- intervalle,
- combinaison,
- IVe voix,
- Sphinx
Abstract
This article is proposed as an original study on the application of the methods of textual data analysis to musical corpus. In modern musicology, the musical oktoechos of the charagan repertoire of the Armenian liturgical chant has never been described in detail. This repertoire is organized in an oktoechos (eight modes) system. In its present state, some twenty musical modes seem to have been classified by convention in a symbolic system of oktoechos. This fact gives each of the oktoechos modes the character of a mode family rather than a precise single mode. In this article, we are presenting the first stage of the description of six different versions of 42 chants belonging to the same mode and same melody-type. A total of 728 verses, divided into phrase units, are analysed with Sphinx application program. Our analysis with Sphinx allows us to show the specificities of different versions, degrees, as well as proper motifs of initial, median and final formulae of different versions of these songs. The analysis also permits to reveal characteristic formulae suits of sharakan phrases, and the environment created by different intervals which constitute this mode.
Keywords:
- Charagan,
- armenian liturgical chant,
- oktoechos,
- modal structure,
- melody-type,
- intervals,
- combination,
- IVe mode,
- Sphinx
Corps de l’article
Introduction
Notre étude s’intéresse à un sujet peu étudié, celui des charagan[1]. Les charagan[2] constituent un répertoire spécifique[3] du chant liturgique arménien transmis essentiellement par voie orale, soutenue par une notation neumatique[4] et, depuis le 19e siècle, par la Notation musicale arménienne moderne[5]. Le chant liturgique arménien s’inscrit dans un système musical monodique et modal : c’est le développement mélodique qui importe et non l’harmonique. Aussi, ce chant se caractérise par l’usage du bourdon, chanté sur la voyelle « ou » et sur le degré fondamental du mode.
Les charagan forment la substance du système musical du chant liturgique arménien et se distinguent des autres chants par le fait qu’ils forment le seul répertoire dans lequel apparaît le système d’oktoechos[6] musical (huit voix ou modes), mais aussi des « mélodies — types » traditionnelles et le système de variation. C’est un répertoire[7] dynamique basé sur une variation mélodique selon le texte et une variation de tempo selon la fonction ou l’usage dans les rituels. Chaque charagan est composé dans un seul mode et il est chanté dans ce mode uniquement. Le mode étant le choix spécifique de sons (degrés) qui ont une hiérarchie, chaque choix et chaque hiérarchie établit un environnement sonore reconnaissable (mode). Le choix d’une série de 3, 4, 5, degrés consécutifs ayant des rapports spécifiques[8] forment les unités de la structure d’un mode, les intervalles. Ces intervalles sont identifiés par leur genre (basé sur les rapports acoustiques) et leurs espèces (les différents ordonnancements de ces rapports d’intervalles).
Aucune étude en musicologie moderne n’a encore décrit en détail le système modal en usage dans le répertoire des charagan, chants liturgiques arméniens. Dans ce répertoire, on peut déceler une vingtaine de modes musicaux qui semblent avoir été classés par convention dans un système symbolique d’oktoechos (huit modes). Ceci donne à chacun des modes de l’oktoechos le caractère d’une famille de modes plutôt que d’un seul mode spécifique.
En général les études sur les charagan se concentrent sur leur aspect liturgique (Wrinkler, 1983; 1984). Notre objectif est plutôt de décrire la structure de l’un des modes de l’oktoechos arménien, la 4e Voix. Ce mode a été choisi tout d’abord pour sa complexité. En effet, le mode 4e Voix est le mode le plus complexe de l’octoechos; il permet d’étudier le plus grand nombre de cas de figure et d’obtenir suffisamment d’éléments qui pourraient être appliqués ensuite à l’octoechos entier. Les chants analysés appartiennent donc tous au même mode musical (appelé la 4e Voix, dans l’octoechos). Deuxièmement, ces chants sont fondés sur des mélodie-types plus ou moins similaires, et, pris ensemble, ils peuvent être considérés comme formant une famille de mélodie-type. Autrement dit, les chants choisis montrent un éventail de variations mélodiques (en grande partie fondées sur le texte), avec des structures modales comparables.
