

Résumés
Résumé
Le présent article décrit une étude de cas multiples qui s’est penchée sur l’interaction des compétences de navigation, d’évaluation et d’intégration au sein d’un processus menant à la compréhension d’informations consultées en ligne, et ce, lors de la réalisation d’une tâche de littératie informationnelle par des lecteur·rices internautes de 6e année. L’étude combine l’entretien direct, la verbalisation de la pensée, l’entretien libre de verbalisation de la compréhension et l’entretien rétrospectif semi-dirigé. Elle permet l’induction d’une mobilisation autorégulée des compétences, en plus de permettre, au départ des convergences et des divergences observées entre les cas, la formulation d’une hypothèse de profils de lecteur·rices internautes.
Mots-clés :
- littératie informationnelle en ligne,
- multimodalité,
- compréhension,
- étude de cas multiples,
- lecteur·rices internautes de 6e année
Abstract
This article describes a multiple case study that investigated the interaction of navigation, evaluation and integration competencies within a process leading to the comprehension of online informations during the realization of an information literacy task by 6th grade readers. In combining direct interviews, think-aloud protocol, free interviews of comprehension verbalization and semi-directed retrospective interviews, this study allows the induction of an autoregulated mobilization of the competencies while learning from multimodal and non-linear informations consulted online. It also leads to the hypothesis of five online reader’s profiles.
Keywords:
- online information literacy,
- multimodality,
- comprehension,
- multiple case study,
- 6th grade online readers
Corps de l’article
Introduction
Alors que les usages du numérique se redéfinissent au rythme de l’innovation technologique, l’activité de lecture évolue et, en ce sens, s’approprier un discours informatif croit en complexité. Le·a lecteur·rice internaute[1], dès le primaire (Coiro et Dobler, 2007; Kiili et al., 2020; Pleau, 2023; Potocki et al., 2020), accomplit des tâches l’incitant à développer une compréhension de contenus informationnels multimodaux (Pleau et Boutin, sous presse) présentés de manière non linéaire (Acerra, 2021) dans des documents aux formes discursives en constant renouvellement.
Allant bien au-delà de ce que peuvent expliquer les conceptualisations traditionnelles de la lecture, s’informer requiert maintenant du·de la lecteur·rice qu’iel navigue une quantité techniquement infinie d’informations sélectionnées, hiérarchisées et mises en évidence par des algorithmes (Claes et Philippette, 2020; Verdi et Le Deuff, 2020). Qu’iel recoure à un moteur de recherche ou à un agent conversationnel pour s’informer, le·a lecteur·rice internaute actualise constamment ses pratiques et développe, au fil de ses navigations et de ses interactions avec l’« infosphère » (Reviglio, 2019; Commission mondiale d’éthique des connaissances scientifiques et des technologies – UNESCO, 2001), des compétences en littératie informationnelle (Kuiper et Volman, 2008; Michelot et Poellhuber, 2019; Simonnot, 2009; Zurkowski, 1974).
Malheureusement, tous·tes les lecteur·rices internautes n’ont pas la possibilité de développer leurs compétences de la même manière. Étudier la compréhension d’informations consultées en ligne amène inévitablement à s’intéresser aux problèmes d’inégalités numériques dénoncés depuis plus de vingt ans (Dewan et Riggins, 2005; Henry, 2007; Mossberger et al., 2003; Norris, 2001; Rallet et Rochelandet, 2004); des problèmes qui mettent en lumière les impacts socioculturels du numérique (Yagoubi, 2020) rattachés, entre autres choses, à l’accès à l’information, à la capacité des individus à faire un usage efficace des outils numériques (Dewan et Riggins, 2005; Henry, 2007; Mossberger et al., 2003; Norris, 2001) et à l’écart entre les pratiques numériques scolaires et extrascolaires (Coiro et al., 2008). Ces inégalités peuvent entraîner des conséquences significatives sur le développement de la compréhension en ligne et sur la réussite scolaire (Coiro et al., 2008; Sunderland-Smith et al., 2003). Les « inforiches » et les « infopauvres », des termes utilisés par certain·es (Rizza, 2006; Yagoubi, 2020) pour décrire cette division, en sont des exemples.
Les préoccupations autour de la compréhension d’informations consultées en ligne sont partagées par plusieurs disciplines scientifiques. En raison de la complexité de cette question, s’y intéresser requiert de considérer une multitude de variables cognitives, sociales, culturelles, technologiques, scolaires et sémiotiques. Il est ainsi nécessaire de convoquer différentes épistémologies se rapportant notamment aux sciences de la communication et de l’information, aux sciences du langage, aux sciences cognitives et aux sciences de l’éducation. Les travaux actuels documentent l’écosystème numérique (Le Crosnier, 2017), la sémiotique de l’information (Lacelle, Boutin et Lebrun, 2017), l’apprentissage (Coiro et Dobler, 2007; Mayer, 2005, 2020, 2017), de même que le processus menant à l’intégration de nouvelles connaissances (Salmerón et al., 2018; Brand-Gruwel et al., 2009; Rouet et Britt, 2011). Tous·tes observent les activités de littératie informationnelle au départ de leur discipline, mais peu croisent les épistémologies pour favoriser l’émergence d’une vision holistique d’une telle compréhension.
Les travaux s’étant penchés sur la question se sont essentiellement intéressés aux lecteur·rices internautes adultes (Brand-Gruwel et al., 2009; Dumouchel et Karsenti, 2017; Le Bigot et Rouet, 2007; Wineberg et al., 2022) ou adolescent·es (Anderson et Jiang, 2018; Coiro et al., 2015; Hämäläinen et al., 2023; Henry, 2007; Macedo-Rouet et al., 2019; OCDE, 2019; Yagoubi, 2020) pour décrire et conceptualiser le processus menant à la compréhension d’informations consultées en ligne. Très peu d’entre elleux ont considéré l’aspect développemental de ce processus. Celleux qui l’ont directement ou indirectement fait ont réalisé des études auprès d’échantillons américains (Chen, 2009; Coiro et Dobler, 2007; Henry, 2007), belges (Wiard et al., 2020), taiwanais (Chen, 2009) et finlandais (Kiili et al., 2020). La revue des écrits scientifiques révélait notamment que les apprenant·es, vers l’âge de 10 à 12 ans, rencontraient des difficultés dans l’évaluation de l’information (Potocki et al., 2020; Eastin et al., 2006). Elle mettait aussi en évidence la complexification, en ligne, du recours aux stratégies d’inférence, de prédiction et d’évaluation des choix de lecture (Coiro et Dobler, 2007), de même que la capacité parfois limitée des apprenant·es à construire un argumentaire à partir d’informations provenant de sources multiples, le tout en recourant au copier-coller et à la paraphrase (Kiili et al., 2020). Ne s’intéressant qu’à des aspects spécifiques du processus, ces études, qui pour la plupart datent de plus d’une décennie, dévoilent un manque de vision globale dans notre connaissance de l’interaction des compétences de navigation, d’évaluation et d’intégration d’informations consultées en ligne par des lecteur·rices internautes du primaire. Elles n’explicitent pas la réalisation, à cet âge, d’une tâche de littératie informationnelle sans que le·a lecteur·rice internaute ne soit contraint·e dans le développement de son parcours de lecture, ce qui limite la transposition de leurs résultats en contexte de classe.
Considérant les attentes de formation des apprenant·es en littératie informationnelle dès leur entrée à l’école (Gouvernement de l’Ontario, 2023), considérant l’importance sociale des compétences rattachées à cette littératie dans la lutte contre la désinformation, considérant le besoin criant de données pouvant supporter l’émergence d’une didactique de la littératie informationnelle numérique et considérant la rare rencontre des épistémologies et des domaines dans l’étude approfondie de la littératie informationnelle, le besoin de recherches se penchant explicitement sur l’articulation des compétences de navigation, d’évaluation et d’intégration d’un point de vue développemental se fait sentir.
Le présent article décrit une étude de cas multiples qui s’est intéressée à l’interaction de ces compétences au sein d’un processus autorégulé menant à la compréhension d’informations consultées en ligne, et ce, lors de la réalisation d’une tâche de littératie informationnelle par des lecteur·rices internautes du primaire. Il présente d’abord les concepts opérationnalisés par l’étude en définissant les informations disponibles en ligne, les tâches scolaires de littératie informationnelle et la compréhension d’informations consultées en ligne. L’article se poursuit par la description du protocole expérimental privilégié pour une étude in situ des navigations de neuf lecteur·rices internautes de 6e année. La combinaison des méthodes verbales et visuelles qui a permis la cueillette de données descriptives et multimodales y est alors présentée. L’article décrit enfin l’analyse des données et leur interprétation, puis s’achève par une discussion autour d’une hypothèse de profils de lecteur·rices internautes.
1. Cadre théorique
1.1. Les informations disponibles en ligne
Lire en ligne implique de porter son attention vers des informations essentiellement multimodales (Lacelle et al., 2017) où les images, le texte et le vidéo interagissent dans un environnement médiatique (Buccellati, 2008; Lim et Toh, 2020) aux complexités interactionnelles. Le sens de ces informations se précise sur la base de leurs caractéristiques intrinsèques, guidant l’internaute dans une sémiotique non linéaire (Gervais et Saemmers, 2011) et une rhétorique orientée par les intentions de communication informationnelle. Abstraite de matérialité et de temporalité, les pratiques d’exploration de ces informations amènent l’internaute vers la consultation d’espaces décloisonnés où l’interaction sociale et la collaboration deviennent outils d’apprentissage (Pleau et al., 2022).
Le wiki (Acerra et al., 2021; Lacelle et al., 2017), le site de vulgarisation scientifique (Reboul-Touré, 2020), la chaîne de vulgarisation scientifique (Adenot, 2016; Chevry Pébayle, 2021), le blogue de vulgarisation scientifique (Reboul-Touré, 2020; Branca-Rosoff, 2007), de même que le dictionnaire en ligne, le moteur de recherche, sont tous des exemples de genres explorés par les internautes de 6e année au fil de leurs navigations informationnelles (Martel et Pleau, 2023). Cette variété générique les confronte à différentes expériences sémiotiques par la mise en scène de l’information selon des procédés, des formes, des messages qui leur sont propres et qui articulent l’information (Lebrun et al., 2019; Lim et Toh, 2020; Pleau et al., 2022) tout en sollicitant un engagement (Demers et al., 2016; Lim et Toh, 2020). Le polymorphisme des formes de discours (Pleau et al., 2022) de même que leur hybridation (Paveau, 2012) poussent le·a lecteur·rice internaute à élaborer des parcours de lecture flexibles profitant ainsi de l’un des principes de l’« infosphère », soit celui d’aller à la rencontre d’une certaine sérendipité en exploitant ses éléments de design (Commission mondiale d’éthique des connaissances scientifiques et des technologies – UNESCO, 2001; Reviglio, 2019) au cours de la réalisation d’une tâche de littératie informationnelle.
1.2. Les tâches scolaires de littératie informationnelle
La définition des tâches scolaires réalisées par les lecteur·rices internautes croise les propositions de Doyle (1983) à celles de Marchionini (1989) et de Bilal (2000, 2001, 2002). Elle décrit des tâches cognitives effectuées d’abord en environnement analogique (mémorisation, application d’une procédure, compréhension, prise de position; Doyle, 1983), puis numérique (Bilal, 2000, 2001, 2002; Marchionini, 1989).
