Résumés
Résumé
Après avoir passé en revue une grande partie de la documentation scientifique portant sur la narrativité en musique et dans d’autres formes d’expression non littéraires, l’auteur observe que la chanson enregistrée n’a pas véritablement fait l’objet d’études sérieuses du point de vue narratologique. Afin de combler en partie cette lacune, l’article propose une analyse de la chanson « Stan » du rappeur états-unien Eminem, dans le but de dévoiler le fonctionnement narratif de la chanson. En se concentrant sur les aspects performanciels et technologiques, l’analyse rend compte de la richesse du récit phonographique à l’oeuvre dans cet enregistrement, en considérant notamment les relations temporelles et spatiales, de même que les modes d’énonciation vocale.
Abstract
Any survey of the work done on narrativity in music as well as in other non-literary forms of expression will show that the narratological study of recorded songs has been widely neglected. In an attempt to partially fill that gap, I propose an analysis of “Stan”, by US rapper Eminem, which reveals the song’s narrative functioning. By focussing on both performative and technological aspects of the song, I will try to account for the richness of the recording’s phonographic discourse, taking into consideration, among other things, temporal and spatial relationships, as well as vocal modes of enunciation.
Corps de l’article
Introduction
« Peut-on parler de narrativité en musique ? », demandait Jean-Jacques Nattiez dans son article du même titre paru en 1990. Cette question, par ailleurs fort complexe, demande à ce que l’on commence par définir ce que l’on entend par « musique ». En effet, la très vaste majorité des écrits traitant de narrativité musicale se concentre sur la musique de tradition « classique » et savante, le plus souvent instrumentale, d’une part, et ne tient compte que des paramètres musicaux que j’appellerai « abstraits », puisque facilement notables (comme la mélodie, l’harmonie, la forme et, dans une certaine mesure, le rythme), d’autre part[2]. C’est d’ailleurs, à mon avis, l’une des raisons qui conduisent Nattiez à conclure « qu’en elle-même, et à la différence de bien des énoncés linguistiques, la musique n’est pas un récit et que toute description de ses structures formelles [les paramètres abstraits] en termes de narrativité n’est qu’une métaphore superflue » (1990 : 88)[3]. Je suis donc d’accord avec Nattiez, dans la mesure où l’on restreint ses conclusions au corpus de la musique instrumentale savante, ou, plus généralement, lorsqu’on l’applique à une conception idéale de la musique. Comme on le verra bientôt, la musique populaire enregistrée constitue un tout autre objet envers lequel il faudra adopter une attitude radicalement différente.
Depuis la parution de l’article de Nattiez, qui faisait le bilan des efforts musicologiques depuis les années 1970 jusqu’au début des années 1990 en matière de narrativité musicale[4], plusieurs auteurs ont poursuivi l’exercice[5]. Dans ce corpus, et même lorsqu’on fait référence à la musique vocale, la musique populaire est presque systématiquement exclue. On trouve un exemple éloquent de cette attitude dans la toute récente Routledge Encyclopedia of Narrative Theory. L’auteur de l’entrée « Music and Narrative », Werner Wolf (2005), définit la narrativité musicale selon trois classes de pratiques intermédiatiques, dont les combinaisons plurimédiatiques de musique avec d’autres médias narratifs non musicaux (par exemple, le cinéma ou l’opéra)[6]. C’est évidemment dans cette catégorie que l’on classerait la chanson populaire. Pourtant, non seulement l’auteur ne consacre qu’à peine dix-sept lignes à cette catégorie (alors que les deux autres classes se voient attribuer de deux à trois pages chacune), mais il n’y est de plus aucunement mention de chanson populaire[7] ; plus encore, l’auteur masque à peine ce qui semble constituer un jugement de valeur à propos de ces formes hybrides apparemment plus « simples » (Wolf, 2005 : 325). En plus de ne mentionner que des genres plus ou moins issus de la tradition « savante », cette définition (comme à peu près partout ailleurs) ne tient compte ni de l’aspect performanciel lié à la pratique musicale, ni des développements technologiques qui sont pourtant aujourd’hui partie intégrante de la vaste majorité des productions musicales. Cette façon de concevoir la musique est malheureusement représentative de la vaste majorité des écrits traitant de narrativité musicale[8]. De reconnaître la nature singulière de la chanson nous permettrait pourtant de l’aborder comme une pratique avec un fort potentiel narratif.
Outre la combinaison musique-paroles, la nature multimédiatique, ou plus précisément multi-artistique de la chanson enregistrée, est tout aussi caractérisée par la présence d’une performance multipliée (vocale et instrumentale), elle-même fixée et médiatisée au moyen des techniques d’enregistrement. De ce point de vue, la chanson enregistrée partage un ensemble de caractéristiques avec d’autres pratiques artistiques : d’abord, analogies avec des pratiques déjà relevées par Wolf, dont la littérature, et plus particulièrement la poésie, tant par sa forme brève que par le recours à certaines stratégies textuelles communes (formes répétitives, correspondances sonores, etc.) ; analogies aussi avec certaines formes vocales de musique savante (comme le lied ou l’opéra). Mais la chanson enregistrée présente d’autres analogies également importantes avec d’autres formes d’expression ; par exemple, avec le théâtre, de par l’importance de l’interprétation, de la performance ; ou encore avec le cinéma ou la dramatique radiophonique, de par le recours, entre autres, à diverses techniques de montage. C’est en fait l’exploration de certaines de ces analogies, dans l’analyse qui va suivre, qui devrait faire ressortir, je l’espère, la singularité de la chanson populaire enregistrée, singularité qui émerge justement de son mode d’existence particulier qui a plus à voir avec ces pratiques multimédiatiques qu’avec une conception plus traditionnelle de la musique « pure ».
D’autres auteurs, pourtant tout à fait conscients du rôle crucial de la médiation de la technologie dans certaines formes d’expression, omettent ou méjugent les possibilités offertes par l’enregistrement sonore. Par exemple, dans son effort pourtant tout à fait louable de proposer une narratologie transversale des médias, Marie-Laure Ryan suggère que les technologies de l’enregistrement sonore n’ont pas été exploitées du point de vue narratif :
Bien qu’il aurait pu devenir le support d’un nouveau genre narratif, on a d’abord et avant tout utilisé le gramophone pour enregistrer la musique ou l’opéra. Autrement dit, on s’en est servi comme outil de transmission et de reproduction plutôt que d’exploiter son potentiel créatif.
2005 : 290-291. Notre traduction : nt[9]
Bien que, pour des raisons d’ordre essentiellement technique, il soit vrai en partie qu’on exploitait assez peu le potentiel créatif des techniques d’enregistrement avant l’avènement de l’enregistrement « électrique » (dans les années 1920), il est clair que, dès les années 1930, pour ce qui est de la poésie sonore du moins (Lacasse, 2000 : 79-81), de même que dès les années 1940 et 1950 pour la musique concrète (ibid. : 81-82) ou même la musique populaire, on commence à mettre à profit les nouvelles possibilités offertes par le média (techniques de prise de son ; effets d’écho et de réverbération ; enregistrement multipiste ; etc.), et ce, à des fins résolument expressives[10].
