
Résumés
Résumé
L’alpha de Cronbach est l’indice de consistance interne le plus répandu en sciences de l’éducation. Le but de cet article est d’évaluer la performance de six estimateurs de consistance interne à partir d’une étude de simulation. La simulation porte sur l’alpha de Cronbach, le lambda-2, le lambda-4 et le lambda-6 de Guttman, la plus grande limite inférieure et l’oméga. Quarante-cinq scénarios ont été définis par la taille de l’échantillon, le nombre d’items et la valeur des coefficients de saturation factorielle. Les résultats suggèrent que, dans le cas où l’instrument compte cinq items, l’estimateur à privilégier serait l’oméga. Dans les autres cas, ce serait la grande limite inférieure. L’alpha et le lambda-2 sont systématiquement les deux estimateurs qui sous-estiment le plus la valeur de la consistance interne et devraient être évités. Le lambda-6 serait le meilleur estimateur offert par SPSS. Dans l’ensemble, cette étude offre un rationnel empirique pour un changement de pratique dans les recherches en éducation.
Mots-clés :
- fidélité,
- consistance interne,
- mesure,
- simulation,
- alpha de Cronbach
Abstract
Cronbach’s alpha is the most common internal consistency index in educational sciences. The goal of this article is to assess the performance of six internal consistency estimators by conducting a simulation study. The simulation focuses on Cronbach’s alpha, lambda-2, Guttman’s lambda-4 and lambda-6, the greatest lower bound (GLB) and the omega. Forty-five scenarios were defined by the sample size, the number of items and the value of factorial saturation coefficients. The results suggest that if the instrument has five items, the preferred estimator would be omega. In other cases, it would be the GLB. Alpha and lambda-2 are systematically the two estimators that most underestimate the value of internal consistency and should be avoided. Lambda-6 would be the best estimator offered by SPSS. Overall, this study offers an empirical rationale for a change of practice in educational research.
Keywords:
- fidelity,
- internal consistency,
- measure,
- simulation,
- Cronbach’s alpha
Resumen
El alfa de Cronbach es el índice de consistencia interna más extendido en ciencias de la educación. El objetivo de este artículo es evaluar el rendimiento de seis estimadores de consistencia interna a partir de un estudio de simulación. La simulación trata del alfa de Cronbach, el lambda-2, el lambda-4 y el lambda-6 de Guttman, el mayor límite inferior y el omega. Se definieron cuarenta y cinco situaciones según el tamaño de la muestra, el número de ítems y el valor de los coeficientes de saturación factorial. Los resultados sugieren que, en el caso en que el instrumento cuente con cinco ítems, el estimador a privilegiar sería el omega. En los otros casos, sería el mayor límite inferior. El alfa y el lambda-2 son sistemáticamente los dos estimadores que más subestiman el valor de la consistencia interna y deberían ser evitados. El lambda-6 sería el mejor estimador ofrecido por el programa informático SPSS. De manera general, nuestro estudio ofrece una justificación empírica para un cambio de prácticas en las investigaciones en educación.
Palabras clave:
- fidelidad,
- consistencia interna,
- medida,
- simulación,
- alfa de Cronbach
Corps de l’article
1. Introduction et problématique
Selon la théorie classique des tests, le score total à un test (X) ne représente jamais le score vrai (V, la quantité exacte que l’on tente de mesurer) et est toujours influencé par une part d’erreur de mesure (ε, Streiner, 2003) :
L’erreur se divise elle-même en deux composantes : l’erreur aléatoire, distribuée normalement et dont la moyenne est 0, et l’erreur systématique, dont la distribution est asymétrique et dont la moyenne diffère de 0. Si l’erreur aléatoire n’introduit pas de biais systématique dans la mesure, l’erreur systématique, lorsqu’elle diffère de 0, fera en sorte que le score observé surestimera ou sous-estimera systématiquement le score vrai.
Les estimateurs de fidélité permettent d’estimer à quel point le score observé se rapproche du score vrai. Par exemple, les indices de consistance interne comme l’alpha de Cronbach sont des mesures de fidélité qui font référence au degré auquel les items mesurent le même concept (Cronbach, 1951). Dans les recherches en éducation, le coefficient alpha est en ce moment le plus couramment utilisé pour évaluer la consistance interne des scores à un test (Cho, 2016 ; Sijtsma, 2009a). Son omniprésence dans les écrits scientifiques, en particulier en éducation, est quelque peu étonnante puisque cet indice ne semble pas constituer le meilleur estimateur de la fidélité réelle, une situation qui serait connue depuis au moins la fin des années soixante-dix (Callender et Osburn, 1979 ; Sijtsma, 2009a).