Selon les études empiriques de Bilal (2000, 2001, 2002), les tâches réalisées en ligne pourraient être décrites selon trois types. Le premier regroupe les tâches invitant l’apprenant·e à vérifier des faits en ligne (ex. : Où l’ornithorynque vit-il ?). Le second, décrivant les tâches « orientées vers la recherche », incite les internautes à développer leurs connaissances d’un sujet (ex. : Cherche des informations en ligne pour comprendre la photosynthèse.). Le dernier type propose quant à lui des tâches ouvertes où le sujet est choisi par l’internaute. Dans tous les cas, les ressources cognitives de l’internaute sont sollicitées à différents niveaux (figure 1).
Figure 1
Représentation de la charge cognitive en fonction des activités réalisées en ligne selon Bilal (2000, 2001, 2002) et Marchionini (1989), tirée de Pleau (2023)

Les tâches scolaires en littératie informationnelle présentent une structure qui se décrit au départ de la modélisation d’inspiration cognitiviste d’Eisenberg et Berkowitz (Big Six Skills, 1990). Celle-ci décrit des habiletés constitutives et conditionnelles associées par Brand-Gruwel et al. (2009) à la résolution de problème à partir d’informations consultées en ligne dans un processus régulé (figure 2). Selon ces auteur·rices, l’internaute procéderait à la définition d’un problème d’information, à la recherche, au survol, au traitement, puis à l’organisation des informations en vue de leur utilisation.
Figure 2
Modèle de résolution de problème d’information sur Internet de Brand-Gruwel et al., 2009 (traduction libre de Pleau [2023])
![Modèle de résolution de problème d’information sur Internet de Brand-Gruwel et al., 2009 (traduction libre de Pleau [2023])](/fr/revues/rrlmm/2024-v20-rrlmm09818/1115968ar/media/2426281.jpg)
1.3. La compréhension d’informations consultées en ligne
Lors de la réalisation des tâches scolaires de littératie informationnelle, les lecteur·rices internautes du primaire seront invité·es à consulter des informations présentées selon des genres variés (Gervais et Saemmers, 2011; Gonçalves, 2014; Pleau, 2017; Vandendorpe, 1999), et ce, au départ d’une requête dans un moteur de recherche (Cordier, 2017; Pleau, 2023). Comprendre les informations engage ainsi différentes compétences, dont la navigation, l’évaluation et l’intégration (Salmerón et al., 2018).
La navigation amène le·a lecteur·rice internaute à développer un parcours de lecture autour de son intention de recherche. Iel exploite ainsi les relations de sens qui lient entre elles les informations de manière non linéaire et réseautée (Amadieu et al., 2011). Cette navigation est le résultat du croisement d’une série de décisions basées sur l’analyse des informations repérées en ligne, et du besoin d’information identifié par le·a lecteur·rice internaute (Rouet et Britt, 2011). Lors du développement de son expertise, ce·tte dernier·ère élabore une représentation de différents parcours en ligne; une représentation mobilisée lors de navigations futures (Clark et al., 2006). Au primaire, ce parcours peut s’amorcer par la consultation du moteur de recherche Google (Cordier, 2017).
En plus de la capacité de développer un parcours de lecture, comprendre des informations consultées en ligne requiert du·de la lecteur·rice internaute de fréquentes prises de décision. Iel pose ainsi un regard critique sur les informations rencontrées, jugeant de leur pertinence et de leur qualité. L’étude de Coiro et al. (2015) soulignait la superficialité des critères auxquels recourent les lecteur·rices internautes de 7e année. Les chercheuses mentionnaient la présence de nombres et de statistiques, la présence du symbole de copyright (©) et le nombre de consultations du document. D’autres chercheur·ses soulevaient quant à elleux une influence des connaissances antérieures dans la capacité de l’internaute à avoir confiance en l’information rencontrée en ligne (Salmerón et al., 2018; Stadtler et Bromme, 2014). Ainsi, une information qui contredirait ses connaissances antérieures pourrait lui inspirer de la méfiance. Coiro et al. (2015) ajoutaient que l’expérience personnelle de l’internaute pouvait également influencer l’évaluation des informations consultées en ligne (ex. : J’ai déjà mangé cet aliment et je n’ai pas été malade, l’information est probablement fausse). L’évaluation de la pertinence, quant à elle, amène le·a lecteur·rice internaute à comparer les informations rencontrées en ligne à son besoin d’information pour en vérifier l’utilité dans l’atteinte de son intention de recherche (McCrudden et al., 2011). Elle pousse le·a lecteur·rice internaute à survoler les informations pour repérer et diriger son attention vers les informations qui semblent utiles à sa tâche (Salmerón et al., 2018), ce qui lui permet d’effectuer un premier tri duquel découlera un traitement attentif des informations sélectionnées.
La compétence d’intégration définie par Salmerón et al. (2018) soulève la complexité du traitement d’informations de genres et de modes variés provenant de sources multiples (Rouet et Britt, 2011), mais qui se complètent, se superposent et/ou se contredisent. Elle met en évidence la sémiotisation de l’information par la convocation et l’élaboration de représentations mentales (Kintsch, 1998), tout en soulignant l’importance de l’agentivité du·de la lecteur·rice internaute face à ses apprentissages (Demers et al., 2016). L’intégration réfère à la direction et au maintien de l’attention du·de la lecteur·rice internaute envers le traitement des informations consultées (Wylie et al., 2018), ce qui interpelle le concept de charge cognitive (Clark et al., 2006). Définir l’intégration, c’est considérer le rôle essentiel des connaissances antérieures dans la compréhension des informations consultées en ligne (Amadieu et Tricot, 2006; Amadieu et al., 2011; Coiro et Dobler, 2007; Mayer, 2017; Rouet et Britt, 2011) et dans la construction de nouveaux savoirs, que ces derniers soient développés à l’école ou hors de celle-ci.
2. Les choix méthodologiques
Le présent article présente une étude qui visait à décrire les activités de navigation d’internautes de 6e année au cours du développement de leur compréhension d’informations consultées en ligne, en plus d’expliquer l’interaction entre le raisonnement d’internautes de 6e année et leur prise de décision durant la mobilisation de leurs compétences de navigation, d’évaluation et d’intégration.
En raison de la complexité du phénomène à l’étude, du besoin de l’explorer dans le contexte le plus naturel possible et de la profondeur de l’analyse requise, l’étude de cas multiples a été privilégiée (Gagnon, 2012; Karsenti et Demers, 2011; Merriam, 1988). Les données de navigation de neuf cas de lecteur·rices internautes de 6e année ont ainsi été collectées et analysées au départ d’un protocole expérimental comportant quatre phases distinctes.
2.1. La sélection des participant·es et des cas à l’étude
Considérant les objectifs énoncés plus haut, des apprenant·es québécois·es de 6e année ont été sélectionné·es pour participer à l’étude selon les principes de l’échantillonnage de convenance. Les centres de services scolaires (CSS) et les classes interpellées aux fins d’échantillonnage provenaient d’une variété de régions du Québec, ce qui a favorisé l’observation du phénomène dans divers environnements (Stake, 2006), en plus de diminuer la possibilité de biais rattaché à la fracture numérique (limite d’accès au numérique) en milieu éloigné des centres urbains. L’école A était située dans une subdivision de recensement à proximité de Montréal (111 575 habitant·es au recensement de 2016, Statistique Canada, 2017), l’école B était située dans une agglomération de recensement sur le territoire de la Manicouagan (27 692 habitant·es au recensement de 2016, Statistique Canada, 2017), et les troisième et quatrième écoles étaient situées dans une subdivision de recensement de la région de Bellechasse (3 362 habitant·es au recensement de 2016, Statistique Canada, 2017).
La sélection des milieux scolaires s’est également appuyée sur l’indice de milieu socio-économique (IMSE) du MEES (2017). Au départ d’une échelle définissant 10 niveaux (niveau 1 : milieu favorisé; niveau 10 : milieu défavorisé), les écoles sélectionnées présentaient toutes un IMSE de 6 au moment de l’échantillonnage (MEES, 2017).
Au sein des milieux, les classes sollicitées répondaient à certains critères. Le protocole expérimental prévoyant une tâche scolaire de littératie informationnelle réalisée en ligne et une verbalisation à voix haute de la pensée, les classes recouraient fréquemment à l’enseignement explicite et à l’approche inductive, habituant ainsi les élèves au modelage et à la verbalisation de la pensée (Gauthier et al., 2013), de même qu’à la résolution de problème caractéristique, selon Demers et al. (2016), de l’agentivité.
En nous inspirant des travaux approfondis lors de la revue des écrits scientifiques, les participant·es ont été choisi·es, par leur enseignant·e, pour leurs habiletés en lecture (Coiro et Dobler, 2007; Brand-Gruwel et al., 2009), pour leurs habiletés à l’ordinateur (Brand-Gruwel et al., 2009) et pour leur facilité à communiquer oralement leur pensée. Considérant l’importance des habiletés en lecture et des habiletés à l’ordinateur pour réaliser la tâche prévue au protocole expérimental, aucun·e élève présentant des diagnostics comme la dyslexie ou la dyspraxie n’a été sélectionné·e. Ces contraintes de sélection ont permis d’éviter de soumettre des apprenant·es à des tâches trop difficiles qui auraient pu entraîner, de leur part, un découragement, une incapacité de réaliser la tâche de manière autonome, voire un abandon.
2.2. Le protocole expérimental
L’étude de cas, telle que pensée pour les besoins de cette recherche, a proposé aux participant·es une tâche inspirée des travaux de Bilal (2000, 2001, 2002) où il leur était demandé d’en apprendre le plus possible sur un sujet en consultant Internet. Lors de la première rencontre (navigation A), les participant·es s’informaient sur le neurone et, la semaine suivante, sur la synapse. À chaque rencontre, la question de recherche était formulée de manière similaire (« qu’est-ce qu’un neurone ? »; « qu’est-ce qu’une synapse ? »), sans offrir de balises spécifiques pouvant guider le parcours de lecture du·de la participant·e.
2.2.1. Le choix des sujets de navigation
Plusieurs variables ont été considérées dans le choix des sujets proposés aux participant·es pour la réalisation de la tâche. Il fallait d’abord que ces sujets n’aient pas été approfondis en classe avec les enseignant·es; une situation qui aurait pu compromettre la validité interne du protocole expérimental (Coiro, 2011). Un tel choix a permis d’observer le recours aux connaissances antérieures générales des participant·es (ex. : le corps humain, la cellule) dans l’élaboration d’une compréhension spécifique des sujets, ce qui permettait d’exposer le processus menant à la compréhension d’informations consultées en ligne (Amadieu et al., 2011; Brand-Gruwel et al., 2009; Coiro et al., 2015; Rouet et Britt, 2011; Salmerón et al., 2018). Nous avons également réfléchi les sujets pour que le second soit une complexification du premier. De cette manière, les connaissances développées sur le sujet du neurone pouvaient être mobilisées à titre de connaissances antérieures lors de la navigation B portant sur la synapse. Il était ainsi possible d’explorer la part du processus qui sollicite un transfert des connaissances en examinant la rétention des apprentissages et la capacité du·de la lecteur·rice internaute à réutiliser ces connaissances. Le choix des sujets a fait l’objet d’une vérification des ressources disponibles en ligne. Nous nous sommes alors intéressés, par une préexploration des résultats de différents moteurs de recherche, à la variété d’informations accessibles aux participant·es par la seule entrée des mots « neurone » et « synapse » dans la barre de recherche. Nous avons alors repéré sans difficulté des informations de différents niveaux de vulgarisation, de différentes modalités sémiotiques et de différentes intentions de communication.