Aussi, dans ce qui suit, je propose d’illustrer, par l’analyse d’une chanson enregistrée, quelques stratégies narratives mises à l’oeuvre en montrant comment la technologie contribue à mettre en forme, à actualiser le récit. Je montrerai aussi comment la performance vocale (et sa « mise en scène ») participe aussi étroitement à l’articulation de ce récit que je qualifierai de « phonographique ». Pour l’analyse, j’ai porté mon choix sur une chanson fort controversée du rappeur Eminem : « Stan », figurant sur l’album The Marshall Mathers LP (2000)[11]. Pourquoi cette chanson plutôt qu’une autre ? Principalement parce « Stan » constitue un exemple frappant d’un récit exploitant les possibilités offertes par la technologie et qui met en scène des personnages en situation dramatique dans une sorte de film acousmatique[12]. Évidemment, ce n’est pas le cas de toutes les chansons (bien que…)[13]. Toutefois, en me concentrant sur un exemple à ce point représentatif, j’espère ouvrir la voie à une réflexion qui permettra d’aborder différemment le répertoire. Mais avant de plonger dans l’analyse proprement dite, il convient de nous entendre sur un certain nombre de notions qui permettront d’aborder la chanson enregistrée en tenant compte de ses particularités.
Définitions
Récit phonographique
Dans Performing Rites, Simon Frith propose d’aborder toute chanson comme un récit :
De façon implicite, toutes les chansons sont des récits : elles comportent un personnage principal, l’interprète, soit un personnage adoptant une attitude, faisant face à une situation, s’entretenant avec quelqu’un (si ce n’est qu’avec lui-même). C’est là une des raisons qui font dire à Leon Russelson que les chansons ne sont pas des poèmes : de ce point de vue, « la chanson est théâtre ».
1996 : 169-170. nt[14]
À mon avis, et comme je l’ai déjà suggéré, bien que la chanson enregistrée soit en plusieurs points comparables au théâtre, elle me semble plus proche du cinéma, notamment à cause du rôle central joué par la technologie.
J’ai soumis ailleurs ma vision tripartite de ce que constitue une chanson enregistrée (Lacasse, 2005a-b). En bref, il s’agit d’un ensemble de performances vocales et instrumentales (paramètres performanciels) exécutant un texte, des lignes mélodiques, des rythmes, des accords, etc. (paramètres abstraits), le tout médiatisé par les techniques d’enregistrement (paramètres technologiques). En fait, lorsqu’on écoute une chanson enregistrée, on a accès à une sorte de scène acousmatique virtuelle sur laquelle évoluent différents éléments. J’appelle « mise en scène phonographique » le résultat de ce processus de médiation. Par exemple, par le truchement des techniques d’enregistrement, et un peu à la manière du montage ou des prises de vue en cinéma, on peut entendre très clairement une voix pourtant chuchotée (sorte de gros plan acoustique) superposée à un son de guitare électrique presque imperceptible (bien que produit à un niveau sonore très élevé au moment de la prise de son). Outre ces effets de dynamique, ces techniques de prise de son et de mixage permettent également d’effectuer toutes sortes de manipulations d’ordres temporel (superposition d’événements sonores), spatial (ajout de réverbération pour créer l’impression d’un espace) ou « timbral » (transformation du timbre d’une voix qui paraît soudainement provenir du combiné d’un téléphone par exemple)[15].
Dans ce contexte, je propose d’aborder la chanson enregistrée comme un « récit phonographique », c’est-à-dire un récit dont l’articulation n’est pas restreinte au seul texte chanté et à son contenu sémantique, mais bien à l’ensemble des paramètres (abstraits, performanciels et technologiques). Comme c’est le cas dans la chanson à l’étude, tous ces paramètres contribuent à suggérer l’espace où survient l’action (à l’aide d’effets comme la réverbération, ou par le recours à des effets sonores, comme le son de la pluie), le déroulement du temps, ou les émotions ressenties par les personnages (par exemple, par le biais d’éléments paralinguistiques). Cette structure de médiation, proche de celle de la dramatique radiophonique ou du film cinématographique, nous conduit à pousser notre analogie un peu plus loin en abordant la notion de « personnage ».
Personne, persona, personnage
Frith propose d’aborder les artistes de musique populaire un peu comme des acteurs de cinéma : dans les films, le personnage incarné par l’acteur est toujours contaminé, en quelque sorte, par l’aura médiatique de l’acteur lui-même ; il appelle ce phénomène « double enactment »[16]. Ainsi, dans le contexte d’une performance vocale, Frith en vient à « diviser » l’artiste pop en trois strates qui interagissent :
En premier lieu, on retrouve le personnage présenté comme le protagoniste de la chanson, son interprète et son narrateur : l’être implicite qui contrôle l’action en adoptant une attitude et un ton spécifiques. Mais il peut y avoir aussi un personnage « cité », celui dont il est question dans la chanson […]. Superposé à ces personnages, on trouve la personnalité de l’interprète comme star, avec tout ce que l’on connaît à son sujet, ou plutôt, tout ce que l’on a bien voulu nous laisser croire à son sujet par le biais de la publicité et de la mise en marché. Finalement, s’ajoute notre représentation de l’interprète en tant que personne, telle que nous aimons bien nous l’imaginer, et qui nous est révélée, en fin de compte, par sa voix.
1996 : 198-199. nt
En conséquence :
L’acte de chanter, conçu comme agencement de manifestations vocales, c’est à la fois incarner le protagoniste de la chanson (avec les émotions appropriées pour ce rôle), incarner la star (en adéquation avec l’image à projeter), le tout en laissant transparaître une partie de l’être véritable : un corps physique produisant des sons physiques ; […] une présence physique qui déborde les contraintes formelles de la performance.
Ibid. : 212. nt
Philip Auslander propose de systématiser cette tripartition, notamment en renommant chacune des strates (que je traduis à mon tour) : la véritable personne, la persona de l’artiste et le(s) personnage(s) incarné(s) dans les chansons (Auslander, 2004 : 6).
Lorsque appliqué à un artiste tel qu’Eminem, ce modèle simple est particulièrement révélateur. En effet, non seulement Eminem subdivise-t-il lui-même de façon explicite son « être public » en ces trois strates, mais tout son jeu consiste précisément à rendre floues les frontières entre les trois. Cohabitent ainsi la personne Marshall Mathers (né le 17 octobre 1972 à St. Joseph, MO), la persona Eminem (dont le nom dérive d’un jeu de sonorités avec les initiales de Marshall Mathers, M&M) et les différents personnages incarnés dans les chansons, en particulier celui de Slim Shady. Ce dernier donne d’ailleurs l’occasion à Mathers de laisser s’exprimer son côté sombre (qui découle apparemment de ses expériences personnelles, souvent difficiles), stratégie à l’origine de la plupart des controverses entourant le travail du rappeur[17].
Notre analyse de la chanson « Stan » nous permettra à la fois d’identifier les différents personnages mis en scène dans la chanson (notamment le personnage central de Stan, qui correspond au « personnage cité » identifié par Frith), et de relever les diverses stratégies mises de l’avant (performancielles et technologiques) pour articuler leurs discours. L’un des aspects qui seront abordés concerne le traitement spatiotemporel du récit. À cet égard, la notion de son supradiégétique s’avérera fort utile.
Le son supradiégétique
Que nous abordions le discours chansonnier d’un point de vue strictement verbal (le texte) ou davantage dramatique (en tenant compte de la performance et de la « mise en scène phonographique »), nous sommes toujours confrontés à une particularité du genre : l’assujettissement du discours et de son énonciation au rythme et, plus généralement, au cadre musical de la chanson. Comment traiter, d’un point de vue narratologique, la présence d’un accompagnement musical dans une chanson ? Comment justifier, par exemple, le fait que le texte énoncé par un personnage soit soumis à la fois aux règles de la prosodie, à une courbe mélodique et à la pulsation imposée par le rythme ? Comment aborder les instruments que l’on entend en même temps que le discours chanté (ou rappé) ? De façon plus précise, dans la mesure où ces paramètres agissent sur notre perception de la temporalité d’une chanson et de l’environnement immédiat des protagonistes qui l’habitent, comment s’intègrent-ils (ou non) à la diégèse ?