Paradoxalement, l’alpha est sans contredit l’une des statistiques les plus critiquées et les plus mal comprises en sciences sociales (Cho, 2016 ; Cortina, 1993 ; Green et Yang, 2009 ; Sijtsma, 2009a). Cronbach évoque d’ailleurs lui-même le fait que les nombreux⋅ses chercheur·se·s ayant utilisé l’alpha n’ont pas nécessairement lu et compris son texte original (Cronbach et Shavelson, 2004). D’ailleurs, plusieurs articles portant sur le coefficient alpha et ses limites se retrouvent dans la revue Psychometrika, une publication spécialisée s’adressant à des spécialistes de la psychométrie, et non à l’ensemble des chercheur⋅se⋅s des sciences sociales ou des sciences de l’éducation. De nombreux expert⋅e⋅s se méfient de l’usage du coefficient alpha, non seulement en tant que mesure de la consistance interne, mais aussi comme mesure de la fidélité (Bentler, 2009 ; Cho et Kim, 2015 ; Davenport, Davison, Liou et Love, 2015 ; Green et Yang, 2009 ; Revelle et Zinbarg, 2009 ; Sijtsma, 2009a). On affirme d’abord que les conditions qui sous-tendent son utilisation (tau-équivalence ou items mesurant un seul facteur et ayant la même variance, unidimensionnalité et non-corrélation des erreurs, entre autres) sont très rarement satisfaites en pratique (Green et Yang, 2009). De plus, en tant que borne inférieure de la fidélité réelle du score à un test, le coefficient alpha sous-estime largement et systématiquement cette valeur (Callender et Osburn, 1979 ; Schmitt, 1996 ; Sijtsma, 2009a). Ceci peut avoir d’importantes conséquences empiriques et cliniques (Green et Yang, 2009 ; Henson, 2001). Au plan empirique, les chercheur⋅se⋅s en recherche appliquée pourraient rejeter un instrument psychométrique en pensant qu’il ne mène pas à des scores fidèles. De même, lorsque les erreurs sont corrélées (ce qui est souvent le cas), le coefficient alpha serait surestimé (Green et Yang, 2009). Un⋅e chercheur⋅se pourrait donc conserver un instrument en pensant qu’elle ou il produit des scores fidèles, alors que ce n’est pas le cas. Au plan clinique, la première situation peut faire en sorte de limiter les choix d’instruments disponibles pour les clinicien⋅ne⋅s ; la deuxième situation peut entrainer l’utilisation d’instruments qui produisent en réalité des scores non fidèles, ce qui peut mener à un dépistage ou à un diagnostic erroné, à la constatation de faux progrès, à l’admission ou au rejet d’un candidat ou d’un patient, etc.
D’autres coefficients de fidélité moins biaisés existent et permettent de contourner les difficultés rencontrées avec l’alpha (Green et Yang, 2009 ; Osburn, 2000 ; Revelle et Zinbarg, 2009 ; Sijtsma, 2009a ; Trizano-Hermosilla et Alvarado, 2016). Par exemple, Guttman (1945) a présenté un modèle comprenant une série de six coefficients de fidélité, de lambda-1 à lambda-6. Le lambda-3 s’avère mathématiquement équivalent à l’alpha (Callender et Osburn, 1979 ; Cho et Kim, 2015). Bien que le modèle de Guttman et, donc, le lambda-3 aient été avancés avant l’alpha, proposé en 1951, la communauté scientifique a crédité Cronbach, bien malgré lui, en associant son nom à l’alpha (Cho et Kim, 2015 ; Cronbach et Shavelson, 2004). En effet, quoique mathématiquement équivalent, le coefficient alpha était plus facile à calculer que le lambda-3, à une époque où les calculs à la main dominaient (Cho, 2016 ; Cho et Kim, 2015). Le lambda-2 de Guttman était quant à lui supérieur à l’alpha, mais requérait aussi une opération mathématique élaborée (Cho et Kim, 2015). D’autres coefficients ont par la suite été avancés, dont la plus grande limite inférieure (en anglais greatest lower bound ou grande limite inférieure ; Woodhouse et Jackson, 1977), le coefficient oméga (McDonald, 1978), le coefficient bêta (Revelle, 1979) et la série de coefficients mu (0 à 6), le coefficient mu 1 étant équivalent au lambda-2 (Ten Berge et Zegers, 1978). Enfin, plus récemment, la modélisation par équations structurelles a aussi été mise à contribution pour estimer la fidélité (Bentler, 2009 ; Cho et Kim, 2015 ; Green et Yang, 2009).
L’existence de plusieurs coefficients dont la performance est supérieure à celle de l’alpha et le fait que Cronbach lui-même ait reconnu que l’alpha n’était qu’une mesure de fidélité parmi d’autres (Cronbach et Shavelson, 2004) rendent pertinent le questionnement sur ce qui entraine cette persistante popularité de l’alpha. Quelques explications sont mises de l’avant, comme l’habitude et l’accessibilité (Cho, 2016 ; Revelle et Zinbarg, 2009 ; Sijtsma, 2009a, 2009b ; Trizano-Hermosilla et Alvarado, 2016). En effet, l’alpha est très connu et peut être calculé aisément à partir d’IBM SPSS, le logiciel le plus répandu dans les facultés d’éducation. Cho (2016) compare quant à lui l’alpha à une marque de commerce qui s’est taillé une place et qui conserve une part importante du marché.