2.2.2. Les phases de l’expérimentation
Le devis méthodologique, déployé lors de deux rencontres (navigation A et navigation B), a proposé aux participant·es quatre phases dont les intentions visaient la description des cas et l’induction du processus menant à la compréhension d’informations consultées en ligne. Le déroulement de ces phases a nécessité le recours à une variété d’outils méthodologiques dont l’entretien dirigé, la méthode de pensée à voix haute (think aloud protocol), l’entretien libre et l’entretien semi-dirigé rétrospectif (tableau 1). Leur triangulation dans l’analyse a par ailleurs contribué à la robustesse des résultats de la présente étude (Karsenti et Savoie-Zajc, 2018; Merriam, 1988; Stake, 1995).
Tableau 1
Description des phases du protocole expérimental
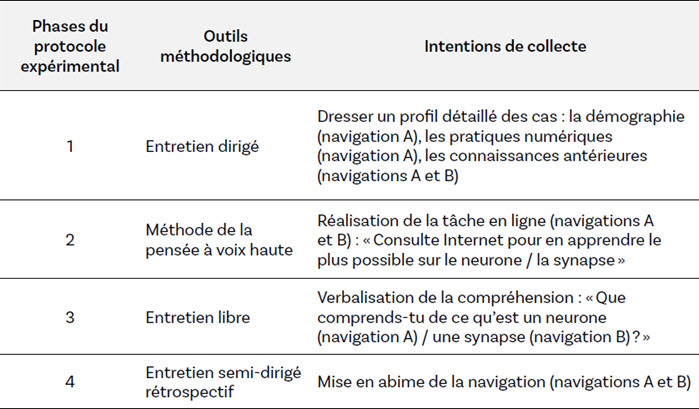
En souhaitant dresser un profil détaillé des cas, l’entretien dirigé de la première phase du protocole expérimental a servi à la collecte d’informations démographiques (âge, milieu socioculturel, milieu familial), à documenter les pratiques informationnelles numériques des participant·es, leurs connaissances et leurs expériences antérieures. Cette étape préalable à la réalisation de la tâche a nourri, d’une part, notre évaluation de l’expertise des participant·es (Brand-Gruwel et al. 2009; Coiro et Dobler, 2007), et, d’autre part, l’anticipation de leurs connaissances du sujet (neurone / synapse); des données reconnues par les chercheur·ses (Brand-Gruwel et al. 2009; Coiro et Dobler, 2007; Macedo-Rouet et al., 2013; Salmerón et al., 2017) et essentielles à la circonscription des apprentissages effectués par le·a participant·e lors de la réalisation de la tâche. La semaine suivante, au moment d’amorcer la seconde rencontre (navigation B), seules les connaissances antérieures du sujet (synapse) ont été documentées.
La seconde phase du protocole expérimental a engagé les participant·es dans la réalisation en ligne d’une tâche scolaire de littératie informationnelle tout en verbalisant leurs réflexions. La méthode de pensée à voix haute (think aloud protocol), utilisée depuis plus d’un siècle par des chercheur·ses en sciences cognitives et en sciences de l’éducation (Charters, 2003), permet l’étude des processus rattachés à la compréhension du sens en environnement numérique (Anmarkrud et al., 2013; Coiro, 2011; Coiro et Dobler, 2007; Falardeau et al., 2014; Kaakinen et Hyona, 2005; Salmerón et al., 2017). Elle offre un accès valide et fiable aux pensées et aux actions du·de la lecteur·rice (Charters, 2003; Coiro et Dobler, 2007; Pressley et Afflerbach, 1995) tout en offrant la possibilité d’inférer les processus et les stratégies cognitives de manière contextualisée (Falardeau et al., 2014; Hilden et Presley, 2011), ce que l’observation directe du comportement et la mesure de performance ne permettent que partiellement (Forget, 2013). Pour répondre aux objectifs de cette étude, le logiciel de montage Camtasia Screen Capture a sauvegardé, sous forme de vidéo, les activités de navigation des participant·es, leurs verbalisations et leurs expressions faciales (Coiro, 2007; 2011). Inspirée des travaux de Bilal (2000, 2001), la tâche de recherche documentaire réalisée par les participant·es a été réfléchie pour se rapprocher le plus possible des tâches accomplies en classe (matériel similaire à celui utilisé en classe : ordinateur portable, clavier et souris externes, système d’exploitation Windows 10, accès à Chrome et à Explorer à partir d’icônes évidentes sur le bureau). La tâche de recherche les a plongé·es dans l’exploration d’informations concernant le neurone durant 30 minutes (navigation A), puis, la semaine suivante, concernant la synapse durant 10 minutes (navigation B). La durée de la navigation B a été ainsi réduite pour tenir compte du lien de sens unissant les deux sujets et des connaissances antérieures développées durant la navigation A.
Au terme de chaque navigation, il a été demandé aux participant·es d’expliquer, dans leurs mots, ce qu’iels ont compris du sujet (navigation A : neurone; navigation B : synapse). Ne visant aucune mesure de performance, les données collectées à cette étape étaient qualitatives et avaient pour but de faire émerger les thématiques explorées par les participant·es durant l’élaboration de leur compréhension. Considérant les objectifs de la présente recherche, la production écrite souvent associée aux tâches scolaires de littératie informationnelle a été mise de côté au profit d’un rappel oralisé des informations comprises. Les participant·es ayant été sélectionné·es eu égard à leurs habilités à oraliser leur pensée, les données collectées par une production écrite auraient pu être biaisées par une maitrise difficile de la compétence à écrire.
La dernière phase du protocole expérimental invitait le·a participant·e à revisiter sa navigation pour approfondir, avec la chercheuse, ses actions et ses décisions de navigation. Ainsi, à la manière d’une mise en abime, la mobilisation des compétences de navigation, d’évaluation et d’intégration a pu être expliquée par le·a participant·e alors qu’iel visionnait l’enregistrement Camtasia immédiatement après la fin de sa navigation (Coiro, 2007).
2.2.3. L’analyse et l’interprétation des données
Au terme de l’expérimentation, les données collectées par les navigations A et B de chaque participant·e ont été analysées pour soutenir la définition fine des cas comme cela fut fait dans les travaux de Coiro (2007). La procédure d’analyse mise de l’avant a permis, dans un premier temps, de traiter séparément les données en dégageant les constances (similarités entre les navigations d’un même cas), en dégageant les inconstances (singularités entre les navigations d’un même cas) et en dégageant les points de rencontre entre les cas (émergence d’une hypothèse de profils de lecteur·rices internautes). À la suite de cette étape, les données de navigation ont été mises en relation avec les données démographiques, les connaissances antérieures et l’expertise des participant·es pour tirer des conclusions.
De manière spécifique, le traitement du corpus de données s’est déroulé selon cinq étapes. Il a débuté par la préparation des données (sauvegarde des enregistrements et mise en page) et s’est poursuivi par l’organisation des données verbales et visuelles. Des verbatims ont été rédigés en distinguant les interlocuteur·rices, les passages de lecture à voix haute, les difficultés de décodage et les réflexions des participant·es, réduisant ainsi les données pour une première fois. Les données visuelles rattachées au parcours de lecture des participant·es ont quant à elles été consignées à l’aide de lignes du temps horodatées, ce qui permettait de mettre en évidence les sites consultés, les informations visuelles consultées et les actions de navigation. Ainsi, 12 heures et 32 minutes d’enregistrement ont été organisées (Tableau 2).
Tableau 2
Durée des vidéos analysées pour la rédaction des verbatims et la constitution des lignes du temps (horodatage des actions de navigation)

Considérant la multimodalité du corpus et le besoin de trianguler les données collectées par les différents outils méthodologiques, des matrices multimodales ont été constituées permettant une lecture transversale des données et une seconde réduction. La figure 3 présente un exemple de cette lecture dans la matrice de Thomas. On y lit que le participant a consulté Wikipédia pour une durée de 1 minute et 22 secondes, qu’il a cliqué sur une image située à droite de son écran (colonne de droite) en se demandant « C’est quoi ça ? », ce qui l’a amené à lire (en gris) le titre sous l’image et à s’exclamer « Ah ! ». Le verbatim rétrospectif précise que l’image consultée sur Wikipédia rappelait à Thomas une image de son cahier de sciences. Selon lui, cette image décrivait comment « les cellules étaient faites ».
Figure 3
Exemple de lecture transversale dans la matrice de Thomas (navigation A)

Nous avons ainsi procédé au repérage et à la catégorisation des 475 pages de matrices multimodales en utilisant le logiciel NVivo 12. Afin de soutenir la rigueur de l’analyse de contenu, la procédure de codage a fait l’objet d’une évaluation interjuge. Une analyste et la chercheuse ont alors codé 5 % du corpus de données ensemble, puis un autre 10 % séparément. Elles ont ensuite comparé leur évaluation, ce qui a mis en évidence la validité de la procédure et de la grille de codage (taux d’accord : 97 %).
Tableau 3
Nombre de pages du corpus de données analysées

Par une description fine des cas (20 à 30 pages par participant·e) en fonction des concepts de la navigation, de l’évaluation, de l’intégration et de l’autorégulation, les données ont été réduites une nouvelle fois dans un effort d’expliquer de manière résumée les relations et les interactions entre les données (croisement de données démographiques et de l’expertise des internautes). Au terme, l’induction du processus s’est effectuée au départ des données saillantes de la description et de l’explication des manifestations de compétences. Par la mise en évidence des ressemblances et des disparités entre les cas, une hypothèse de profils de lecteur·rices internautes a pu être formulée.
3. Les résultats
3.1. La description des données démographiques
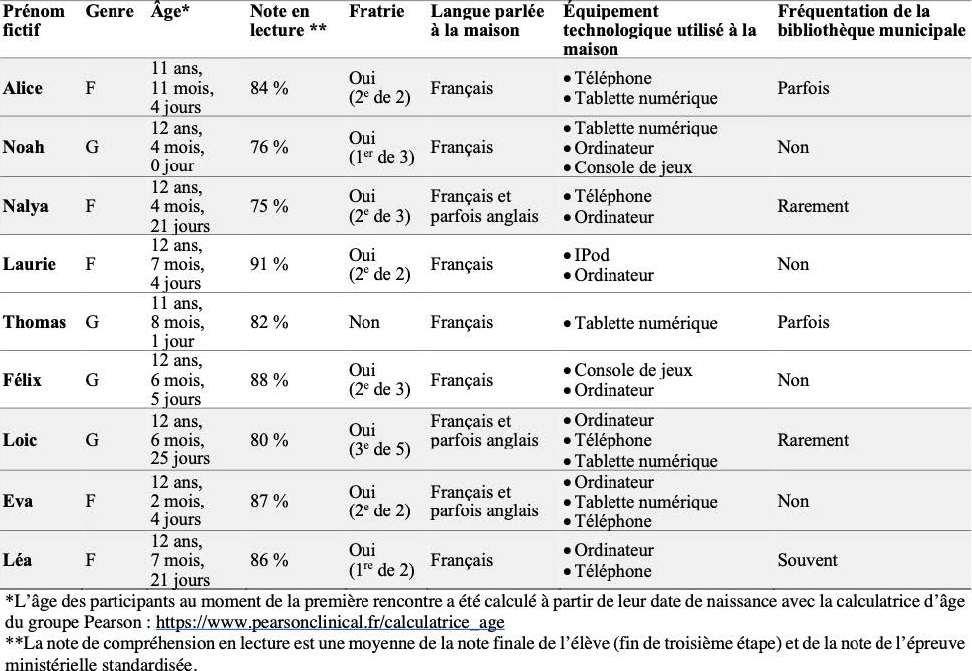
La collecte des données s’étant déroulée au mois de mai, les participant·es à l’étude, neuf élèves de 6e année né·es au Québec, achevaient leur scolarisation primaire (système d’éducation où l’année scolaire débute en septembre et se termine à la fin de juin). Trois participant·es (Alice, Noah et Nalya) étaient scolarisé·es dans une école à proximité de Montréal (SDR), trois autres (Laurie, Thomas et Félix) dans une école de la Manicouagan (AR), tandis que les trois dernier·ères (Loic, Éva et Léa) fréquentaient une école de Bellechasse (SDR). Le tableau 4 résume les données démographiques collectées lors des entretiens dirigés. Lorsqu’iels ont été interrogé·es à ce sujet, aucun·e participant·e n’a déclaré avoir suivi de programme spécifique mettant de l’avant l’utilisation des technologies de l’information et de la communication.