Un genre cinématographique bien connu présente un problème analogue : la comédie musicale. Au cinéma, on distingue traditionnellement le son et la musique intradiégétiques (accessibles aux personnages, comme un orchestre jouant au cours d’une soirée à laquelle ces personnages participent) de la musique extradiégétique (non accessible aux personnages, responsable de l’« atmosphère émotive » du film). Mais qu’advient-il lorsqu’un personnage, par exemple, se met à chanter en gambadant dans la forêt, et qu’un accompagnement musical nous fait soudainement entendre un ensemble d’instruments manifestement absents du strict espace diégétique ? Le théoricien du cinéma Rick Altman aborde le problème en ces termes :
Mais peut-on dire que la chanson fait partie de la bande diégétique ? Elle semble être le fait du personnage dont les mouvements des lèvres correspondent aux paroles, elle a l'air de constituer un son diégétique. [...]Du point de vue de la source et de la motivation, elle relève de la piste diégétique, mais si l'on considère son type de production et l'effet général, elle appartient à la piste musicale [extradiégétique].
1992a : 78
À ce problème, Altman propose la solution d’ajouter un nouvel espace qui chevaucherait l’intra- et l’extradiégétique : le supradiégétique. Selon ce schéma, ce n’est plus la musique qui accompagne l’action, mais plutôt les éléments de l’action qui deviennent subordonnés au rythme musical :
À ce moment, les événements de la diégèse répondent à un nouveau type de motivation. Les sons diégétiques disparaissent, les seuls qui sont maintenus à un volume normal sont ceux qui marquent la mesure, c'est-à-dire ceux qui sont soumis à la musique (claquettes, battements de mains, sons rythmiques naturels).
Ibid. : 84
Ce rapprochement avec la comédie musicale n’est pas fortuit, comme le suggère d’ailleurs Simon Frith, qui considère la chanson comme « une mini-comédie musicale » (1996 : 211). D’une façon générale, on pourrait postuler que les chansons enregistrées se conforment à ce jeu supradiégétique : on pourrait ainsi aborder toute chanson comme un récit, avec une diégèse à l’intérieur de laquelle chacun des éléments du discours narratif ou dramatique est assujetti aux règles musicales. C’est entre autres afin de mieux faire voir l’intérêt analytique de cette approche que j’ai choisi de me pencher sur une chanson qui exploite de façon explicite ce jeu supradiégétique, établissant ainsi une analogie plus marquée entre le cinéma et la chanson enregistrée. Comme nous le verrons maintenant, dans « Stan », même les éléments naturels, aussi déchaînés soient-ils, se soumettent à la loi musicale, le tout au service du récit.
Analyse
Intrigue et structure générale du récit
« Stan » raconte l’histoire tragique d’un admirateur (fictif) d’Eminem devenu pathologiquement fanatique ; à tel point qu’il en vient à confondre (à l’instar de plusieurs détracteurs du rappeur…) le personnage de Slim Shady avec la persona d’Eminem. Il écrit ainsi plusieurs lettres à Slim Shady, lettres auxquelles Eminem voudra répondre, mais trop tard : ne recevant pas assez rapidement de réponses à ses missives, et croyant que Shady l’ignore complètement, Stan décide de commettre un crime en s’inspirant de gestes semblables posés par Slim Shady (gestes racontés dans « Kim » et « 97’ Bonnie and Clyde »)[18]. Il enferme ainsi sa femme (par ailleurs enceinte) dans le coffre arrière de sa voiture et se jette avec elle dans un cours d’eau au moment de passer un pont. Il enregistre la scène sur son dictaphone, qui sera d’ailleurs retrouvé une fois la voiture et les corps repêchés.
L’histoire de Stan est racontée sous la forme d’un récit épistolaire divisé en quatre couplets. Dans les deux premiers, on entend le personnage de Stan écrire ses lettres à Shady sur un ton de plus en plus réprobateur. Le troisième couplet nous fait entendre l’enregistrement qu’a fait Stan dans sa voiture au moment de l’accident volontaire, sorte de lettre sonore dans laquelle Stan exprime tout son dégoût et sa rage envers Shady qui l’a profondément déçu et, selon lui, trahi. Après l’accident, la chanson se clôt sur le quatrième couplet dans lequel Eminem, ignorant que Stan n’est plus de ce monde, répond finalement à ce dernier : ce n’est qu’au moment d’achever la rédaction de sa lettre qu’Eminem réalise que l’individu manifestement perturbé à qui il est en train d’écrire est en fait ce fanatique assassin dont il a entendu parler deux semaines plus tôt dans les médias : « Damn ! », s’exclame-t-il à la toute fin de la chanson[19].
Schéma formel
Le schéma formel de « Stan » est donné à la page suivante[20]. Au bas de chacun des systèmes, dont les éléments sont groupés par des accolades, se trouve un axe de repère formel où sont identifiées les sections de la chanson (couplets, refrains, pont, etc.), les mesures (chaque petite ligne verticale descendante représentant une barre de mesure de quatre temps[21]), de même que le minutage (la chanson s’étendant de 0:00 à 6:44). Pour faciliter le repérage, les indications de minutage coïncident avec des moments significatifs de la structure formelle, moments par ailleurs soulignés par la présence de barres de mesure verticalement plus longues. Par exemple, dans le premier système, l’indication « 0:24 » correspond au moment où l’instrumentation complète de la chanson fait son entrée. Comme bien souvent en musique populaire, ces sous-divisions correspondent à des groupes hypermétriques de quatre ou huit mesures.
Figure 1
Schéma formel de « Stan » (2000)
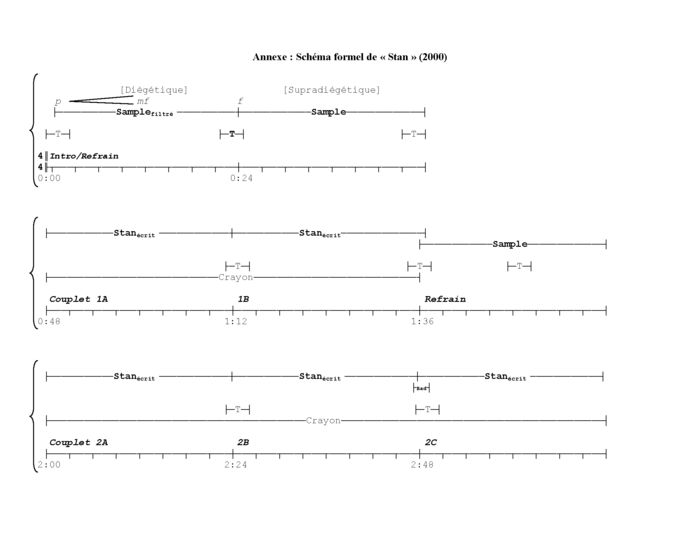
Figure 1 (suite)

Les différents segments étiquetés |——Sample——|, qui sont placés au-dessus de cet axe de repère formel, renvoient à des événements sonores bien précis entendus au cours de l’enregistrement. Pour faciliter la lecture (en évitant, par exemple, la superposition d’événements simultanés), j’ai choisi de répartir ces événements sonores sur deux strates principales : une strate « vocale » d’abord, et une seconde, où sont regroupés des effets sonores sans manifestations vocales. Ainsi, les segments étiquetés « Stan » et « Eminem » représentent les lignes vocales exécutées par les deux personnages centraux de la chanson (tous deux interprétés par Eminem ou, si l’on préfère, par Marshall Mathers). Le segment « Sample » renvoie, quant à lui, à l’extrait de la chanson « Thank You » (1999) de l’artiste britannique Dido, extrait qui a été inséré dans « Stan » et qui tient lieu de refrain[22]. Cette strate vocale inclut également les cris poussés par la femme enfermée dans le coffre arrière (4:30-4:55). Sous cette strate vocale, j’ai placé différents effets sonores entendus au fil de la chanson : le tonnerre (T), le son d’un crayon glissant sur le papier, celui des essuie-glaces, de même que les bruits liés à l’accident (« Crash » et « Eau » survenant entre 4:48 et 5:00)[23].