Notre recherche innove non seulement par son objet, mais aussi par la méthodologie développée, c’est-à-dire par la description minutieuse de la structure et de ses variantes grâce au logiciel d’analyses documentaires et statistiques de données textuelles Sphinx[9]. En effet, peu d’études en musicologie se sont aventurées dans l’utilisation d’outils d’analyse informatisée et statistique. À partir des années 70, il y a eu des essais d’utiliser la statistique en musicologie (Barbaud, 1971; Charnassé et Ducasse, 1973). Benzécri et al. (1981), avec l’article de Morino (1976), présentaient déjà une première application de la statistique, notamment de l’Analyse Factorielle de Correspondance (AFC)[10], à l’étude de partitions musicales.
Grâce aux outils informatisés d’analyse de données textuelles (analyses qualitatives et statistiques), nous voulons trouver l’ensemble des règles objectives qui régissent l’ordonnancement des sons dans la création des mélodies, étudier la succession des intervalles et leur permutation. Pour cela nous avons constitué un corpus important de charagan et nous avons développé une démarche d’analyse que nous présentons dans la section suivante.
1. Corpus et méthodologie
Nous avons choisi 42 chants de ce même mode 4e Voix (plus ou moins ressemblants au niveau de la mélodie-type) en considérant quatre à six versions mélodiques de chaque chant provenant de différentes traditions locales. En tout 728 versets composés chacun d’une phrase littéraire composent notre corpus. En prenant comme seul critère l’unité de sens fonctionnelle du texte, les phrases sont découpées en unités de sous-phrases qui constituent des formules mélodiques (commencement, développement, finale). Ces dernières sont à leur tour divisées en motifs (unités de sens fonctionnel du syntagme constituant la formule). Le critère musical intervient aussi en système de question-réponse. Ci-dessous un exemple de découpage d’un verset (Figure 1).
La transcription de ces chants s’est déroulée en quatre étapes :
-
Première étape : les chants sont retranscrits en notation occidentale et de façon synoptique, chaque verset sur une ligne. On divise le verset en formules initiales (commencement), médiane (développement) et finale en prenant comme seul critère l’unité de sens fonctionnelle du texte. Le critère musical intervient aussi en système de question-réponse. Les formules sont constituées de motifs, d’unités de sens fonctionnel du syntagme constituant la formule (Figure 1);
-
Deuxième étape (intermédiaire et facultative) : schématisation du déroulement mélodique, où apparaît l’ordonnancement des sons et la hiérarchie (note noire avec un trait = note qui se répète; note blanche = degré d’appel ― sorte de dominant à l’écoute, finale intermédiaire ou finale;
-
Troisième étape : extraction des intervalles employés;
-
Quatrième étape : transcription en fichier texte. Les degrés et intervalles sont traduits par des lettres en unités mots (par exemple, le mot SIarDOREMI traduit la succession des notes Si arrêt Do RE MI (Tableau 1).
Figure 1
Exemple du découpage d’un verset

Ce fichier texte a ensuite été préparé pour le traitement statistique du lexique avec Sphinx[11] (Figure 2). Pour cela, chaque chant a été repéré par un Jalon (par exemple [J=22] identifie le chant 22), les versions et les versets de ce même chant par un Jalon texte [JT=22Bi] (B étant la version B du chant 22 et i, le 1er verset); quant aux parties du verset, initiale(com), médiane(dev) et finale (fini), elles ont été repérées par une Marque (par exemple [M=com], [M=Dev]). Voici, dans la figure 2, un extrait de ce fichier texte ainsi constitué.