Les enseignantes de ces participant·es ont confirmé que l’approche inductive et l’enseignement explicite étaient fréquemment mis de l’avant en classe. Elles ont d’ailleurs décrit les participant·es choisi·es comme étant volubiles et capables de réfléchir à voix haute lors d’un modelage.
Tableau 4
Compilation des données démographiques des participant·es
3.2. L’exploitation du réseau sémantique dans l’intégration des informations consultées en ligne
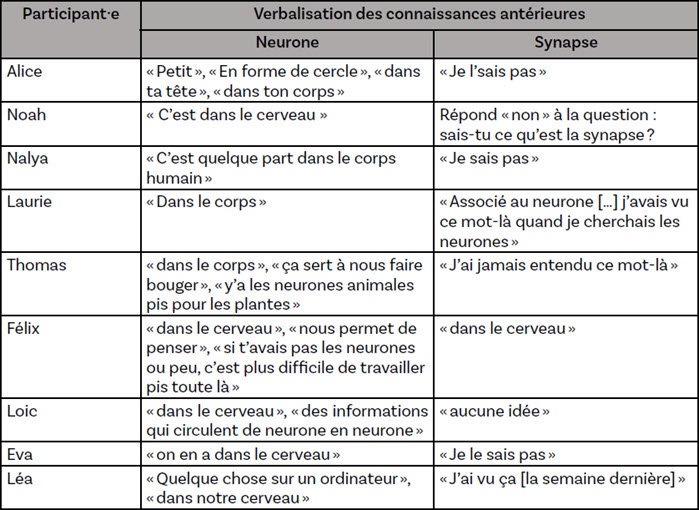
Alors que les participant·es à l’étude étaient interrogé·es sur le neurone et la synapse avant d’amorcer les tâches de recherche documentaire en ligne, l’analyse des verbatims de l’entretien dirigé a mis en lumière les limites de leurs connaissances antérieures (tableau 5).
Tableau 5
Verbalisation des connaissances antérieures des participant·es
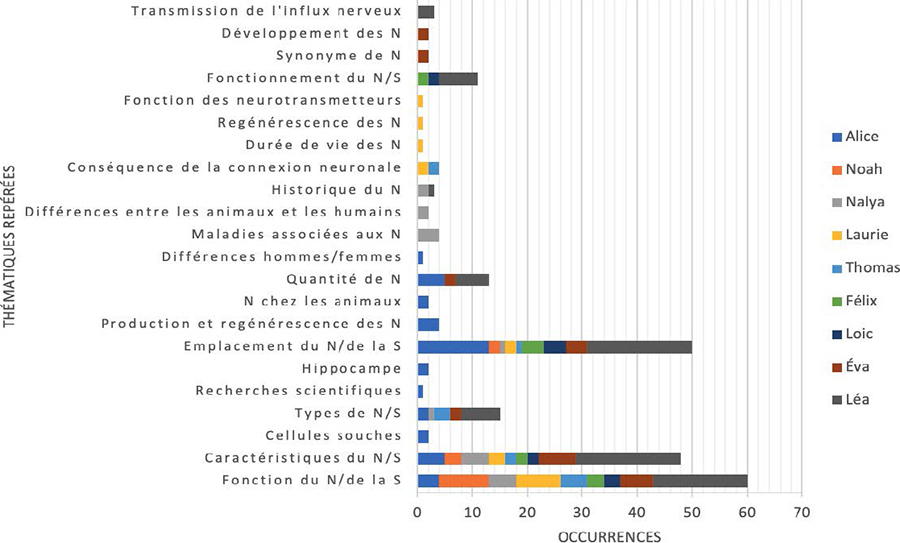
En nous intéressant aux données verbales collectées durant les navigations, de même qu’à celles collectées durant l’entretien semi-dirigé rétrospectif, il a été possible de constater le développement du parcours de lecture des participant·es par la mise en réseau d’informations sémantiquement reliées. Des regroupements thématiques ont pu être effectués au départ de l’analyse de contenu, permettant ainsi de brosser le portrait de l’expansion sémantique des parcours de lecture des participant·es. Il émerge de cette analyse que les thématiques de la fonction du neurone/de la synapse, de leur emplacement et de leurs caractéristiques ont été les plus fréquemment repérées dans les verbalisations des participant·es. En revanche, des thématiques comme la régénérescence des neurones, les différences entre les hommes et les femmes, la durée de vie des neurones,les recherches scientifiques et la fonction des neurotransmetteurs étaient uniques à certaine·es participant·es.
Figure 4
Occurrences des thématiques repérées dans les verbalisations des navigations A et B
Ces regroupements thématiques ont également mené au constat d’une variation dans le nombre de thématiques explorées par les participant·es (tableau 6). Les analyses proposent qu’iels aient consulté une moyenne de 8,22 thématiques différentes durant leurs navigations. Noah (N=3) et Alice (N=11) représentant les extrêmes de cette répartition.
Tableau 6
Répartition du nombre de thématiques explorées

Les analyses des matrices de données ont également mis en évidence le recours à une quinzaine de stratégies rattachées à la compétence d’intégration des informations consultées en ligne (tableau 7). On y remarque notamment que des activités autorégulatoires comme se questionner, prédire, planifier, sont partagées par tous·tes les internautes. À l’opposé, le fait d’éviter ou d’ignorer les informations difficiles, qui semblent difficiles ou qui contredisent une compréhension initiale, est une stratégie qui n’a été mobilisée que par Thomas. Relire des passages déjà lus est quant à elle la stratégie la plus fréquemment repérée dans les navigations (N=6). Dans tous les cas, des liens sémantiques explicites avec les connaissances antérieures des internautes ont pu être identifiés dans les verbalisations.
Tableau 7
Répartition de stratégies de gestion de l’intégration des informations selon les cas

3.3. Le développement du parcours de lecture par la navigation
Par l’analyse des données rattachées aux activités de navigation, à leur horodatage dans les matrices et aux verbalisations, il a été possible de déterminer la proportion du temps consacré par les participant·es aux différentes activités de navigation : exploration d’un moteur de recherche, exploration de sites variés et prise ou ajustement des notes. Telles que le présente la figure 5, des tendances se dessinent. On constate que tous·tes les participant·es ont alloué plus de 50 % de leur temps de navigation (A et B) à l’exploration des informations présentées par une variété de sites. On remarque par ailleurs que pour sa navigation A uniquement, Léa a dépassé le seuil des 78 %; un seuil franchi lors des deux navigations par Noah, Nalya, Loic et Éva. Se démarquant des autres, ces données exposent également que Thomas et Alice ont pris ou ajusté des notes durant plus de 20 % de leurs navigations, ce qui se distingue franchement de Noah, Nalya, Laurie et Loic qui ont maintenu ce nombre sous les 5,2 % et de Laurie et Loic qui n’ont pris aucune note durant la navigation B.
Figure 5
Proportion du temps accordé aux activités en fonction de la durée des navigations pour chaque participant·e

En nous intéressant aux données de navigation, il a été possible de comparer le nombre de sites consultés par navigation, et ce, pour chaque participant·e (figure 4). Il ressort de ces analyses que les internautes ont consulté, en moyenne, 9 sites au cours de leur navigation A et 3,44 sites au cours de la navigation B. Considérant la diminution de la durée des navigations A et B, une telle baisse était attendue. Cependant, il ressort des données que malgré cette variable, une certaine stabilité du nombre de sites consultés a pu être observée pour le tiers des cas (Alice, N=6; Thomas, N=2; Léa, N=3). Par ailleurs, Éva s’est démarquée de tous les cas étudiés puisqu’elle présente la plus grande variation dans le nombre de sites consultés.
Figure 6
Nombre de sites consultés par navigation pour chaque participant·e.

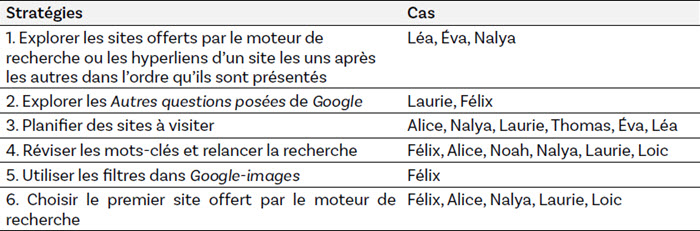
Le corpus de données analysé a favorisé l’émergence de six stratégies de navigation (tableau 8). On y remarque que planifier des sites à visiter, une stratégie qui prend un appui fort sur les connaissances et les expériences des navigations passées de l’internaute, et réviser les mots-clés et relancer la recherche, qui quant à elle mobilise des connaissances lexicales, sont des stratégies repérées dans les verbalisations et les activités du deux tiers des cas (N=6). Il est aussi possible de faire le constat que la consultation du premier site offert par le moteur de recherche a été une stratégie vers laquelle la majorité des cas (N=5) s’est tournée. Ces données révèlent aussi le recours à des stratégies moins fréquentes. Le cas de Félix a mis en évidence l’utilisation des filtres dans Google-images, de même que l’exploration de la section « Autres questions posées » de Google; une stratégie seulement retrouvée dans les données de navigation de Laurie.
Tableau 8
Répartition de stratégies de navigation selon les cas
3.4. L’évaluation des informations en ligne
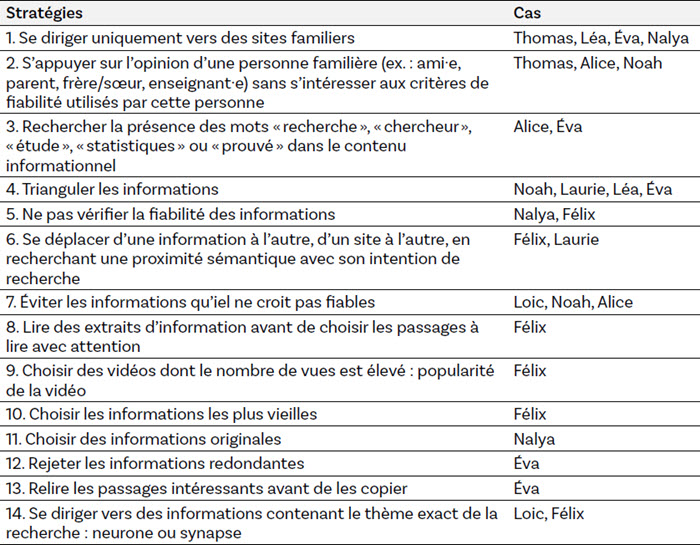
Évaluer les informations consultées en ligne est une compétence qui s’est manifestée dans les données analysées (tableau 9), principalement en ce qui a trait à la pertinence des informations avec le sujet approfondi par les participant·es, soit le neurone (navigation A) ou la synapse (navigation B). L’évaluation de l’information pour sa fiabilité n’a eu que très peu de présence dans le corpus de données, ce qui suggère une faible attention dirigée vers cet aspect de la compétence. Lorsqu’elle était observée, l’évaluation de la fiabilité s’appuyait essentiellement sur des critères instables d’évaluation comme le nombre de vues d’une vidéo, la présence/absence du mot « recherche » ou « science » dans les informations. Le cas de Félix a présenté une préoccupation autour de la date de publication des informations consultées, mais en précisant « Ben j’crois que c’est à cause de l’année que c’est sorti. Février 2012. Donc, j’me suis dit «en février 2012, y devait pas y avoir de grands menteurs là» », ce qui met en évidence l’émergence d’une préoccupation autour de la fiabilité des informations consultées en ligne et des critères utiles à son évaluation, sans toutefois en maitriser le recours. La triangulation des informations entre les sites est une stratégie qui a été mobilisée dans quatre cas (Noah, Laurie, Léa, Éva). Pour eux, une information était « bonne » si elle était rencontrée à plusieurs endroits. Ces données révèlent que, dès la 6e année, certain·es lecteur·rices internautes démontrent l’émergence d’une capacité d’analyse critique de l’information; une compétence qui ne semble pas encore formalisée. Ce constat laisse croire à la vulnérabilité des lecteur·rices internautes de cet âge face à l’information trompeuse.