Temps et espace
Relations supradiégétiques : le tonnerre
Comme l’illustre bien notre schéma formel, le temps d’une chanson enregistrée est littéralement mesuré : il est divisé et subdivisé en mesures et en temps musicaux (noires, croches, etc.), selon une pulsation rythmique qui régule l’ensemble des événements sonores. Ainsi, les sections formelles débutent et se terminent généralement à des moments précis ; c’est aussi en fonction de cette division rythmique que s’articulent et s’agencent les exécutions vocales et musicales, et même la plupart des effets sonores. Comme on l’a vu, c’est précisément cette dimension rythmique mesurée qui donne lieu à un univers où peuvent s’établir des rapports d’ordre supradiégétique entre les aspects musicaux et les autres éléments de la diégèse, un univers dans lequel tout (ou presque) s’échafaude et se combine au gré d’une pulsation maîtresse.
Selon Altman, dans la comédie musicale, c’est en partie cette étrange interaction qui permet d’explorer des rapports souvent inédits entre l’imaginaire et le réel :
Dans les oeuvres relevant d’autres genres [que la comédie musicale] , les pistes musicale et diégétique restent totalement séparées ; dans la comédie musicale elles se livrent à un chassé-croisé permanent. La musique s’infiltre dans la bande diégétique, des bruits diégétiques se transforment en musique. [...]En abattant la barrière entre les deux pistes, la comédie musicale brouille la frontière entre la réalité et l’idéal.
1992a : 77
Ce rapport particulier qu’entretient la comédie musicale avec la réalité et l’idéal m’apparaît tout aussi caractéristique de l’enregistrement qui nous intéresse. En effet, et comme le montre le schéma formel de « Stan », même les coups de tonnerre sont soumis à l’emprise du rythme musical et semblent tenir lieu de ponctuation structurante. En plus des coups de tonnerre qui ouvrent et closent la chanson, on retrouve tous ceux qui surviennent lors du passage d’une section formelle à une autre[24]. Ce rôle de ponctuation est même observable à l’intérieur de la plupart des couplets, comme pour marquer les groupes hypermétriques de huit mesures évoqués plus haut. De plus, à certains endroits dans les refrains, la batterie s’arrête momentanément, comme pour laisser une place au tonnerre, autre indice des rapports intimes qui s’établissent entre effets sonores et musique : les sons diégétiques sont maintenant absorbés, en quelque sorte, par le cadre musical supradiégétique. Mais à quel moment ce passage du diégétique au supradiégétique s’opère-t-il ?
C’est le coup de tonnerre le plus intense qui joue peut-être le rôle de transition le plus important, soit celui soulignant la division de l’introduction en deux parties (0:24), et, du même coup, le passage du son (et de la musique) diégétique au supradiégétique[25]. En effet, les 24 premières secondes de la chanson s’ouvrent, comme je l’ai dit, sur un coup de tonnerre, immédiatement suivi par l’extrait de la chanson de Dido, le tout superposé au son de la pluie. Or, l’extrait de « Thank You » est manipulé (d’où la mention « filtré » en indice dans le schéma), de telle sorte qu’on a l’impression qu’il provient d’un endroit spécifique dans la diégèse, du moins autant que faire se peut en situation acousmatique : peut-être d’un poste de radio ou de télévision, ou encore d’une chaîne stéréo éloignée de nous. Plus encore, et comme le montre l’épingle croissante du signe de crescendo sur le schéma, le niveau sonore de l’extrait augmente, passant approximativement de la nuance piano à mezzo forte, comme si on s’en approchait. Cette mise en scène nous suggère donc une musique qui semble d’abord intégrée à la diégèse, au même titre que le tonnerre et la pluie. Puis, lorsque survient le grand coup de tonnerre (0:24), l’extrait se trouve soudainement accompagné d’une section rythmique supplémentaire (batterie et basse) et de guitares, prenant ainsi l’avant-scène. C’est à partir de ce moment qu’on observe que tous les éléments de la diégèse sonore sont soumis au rythme qui impose l’extrait soutenu par cette nouvelle instrumentation[26].
Cette façon d’opérer la transition entre une musique intra- puis supradiégétique est d’ailleurs très semblable à ce qu’Altman a observé dans les comédies musicales. Altman montre bien que le passage du diégétique au supradiégétique s’opère le plus souvent par le biais de ce qu’il appelle un « fondu sonore » :
Les événements qui semblent se dérouler selon un processus entièrement causal glissent [...],grâce au fondu sonore, vers la réduction du son diégétique et l'introduction d'une musique supra-diégétique transcendante.
1992a : 84
Dans notre chanson, le tonnerre contribue manifestement à la transition (plus soudaine, j’en conviens, mais tout de même présente), tout en annonçant, d’une façon plus métaphorique cette fois, que l’histoire que l’on s’apprête à raconter n’est pas nécessairement joyeuse.
En effet, en plus de ce rôle formel structurant, le tonnerre semble aussi avoir une fonction connotative. Un peu à la manière d’anciens films gothiques ou d’épouvante, ou de leurs caricatures, l’orage qui gronde et les coups de tonnerre bien placés agissent comme un commentaire sur l’action, ou en enrichissent la portée émotive. Tout d’abord, il me semble important de souligner le rapprochement, d’une part, entre l’orage qui gronde à l’extérieur et, d’autre part, la musique, au tout début, qui semble provenir d’un endroit spécifique à l’intérieur[27] . Fait intéressant, les paroles de l’extrait de « Thank You » font référence à une fenêtre (window), lieu de transition par excellence, justement, entre le monde extérieur et l’intérieur[28]. D’ailleurs, lorsqu’on compare l’enregistrement original de la chanson de Dido avec l’extrait inséré dans « Stan », on se rend compte qu’un effet d’écho a été ajouté au mot window dans l’extrait figurant dans « Stan », effet qui fait ressortir le mot (et donc l’allusion) encore davantage. Un autre coup de tonnerre bien placé survient vers 1:12 sur le mot « Bonnie », soit au moment où Stan annonce à Slim Shady que sa femme est enceinte et que, si c’est une fille, elle s’appellera Bonnie, en l’honneur de la fille de Slim Shady[29]. Le coup de tonnerre sur le mot « Bonnie » suggère ainsi un malaise, et annonce, par le truchement d’un lien intertextuel et transfictionnel, le malheur à venir, lui aussi inspiré par l’acte criminel raconté dans « 97’ Bonnie and Clyde ».