Figure 2
Extrait du fichier texte dans Sphinx

2. Analyse
La transformation des données musicales en fichier texte permet de traduire en variables objectives les différents éléments qui constituent le sentiment modal. D’autre part, elle permet leur analyse par des outils informatiques et statistiques. En soi, ce travail de traduction et de transformation des données en catégories identifiables représente une description qualitative des données, un travail de conceptualisation-codification énorme. Vu l’ampleur et la complexité de la description de la structure de ces versets (plusieurs variables à étudier simultanément), nous avons utilisé les analyses documentaires et statistiques du logiciel Sphinx.
Les unités d’analyse qui ont permis de décrire la structure modale se regroupent autour de deux variables : les unités texte et les unités de structure. La variable texte est composée des modalités mots du lexique (suites de degrés séparés par des blancs) et segments (suites de mots du lexique).
Ces modalités sont constituées de plusieurs éléments descriptifs du mode : l’Intervalle (unité formelle de plusieurs degrés consécutifs), le Saut (s), (passage d’un degré à l’autre en omettant les degrés intermédiaires), la Corde (un degré qui devient une corde de récitation, quand la mélodie reste assez longtemps sur un même degré), l’Arrêt (ar), (motif mélodique qui s’arrête sur un degré de l’intervalle en cours et qui est de moindre importance dans la hiérarchie).
Les unités de structure sont le Verset (une phrase littéraire complète qui est chantée sur une mélodie complète), la Formule (un membre de phrase musicale, délimitée par la partie de la phrase littéraire correspondante), le Motif (une subdivision mélodique de la formule, délimitée par l’unité syntagmatique correspondante).
2.1. Première étape : analyse du lexique
Afin de vérifier le poids réel de chaque mot du fichier texte ainsi obtenu, les analyses statistiques sur les mots du lexique ont été effectuées aussi bien pour l’ensemble du corpus que pour chacune des versions. Le dictionnaire ainsi constitué recense la liste des éléments ou configurations qui constituent le mode (Tableau 1).
Tableau 1
Fréquence des mots dans le Lexique total (extrait)

Les mots du lexique qui ont les plus hautes fréquences, SIarDOREMI 432, SIDOREfii 387, SIDOREap 384 SIDOREapMI 248 LASIDOREapMI 206 DOarREMI 173, cDO 150, représentent les configurations constitutives du mode. Cette liste de fréquences hautes révèle les deux espèces d’intervalles qui sont à la base du mode : diatonique de la deuxième espèce (mots commençant par LA) et diatonique de la troisième espèce (mots commençant par SI). Une troisième, le diatonique de la première espèce (mots commençant par SOL ou DO) est employé dans certains cas.
Les occurrences moins fréquentes comme REfiiMIFA 6, SIDOREfi1MIFA 1, sLADO 1 sLARELA 2, Siar DOREMIFA 5, représentent en général les variations modales possibles.
Avant même de faire un regroupement des mots appartenant aux mêmes espèces, le début de la liste est déjà révélateur : les quatre premiers mots (SIarDOREMI, SIDOREfii, SIDOREap, SIDOREapMI) appartiennent à la troisième espèce, les trois mots suivants (LASIDOREapMI, LAarSIvaDORE, LASIDOREap) à la deuxième espèce et le huitième mot (DOarREMI) à la première espèce. Le regroupement accentuera l’importance de la première espèce et révélera la variation modale qu’il induit (Kerovpyan, 2003); toutefois l’ordre d’apparition des espèces correspond effectivement à leur importance dans la constitution du mode.
2.1.1. Analyse du lexique en fonction des versions
Les six versions étudiées diffèrent par l’emploi de certains éléments. L’analyse statistique permet de relever ces particularités qui passent souvent inaperçues dans l’ensemble de la mélodie. On peut en faire l’inventaire et concrétiser ces différences par exemple en croisant les mots du lexique avec les différentes versions du chant. Ce tableau de fréquence permet d’établir un cadre dynamique du mode. Cadre dynamique, car contrairement à la description habituelle des modes, basée uniquement sur la présentation de l’échelle des sons et l’indication des degrés dominants, nous incluons toutes les possibilités de variations effectuées, ce qui permet de percevoir de façon plus complète les mouvements internes du mode.