Durant leurs navigations, Félix et Laurie ont démontré de manière explicite la recherche d’une proximité sémantique avec leur intention de recherche (neurone/synapse). Pour Loic et Félix, le mot exact de cette intention devait être repéré dans l’information pour décider d’y accorder de l’attention. Cette stratégie les a, par ailleurs, amené·es à rejeter des informations sur la synapse lorsqu’iels apercevaient d’abord le mot neurone, et ce, jusqu’à ce qu’iels comprennent la relation entre ces deux mots. Les informations ont été évaluées par Nalya pour leur originalité et par Éva pour leur redondance.
Tableau 9
Répartition des stratégies d’évaluation selon les cas
4. La discussion
La présente discussion comporte deux parties. La première permet la présentation d’une hypothèse de profils de lecteur·rices internautes qui a émergé de l’interprétation des résultats de l’étude. La seconde discute quant à elle de l’enjeu de la surcharge cognitive dans le processus rattaché à la compréhension d’informations consultées en ligne, de la flexibilité cognitive et de la capacité d’inhibition observée chez les lecteur·rices internautes participant à l’étude.
4.1. Une hypothèse de profils de lecteur·rices internautes
L’analyse des données de recherche a fait émerger des saillances et des distinctions entre les cas. Elles ont été explorées eu égard au dernier objectif de la présente recherche et ont permis la proposition d’une hypothèse de profils de lecteur·rices internautes : rigide, explorateur, vérificateur, synthétique et tenace.
4.1.1. Le profil rigide
Le profil rigide décrit un·e internaute déstabilisé·e par la tâche si elle ne lui offre pas une structure explicite. Sans points de repère, iel se dirige vers des sites familiers, ce qui limite l’expansion de son parcours de lecture. Ce profil se tourne vers des stratégies peu efficaces, mais qu’iel sait contrôler. Sa rigidité cognitive l’amène à éprouver des difficultés dans la régulation de sa compréhension, notamment parce qu’iel n’est pas disposé·e à douter d’une compréhension initiale. Iel choisit plutôt d’insister sur la validité de cette compréhension (ex. : le neurone fait de la photosynthèse) et d’ignorer les informations qui la contredisent, même si elles sont nombreuses.
4.1.2. Le profil vérificateur
La description du profil vérificateur croise celle du profil synthétique et du profil tenace sans toutefois s’y conformer. Elle décrit un·e internaute qui effectue un contrôle étroit de sa navigation. Le profil vérificateur s’intéresse à la fiabilité des informations consultées en triangulant des sources, en consultant différents moteurs de recherche, en s’appuyant sur les conseils de personnes de son entourage (ex. : parent, fratrie, enseignant·e) et en contournant volontairement les sources où l’information est produite par la contribution de tout un chacun. Ce profil développe son parcours de lecture en recherchant les mots « recherche », « chercheur », « étude » et « prouvé » qui, pour lui, sont synonymes de fiabilité. Le·a lecteur·rice internaute du profil vérificateur alterne entre la consultation d’informations spécifiques et vulgarisées, repérées à l’aide de mots-clés ou en exploitant certaines fonctionnalités comme les propositions des algorithmes de Google. Lorsque des mots difficiles sont rencontrés, iel les ignore et accepte de ne pas tout comprendre. Ce profil étudie avec attention certaines informations et en survole d’autres. Il démontre une facilité à résoudre des bris de compréhension parce qu’il est capable de douter et de réviser une compréhension initiale. Les publicités et les fenêtres surgissantes dérangent le profil vérificateur, mais ne l’empêchent pas d’accomplir la tâche.
4.1.3. Le profil synthétique
Le profil synthétique réfère à un·e lecteur·rice internaute qui s’empresse de terminer la tâche. Il·elle recherche une efficacité et se tourne généralement vers des sites familiers qu’iel sait utiles à sa compréhension. Ce profil consulte des informations vulgarisées et peu variées pour développer une compréhension générale et non spécifique de son sujet de recherche. Il les repère par un survol des titres et des sous-titres, mais n’amorce la lecture d’un paragraphe que s’il croit qu’il sera utile à la réponse de son besoin d’information. Lors de sa navigation, cet·te internaute prend peu de notes, voire aucune. Iel n’explore que la première page des résultats du moteur de recherche et ne se préoccupe pas de la fiabilité des informations qu’iel consulte. Dans le développement de son parcours de lecture, le profil synthétique cherche à repérer une redondance dans les informations. Pour lui, elle signifie qu’il a atteint une saturation dans la sélection de son corpus informationnel, ce qui l’incite à mettre fin à sa navigation même si sa durée était brève.
4.1.4. Le profil tenace
Nous référons au profil tenace pour décrire un·e lecteur·rice internaute qui s’informe en consultant des informations spécifiques. Leur consultation lui entraîne des difficultés de décodage alors qu’iel étudie avec attention l’entièreté des sites choisis dans la liste des résultats du moteur de recherche. Ce profil explore de manière systématique les hyperliens contenus dans les documents qu’il consulte afin de s’assurer de ne rien manquer. Il définit les mots difficiles qu’il rencontre, ce qui impose une charge importante à sa mémoire. Le·a lecteur·rice internaute qu’il décrit est fréquemment confronté·e à des bris de compréhension qu’iel considère inacceptables. Iel relira plusieurs fois le même passage et recherchera des définitions pour les résoudre (ex. : en cherchant à comprendre la « cellule gliale », le·a lecteur·rice internaute du profil tenace rencontrera un mot comme « phagocytée » qu’iel voudra également définir). Pour soutenir sa compréhension, ce profil prend des notes détaillées, sans toujours se soucier de leur organisation.
4.1.5. Le profil explorateur
Le dernier profil, celui de l’explorateur, décrit un·e lecteur·rice internaute qui se laisse guider par les propositions de l’environnement numérique dans la réponse de ses besoins informationnels. Ce profil présente une grande expertise en ligne et la mobilise pour atteindre ses objectifs de navigation. La motivation qui guide ses navigations semble toutefois pouvoir varier. Pour cette raison, nous pensons plus adéquat de décrire ce profil selon trois sous-catégories : explorateur nomade, explorateur expérimentateur, errant (un profil théorique).
Le profil explorateur nomade
L’explorateur nomade décrit un profil qui se laisse porter par l’environnement numérique. Cet·te lecteur·rice internaute s’informe à même le moteur de recherche. Iel en exploite les fonctionnalités dans la réponse de son besoin informationnel en dévouant un temps considérable au traitement des encadrés de définition de Google, ou de l’espace Autres questions posées. Lorsque ce profil a épuisé les informations offertes par le moteur de recherche, il explore la liste des résultats et débute la consultation de sites choisis pour leur proximité sémantique avec son intention de recherche. Le survol lui est très utile et permet de repérer les redondances entre les informations, ce qui crée chez lui le besoin de relocaliser sa consultation d’informations.
Le profil explorateur expérimentateur
Des trois explorateurs, l’expérimentateur est le profil qui semble le plus expert. Ce profil caractérise un·e lecteur·rice internaute qui, comme le profil nomade, exploite les fonctionnalités de l’environnement numérique. Iel s’en distingue toutefois par sa motivation envers la découverte. Iel émet des hypothèses quant à des fonctionnalités qu’iel ne connait pas, les expérimente et y recourt dans ses navigations. De manière autonome, ce profil repousse les limites de sa compréhension de l’environnement numérique en recherchant constamment des manières d’augmenter l’efficacité de ses navigations.
Le profil explorateur errant
Ce dernier profil, d’explorateur, l’errant, décrit un profil théorique qui n’a pas pu être observé dans les cas à l’étude. Il définit un·e lecteur·rice internaute dont l’attention s’égare durant sa navigation. Iel circule d’un hyperlien à un autre, sans but précis. Iel saisit les opportunités offertes par l’environnement numérique au gré de ses émotions et de sa curiosité. En raison du protocole expérimental mettant de l’avant une tâche guidée par une intention claire, ce profil n’a pas émergé. Nous sommes d’avis qu’il pourrait toutefois être observé dans le contexte d’une étude ethnographique dont les paramètres soutiendraient des activités d’errance en ligne.
4.1.6. Une rencontre des définitions de profils
L’émergence de cette hypothèse de profils de lecteur·rices internautes offre un potentiel didactique intéressant eu égard, notamment, à la différenciation des tâches de littératie informationnelle. Les travaux de Hahnel et al. (2022) supportaient cette idée alors qu’au terme de leur étude exploratoire sur les comportements en lecture hypertextuelle chez des apprenant·es de 15 ans, il·elles ont présenté sept profils aux comportements distincts : « on-task », « passive », « hasty », « persistent », « exploring », « lost interest », « disengaged ». D’un point de vue contextuel, cette étude a analysé les données recueillies par l’enquête internationale PISA 2012 (OCDE, 2013, 2014). Concrètement, cela signifie qu’elle proposait aux participant·es trois tâches exigeant une lecture d’hypertexte dans un environnement fermé, exerçant ainsi un contrôle sur le développement du parcours de lecture hypertextuel. Ces participant·es, plus vieux·illes que celleux concerné·es par la présente étude, donc possiblement plus expérimenté·es et, en conséquence, plus familier·ères avec les tâches de compréhension en lecture due à une plus longue scolarisation, ont réalisé l’enquête il y a plus d’une décennie. Malgré ces distinctions méthodologiques et contextuelles, la définition des profils se croise, mais la comparaison demeure limitée. À titre d’exemple, l’explorateur présenté par la présente étude propose une expertise et une efficacité dans la réalisation de la tâche, ce que le profil « exploring » ne suggère pas. Ce dernier décrit plutôt une moins bonne maitrise des compétences requises, notamment en ce qui concerne l’orientation au sein de l’hypertexte. Les profils tenace et « persistent » suggèrent tous deux une difficulté à comprendre, une faible activité de navigation et une orientation lente vers les informations. Le synthétique et le « hasty », décrivent quant à eux un comportement précis où l’orientation vers une information se fait de manière rapide sans toutefois approfondir la compréhension des contenus consultés.
Les résultats de la présente recherche nous renseignent quant à la mobilisation des compétences de navigation, d’évaluation et d’intégration dans un processus autorégulé menant à la compréhension d’informations consultées en ligne. Ils poussent aussi à la réflexion quant à plusieurs enjeux cognitifs impliqués dans cette mobilisation; des enjeux révélés par l’étude approfondie des cas et qui pourraient guider la différenciation des tâches scolaires en littératie informationnelle.