Ordre et durée
Contrairement au récit littéraire, qui « n’a pas d’autre temporalité que celle qu’il emprunte, métonymiquement, à sa propre lecture » (Genette, 1972 : 78), la durée d’une chanson enregistrée, à l’instar d’autres manifestations qui se déroulent « dans le temps » (film, concert, pièce de théâtre, etc.), est fixe[30]. Dans le cas qui nous occupe, le récit « dure » exactement 6 minutes et 44 secondes. Bien entendu, cette durée ne correspond pas au « temps » de l’histoire racontée, laquelle, selon les indices fournis par l’enregistrement et le texte, semble s’étendre sur une période d’au moins six mois, soit entre le moment où Stan écrit sa première lettre au début de la chanson et celui où Eminem achève la sienne à la toute fin[31].
Comme je l’ai rapidement évoqué plus haut, le récit est structuré en quatre couplets entrecoupés par le retour du refrain. D’un point de vue dramatique, l’action de chacun des couplets se déroule à des moments différents ayant leur durée propre. Le récit phonographique découpe donc l’histoire en segments, que j’appellerai, par analogie avec le cinéma, des « séquences ». Ce fractionnement elliptique ne présente toutefois pas d’anachronies : il s’agit simplement de quatre séquences isolées qui sont ordonnées de façon chronologique et qui sont séparées par d’importantes ellipses[32]. Tous les refrains qui suivent les couplets (et le pont) jouent donc un rôle de transition entre les différentes séquences dramatiques (j’y reviendrai). En même temps, et comme pour donner une unité thématique (bien qu’idéale) à cet ensemble par ailleurs segmenté, la pluie et le tonnerre sont présents tout au long de la chanson, donnant ainsi l’impression que l’orage gronde sans relâche depuis six mois, ou encore que Stan a subi un mauvais sort et que son personnage est irrémédiablement lié au mauvais temps (un trope tout à fait conforme aux genres fictionnels dont semble relever la chanson).
Toutes ces séquences ont lieu à des moments et en des endroits spécifiques relativement identifiables : nous nous trouvons vraisemblablement chez Stan, dans les deux premiers couplets ; dans sa voiture, dans le troisième ; et finalement chez Eminem, dans le quatrième (bien que ce dernier puisse se trouver n’importe où, considérant qu’il effectue tournée après tournée). De plus, l’intervalle de temps plus ou moins mesurable qui s’écoule entre chacun de ces moments permet de justifier la colère grandissante de Stan vis-à-vis d’Eminem, une colère qui s’entend de plusieurs façons, comme notre analyse des modes de représentation et des voix l’illustrera.
Modes et voix
Comme au théâtre, au cinéma ou à la radio, la chanson enregistrée permet de « montrer » (de façon acousmatique) l’action. Bien que plusieurs chansons mettent en scène un narrateur racontant, en partie ou en totalité, une histoire, la chanson à l’étude est construite sur le mode de la représentation dramatique : on nous y présente des « tranches » d’action – chacune, comme on l’a vu, se déroulant en temps réel à des moments et en des lieux différents –, durant lesquelles interviennent des personnages dont on entend le discours. Ce discours « direct » est cependant de deux types : discours intérieur, lorsque Stan ou Eminem écrivent leurs lettres (indiqué par la mention « écrit » en indice dans le schéma formel) ; et discours prononcé, lorsque Stan s’enregistre au moment de l’accident dans le troisième couplet (incluant les cris de sa femme), ou lorsque Eminem prononce « Damn ! » (indiqué par la mention « parle » dans le schéma).
Ici encore, le recours aux techniques d’enregistrement permet de mettre phonographiquement en scène ces différentes formes de discours, en plus de rendre audibles les émotions ressenties et exprimées par les personnages. Bien que la chanson enregistrée soit une forme d’expression acousmatique, il est tout à fait possible de manipuler les voix de façon à ce qu’elles semblent présentes ou non dans le cadre de la scène sonore virtuelle (par exemple, en jouant avec des effets stéréophoniques ou en altérant le timbre de façon significative), ou afin de suggérer que le discours soit effectivement prononcé, ou énoncé intérieurement. Ce sont ces différentes configurations que nous allons maintenant aborder, selon que les voix sont intérieures ou prononcées à voix haute[33].
Voix intérieures
Lorsque les personnages de Stan et d’Eminem rédigent leurs lettres, nous entendons leur voix respective. Or, il est plus que probable que le discours entendu ne soit pas prononcé à voix haute ; plutôt, il s’agit simplement d’une représentation sonore du texte en train d’être rédigé par l’auteur de chacune des lettres. Parmi les indices qui nous indiquent que ces voix sont intérieures, mentionnons la présence de réverbération dans la voix, de même que le son du crayon glissant sur le papier. En effet, la réverbération qui affecte les voix de Stan et d’Eminem, lorsqu’ils écrivent, fait en sorte de situer leurs voix dans un environnement sonore détaché de celui où ils se trouvent physiquement. Dans les deux cas, le son du crayon n’est affecté d’aucune réverbération, suggérant qu’un énoncé à voix haute dans le même environnement n’en serait pas affecté non plus, ce qui n’est pas le cas. De plus, le niveau sonore élevé du crayon suggère que le point d’écoute est tout près du personnage : une telle proximité ne donnerait pas lieu à une voix réverbérée. En fait, tout se passe comme si ce que l’on entend correspondait à ce que le sujet entend lui-même au moment d’écrire sa lettre : les sons de son environnement physique immédiat (le crayon tout proche, l’orage, la musique de Dido – par ailleurs devenue supradiégétique), de même que son propre discours, qu’il objective, en quelque sorte, comme le suggère la réverbération qui détache cette voix de l’environnement physique du sujet. Cet effet de mise en scène vocale est différent des cas où le discours est prononcé à voix haute.
Voix prononcées
Pour Jean Châteauvert,
[...] le dialogue correspond à la forme canonique de discours [filmique], prononcé à voix haute dans la diégèse visualisée, et qui est potentiellement accessible à tout personnage se trouvant dans le même environnement.
1996 : 142
Comme l’indique le mot « potentiellement » de cette définition, et en dépit de ce que suggère son appellation, le dialogue n’exige pas la présence effective de deux ou de plusieurs personnes : il s’agit plutôt d’un énoncé « qui peut prendre la forme d’un dialogue effectif ou d’un monologue à voix haute, susceptibles, l’un comme l’autre, d’être entendus par tout personnage figurant dans cet environnement » (ibid.). Ici, le mot « environnement » est crucial : en effet (et contrairement à la voix intérieure dont on vient de parler), puisque le dialogue a lieu dans un environnement, le son de la voix devient automatiquement « teinté » par cet environnement, conférant à la voix ce que Rick Altman appelle une « signature spatiale »[34].
Dans le troisième couplet, Stan s’enregistre lui-même à voix haute alors qu’il conduit sa voiture. Sa voix est alors potentiellement accessible aux autres personnages partageant son espace diégétique. Aussi entreprend-il une sorte de double dialogue : d’abord, un dialogue indirect avec Slim Shady à travers le dictaphone ; ensuite avec sa femme (« Shut up bitch ! », 4:31-4:32), qui est enfermée dans le coffre arrière et qui pousse des cris pendant l’enregistrement. Dans ce contexte, la voix de Stan résonne tout à fait comme si elle émanait de l’habitacle d’une voiture, tout comme la voix de sa femme, dont le timbre a été altéré de façon à donner l’impression qu’elle provient du coffre, et donc qu’elle est située à une certaine distance du dictaphone. On pourrait même aller jusqu’à considérer la voix de Stan comme étant in et celle de sa femme comme étant hors champ (off), comme le suggère leur signature spatiale respective. De plus, le son des essuie-glaces, superposé à celui de la pluie, contribue au réalisme de la séquence, qui débouche sur l’accident (4:48-5:00), lui aussi représenté de façon réaliste avec les bruits de pneus qui crissent avant l’impact et la plongée dans le cours d’eau. Toutefois, et comme le montre le schéma formel, ce réalisme est constamment fragilisé, puisque tous ces sons demeurent assujettis à la musique supradiégétique qui rythme l’ensemble (par exemple, les pneus commencent à crisser sur le premier temps de la mesure, tout comme le son de la voiture qui plonge dans l’eau). Cette dernière remarque au sujet de la musique nous amène à traiter de la performance vocale.