Le tableau de contingence obtenu par le croisement des mots du lexique selon les versions, soumis à l’Analyse factorielle de Correspondance nous donne la figure 3.
Figure 3
Analyse factorielle de Correspondance des intervalles selon les versions
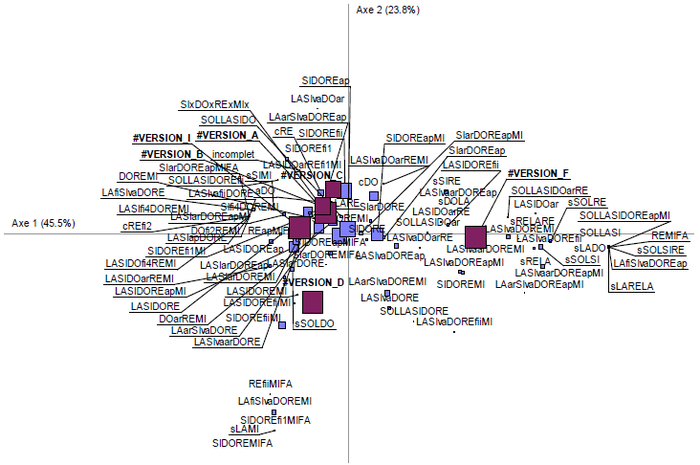
Cette AFC oppose sur le premier axe (45,5 % de la variance), la version F aux autres versions. Bien que la version F utilise le même schéma mélodique que les autres versions, elle montre certaines préférences, notamment l’utilisation de configurations de la première espèce (tout ce qui commence par SOL); par exemple, là où les autres versions utilisent sLARE, la version F préférera utiliser sSOLRE. Dans la version F, les configurations en tétracorde de la deuxième espèce (LASIDORE) ont tendance à devenir des configurations en pentacorde (LASIDOREMI). Comme on le verra aussi plus loin avec l’AFC des sauts, la version F se caractérise par l’utilisation importante de configurations avec sauts.
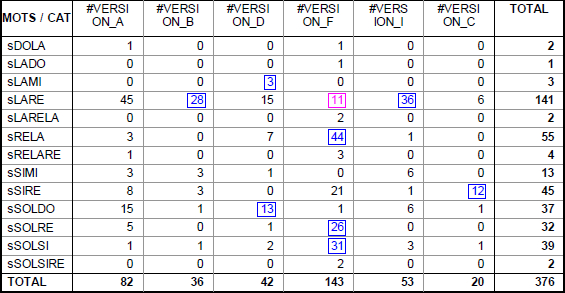
Tableau 2
Tableau de contingence des sauts par version
L’axe 2 (23,8 % de la variance) oppose la version D aux autres versions. La version D se caractérise par l’utilisation d’intervalles de la 2e espèce (commençant par LA) dans les finales alors que toutes les autres versions préfèrent la 3e espèce (commençant par SI). D’autre part, la version D va préférer les configurations en pentacorde. Par exemple, là où les autres versions utiliseront LASIDOREap, la version D utilisera LASIDOREapMI.
La fréquence des autres éléments (sauts, cordes, et arrêts) relevée notamment par version, complète notre vue de la structure modale et montre comme pour les intervalles, les préférences des versions mélodiques et par conséquent, l’étendue des variations possibles. L’exemple ci-dessous de l’étude du saut est assez révélateur.
Figure 4
AFC sauts par version

Cette analyse nous montre que la version F se caractérise par les sauts sRELARE, sSOLSI sRELA, sSOLRE, sSOLSIRE, sLADO, sLARELA. Par exemple, là où les versions A, B, et I utilisent le saut LARE la version F préfère utiliser le saut SOLRE.