4.2. Quelques enjeux rattachés à la compréhension d’informations consultées en ligne
4.2.1. L’enjeu de la charge cognitive
Faire l’étude de la compréhension d’informations consultées en ligne par des lecteur·rices internautes du primaire nous amène à nous pencher sur la théorie de la charge cognitive (Clark et al., 2006; Debue et van Leemput, 2014; Puma, 2016). Nous comprenons qu’une interaction entre la mémoire à long terme et la mémoire de travail est essentielle pour intégrer des informations consultées en ligne et qu’une maitrise non automatisée de processus comme la saisie au clavier pourrait occasionner une surcharge cognitive qui limiterait la compréhension (Clark et al., 2006; Pleau et Lavoie, 2016); ce qui fut observé par l’analyse des données du cas de Thomas.
Dans la compréhension des informations consultées en ligne, l’appui sur les représentations mentales existantes du·de la lecteur·rice internaute est essentiel et favorable à la compréhension (Amadieu et Tricot, 2006), particulièrement lorsqu’il est question d’un sujet complexe (Amadieu et al., 2011; Chen et Rada, 1996). Le cas d’Alice démontrait bien cette idée. Alors qu’elle tentait de comprendre le neurone, Alice a rencontré le mot hippocampe qu’elle reconnaissait en l’associant à l’animal marin. Dans les informations qu’elle consultait, ce mot était toutefois utilisé pour discuter de la partie du cerveau portant le même nom. Cette situation lui a occasionné un bris de compréhension; bris qui s’est résolu par l’exploration d’une variété de contextes sémantiques établissant des liens explicites entre les mots cerveau et hippocampe.
4.2.2. L’enjeu de la flexibilité cognitive
Discuter du cas d’Alice nous pousse aussi à interroger le concept de flexibilité cognitive (Chevalier, 2010; Clément, 2006; Duval et al., 2017; Miyake et al., 2000; Wylie et al. 2018) qui permet au·à la lecteur·rice internaute de réviser une compréhension initiale, de changer d’idée. L’attitude d’Alice face au mot hippocampe l’a poussée, au fil de l’exploration de son corpus informationnel, à douter de sa compréhension initiale. Il s’agit d’une distinction franche avec le cas de Thomas qui, pour sa part, a débuté sa navigation en démontrant une confusion dans la définition du mot cellule. Pour lui, toute cellule pouvait faire de la photosynthèse, ce qui inclut le neurone. Malgré une exposition fréquente à des informations qui ne suggéraient aucun lien entre la photosynthèse et le neurone, voire de nombreuses informations situant le neurone dans le corps humain, Thomas a maintenu sa compréhension initiale sans la remettre en question, mentionnant même la photosynthèse du neurone durant l’entretien libre de verbalisation de sa compréhension. Ce cas démontrait de manière explicite ce que Clément (2006) définit comme le défaut de flexibilité, soit la rigidité cognitive. Elle amène une difficulté à s’adapter à des idées différentes des siennes et, dans le cas de Thomas, elle a nui à sa compréhension.
4.2.3. L’enjeu de l’inhibition
Les travaux en sciences cognitives soulevaient l’importance d’une gestion efficace de l’attention pour soutenir la compréhension d’informations consultées en ligne. Wylie et al. (2018) précisaient que la sollicitation du système sensoriel (stimulus) par la navigation amène le·a lecteur·rice internaute à traiter en mémoire de travail une grande quantité d’informations. Sa capacité à faire fi d’informations non utiles à son intention de recherche, l’inhibition, soutiendrait l’apprentissage à partir d’informations consultées en ligne. Cependant, selon les travaux de Eastin et al. (2006), il serait possible que cette inhibition soit limitée, notamment lorsqu’il est question de publicités à l’écran. Or, les résultats de la présente étude suggèrent qu’en 6e année, les lecteur·rices internautes réussiraient à ignorer les publicités dynamiques et colorées qui bordent leur écran, exception faite des publicités qui déforment le texte alors qu’ils en effectuent la lecture (cas de Loic).
La capacité d’inhibition demeure, à ce jour, peu étudiée en relation avec le développement de la compréhension en lecture (Butterfuss et Kendeou, 2017), encore moins lorsqu’il s’agit de lecture en environnement numérique (Wylie et al., 2018). Nous comprenons toutefois des résultats de cette étude qu’en 6e année, les lecteur·rices internautes participant à l’étude ont déclaré ne pas avoir remarqué·es les publicités durant leurs navigations. Nous expliquons ce résultat en proposant que leur expérience de navigation les ait amené·es à reconnaître certaines caractéristiques des publicités en ligne (ex. : apparition, animation, emplacement). Nous interrogeons toutefois l’efficacité et la régularité d’une telle reconnaissance lorsque des informations se présentent à eux en adoptant les mêmes caractéristiques que la publicité, comme cela est souvent le cas des fenêtres surgissantes de définition. Selon Butterfuss et Kendeou (2017), l’inhibition serait une fonction exécutive encore en développement à 12 ans.
Conclusion
Cette recherche offre un éclairage complémentaire aux travaux déjà entrepris pour mieux comprendre l’aspect développemental de la compréhension d’informations consultées en ligne, notamment par la validation des propositions théoriques de Salmerón et al. (2018) auprès de lecteur·rices internautes du primaire.
Adoptant une posture exploratoire, cette recherche empirique comportait quelques limites. Mentionnons d’abord l’impossible généralisation des résultats en raison du nombre limité de cas à l’étude. Une étude subséquente pourra notamment approfondir la validité de l’hypothèse de profils qu’elle propose au terme de son analyse des cas. Une seconde limite concerne cette fois l’impossibilité de contrôler l’effet des algorithmes sur les informations offertes par les moteurs de recherche lors de la réalisation de la tâche par les participant·es. Bien que l’historique de navigation ait été effacé après chaque rencontre, les données de navigation de l’ordinateur peuvent avoir orienté les propositions d’informations en ligne. En terminant, nous sommes d’avis que la collecte de données prépandémique peut être considérée comme une limite. Il est effectivement possible que l’école à la maison puisse avoir soutenu le développement des compétences des lecteur·rices internautes, créant ainsi un écart entre les données ici rapportées et les données qui pourraient être collectées aujourd’hui. Une telle hypothèse ne peut toutefois pas être confirmée sans de nouveaux travaux orientés spécifiquement vers la validation empirique des profils.
Malgré le nombre limité de cas, cette recherche a pu faire le constat de données saillantes qui ont fait émerger des similarités et des distinctions franches entre les cas. Ces saillances ont mené à la proposition d’une hypothèse de profils qu’il sera nécessaire d’approfondir dans des recherches subséquentes, notamment par la validation empirique dans un contexte de classe.
Parties annexes
Note
-
[1]
Le terme « lecteur·rice internaute » est choisi parce qu’il permet à la fois de comprendre que nous étudions les lecteur·rices, donc la personne qui effectue une lecture(réception) d’informations, et le fait que cette lecture (réception) se passe en ligne.
Bibliographie
- Acerra, E. (2021, 22 avril). Fiche concept sur la Linéarité / non-linéarité. Lab-yrinthe. https://lab-yrinthe.ca/education/linearite-non-linearite
- Adenot, P. (2016). Les pro-am de la vulgarisation scientifique : de la co-construction de l’ethos de l’expert en régime numérique. Itinéraires. https://doi.org/10.4000/itineraires.3013
- Amadieu, F. & Tricot, A. (2006). Utilisation d’un hypermédia et apprentissage : deux activités concurrentes ou complémentaires ? Psychologie française, 51(1), 5-23. https://doi.org/10.1016/j.psfr.2005.12.001
- Amadieu, F., Tricot, A. & Mariné, C. (2011). Comprendre des documents non linéaires : quelles ressources apportées par les connaissances antérieures ? L’année psychologique, 111(2), 359-408. https://doi.org/10.4074/S0003503311002053
- Anderson, M. & Jiang, J. (2018). Teens, Social Media & Technology 2018. Pew Research Center. https://www.pewresearch.org/internet/2018/05/31/teens-social-media-technology-2018/
- Anmarkrud, Ø., McCrudden, M. T., Bråten, I. & Strømsø, H. I. (2013). Task-Oriented Reading of Multiple Documents: Online Comprehension Processes and Offline Products. Instructional science, 41(5), 873-894. https://doi.org/10.1007/s11251-013-9263-8
- Bilal, D. (2000). Children’s Use of the Yahooligans! Web Search Engine: I. Cognitive, Physical, and Affective Behaviors on Fact-Based Search Tasks. Journal of the American Society for Information Science, 51(7), 646-665. https://doi.org/10.1002/(SICI)1097-4571(2000)51:7<646::AID-ASI7>3.0.CO;2-A
- Bilal, D. (2001). Children’s Use of the Yahooligans! Web Search Engine: II. Cognitive and Physical Behaviors on Research Tasks. Journal of the American Society for Information Science and Technology, 52(2), 118-136. https://doi.org/10.1002/1097-4571(2000)9999:9999<::AID-ASI1038>3.0.CO;2-R
- Bilal, D. (2002). Children’s use of the Yahooligans! Web Search Engine: III. Cognitive and Physical Behaviors on Fully Self-Generated Search Tasks. Journal of the American Society for Information Science and Technology, 53(13), 1170-1183. https://doi.org/10.1002/asi.10145
- Brand-Gruwel, S., Wopereis, I. & Walraven, A. (2009). A Descriptive Model of Information Problem Solving While Using Internet. Computers et Education, 53(4), 1207-1217. https://doi.org/10.1016/j.compedu.2009.06.004
- Branca-Rosoff, S. (2007). Genres et activité langagière : l’exemple des tchats. Linx, 56, 127-141.
- Britt, M. A., Rouet, J.-F. & Durik, A. M. (2017). Literacy Beyond Text Comprehension. A Theory of Purposeful Reading. Routledge.
- Buccellati, G. (2008). Digital Text. Dans Digital Thought. http://urkesh.org/pages/312i.htm
- Burbules, N. C. & Callister, T. A. (2000). Watch IT. The Risks and Promises of Information Technologies for Education. Westview Press.
- Butterfuss, R. & Kendeou, P. (2017). The Role of Executive Functions in Reading Comprehension. Educational Psychology Review, 30(3), 801-826. https://doi.org/10.1007/s10648-017-9422-6
- Charters, E. (2003). The Use of Think-Aloud Methods in Qualitative Research: An Introduction to Think-Aloud Methods. Brock Education, 12(2), 68-82. https://doi.org/10.26522/brocked.v12i2.38
- Chen, H.-Y. (2009). Online Reading Comprehension Strategies Among General and Special Education Elementary and Middle School Students [Thèse de doctorat, Michigan State University). ERIC. https://eric.ed.gov/contentdelivery/servlet/ERICServlet?accno=ED506429
- Chen, C. & Rada, R. (1996). Interacting with Hypertext: A Meta-Analysis of Experimental Studies. Human-Computer Interaction, 11(2), 125-156. https://doi.org/10.1207/s15327051hci1102_2
- Chevalier, N. (2010). Les fonctions exécutives chez l’enfant : concepts et développement. Canadian Psychology, 51(3), 149-163. https://doi.org/10.1037/a0020031
- Chevry Pébayle, E. (2021). Pratiques informationnelles des youtubeurs scientifiques au service de la médiation du savoir. Communication, 38(2). https://doi.org/10.4000/communication.14808
- Claes, A. & Philippette, T. (2020). Defining Critical Data Literacy for Recommender Systems : A Media-Grounded Approach. Journal of Media Literacy Education, 12(3), 17-29. https://doi.org/10.23860/JMLE-2020-12-3-3
- Clark, R., Nguyen, F. & Sweller, J. (2006). Efficiency in Learning: Evidence-Based Guidelines to Manage Cognitive Load. Pfeiffer.