Performances vocales
L’une des caractéristiques de la chanson enregistrée qui la rapproche de pratiques comme le théâtre ou le cinéma, en même temps qu’elle l’éloigne de la littérature, concerne la présence de performances vocales, fixées et médiatisées par les techniques d’enregistrement sonore. Ainsi, « les particularités de l’élocution » (Genette, 1983 : 34), comme le timbre de la voix, les intonations, les accents, etc., deviennent partie intégrante de la chanson. Ce sont ces aspects paralinguistiques qui permettent à la fois d’identifier les personnages et de véhiculer leurs états émotifs (Poyatos, 1993). Or, comme on l’a vu, l’interaction entre les trois niveaux identitaires que sont la personne, la persona et le personnage ajoute à l’ensemble : ici, c’est évidemment Marshall Mathers qui incarne les personnages de Stan et d’Eminem dans notre chanson. Le mot « incarne » devient important, dans la mesure où c’est dans la voix enregistrée que subsistent les seules traces concrètes et physiques de la personne de Mathers, qui les contrôle de façon à jouer ces rôles. En même temps, la persona publique d’Eminem fait en sorte que c’est ce niveau d’identité qui, peut-être, domine tous les autres : lorsqu’on entend Stan, et bien que l’on comprenne qu’il s’agisse de Stan (le personnage), on entend néanmoins toujours Eminem (la persona), par l’entremise de Mathers (la personne). Voyons de plus près comment se manifestent ces différentes relations.
Mathers personnifie vocalement les personnages de Stan et d’Eminem en donnant à chacun un timbre relativement spécifique. La voix de Stan est ainsi plus aiguë et nasillarde que celle d’Eminem qui, dans le dernier couplet, présente plus de basses fréquences[35]. Par ailleurs, le ressentiment croissant de Stan est évidemment aussi reflété dans la performance vocale de Mathers. Ainsi, bien que l’on sente une pointe de déception dans le premier couplet, le deuxième couplet est généralement énoncé avec plus d’intensité, et certains mots plus particulièrement, comme « fucked up » (2:04-2:05) ou « pain » (2:51-2:52). Toutefois, c’est dans le troisième couplet que Stan éclate véritablement, alors qu’il s’enregistre sur son dictaphone. Déjà, la performance de Mathers dans les sections A et B du couplet 3 illustre l’état d’esprit du personnage, qui s’apprête à commettre son geste. Mais c’est au moment de passer à la section C que culmine l’action ; Stan crie alors à Shady, à qui il souhaite de faire des cauchemars à son sujet :
You ruined it now, I hope you can’t sleep and you dream about it
And when you dream I hope you can’t sleep and you SCREAM about it
I hope your CONscience EATS at you and you can’t BREATHE without me (4:21-4:31)
Dans cet extrait de dix secondes, l’accentuation (représentée par le souligné) joue un rôle central dans l’expression des sentiments exprimés par Stan. Non seulement fait-elle ressortir les mots importants, mais elle échange magistralement avec le rythme imposé par le cadre musical de la chanson, un trait d’ailleurs caractéristique du rap (Béthune, 2004 : 79-81). Quant aux majuscules, elles indiquent les syllabes qui sont prononcées avec une voix rauque, illustrant ainsi clairement la colère du personnage[36]. On le voit, l’élocution constitue un élément capital d’une chanson enregistrée. J’en conviens, « Stan » est avant tout rappée, et donc différente d’une chanson avec une mélodie chantée. Pourtant, une voix chantante intervient à chaque refrain : celle de Dido.
Dido : narratrice supradiégétique ?
Jusqu’à maintenant, nous n’avons abordé le refrain de la chanson, et donc l’extrait de « Thank You » de Dido, que selon une perspective formelle : l’extrait joue un rôle de transition spatiotemporel, nous permettant de sauter d’une séquence dramatique à une autre. Toutefois, la nature singulière de la chanson nous oblige à considérer les rapports que peut entretenir ce refrain avec notre récit. En d’autres termes : quelle serait la fonction de cet extrait, d’un point de vue narratologique[37] ? Dido pourrait être considérée comme une sorte de narratrice supradiégétique (donc présente à la fois dans l’espace intradiégétique et extradiégétique) commentant, d’une certaine façon, le récit. Pour nous permettre d’explorer cette avenue, je reproduis le texte de l’extrait en question :
My tea’s gone cold I’m wondering why
I got out of bed at all
The morning rain clouds up my window
and I can’t see at all
And even if I could it’d all be gray,
but your picture on my wall
It reminds me, that it’s not so bad,
it’s not so bad
Ce texte entretient des rapports évidents avec notre histoire. D’abord, la présence de la pluie et de l’ambiance « grise » correspond tout à fait à l’atmosphère sombre dépeinte dans « Stan ». Ensuite, la ligne « but your picture on my wall » renvoie à deux extraits tirés des lettres de Stan à Slim Shady. Dans le premier couplet, un Stan toujours admiratif écrit : « I got a room full of your posters and your pictures man », alors qu’une fois désillusionné et en colère (dans le troisième couplet), on l’entend vociférer : « I hope you know I ripped all of your pictures off the wall ». En plus de ces correspondances, le contenu musical de l’extrait (la mélodie et l’harmonie, entre autres) ajoute une touche presque sentimentale à l’ensemble.
Dans le contexte de l’attitude de Stan qui passe d’une admiration fanatique à une haine (auto)destructrice, le refrain ajoute au récit en éclairant l’action différemment à chacun de ses passages : au tout début, et comme on l’a vu, la manipulation « timbrale » de l’extrait et l’environnement sonore dans lequel il est plongé installent déjà l’auditeur dans une ambiance plutôt sombre :
Le premier élément accrocheur, cet index qui nous fait signe, est carrément génial. La voix de Dido est étouffée sous les sons de l’orage et une couche de bruits parasites électroniques (comme si sa voix venait du casque d’écoute d’un étranger assis tout près de nous). Obligé d’écouter, on est déjà attiré vers une nouvelle vie, vers le monde de quelqu’un d’autre; et pour ce seul instant, on s’expose, sans protection.
McKinney, 2005 : 315. nt[38]
Puis, dans le contexte des deux premiers couplets (avant l’accident), le refrain contribue à véhiculer une partie des sentiments ressentis par Stan qui oscillent entre une tristesse profonde et une sorte de répit que lui accorde sa « relation » avec son idole, Slim Shady. Après l’accident, l’extrait devient plutôt rétrospectivement nostalgique et se juxtapose, en quelque sorte, à notre propre consternation devant les événements racontés. Comme c’est le cas dans la plupart des chansons, la répétition structurelle du refrain ne coïncide donc pas avec un discours réitéré : à chaque passage, sa signification s’enrichit plutôt du contexte dans lequel il s’insère. De plus, dans le cas qui nous occupe, le fait que l’extrait provienne d’une autre chanson contribue à lui conférer ce statut potentiel de commentateur. Il s’agit d’un corps étranger qui, en s’intégrant à l’ensemble, n’en demeure pas moins toujours détaché. C’est là, je pense, l’un des atouts du statut supradiégétique, l’une des façons de rendre palpable ce jeu entre l’idéal et le réel dont parle Altman.