Cet ensemble de résultats fournit les informations nécessaires pour établir le cadre dynamique du mode. Les différences entre les versions restent toutes dans le même cadre modal, c’est-à-dire qu’elles se réfèrent aux mêmes éléments de base. Par exemple, les différents sauts d’intervalles sont issus des mêmes intervalles de base qui constituent le mode. L’analyse statistique démontre ainsi la cohérence qui existe entre les versions, qui se distinguent pourtant facilement à l’écoute.
2.1.2 Analyse du Lexique selon les formules (initiale, médiane, finale)
Pour la description de la phrase du charagan, une autre analyse du lexique s’est avérée intéressante, celle de l’analyse des intervalles en fonction de la place qu’ils occupent dans la phrase musicale, c’est à dire dans les différentes parties initiale (commencement), médiane (développement) et finale. Les tableaux de cooccurrences du lexique en fonction de ces trois modalités de la place dans la phrase ainsi que les AFC de ces tableaux nous ont permis de faire ressortir les spécificités de chacune des parties de la phrase et d’arriver à une connaissance plus précise de la fonction de chaque élément dans la phrase. Nous présentons exemple l’AFC du Lexique total par parties de textes (Figure 5).
Figure 5
AFC du lexique en fonction des trois parties, initiale (com), médiane (dév) et finale

Le 1er axe de cette AFC (71 % de la variance) montre clairement les différences mélodiques entre les trois parties. On voit que les variations arrivent soit à la fin de la partie médiane, soit au début de la partie finale. Contrairement aux deux autres parties (initiale et médiane), la partie finale se caractérise par l’utilisation de l’intervalle fusionné (2e et 3e espèces combinées), c’est à dire des configurations qui commencent par LASI suivi de « ar » (arrêt) ou « vaar » (variation et arrêt), des cordes (cDO, cREfi2) et les sauts (sSOLSI, sSOLDO, sSIRE, sSIMI, sSOLSIRE). Quelques finales spéciales comme fi2Refii Refi1MI, Dofi2REMI, caractérisent aussi cette partie.
Le 2e axe (28,1 % de la variance) oppose les deux parties initiales et médianes (Dev). La fin de la partie médiane est caractérisée par la variante ap. Les configurations contenant SIar arDO et REap caractérisent la médiane, tandis que les sauts caractérisent la partie initiale (com), notamment les débuts des versets. Ce sont, en général, des mots dont l’accentuation permet un début affirmé par un saut, ou bien des mots à deux syllabes qui favorisent le saut initial, comme aysor (aujourd’hui ou ce jour).
L’histogramme des sauts par parties du texte (Figure 6) nous montre que les sauts LARE et RELA caractérisent la partie initiale (com) et que les sauts SIMI, SIRE, SOLDO, SOLSI prédominent dans la partie finale.
Figure 6
Histogramme du nombre de « Sauts » par « Parties » du texte

2.2. Deuxième Étape : Analyse structurelle
La deuxième étape a consisté en un regroupement en deux étapes ou niveaux des intervalles selon des classes d’équivalence afin de trouver les structures minimales ou les schémas modaux.
Les critères suivants ont été utilisés pour les regroupements de la première étape :
-
intervalles de même espèce utilisés de différentes façons;
-
Présence de deux mots du lexique employés ensemble fonctionnent comme un autre mot du lexique; par exemple, sLARE$SIDOREapMI=LASIDOREapMI;
-
Présence de deux éléments employés ensemble, chacun des éléments fait partie du tout, comme par exemple sLARE avec LASIDORE.