Cet article cherche à évaluer, à partir de simulations, la performance du coefficient alpha et de cinq autres estimateurs de consistance interne (lambda-2, lambda-4max, lambda-6, plus grande limite inférieure et oméga) en fonction d’une variété de scénarios quant à la taille de l’échantillon, au nombre d’items et à la valeur des coefficients de saturation factorielle. Plus précisément, nous porterons attention à deux caractéristiques de ces indices : leur valeur moyenne et leur variance, la stabilité constituant un autre trait désirable d’un bon indice de fidélité.
2. Contexte théorique
2.1 Fidélité et consistance interne
Comme nous l’avons mentionné au début de ce texte, selon la théorie classique des tests, le score total à un test (X) est constitué d’une part du score réel (V) et, d’autre part, de l’erreur de mesure (ε) :
Les mesures de fidélité cherchent à évaluer à quel point une mesure est entachée d’erreur ou, autrement dit, à quel point le score total se rapproche du score réel. Streiner, Norman et Cairney (2015, p. 9) proposent la définition générale suivante de la fidélité : « le degré auquel l’évaluation d’individus à différentes occasions, ou par des observateurs différents, ou par des tests similaires ou parallèles, produit les mêmes résultats ou des résultats similaires » (traduction libre). La fidélité (rX) peut donc être exprimée soit comme la corrélation entre le score observé et le score vrai (rXV),
soit comme le rapport entre la variance du score vrai (σV2) et la variance du score au test (σX2) :
Il existe plusieurs indices pour estimer la fidélité. Les experts en psychométrie considèrent l’alpha de Cronbach comme une estimation de la consistance interne des items d’un instrument. Selon Cronbach (1951), la consistance interne fait référence à l’homogénéité des items, c’est-à-dire à quel point les items du test sont similaires ou, autrement dit, à quel point ils mesurent la même dimension d’un construit (unidimensionnalité). Or, plusieurs chercheur⋅se⋅s ont démontré de façon robuste qu’une valeur élevée de l’alpha ne se traduit pas nécessairement en une homogénéité ou en une unidimensionnalité des items. En revanche, ces chercheur⋅se⋅s acceptent plutôt que la consistance interne représente à quel point les items d’une échelle sont étroitement reliés ou corrélés (Cho et Kim, 2015 ; Cortina, 1993 ; Schmitt, 1996).
2.2 Alpha de Cronbach
On fait souvent référence à l’alpha comme à une estimation de la fidélité telle que Cronbach (1951) l’avait décrite :
(Où k est le nombre d’items).
Toutefois, six ans plus tôt, Guttman (1945) avait plutôt conçu l’alpha (qui correspond à son lambda-3) comme une limite inférieure à la fidélité réelle étant donné sa valeur normalement plus petite que lambda-2 lorsque certaines conditions, dont la tau-équivalence, n’étaient pas réunies. Pour sa part, Cortina (1993) avance que la valeur de l’alpha est plus exacte lorsque trois conditions sont satisfaites : 1) l’unidimensionnalité (les items mesurent un seul facteur), 2) la tau-équivalence et 3) les erreurs d’items non corrélées. Toutefois, en pratique, ces conditions (surtout celle de tau-équivalence) sont rarement remplies, ce qui mène à une sous-estimation systématique de la fidélité réelle. De plus, la valeur de l’alpha est fortement influencée par le nombre d’items, le nombre de dimensions orthogonales et la moyenne des corrélations entre items (Cortina, 1993). Par conséquent, d’autres indices de fidélité ont été proposés.
2.3 Lambda de Guttman
Guttman (1945) a dérivé six coefficients (L1 – L6) qu’il décrit comme des limites inférieures à la fidélité. L’efficacité de chacun de ces indices à mesurer la fidélité réelle est influencée par différentes conditions. Le lambda-1 est le premier indice calculé et sous-estime largement la fidélité réelle. Il n’est pas utilisé comme estimateur de fidélité, mais constitue plutôt une étape intermédiaire vers le calcul des autres indices de Guttman.
(Où ![]() est la variance de l’item k, et
est la variance de l’item k, et ![]() est la variance du score dérivé des items.)
est la variance du score dérivé des items.)
Le lambda-2 est toujours plus élevé que le lambda-1 et est supérieur ou égal au lambda-3 (donc à l’alpha de Cronbach) en cas d’indépendance entre les erreurs des items.
(Où C2 est la somme des carrés de la covariance entre les items.)
Comme déjà mentionné, le lambda-3 est l’équivalent de l’alpha de Cronbach et est toujours plus élevé que le lambda-1. Le lambda-4 représente quant à lui un coefficient de bissection. Comme il y a plusieurs façons de diviser un test en deux, la valeur de lambda-4 représente la moyenne de toutes les bissections possibles.