Conclusion
Dans son article à propos de « moments magiques » en musique populaire, Devin McKinney fait un parallèle entre « Stan » et d’autres chansons du même genre des années 1960. En particulier, il entend dans « Stan » une claire évocation des chansons réalisées par ce personnage mystérieux au nom emblématique, George « Shadow » Morton :
Eminem réactive un scénario des plus élémentaires, un scénario dans lequel la route n’est pas une métaphore existentielle, mais plutôt le théâtre de l’expression des émotions : un lieu où se jouent l’effroi, le désastre, l’autodestruction. Remontez cette route jusqu’à son point de départ, et qui trouvez-vous en train d’appeler Eminem à travers les décennies? Les Shangi-Las! On entend le début de « Remember (Walking in the Sand) ». On entend les orages, et des adolescents de la ville pleurant sur des autoroutes abandonnées. On perçoit l’impression cinématographique d’un espace enregistré, de même que des récits d’amours obsessifs, de séparations irréconciliables, de morts violentes (causées le plus souvent par des accidents de la route). […] « Stan » n’est plus ce récit ultraviolent que j’ai d’abord cru entendre, aussi incisif et vide d’émotion qu’un film de Tarantino ; plutôt, il s’agit d’un pur opéra-pop mélodramatique, mais plus riche et plus engagé.
McKinney, 2005 : 315-316. nt
Dans cet article, j’ai voulu montrer comment la chanson enregistrée, conçue comme une forme d’expression multimédiatique (proche du cinéma), permettait de structurer un récit à l’aide de paramètres autres que son seul texte. J’ai d’ailleurs volontairement écarté le plus possible l’analyse narratologique du texte de « Stan », de façon à me concentrer sur le rôle de la voix et de la technologie. Une analyse du texte dévoilerait une structure narrative riche et complexe, remplie de liens intertextuels et transfictionnels divers, mais en même temps fort différente de celle décrite dans cet article consacré au rôle de la voix et de la technologie. Je laisse donc le soin à d’autres de procéder à une telle analyse, de façon à montrer les rapports que cette structure entretient avec celle du récit phonographique. La chanson enregistrée, abordée comme objet multimédiatique, exige que l’on tienne compte du texte, bien sûr, mais pas au détriment des autres paramètres.
Comme je l’ai suggéré au début de cet article, je suis d’avis que le terme « musique » est fréquemment restreint à une certaine conception qui exclut, le plus souvent, le type de chanson dont il a été question ici. En fait, et comme je l’ai à plusieurs reprises signalé ailleurs, la musique populaire enregistrée consiste en une forme d’expression relativement éloignée de notre conception traditionnelle de la musique (au même titre que, par exemple, la musique électroacoustique). Il s’agit toutefois toujours d’un art de la « combinaison des sons », mais de sons concrets, audibles, matériels, charnels même. C’est dans cet agencement de lignes mélodiques, de rythmes et de sons physiques que se trouve la richesse d’une telle pratique.
Un tel plaidoyer ne vise toutefois pas à justifier la valeur ni l’ensemble de la production musicale populaire, ni du travail d’un artiste en particulier comme Eminem. J’ai choisi Eminem notamment à cause de sa très grande popularité ; j’ai également choisi de ne pas me prononcer sur la valeur (esthétique ou morale) de son travail[39]. Mon objectif était plutôt de suggérer quelques pistes qui pourraient aider à mieux comprendre le mécanisme au coeur de ce type d’objet ; à mieux comprendre comment une telle construction parvenait à véhiculer un ensemble de significations, lesquelles, une fois lancées, peuvent alors donner lieu à une série d’interprétations et de jugements. Il me semble toutefois clair que, du point de vue d’une construction destinée à raconter une histoire, la structure narrative de cette chanson, à l’instar d’innombrables autres, est particulièrement efficace.
Parties annexes
Note biographique
Serge Lacasse
Spécialiste de la musique populaire, Serge Lacasse est professeur agrégé à la Faculté de musique de l’Université Laval, où il enseigne l’analyse, l’histoire, l’écriture et la théorie de la musique populaire. En plus de ses fonctions de professeur, il est chercheur régulier au Centre de recherche interuniversitaire sur la littérature et la culture québécoises (CRILCQ), et chercheur associé à l’Observatoire international sur la création musicale (OICM). Il siège à l’exécutif de ces deux centres, de même qu’au comité de lecture des Cahiers de la Société québécoise de recherche en musique (depuis 2006) et au comité de parrainage de la revue française Copyright Volume ! : autour des musiques populaires (depuis 2005). Il termine présentement son mandat (2001-2006) de rédacteur en chef (section francophone) de la Revue de musique des universités canadiennes, et fait partie, depuis 2005, du comité scientifique de l’Observatoire musical français (Université de Paris-Sorbonne).
Notes
-
[1]
La recherche liée à la rédaction de cet article a bénéficié du soutien financier du Fonds québécois de la recherche sur la société et la culture (FQRSC).
-
[2]
De plus, le fait de fixer ces paramètres sur papier les stabilise, en quelque sorte, excluant ainsi les micro-variations (pourtant cruciales) qu’ils subissent lors de l’exécution.
-
[3]
Ailleurs, il explique : « Le discours musical s’inscrit dans le temps. Il est fait de répétitions, de rappels, de préparations, d’attentes, de résolutions, et, au niveau de la syntaxe mélodique, c’est sans doute Leonard Meyer qui est allé le plus loin dans l’inventaire de ce qu’on pourrait appeler les techniques de la continuité. On est tenté de parler de récit musical à cause de l’existence de cette dimension syntaxique et temporelle de la musique. […] Le contenu d’un récit, l’histoire qui est racontée, peut être “décollée” de son support linguistique pour être prise en charge par un autre médium, un autre type de discours, le film ou la bande dessinée. […] En musique, les connexions se situent au niveau du discours, pas au niveau de l’histoire » (1990 : 72-73).
-
[4]
Parmi les propositions que Nattiez passe ainsi en revue, mentionnons celles d’Abbate (1991), Cone (1974) et surtout Newcomb (1987).
-
[5]
En plus de l’entrée « Narratology, Narrativity » du Grove Music Online par F. E. Maus (2000), mentionnons le volume 12 (nos 1-2) de la revue Indiana Theory Review consacré à la narrativité musicale, dans lequel on retrouve un article du même Maus (1991), en plus de ceux d’autres musicologues de la même envergure, dont R. Hatten (1991), E. Tarasti (1991) et L. Kramer (1991). Ici encore, les résultats sont plutôt mitigés, comme le laisse entendre Kramer en conclusion de son article : « Tout chercheur voyant dans la narratologie un moyen d’éclairer la structure et l’unité de la musique serait mieux de chercher ailleurs » (1991 : 162. nt). Je renvoie également les lecteurs à des travaux plus récents, dont ceux par S. McClatchie (1997), J. K. Novak (1997), M. Grabócz (1998), V. Micznik (2001) ou E Tarasti (2004). Micznik fait le constat synthétique suivant : « Évidemment, la question n’est pas de déterminer si la musique en elle-même constitue un récit dans le sens littéraire du terme ; plutôt, par ses manifestations et son discours, elle peut sembler présenter des situations analogues à celles rencontrées dans des histoires. La musique est un média qui présente un potentiel narratif, tel que défini de façon très générale par Hayden White [1981 : 1] : elle peut traduire une certaine forme de connaissance en une certaine forme de récit. […] C’est pourquoi je n’essaie pas de déterminer si un texte musical peut être qualifié de narratif ou non de façon univoque ; nous sommes plutôt en présence d’un spectre de possibilités, permettant d’aborder la musique avec des degrés variables de narrativité » (Micznik, 2001 : 244-245. nt).