- Clément, É. (2006). Approche de la flexibilité cognitive dans la problématique de la résolution de problème. L’année psychologique, 106(3), 415-434. www.persee.fr/doc/psy_0003-5033_2006_num_106_3_30923
- Coiro, J. (2011). Predicting Reading Comprehension on the Internet: Contributions of Offline Reading Skills, Online Reading Skills, and Prior Knowledge. Journal of Literacy Research, 43(4), 352-392. https://doi.org/10.1177/1086296X11421979
- Coiro, J. (2007). Exploring Changes to Reading Comprehension on the Internet: Paradoxes and Possibilities for Diverse Adolescent Readers [Thèse de doctorat, University of Connecticut]. https://opencommons.uconn.edu/dissertations/AAI3270969/
- Coiro, J., Coscarelli, C., Maykel, C. & Forzani, E. (2015). Investigating Criteria that Seventh Graders Use to Evaluate the Quality of Online Information. Journal of Adolescent & Adult Literacy, 59(3), 287-297. https://doi.org/10.1002/jaal.448
- Coiro, J. & Dobler, E. (2007). Exploring the Online Reading Comprehension Strategies Used by Sixth-Grade Skilled Readers to Search for and Locate Information on the Internet. Reading Research Quarterly, 42(2), 214-257. http://dx.doi.org/10.1598/RRQ.42.2.2
- Coiro, J., Knobel, M., Lankshear, C. & Leu, D. J. (2008). Handbook of Research on New Literacies. Routledge.
- Commission mondiale d’éthique des connaissances scientifiques et des technologies – UNESCO. (2001). Sous-Commission de la COMEST sur l’éthique de la société de l’information, 18-19 juin 2001 [Rapport]. https://unesdoc.unesco.org/ark:/48223/pf0000124896_fre?posInSet=1&queryId=996c12b1-40d3-4f06-a183-73c0b1c27b2d
- Conseil supérieur de l’éducation. (2020). Éduquer au numérique. Rapport sur l’état et les besoins de l’éducation 2018-2020. Gouvernement du Québec. https://www.cse.gouv.qc.ca/wp-content/uploads/2020/12/50-0534-RF-eduquer-au-numerique-web_1.pdf
- Cordier, A. (2017). Grandir connectés. Les adolescents et la recherche d’information. C & F Éditions.
- Debue, N. & van de Leemput, C. (2014). What Does Germane Load Mean? An Empirical Contribution to the Cognitive Load Theory. Frontiers in Psychology, 5, 1099. https://doi.org/10.3389/fpsyg.2014.01099
- Demers, S., Bachand, C.-A. & Leblanc, C. (2016). Les approches inductives au service de l’agentivité épistémique et des finalités éducatives émancipatrices. Approches inductives, 3(2), 41-70. https://doi.org/10.7202/1037913ar
- Dewan, S. & Riggins, F. J. (2005). The Digital Divide: Current and Future Research Directions. Journal of Association for Information Systems, 6(2), 298-337. https://www.doi.org/10.17705/1jais.00074
- Doyle, W. (1983). Academic work. Review of Educational Research, 53(2), 159-199. https://doi.org/10.3102/00346543053002159
- Dumouchel, G. & Karsenti, T. (2017). Mon ami Google : une étude des pratiques des futurs enseignants du Québec en recherche d’information. La Revue canadienne de l’apprentissage et de la technologie, 43(2), 1-20. https://cjlt.ca/index.php/cjlt/article/view/27538/20242
- Duval, S., Bouchard, C.& Pagé, P. (2017). Le développement des fonctions exécutives chez les enfants. Les dossiers des sciences de l’éducation, 37, 121-137. https://doi.org/10.4000/dse.1948
- Eastin, M. S., Yang, M. S. & Nathanson, A. I. (2006). Children of the Net: An Empirical Exploration into the Evaluation of Internet Content. Journal of Broadcasting & Electronic Media, 50(2), 211-230. https://doi.org/10.1207/s15506878jobem5002_3
- Eisenberg, M. B. & Berkowitz, R. E. (1990). Information Problem-Solving: The Big Six Skills Approach to Library & Information Skills Instruction. Ablex Publishing Corporation.
- Falardeau, É., Pelletier, C. & Pelletier, D. (2014). La méthode de la pensée à voix haute pour analyser les difficultés en lecture des élèves de 14 à 17 ans. Éducation et didactique, 8(3), 43-54. https://doi.org/10.4000/educationdidactique.2022
- Fischer, H. (2013). Lire et écrire à l’ère du numérique. Relations, 767, 25-27. https://id.erudit.org/iderudit/69791ac
- Forget, M.-H. (2013). Le développement des méthodes de verbalisation de l’action : un apport certain à la recherche qualitative. Recherches qualitatives, 32(1), 57-80. https://doi.org/10.7202/1084612ar
- Gagnon, Y. C. (2012). L’étude de cas comme méthode de recherche. Presses de l’Université du Québec.
- Gauthier, C., Bissonnette, S., Richard, M. & Castongay, M. (2013). Enseignement explicite et réussite des élèves. Pearson.
- Gervais, B. & Saemmers, A. (2011). Présentation : esthétiques numériques. Textes, structures, figures. Protée, 39(1), 5-8. https://doi.org/10.7202/1006722ar
- Gonçalves, M. (2014). Similitudes et différences textuelles dans les genres numériques : blogue et site web. Studii de lingvistică, 4, 75-91. http://studiidelingvistica.uoradea.ro/docs/4-2014/articole%20pdf%20SL4/Goncalves.pdf
- Gouvernement de l’Ontario. (2023). Attentes et contenus d’apprentissage du programme-cadre de français de l’Ontario, de la 1re à 8e année. https://assets-us-01.kc-usercontent.com/fbd574c4-da36-0066-a0c5-849ffb2de96e/e58b0a61-bca4-4d75-9767-f42b1cae9a22/DomaineA_Francais.pdf
- Hämäläinen, E., Kiili, C., Räikkönen, E., Lakkala, M., Ilomäki, L., Toom, A. & Marttunen, M. (2023). Teaching Sourcing During Online Inquiry – Adolescents with the Weakest Skills Benefited the Most. Instructional science, 51, 135-163. https://doi.org/10.1007/s11251-022-09597-2
- Henry, L. A. (2007). Exploring New Literacies Pedagogy and Online Reading Comprehension Among Middle School Students and Teachers: Issues of Social Equity or Social Exclusion? [Thèse de doctorat, University of Connecticut]. Groupe de recherche en littératie médiatique multimodale. https://litmedmod.ca/sites/default/files/pdf/henry_2007_lecture_en_ligne_comprehension_litteratie.pdf
- Hilden, K. & Pressley, M. (2011). Verbal Protocols of Reading. Dans N. K. Duke & M. H. Mallette (dir.), Literacy Research Methodologies (p. 427-440). Guilford Press.
- Kaakinen, J. K. & Hyona, J. (2005). Perspective Effects on Expository Text Comprehension: Evidence from Think-Aloud Protocols, Eyetracking, and Recall. Discourse Processes, 40(3), 239-257. https://doi.org/10.1207/s15326950dp4003_4
- Karsenti, T. & Demers, S. (2011). La recherche en éducation : étapes et approches (3e éd.). ERPI.
- Karsenti, T. & Savoie-Zajc, L. (2018). La recherche en éducations : étapes et approches (4e éd.). Presses de l’Université de Montréal.
- Kiili, C., Bråten, I., Kullberg, N. & Leppänen, P. H. T. (2020). Investigating Elementary School Students’ Text-Based Argumentation with Multiple Online Information Resources. Computers & Education, 147, Article 103785. https://doi.org/10.1016/j.compedu.2019.103785
- Kintsch, W. (1998). Comprehension: A Paradigm for Cognition. Cambridge University Press.
- Kuiper, E. & Volman, M. (2008). The Web as a Source of Information for Students in K-12 Education. Dans J. Coiro, M. Knobel, C. Lankshear & D. J. Leu (dir.), Handbook of Research on New Literacies (p. 241-266). Routledge. https://doi.org/10.4324/9781410618894
- Lacelle, N., Boutin, J.-F.& Lebrun, M. (2017). La littératie médiatique multimodale appliquée en contexte numérique : outils conceptuels et didactiques. Presses de l’Université du Québec.
- Le Bigot, L. & Rouet, J.-F. (2007). The Impact of Presentation Format, Task Assignment, and Prior Knowledge on Students’ Comprehension of Multiple Online Documents. Journal of Literacy Research, 39(4), 445-470. https://doi.org/10.1080/10862960701675317
- Lebrun, M., Lacelle, N. & Boutin, J.-F. (2019). Inscription de la littératie médiatique multimodale dans l’enseignement du français : regard sur l’évolution d’une discipline. Dans A. Dias-Chiaruttin, & M. Lebrun (dir.), Recherches en didactique du français / La question de la relation entre les disciplines scolaires : le cas de l’enseignement du français. Presses universitaires de Namur.
- Le Crosnier, H. (2017). Tentative de délimitation de la culture numérique pour son usage dans l’institution scolaire. Hermès, La Revue, 78(2), 159-166. https://doi.org/10.3917/herm.078.0159
- Leu, D. J., Kiili, C., Forzani, E., Zawilinski, L., O’Byrne, W. I. & McVerry, J. G. (2021). New Literacies of Online Research and Comprehension. Dans C. A. Chapelle (dir.), The Encyclopedia of Applied Linguistics. John Wiley & Sons, Ltd. https://doi.org/10.1002/9781405198431.wbeal0865.pub2
- Lim, F. V. & Toh, W. (2020). How to Teach Digital Reading? Journal of Information Literacy, 14(2), 24-43. http://dx.doi.org/10.11645/14.2.2701
- Macedo-Rouet, M., Braasch, J. L. G., Britt, M. A. & Rouet, J.-F. (2013). Teaching Fourth and Fifth Graders to Evaluate Information Sources During Text Comprehension. Cognition and Instruction, 31(2), 204-226. https://doi.org/10.1080/07370008.2013.769995
- Macedo-Rouet, M., Salmerón, L., Ros, C., Pérez, A., Stadtler, M. & Rouet, J.-F. (2019). Are Frequent Users of Social Network Sites Good Information Evaluators? An Investigation of Adolescents’ Sourcing Abilities. Journal for the Study of Education and Development, 43(1), 101-138. https://doi.org/10.1080/02103702.2019.1690849
- Marchionini, G. (1989). Information-Seeking Strategies of Novices Using a Full-Text Electronic Encyclopedia. Journal of the American Society for Information Science, 40(1), 54-66. https://doi.org/10.1002/(SICI)1097-4571(198901)40:1<54::AID-ASI6>3.0.CO;2-R
- Martel, V. & Pleau, J. (2023, mai). Développement de la littératie (informationnelle) par le recours aux sources d’information analogiques et numériques. Communication présentée au 90e Congrès de l’Association canadienne-française pour l’avancement des sciences (ACFAS) : Colloque « La didactique au coeur des préoccupations éducatives actuelles », Montréal, Canada. https://www.acfas.ca/evenements/congres/programme/90/enjeux-recherche/39/c
- Mayer, R. E. (2005). Cognitive Theory of Multimedia Learning. Dans R. E. Mayer (dir.), The Cambridge Handbook of Multimedia Learning (p. 31-48). Cambridge University Press.
- Mayer, R. E. (2010). Applying the Science of Learning to Medical Education. Medical Education, 44(6), 543-549. https://doi.org/10.1111/j.1365-2923.2010.03624.x
- Mayer, R. E. (2017). Using Multimedia for E-Learning. Journal of Computer Assisted Learning, 33(5), 403-423. https://doi.org/10.1111/jcal.12197
- McCrudden, M. T., Magliano, J. P. & Schraw, G. (2011). Text Relevance and Learning from Text. Information Age Publishing.