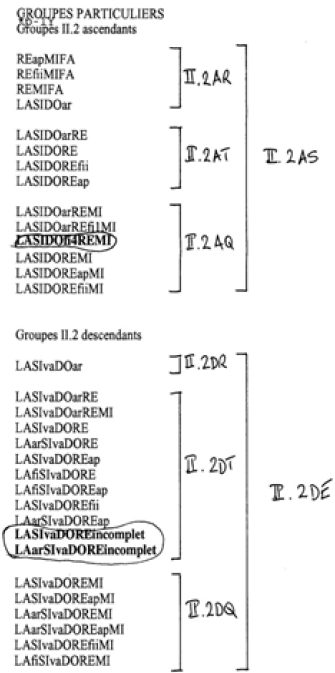
La deuxième étape regroupe les différentes formes de chaque espèce d’intervalle, harmonise la représentation des cordes et des arrêts sur DO, assimile, d’une part, la corde RE à l’intervalle relatif, et, d’autre part, la troisième espèce à la première espèce, quand elle est utilisée avec cette dernière (Figure 7). Voici comme exemple deux versets traduits selon les deux niveaux de regroupement :
C’est le cas le plus simple; en voici un autre plus complexe :
Figure 7
Exemple des 2 niveaux de regroupement
Nous avons analysé la fréquence, le lexique relatif (l’environnement) ainsi que les segments répétés de ces nouveaux constituants (2 niveaux de regroupements) de la phrase. Quelques exemples de ces analyses sont présentés dans les tableaux 3, 4, 5, 6.
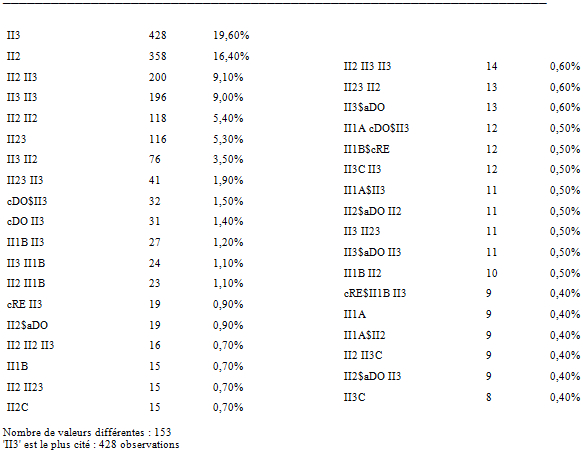
L’analyse de ces regroupements nous a permis dans un premier temps, à partir de l’analyse du tableau de fréquence des intervalles des deux niveaux de regroupement, de relever les configurations principales, c’est-à-dire les intervalles de base du mode (ceux employés le plus fréquemment, II3B, II2A, II3A, etc.), les configurations de second choix (II2B, II1B, II23B, etc.), ainsi que les configurations qui sont d’un usage occasionnel (II1A, II2C, II3C, etc.) (Tableau 3).
D’autre part, l’analyse des tableaux constitués par le lexique relatif de chacun des intervalles ainsi que des segments répétés des intervalles des deux niveaux de regroupement nous a permis de décrire également la succession (linéaire) des intervalles. Par exemple le tableau du lexique relatif de l’intervalle II3B nous montre que cet intervalle est le plus souvent précédé de l’intervalle II2A et suivi de II3B; il est aussi très fréquemment précédé de II3B et suivi de II3 A; ainsi que très fréquemment précédé de II3A et II2B.
La fréquence des segments répétés du regroupement II ainsi que la fréquence des configurations de chaque partie illustrent bien les régularités au niveau de la succession des intervalles.
Tableau 3
Fréquences des intervalles du regroupement I

Tableau 4
Lexiques relatifs du mot « II3B » (878 occ.)
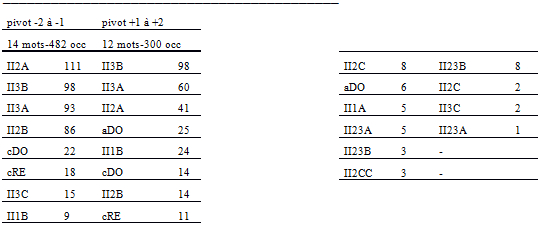
Tableau 5
Segments répétés des intervalles du regroupement I

Tableau 6
Fréquence des suites d’intervalles (regroupement II) par partie de texte
C’est par le regroupement du deuxième niveau que nous obtenons les schémas modaux, nous revenons ensuite au premier niveau pour les affiner.