(Où s2a et s2b sont les variances des deux ensembles d’items créés par la bissection.)
Le lambda-5, quant à lui, est efficace lorsqu’il existe une covariance élevée entre un item et les autres, lesquels, en retour, n’ont pas une covariance élevée entre eux, ce qui n’est pas désirable dans le cas d’une échelle psychométrique ou édumétrique.
(Où ![]() est la somme des carrés des covariances d’un item en particulier avec les k - 1 autres.)
est la somme des carrés des covariances d’un item en particulier avec les k - 1 autres.)
Finalement, le lambda-6 reflète la proportion de variance moyenne de chaque item expliquée en régressant cet item sur tous les autres items, c’est-à-dire la corrélation multiple au carré.
(Où ![]() est la variance de l’estimateur de l’item i provenant de la régression linéaire sur les autres items.)
est la variance de l’estimateur de l’item i provenant de la régression linéaire sur les autres items.)
Les deux lambdas de Guttman qui disposent du plus grand appui empirique quant à leur capacité à estimer la fidélité réelle sont le lambda-2 (Tang et Cui, 2012) et le lambda-4 (Callender et Osburn, 1979 ; Hunt et Bentler, 2015 ; Osburn, 2000), mais il faut noter que certains des indices, le lambda-6 par exemple, n’ont fait l’objet que de peu d’études.
2.4 Plus grande limite inférieure (greatest lower bound)
En 1977, Jackson et Agunwamba se sont intéressés aux indices de Guttman et ont démontré mathématiquement que la valeur maximale du coefficient de bissection lambda-4 (au lieu de la valeur moyenne suggérée par Guttman) est d’habitude la valeur la plus élevée de ces indices et, donc, le meilleur estimateur de la fidélité réelle puisque sa valeur ne peut pas dépasser la valeur de cette dernière (il s’agit d’une limite inférieure). Woodhouse et Jackson (1977) décrivent ensuite comment dériver la grande limite inférieure :
(Où tr(Ce) est la trace de la matrice de covariance des erreurs interitems.)
Dans la majorité des cas, la plus grande limite inférieure est en fait le lambda-4 et l’article démontre la supériorité de ce coefficient sur le lambda-2 et le lambda-3 (l’alpha de Cronbach). Plus récemment, Sijtsma (2009a) a également confirmé que la plus grande limite inférieure constitue un meilleur estimateur de la fidélité que l’alpha. Par contre, Shapiro et Ten Berge (2000) ainsi que Ten Berge et Sočan (2004) ont établi que la plus grande limite inférieure peut surestimer la valeur de la fidélité réelle lorsque calculée à partir de petits échantillons (moins de quelques milliers d’observations) si le nombre de variables est élevé.
2.5 Oméga
De son côté, McDonald (1978, 1985), partant d’une approche d’analyse factorielle, propose le coefficient de fidélité oméga, qui a l’avantage de tenir compte de la force de l’association entre les items et un construit, d’une part, ainsi qu’entre les items et l’erreur de mesure, d’autre part. Par conséquent, selon cet auteur, l’oméga permet une estimation plus exacte de la vraie fidélité de l’échelle. Ce coefficient fonctionne bien même lorsque la condition de tau-équivalence n’est pas respectée et McDonald (1978) démontre mathématiquement que l’oméga sera toujours supérieur ou égal à l’alpha. Pour l’essentiel, l’oméga est le carré de la corrélation entre le score au test et le score au domaine :
(Où q est le nombre d’items du domaine, j est le nombre d’items d’une première moitié de l’échelle, k est le nombre d’items de l’autre moitié, l est le nombre de facteurs, f le coefficient de saturation de l’item et u, son unicité.)
Plusieurs études de simulation justifient l’utilisation de l’oméga de McDonald comme un indice de fidélité alternatif à l’alpha. En effet, dans l’étude de Revelle et Zinbarg (2009), l’oméga de McDonald a été meilleur que 12 autres indices. De plus, deux études en 2016 (Kelley et Pornprasertmanit, 2015 ; Trizano-Hermosilla et Alvarado, 2016) ont aussi démontré la supériorité de ce coefficient. D’autres indices de fidélité ont été proposés, le Beta de Revelle (1979), les indices de Ten Berge et Zegers (μ0, μ1, μ2… ; 1978) ainsi que, plus récemment, des méthodes qui relèvent de la modélisation par équations structurelles (Cho et Kim, 2015 ; Green et Yang, 2009). Toutefois, l’explication de chacune de ces méthodes dépasse les buts de cet article et elles ne seront pas testées dans notre simulation.