- Merriam, S. B. (1988). Case Study Research in Education: A Qualitative Approach. Jossey-Bass.
- Michelot, F. & Poellhuber, B. (2019). Au-delà de l’utilitarisme : Vers une refondation des modèles de compétences informationnelles. Dans T. Karsenti (dir.), Le numérique en éducation : pour développer des compétences (p. 45-76). Presses de l’Université du Québec
- Ministère de l’Éducation et de l’Enseignement supérieur [MEES]. (2017). Indices de défavorisation des écoles publiques, 2016-2017 : Écoles primaires et secondaires. Gouvernement du Québec. http://www.education.gouv.qc.ca/fileadmin/site_web/documents/PSG/statistiques_info_decisionnelle/Indices_PUBLICATION_20162017_final.pdf
- Miyake, A., Friedman, N. P., Emerson, A. H., Howerter, A. & Wager, T. D. (2000). The Unity and Diversity of Executive Functions and their Contributions to Complex Frontal Lobe Tasks: A Latent Variable Analysis. Cognitive Psychology, 41, 49-100. http://dx.doi.org/10.1006/cogp.1999.0734
- Mossberger, K., Tolbert, C. J. & Stansbury, M. (2003). Virtual Inequality: Beyond the Digital Divide. Georgetown University Press.
- Norris, P. (2001). Digital Divide: Civic Engagement, Information Poverty, and the Internet Worldwide. Cambridge University Press.
- OECD (Ed.). (2013). PISA 2012 Assessment and Analytical Framework: Mathematics, Reading, Science, Problem Solving and Financial Literacy. OECD.
- OECD. (2014). PISA 2012 Technical Report. OECD Publishing. http://www.oecd.org/pisa/pisaproducts/PISA-2012-technical-report-final.pdf
- OCDE iLibrary. (2019). Résultats du PISA 2018 (Volume I) : Savoirs et savoir-faire des élèves. Éditions OCDE. https://doi.org/10.1787/ec30bc50-fr
- Oviedo-Trespalacios, O., Peden, A. E., Cole-Hunter, T., Costantini, A., Haghani, M., Rod, J. E., Kelly, S., Torkamaan, H., Tariq, A., Newton, J. D. A., Gallagher, T., Steinert, S., Filtness, A. & Reniers, G. (2023). The Risks of Using ChatGPT to Obtain Common Safety-Related Information and Advice. Safety Science, 167. http://dx.doi.org/10.2139/ssrn.4346827
- Paveau, M.-A. (2012). Genre de discours et technologie discursive. Tweet, twittecriture et twitterature. https://hal.archives-ouvertes.fr/hal-00824817
- Pleau, J. (2023). La compréhension de l’information en ligne par l’intégration, la navigation et l’évaluation : étude de cas d’internautes de 6e année du primaire [Thèse de doctorat, Université du Québec à Montréal]. 236p. https://archipel.uqam.ca/17037/1/D4448.pdf
- Pleau, J. (2017). Le texte à l’ère du numérique : analyse du concept de genre numérique. Revue canadienne des jeunes chercheures et chercheurs en éducation, 8(1), 144-149. https://journalhosting.ucalgary.ca/index.php/cjnse/article/view/30798
- Pleau, J. & Boutin, J.-F. (sous presse). Littératie informationnelle et sémiotisation de l’information par des internautes québécois du primaire. Recherches en Didactique du Français – AIRDF, 17.
- Pleau, J., Lacelle, N., Boutin, J.-F. & Lebrun, M. (2022). La lecture et l’écriture en contexte numérique. Dans I. Montesinos-Gelet, M. Dupin de Saint-André & O. Tremblay (dir.), La lecture et l’écriture : fondements et pratiques aux 2e et 3e cycles du primaire (tome 2), 285-302, Chenelière.
- Pleau, J. & Lavoie, N. (2016). Crayon ou clavier ? Effets de l’outil d’écriture sur les performances graphomotrices et rédactionnelles d’élèves de sixième année. Revue de recherches en littératie médiatique multimodale, 3. https://litmedmod.ca/crayon-ou-clavier-effets-de-loutil-decriture-sur-les-performances-graphomotrices-et-redactionnelles
- Potocki, A., de Pereyra, G., Ros, C., Macedo-Rouet, M., Stadtler, M., Salmerón, L. & Rouet, J.-F. (2020). The Development of Source Evaluation Skills During Adolescence: Exploring Different Levels of Source Processing and their Relationships. Journal for the Study of Education and Development – Infancia y Aprendizaje, 43(1), 19-59. https://doi.org/10.1080/02103702.2019.1690848
- Pressley, M. & Afflerbach, P. (1995). Verbal Protocols of Reading: The Nature of Constructively Responsive Reading. Laurence Erlbaum Associates.
- Puma, S. (2016). Optimisation des apprentissages : modèles et mesures de la charge cognitive [Thèse de doctorat, Université de Toulouse le Mirail]. HAL Archive ouverte. https://tel.archives-ouvertes.fr/tel-01735371/document
- Rallet, A. & Rochelandet, F. (2004). La fracture numérique : une faille sans fondement ? Réseaux, 5-6(127-128), 19-54. https://www.cairn.info/revue-reseaux1-2004-5-page-19.htm
- Reboul-Touré, S. (2020). À la recherche de nouvelles catégories pour l’analyse du discours – quand la vulgarisation scientifique passe par les blogues. Communication présentée au 7e Congrès Mondial de Linguistique Française. Paris, France. https://doi.org/10.1051/shsconf/20207801026
- Reviglio, U. (2019). Serendipity as an Emerging Design Principle of the Infosphere: Challenges and Opportunities. Ethics and Information Technology, 21, 151-166. https://doi.org/10.1007/s10676-018-9496-y
- Rizza, C. (2006). La fracture numérique, paradoxe de la génération Internet. Hermès, La Revue, 45(2), 25-32. https://www.doi.org/10.4267/2042/24031
- Rouet, J.-F. & Britt, A. (2011). Relevance Processes in Multiple Document Comprehension. Dans M. T. McCrudden, J. P. Magliano & G. Schraw (dir.), Text Relevance and Learning from Text (p. 19-52). Information Age Publishing.
- Salmerón, L., Naumann, J., García, V. & Fajardo, I. (2017). Scanning and Deep Processing of Information in Hypertext: An Eye Tracking and Cued Retrospective Think-Aloud Study. Journal of Computer Assisted Learning, 33(3), 222-233. https://doi.org/10.1111/jcal.12152
- Salmerón, L., Strømsø, H. I., Kammerer, Y., Stadtler, M. & van den Broek, P. (2018). Comprehension Processes in Digital Reading. Dans M. Barzillai, J. Thomson, S. Schroeder & P. van den Broek (dir.), Learning to Read in a Digital World (p. 91-120). John Benjamins Publishing Compagny.
- Simonnot, B. (2009). Culture informationnelle, culture numérique : au-delà de l’utilitaire. Les Cahiers du numérique, 3(5), 25-37. https://www.cairn.info/revue-les-cahiers-du-numerique- 2009-3-page-25.htm
- Stadtler, M. & Bromme, R. (2014). The Content-Source Integration Model: A Taxonomic Description of How Readers Comprehend Conflicting Scientific Information. Dans D. N. Rapp & J. Braasch (dir.), Processing Inaccurate Information: Theoretical and Applied Perspectives from Cognitive Science and the Educational Sciences (p. 379-402). MIT Press.
- Stake, R. E. (2006). Multiple Case Study Analysis. Guilford Press.
- Stake, R. E. (1995). The Art of Case Study Research. Sage Publications.
- Statistique Canada. (2017). Série « Perspective géographique », Recensement de 2016 [Produit no 98-404-X2016001]. Statistique Canada. https://www12.statcan.gc.ca/census-recensement/2016/as-sa/fogs-spg/Index-fra.cfm
- Sunderland-Smith, W., Snyder, I. & Angus, L. (2003). The Digital Divide: Differences in Computer Use Between Home and School on Low Socio-Economic Households. L1 – Educational Studies in Language and Literature, 3, 5-19. Kluwer Academic Publishers. https://core.ac.uk/download/pdf/213013939.pdf
- Troude-Chastenet, P. (2018). Fake news et post-vérité. De l’extension de la propagande au Royaume-Uni, aux États-Unis et en France. Quademi, 96(2), 87-101. http://journals.openedition.org/quaderni/1180
- Vandendorpe, C. (1999). Du papyrus à l’hypertexte : essai sur les mutations du texte et de la lecture. Éditions du Boréal.
- Verdi, U. & Le Deuff, O. (2020). La data literacy distribuée : périmètres définitionnels, origines documentaires, perspectives réticulaires. Les Cahiers du numérique, 16, 137-173. https://doi-org.ezproxy.uqar.ca/10.3166/LCN.2020.006
- Wiard, V., Huys, S., Vanneste, B., Collard, Y., Soudon, C., Gobert, O., Guffens, B. & Culot, M. (2020). #Génération2020 : les jeunes et les pratiques numériques. Média Animation ASBL. http://hdl.handle.net/2078.3/219733
- Wineburg, S., Breakstone, J., McGrew, S., Smith, M. D. & Ortega, T. (2022). Lateral Reading on the Open Internet: A District-Wide Field Study in High School Government Classes. Journal of Educational Psychology, 114(5), 893-909. https://doi.org/10.1037/edu0000740
- Wylie, J., Thomson, J., Leppänen, P. H. T., Ackerman, R., Kanniainen, L. & Prieler, T. (2018). Cognitive Processes and Digital Reading. Dans M. Barzillai, J. Thomson, S. Schroeder & P. van den Broek (dir.), Learning to Read in a Digital World (p. 58-90). John Benjamins Publishing Compagny.
- Yagoubi, A. (2020). Cultures et inégalités numériques : usages numériques des jeunes au Québec [Rapport]. Montréal, Printemps numérique : Jeunesse QC 2030. https://www.printempsnumerique.ca/wp-content/uploads/2018/02/Culture-et-inégalités-numériques-Usages-chez-les-jeunes-au-Québec.pdf
- Zurkowski, P. (1974). The Information Service Environment Relationships and Priorities. National Commission on Libraries and Information Science.
 10.7202/1037913ar
10.7202/1037913arListe des figures
Figure 1
Représentation de la charge cognitive en fonction des activités réalisées en ligne selon Bilal (2000, 2001, 2002) et Marchionini (1989), tirée de Pleau (2023)
Figure 2
Modèle de résolution de problème d’information sur Internet de Brand-Gruwel et al., 2009 (traduction libre de Pleau [2023])
Figure 3
Exemple de lecture transversale dans la matrice de Thomas (navigation A)
Figure 4
Occurrences des thématiques repérées dans les verbalisations des navigations A et B
Figure 5
Proportion du temps accordé aux activités en fonction de la durée des navigations pour chaque participant·e
Figure 6
Nombre de sites consultés par navigation pour chaque participant·e.
Liste des tableaux
Tableau 1
Description des phases du protocole expérimental
Tableau 2
Durée des vidéos analysées pour la rédaction des verbatims et la constitution des lignes du temps (horodatage des actions de navigation)
Tableau 3
Nombre de pages du corpus de données analysées
Tableau 4
Compilation des données démographiques des participant·es
Tableau 5
Verbalisation des connaissances antérieures des participant·es
Tableau 6
Répartition du nombre de thématiques explorées
Tableau 7
Répartition de stratégies de gestion de l’intégration des informations selon les cas
Tableau 8
Répartition de stratégies de navigation selon les cas
Tableau 9
Répartition des stratégies d’évaluation selon les cas