Ces résultats dessinent deux schémas modaux encore à l’étude, mais qui se résument bien par ceux des versets 264 et 289 (exemples ci-dessus) :
Conclusion
Cette première étape de l’analyse des charagan, nous a donné des résultats intéressants qui permettent de décrire le système modal des charagan par les éléments suivants : la liste des intervalles caractérisant la quatrième voix des charagan (lexique à haute fréquence); la liste des variations modales possibles dans cette voix (lexique à fréquence basse); la description d’une 3e espèce d’intervalle par la description des sauts, arrêts et cordes; l’établissement du cadre dynamique du mode en décrivant aussi (contrairement à la tradition) toutes les variations possibles; les différences d’emploi des éléments du lexique selon les versions.
Nous avons maintenant une première ébauche de la structure minimale dynamique de ce mode par l’étude des regroupements. Aussi les analyses statistiques effectuées à la fois pour l’ensemble du corpus ainsi que pour chaque version ont permis une analyse subtile des variations dans ce mode qui tient compte des versions, tout en permettant des généralisations bien fondées.
L’étape suivante de la recherche est de poursuivre l’analyse structurelle de la phrase musicale à partir du lexique et des deux niveaux de regroupements afin d’affiner la dynamique des structures modales à la fois sur les axes syntagmatiques et paradigmatiques, et pouvoir ainsi décrire les permutations de syntagmes possibles des unités de premier niveau (regroupement II) : régularités, variantes, des constituants minimaux de ces phrases musicales pour tous les chants, ou, mieux encore, pour chacun des groupes mélodiques.
Parties annexes
Notes
-
[1]
Charagan en arménien occidental et charakan en arménien oriental. Les deux graphies existent. Nous avons choisi la variante occidentale puisque c’est la langue que nous utilisons.
-
[2]
Voici un lien pour écouter des charagan : http://akn-chant.org (les pages des disques du menu).
-
[3]
Ce répertoire est utilisé par les Arméniens, dont la grande majorité se reconnaît comme appartenant à l’Église d’Arménie qui fait partie des Églises dites « Orthodoxes orientaux ». Celles-ci sont actuellement au nombre de six : l’Église d’Arménie, l’Église « ancienne » syriaque, l’Église des Coptes, l’Église d’Éthiopie, l’Église d’Érythrée, l’Église Malabar à Kerala, Inde de sud-ouest. Leur particularité principale est qu’elles admettent seules les premiers trois conciles des Pères de l’Église (Nicée en 325, Constantinople en 381 et Éphèse en 431). Elles n’acceptent pas les décisions du concile de Chalcédoine tenu en 451.
-
[4]
Les neumes (Khaz en arménien) sont des signes avec un sens musical attribué, placés au-dessus du texte, elles sont utilisées pour renforcer la mémoire du chantre ayant appris la musique par transmission orale. Voir Atayan, R. 1999, The Armenian Neume System of Notation.
-
[5]
Une notation neumatique a été utilisée à partir du 9e-10e siècles. Une nouvelle notation spécifique a été créée au début du 19e siècle pour transcrire ce répertoire. Cette dernière est encore en usage parmi les chantres traditionnels. Depuis plusieurs décennies les transcriptions en notation occidentale sont également utilisées par les chorales de type occidental.
-
[6]
Des systèmes d’octoechos sont bien entendu utilisés par d’autres traditions, notamment grégorienne et byzantine, avec un fonctionnement liturgique et un contenu modal différents. Les modes d’une tradition ne correspondent pas nécessairement aux modes d’une autre tradition. Pour en savoir plus sur l’octoechos arménien, cf. le site web suivant : http://akn-chant.org/fr/modes
-
[7]
Les sources de ce répertoire sont à la fois la tradition orale et les transcriptions faites au cours du 19e siècle de la bouche des tenants de la tradition du chant liturgique, aussi bien des ecclésiastiques que des maîtres-chantes ou chantres laïques.