Enfin, cette étude a pour objectifs d’enrichir les résultats de certaines études antérieures (Callender et Osburn, 1979 ; Revelle et Zinbarg, 2009 ; Woodhouse et Jackson, 1977) à l’intention des chercheurs francophones en éducation tout en émettant des considérations supplémentaires sur la variance, absente des études antérieures. Outre cette attention portée à la variance, l’apport original de cet article découle de la variété des scénarios explorés, notamment en ce qui a trait à la variation de la valeur des coefficients de saturation factorielle.
3. Méthodologie
La recherche rapportée ici porte sur une simulation qui vise à comparer la performance de six indices de consistance interne, soit l’alpha de Cronbach (Cronbach, 1951), les lambda-2, lambda-4max et lambda-6 de Guttman (Guttman, 1945), la plus grande limite inférieure (Ten Berge et Sočan, 2004) et l’oméga de McDonald (McDonald, 1978, 1985). Ces indices sont comparés selon 45 conditions définies par trois paramètres : le nombre d’observations (50, 100, 200, 500 ou 1 000), le nombre d’items (5, 10 ou 20) et la valeur moyenne des coefficients de saturation factorielle (0,35, 0,50 ou 0,80). Notons que pour cette dernière condition, les coefficients de saturation sont extraits d’une distribution normale tronquée à 0 et 1 et dont la moyenne correspond à chacune des trois conditions expérimentales. Nous avons fixé le nombre de réplications à 2 000. La simulation a été effectuée avec le logiciel R (la syntaxe est fournie en annexe).
Les packages requis pour la simulation sont les suivants : mvtnorm, Matrix, Rcsdp, psych, GPArotation, e107, truncnorm et plyr. Le moteur de simulation est fonction du nombre de réplications, du nombre d’observations, du nombre d’items et de la valeur des coefficients de saturation factorielle. Dans un premier temps, une matrice de la variance de l’erreur de mesure est créée. Il s’agit d’une matrice de dimension k x k (k étant le nombre d’items), où la diagonale contient la valeur 1 - l2i (li étant la valeur du coefficient de saturation factorielle extrait pour l’item i à l’aide de la commande rtruncnorm). Dans un deuxième temps, la matrice de la variance attribuable au facteur latent est produite. Il s’agit d’une autre matrice k x k, sur la diagonale de laquelle on retrouve le carré des coefficients de saturation (l2i). La matrice des variances observées est obtenue en additionnant ces deux matrices et est donc fixée à 1 pour tous les termes (1 - l2i + l2i).
La matrice de variance-covariance des items est obtenue par la simulation d’une distribution de Wishart à k + 1 degrés de liberté (k étant le nombre d’items) qui est fonction du nombre d’observations et de la matrice de la variance de l’erreur. Le moteur de simulation est ensuite appelé à calculer l’alpha de Cronbach, les lambda-2, lambda-4max et lambda-6 de Guttman, la plus grande limite inférieure et l’oméga de McDonald. Ces calculs sont répétés 2 000 fois, les données simulées étant obtenues sous forme d’une matrice de variance-covariance fonction du nombre d’observations et de la matrice des variances observées.
Les indicateurs de performance des estimateurs de fidélité rapportés ici sont leur valeur moyenne sur l’ensemble des réplications, la variance et l’intervalle de confiance de 95 % associé à ces deux statistiques. Le moteur se termine avec l’identification des 45 (5 x 3 x 3) conditions expérimentales à partir du nombre d’observations, du nombre d’items et de la valeur des coefficients de saturation factorielle. Le calcul d’intervalles de confiance de 95 % pour les moyennes et les variances permet de déterminer si les indices diffèrent de façon statistiquement significative quant à ces paramètres.
4. Résultats
4.1 Quels sont les estimateurs dont la valeur est la plus élevée ?
Selon les résultats de l’étude de simulation, la plus grande limite inférieure produit l’estimation la plus élevée de la fidélité dans 30 cas sur 45 (67 %). Les seuls cas où la plus grande limite inférieure est supplantée (15/45, 33 %) sont ceux où l’échelle évaluée compte peu d’items (5 dans notre étude) et dont les saturations sont faibles (0,35) ou modérées (0,50). Dans cette situation, c’est plutôt l’oméga qui s’approche le plus de la fidélité réelle. Dans les cas (5/45, 11 %) où il y a peu d’items et où la valeur des coefficients de saturation est élevée (0,80), ces deux indices sont équivalents. À l’opposé, l’alpha de Cronbach et le lambda-2 de Guttman sous-estiment systématiquement et significativement la fidélité réelle, et ce, dans tous les scénarios simulés. L’alpha de Cronbach est le second pire estimateur dans 100 % des cas.
Les facteurs qui influencent le plus la valeur des indices de fidélité sont le nombre d’items et la valeur des coefficients de saturation. La valeur de la fidélité estimée augmente considérablement lorsque le nombre d’items passe de cinq à dix, alors que les faibles coefficients de saturation affectent négativement la valeur estimée, surtout pour les estimateurs les moins efficaces comme l’alpha et le lambda-2. Parmi les indices disponibles sur SPSS, c’est le lambda-6 qui obtient les meilleurs résultats. Dans les tableaux qui suivent, les différentes couleurs sur une même ligne identifient les valeurs significativement différentes (les intervalles de confiance ne se chevauchent pas) alors que des valeurs surlignées de la même couleur sur une même ligne ne diffèrent pas significativement au seuil de 0,05. Le vert représente les valeurs les plus élevées alors que l’orange désigne les indices dont les valeurs sont les plus basses et inférieures au seuil recommandé de 0,80 dans le cas des valeurs moyennes.
Tableau 1
Valeur moyenne des six indices de fidélité
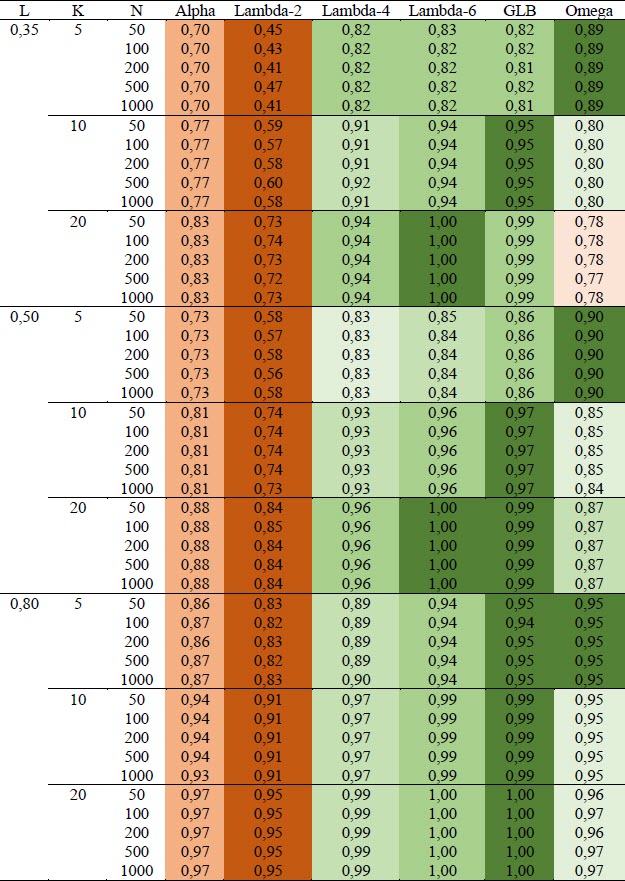
Tableau 2
Variance des six estimateurs de fidélité sur 2 000 itérations

4.2 Quels sont les estimateurs les plus stables ?
La stabilité (faible variance) d’une statistique est une caractéristique importante en ce qu’elle suggère que sa valeur reflète surtout du signal, par opposition au bruit (noise). Dans le cas de cette étude de simulation, les estimateurs de fidélité démontrant la plus faible variance sur les 2 000 échantillons simulés varient selon les conditions expérimentales. Dans le scénario le plus favorable (20 items et coefficients de saturation élevés, 0,80 : 5/45, 11 %), les variances des six indices sont très faibles et statistiquement équivalentes. Dans les cas où l’échelle analysée ne compte que cinq items (15/45, 33 %), c’est l’oméga qui affiche systématiquement la plus faible variance. L’alpha s’avère l’estimateur le plus stable lorsque les coefficients de saturation factorielle sont faibles (0,350). Dans les autres cas, les résultats sont partagés. À l’opposé, c’est le lambda-2 qui démontre systématiquement la variance la plus élevée.
5. Discussion
Les résultats obtenus sont cohérents avec d’autres études. Par exemple, la supériorité de l’oméga pour estimer la fidélité de scores tirés d’échelles constituées de peu d’items correspond aux observations de Revelle et Zinbarg (2009). Selon ces auteur⋅e⋅s, dans une étude portant sur 13 indices de fidélité calculés sur neuf bases de données provenant de l’administration de tests comptant de quatre à huit items, l’oméga a surpassé les autres indices dans sept cas sur neuf (échelles de quatre ou de six items). De façon similaire, nos résultats établissent la supériorité de l’oméga pour les scénarios où l’instrument compterait cinq items. Dans les deux cas restants de l’étude de Revelle et Zinbarg (six et huit items), c’est le lambda-4 qui donnait la meilleure valeur. Une variante du lambda-4 (MSPLIT) avait également surpassé l’alpha et le lambda-2 dans l’étude de Callender et Osburn (1979), portant sur une échelle de 10 items cette fois. Dans ce cas, nos résultats corroborent la supériorité du lambda-4 sur les deux autres indices, mais pas celle du lambda-2 sur l’alpha. De plus, comme dans l’étude de Woodhouse et Jackson (1977), la plus grande limite inférieure constitue ici un estimateur systématiquement supérieur ou égal au lambda-4, et toujours plus élevé que le lambda-2 et l’alpha. Par contre, il est possible qu’il s’agisse d’un artéfact du biais d’échantillonnage documenté par Shapiro et Ten Berge (2000) ainsi que Ten Berge et Sočan (2004).