-
[8]
Les rapports entre les degrés consécutifs.
-
[9]
Le logiciel Sphinx Lexica est un logiciel d’analyse de données textuelles développé par Yves Baulac et Jean Moscarola (France) www.lesphinx-developpement.fr. Il fait partie des logiciels d’ADT développés dans le cadre du réseau européen d’analyses statistiques de données textuelles (JADT). Il permet de faire de l’analyse de contenu ainsi que des analyses textuelles de type qualitatives et quantitatives.
-
[10]
L’Analyse factorielle de Correspondance est une analyse statistique multidimensionnelle poussée développée par Jean-Paul Benzécri et al. (1981).
-
[11]
Nous tenons à remercier Jean Moscarola et Yves Baulac de l’entreprise LESPHINX-Développement (concepteurs du logiciel Sphinx) pour leur aide précieuse lors de cette phase de transcription et de conceptualisation des unités d’étude avec Sphinx.
-
[12]
Le lexique relatif étudie l’environnement lexical du mot : les mots qui viennent avant et ceux qui viennent après le mot en question.
-
[13]
Les segments répétés étudient les suites de mots (segments de deux ou plusieurs mots qui se répètent) et leur fréquence.
Bibliographie
- Atayan, R. (1999). [Traduit de l’arménien par Vrej N. Nersessian] The Armenian Neume System of Notation. Richmond: Curzon.
- Barbaud, P. (1971). La musique, discipline scientifique : introduction élémentaire à l’étude des structures musicales — Nouv. Tirage — Paris : Dunod. [Science Poche; no7].
- Baulac, Y., et Moscarola, J. (2000). Le Sphinx Lexica : Manuel de référence. Seynod-France : LeSphinx-Developpement.
- Benzécri, J.-P. et al. (1981). Pratique de l’analyse des données. Linguistique et lexicologie. Paris : Dunod.
- Charnassé, H., et Ducasse, H. (1973). PARIS-Journées d’informatique musicale, Paris, 8-10 octobre 1973. Textes des conférences. Paris : C.D.H.H.-CNRS [Collection Calcul et Sciences humaines].
- Kerovpyan, A (2003). L’oktoechos arménien. Une méthode d’analyse adaptée au répertoire des charakan. Thèse de doctorat, École Pratique des Hautes Études, Paris.
- Wrinkler, G. (1983). The Armenian Night Office II: The unit of Psalmody, Canticles, and Hymns with particular emphasis on the origins and early evolution of Armenia’s hymnography. Revue des Études arméniennes. 17.471-551.
- Wrinkler, G. (1984). The Armenian Night Office I: The Historical Background of the Introductory part of Giserayin zam. Journal of the society for Armenian Studies. 1.93-113.
Liste des figures
Figure 1
Exemple du découpage d’un verset
Figure 2
Extrait du fichier texte dans Sphinx
Figure 3
Analyse factorielle de Correspondance des intervalles selon les versions
Figure 4
AFC sauts par version
Figure 5
AFC du lexique en fonction des trois parties, initiale (com), médiane (dév) et finale
Figure 6
Histogramme du nombre de « Sauts » par « Parties » du texte
Figure 7
Exemple des 2 niveaux de regroupement
Liste des tableaux
Tableau 1
Fréquence des mots dans le Lexique total (extrait)
Tableau 2
Tableau de contingence des sauts par version
Tableau 3
Fréquences des intervalles du regroupement I
Tableau 4
Lexiques relatifs du mot « II3B » (878 occ.)
Tableau 5
Segments répétés des intervalles du regroupement I
Tableau 6
Fréquence des suites d’intervalles (regroupement II) par partie de texte