Un ajout important de notre étude est la considération de la variance de ces différents indices. Nous observons que selon les scénarios, il peut y avoir des différences importantes de variance. Par exemple, si l’oméga présente la variance la plus faible pour les scénarios où le score est dérivé de cinq items seulement, il obtient la variance la plus élevée dans les cas où il y a 20 items et où la valeur des coefficients de saturation est modérée (0,50).
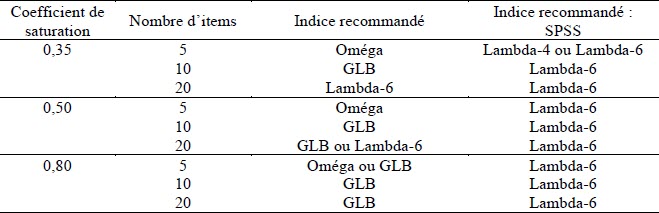
Sur la base de ces résultats, en tenant compte à la fois de la valeur moyenne des estimateurs de fidélité et de leur variance, nous formulons, dans le tableau 3, des recommandations quant à l’utilisation des différents indices selon les scénarios. Ainsi, dans le cas où le nombre d’items composant le test est faible (de l’ordre de cinq items), nos résultats suggèrent que l’utilisation de l’oméga serait indiquée. Dans les autres scénarios, le recours à la plus grande limite inférieure serait préférable, mais vu ses limites (Shapiro et Ten Berge, 2000 ; Ten Berge et Sočan, 2004), il serait probablement plus prudent de recourir à l’oméga ou au lambda-6. Si SPSS constitue la seule option en matière de logiciel d’analyse, le lambda-6 de Guttman constitue une solution plus avantageuse que l’alpha de Cronbach.
Tableau 3
Indice de fidélité recommandé selon les conditions expérimentales
6. Conclusion
Avec cet article, nous voulions comparer la performance de six estimateurs de la consistance interne pour évaluer la fidélité des scores à un instrument psychométrique. À la suite d’écrits plus ou moins récents retrouvés dans des périodiques anglo-saxons, nous soupçonnions que l’indice le plus utilisé en sciences de l’éducation, l’alpha de Cronbach, serait en fait l’un des moins efficaces. C’est ce que nos résultats ont corroboré : l’alpha et le lambda-2 sous-estiment systématiquement et significativement la fidélité dans tous les scénarios testés. Les meilleurs indices seraient en fait l’oméga s’il y a peu d’items, et la plus grande limite inférieure ou le lambda-6 dans les autres cas.
Notre étude se démarque des écrits antérieurs de deux façons. D’abord, en plus de la valeur moyenne de la fidélité de consistance interne estimée par chaque indice, nous avons porté attention à sa variance. Comme la stabilité de l’estimateur constitue une caractéristique désirable, nous disposions d’un autre critère d’évaluation. Enfin, nous avons fait varier l’ampleur des coefficients de saturation factorielle, ce qui a permis de constater deux choses. Premièrement, la variance de tous les estimateurs est plus ou moins équivalente et négligeable lorsque les coefficients de saturation et le nombre d’items sont simultanément élevés. Deuxièmement, l’impact des coefficients de saturation sur la valeur des estimateurs de fidélité semble moindre que celui du nombre d’items.
Notre étude compte évidemment un certain nombre de limites, comme le choix restreint d’estimateurs de fidélité comparés. Les récents développements en psychométrie ont suggéré plusieurs autres méthodes d’estimation de la fidélité réelle, dont des approches basées sur la modélisation par équations structurelles qui n’ont pas été abordées ici. Il serait intéressant de voir comment ces nouvelles méthodes se comparent aux approches plus classiques. De plus, le fait que les coefficients de saturation aient été simulés pour être d’un même ordre de grandeur correspond à une situation théorique fréquemment observée en pratique, mais pas toujours : par exemple, le développement et la validation de nouveaux tests peuvent mener à de grandes disparités entre les coefficients de saturation factorielle des items adéquats et de ceux dont la performance est inadéquate. Des recherches futures devraient tester divers scénarios quant aux valeurs relatives des coefficients de saturation, la présence d’un ou quelques items avec des coefficients très faibles parmi un ensemble d’items aux coefficients élevés, par exemple.
Parties annexes
Annexe
Syntaxe R




Bibliographie
- Bentler, P. M. (2009). Alpha, dimension-free, and model-based internal consistency reliability. Psychometrika, 74(1), 137-143.
- Callender, J. C. et Osburn, H. G. (1979). An empirical comparison of coefficient alpha, Guttman’s lambda-2, and MSPLIT maximized split-half reliability estimates. Journal of educational measurement, 16(2), 89-99.
- Cho, E. (2016). Making reliability reliable: A systematic approach to reliability coefficients. Organizational research methods, 19(4), 651-682.
- Cho, E. et Kim, S. (2015). Cronbach’s coefficient alpha: Well known but poorly understood. Organizational research methods, 18(2), 207-230.
- Cortina, J. M. (1993). What is coefficient alpha? An examination of theory and applications. Journal of applied psychology, 78(1), 98-104.
- Cronbach, L. J. (1951). Coefficient alpha and the internal structure of tests. Psychometrika, 16(3), 297-334.
- Cronbach, L. J. et Shavelson, R. J. (2004). My current thoughts on coefficient alpha and successor procedures. Educational and psychological measurement, 64(3), 391-418.
- Davenport, E. C., Davison, M. L., Liou, P.-Y. et Love, Q. U. (2015). Reliability, dimensionality, and internal consistency as defined by Cronbach: Distinct albeit related concepts. Educational measurement: Issues and practice, 34(4), 1-6.
- Green, S. B. et Yang, Y. (2009). Commentary on coefficient alpha: A cautionary tale. Psychometrika, 74(1), 121-135.
- Guttman, L. (1945). A basis for analyzing test-retest reliability. Psychometrika, 10(4), 255-282.
- Henson, R. K. (2001). Understanding internal consistency reliability estimates: A conceptual primer on coefficient alpha. Measurement and evaluation in counseling and development, 34(3), 177-189.
- Hunt, T. D. et Bentler, P. M. (2015). Quantile lower bounds to reliability based on locally optimal splits. Psychometrika, 80(1), 182-195.
- Jackson, P. H. et Agunwamba, C. C. (1977). Lower bounds for the reliability of the total score on a test composed of non-homogeneous items: I: Algebraic lower bounds. Psychometrika, 42(4), 567-578.
- Kelley, K. et Pornprasertmanit, S. (2015). Confidence intervals for population reliability coefficients: Evaluation of methods, recommendations, and software for composite measures. Psychological methods, 21(1), 69-92.
- McDonald, R. P. (1978). Generalizability in factorable domains: “Domain validity and generalizability”. Educational and psychological measurement, 38(1), 75-79.
- McDonald, R. P. (1985). Factor analysis and related methods. Erlbaum.
- Osburn, H. G. (2000). Coefficient Alpha and related internal consistency reliability coefficients. Psychological methods, 5(3), 343-355.
- Revelle, W. (1979). Hierarchical cluster analysis and the internal structure of tests. Multivariate behavioral research, 14(1), 57-74.
- Revelle, W. et Zinbarg, R. E. (2009). Coefficients alpha, beta, omega, and the GLB: Comments on Sijtsma. Psychometrika, 74(1), 145-154.
- Schmitt, N. (1996). Uses and abuses of coefficient Alpha. Psychological assessment, 8(4), 350-353.
- Shapiro, A. et Ten Berge, J. M. F. (2000). The asymptotic bias of minimum trace factor analysis, with applications to the greatest lower bound to reliability. Psychometrika, 65(3), 413-425.
- Sijtsma, K. (2009a). On the use, the misuse, and the very limited usefulness of Cronbach’s alpha. Psychometrika, 74(1), 107-120.
- Sijtsma, K. (2009b). Reliability beyond theory and into practice. Psychometrika, 74(1), 169-173.
- Streiner, D. L. (2003). Starting at the beginning: An introduction to coefficient alpha and internal consistency. Journal of personality assessment, 80(1), 99-103.
- Streiner, D. L., Norman, G. R. et Cairney, J. (2015). Health measurement scales. A practical guide to their development and use (5th édition). Oxford University Press.
- Tang, W. et Cui, Y. (2012, 17 avril). A simulation study for comparing three lower bounds to reliability. Communication présentée à l’AERA Division D: Measurement and research methodology, section 1: Educational measurement, psychometrics, and assessment (1-25).
- Ten Berge, J. M. F. et Sočan, G. (2004). The greatest lower bound to the reliability of a test and the hypothesis of unidimensionality. Psychometrika, 69(4), 613-625.
- Ten Berge, J. M. F. et Zegers, F. E. (1978). A series of lower bounds to the reliability of a test. Psychometrika, 43(4), 575-579.
- Trizano-Hermosilla, I. et Alvarado, J. M. (2016). Best alternatives to Cronbach’s Alpha reliability in realistic conditions: Congeneric and asymmetrical measurements. Frontiers in psychology, 7(769), 1-8.
- Woodhouse, B. et Jackson, P. H. (1977). Lower bounds for the reliability of the total score on a test composed of non-homogeneous items: II: A search procedure to locate the greatest lower bound. Psychometrika, 42(4), 579-591.
Liste des tableaux
Tableau 1
Valeur moyenne des six indices de fidélité
Tableau 2
Variance des six estimateurs de fidélité sur 2 000 itérations
Tableau 3
Indice de fidélité recommandé selon les conditions expérimentales