-
[6]
Quant aux deux autres catégories, elles comprennent l’influence de la musique sur les médias non musicaux, ou ce qu’il appelle la « musicalisation » : par exemple, un roman dont la structure aurait été inspirée par la forme « sonate » (à ce sujet, voir par ailleurs l’excellent ouvrage du même W. Wolf [1999], de même que celui de F. Escal [1990]), et, finalement, la narrativité musicale proprement dite.
-
[7]
La chanson n’est d’ailleurs mentionnée nulle part ailleurs dans cette encyclopédie (par ailleurs fort instructive), dont l’objectif est pourtant d’offrir un outil transdisciplinaire : « Cet ouvrage se veut un outil de référence universel, constituant ainsi une riche ressource pour les étudiants et les chercheurs de toutes les disciplines s’appuyant sur des concepts liés aux récits, ou utilisant des méthodes d’analyse narratologique. Par conséquent, et bien que couvrant un large éventail de modèles structuralistes et de cadres théoriques d’abord conçus pour étudier la narrativité littéraire, cette encyclopédie vise bien au-delà en voulant présenter un panorama des méthodes élaborées pour l’analyse narrative d’une grande variété de médias et de genres : tant le cinéma, la télévision, l’opéra ou les environnements numériques, que la rumeur, les sports télévisés, la bande dessinée et les avis de décès, pour n’en nommer que quelques-uns » (Herman, Jahn et Ryan, 2005 : x. nt). Il me semble révélateur que l’on décide d’inclure certaines pratiques (par exemple, les notices nécrologiques) tout en excluant la chanson, laquelle, pourtant, est à la fois l’une des formes d’expression les plus anciennes et les plus répandues dans le monde, et dont le potentiel narratif est non seulement évident, mais fortement exploité.
-
[8]
Une grande exception à cette tendance : le livre de G. Sibilla (2003), qui tente justement de proposer une narratologie de la chanson populaire. Toutefois, ce livre n’est disponible qu’en italien. Bien que quelques auteurs se soient également momentanément inspirés de la narratologie dans leurs analyses de chansons populaires, aucun, à ma connaissance, à part Sibilla, n’a cherché à élaborer un modèle narratologique de la chanson enregistrée.
-
[9]
Voir également Ryan, 2004.
-
[10]
Par exemple, dans « Confess » (1948), la voix de Patti Page est réenregistrée, de sorte que deux lignes vocales différentes se chevauchent et se répondent, bien qu’émises par la même chanteuse. De plus, l’une de ces lignes vocales baigne dans une réverbération abondante, donnant l’impression qu’elle résonne dans un environnement spatial différent de la première. En fait, tout se passe comme si la voix intérieure de la protagoniste (peut-être sa « conscience ») dialoguait avec sa voix « principale ». Pour plus de détails sur cet enregistrement historiquement important, voir Lacasse (2000 : 120-122).
-
[11]
Certains auteurs se sont déjà penchés sur « Stan » ; toutefois, leurs analyses, bien que généralement pertinentes, ne visent pas à dévoiler les mécanismes mis en oeuvre dans l’articulation du récit phonographique. Voir surtout le mémoire d’A. Woods (2004 : 44-63).
-
[12]
Par acousmatique, j’entends le fait que les sources sonores ne sont pas visibles pour l’auditeur.
-
[13]
Ici encore, il faudrait invoquer des degrés de narrativité.
-
[14]
Firth cite Russelson (1992-93 : 8-9).
-
[15]
Pour une application de la notion de mise en scène phonographique à l’analyse d’une chanson, voir Lacasse (2002).
-
[16]
Il écrit : « Les chanteurs populaires déploient à la fois leur personnalité de star (leur image) et la personnalité que le texte de la chanson exige. L’art de la vedette pop consiste alors à activer ces deux niveaux en même temps » (Frith, 1996 : 212. nt). Voir également Genette (2004 : 62-63).
-
[17]
À ce sujet, G. Lynch écrit : « Eminem décrit Slim Shady comme la partie « sombre, malfaisante et pathologiquement inventive » de lui-même. Mais contrairement à l’individu Marshall Mathers, rejeté et persécuté, ou à Eminem, qui essaie d’être le gentil garçon, Slim Shady a pour mission de détruire tous ceux qui lui ont fait du tort ou l’ont blessé, en plus de causer le chaos au gré de ses pulsions. En incarnant le personnage de Slim Shady, Marshall/Eminem peut alors exprimer les sentiments qu’il ressent envers l’univers qui l’entoure, de même que les choses qu’il aimerait faire subir aux gens qui lui ont causé du tort. C’est justement le recours à ce personnage qui permet d’aborder ces fantasmes comme le fruit d’un esprit dérangé, plutôt que comme des déclarations littérales de ce que souhaiterait Marshall/Eminem » (Lynch cite C. Weiner, 2001 : 10. nt).
-
[18]
« Kim » (2000) raconte le meurtre de la femme de Slim Shady (Kim), assassinée par Shady lui-même, alors que « 97’ Bonnie and Clyde » (1999) met en scène Slim Shady et sa petite fille d’environ deux ans lors du trajet en voiture pour aller jeter le corps de la mère/épouse dans un lac. Plusieurs auteurs se sont penchés sur ces chansons au sujet sordide (surtout « 97’ Bonnie and Clyde ») : voir, entre autres, Keathley (2002), Woods (2004 : 19-43), Burns et Woods (2004) et Lacasse et Mimnagh (2005).
-
[19]
Pour des raisons de droits d’auteur, le texte complet de la chanson ne peut être reproduit ici. Je renvoie donc les lecteurs au livret du CD (Eminem, 2000) ou encore à Internet, dans lequel on peut trouver de multiples sites avec les paroles de « Stan » (ex. : http://www.thelyricarchive.com/lyrics/stan.shtml (page consultée le 1er mai 2006).
-
[20]
Il est suggéré aux lecteurs de suivre l’analyse en ayant accès à l’enregistrement de la chanson. Les indications de minutage correspondent à celles apparaissant sur tout lecteur CD ou baladeur.
-
[21]
Sauf la toute première et la dernière : la première mesure, incomplète et très courte (moins d’une seconde), se réfère simplement au début du coup de tonnerre sur lequel s’ouvre la chanson (en langage musical, on pourrait parler d’une « anacrouse »), suivi de près par le début du « Sample », dont le commencement coïncide avec le début de la deuxième mesure (qui, en fait, constitue la première mesure complète). Quant à la dernière mesure, on n’y trouve plus de barres de mesure, indiquant ainsi que toute activité musicale rythmée est suspendue : seul persiste le son de l’orage qui s’évanouit en fondu au silence (6:37-6:44).
-
[22]
Paradoxalement, l’extrait en question constitue pourtant le premier couplet de la chanson-source, et non son refrain.
-
[23]
J’ai toutefois exclu de la grille un effet sonore pourtant crucial : le son de la pluie. Mais comme sa présence est constante, du début à la fin de la chanson, il m’a semblé qu’une représentation graphique était inutile. Autre élément absent de la grille : l’accompagnement musical. En effet, cette analyse ne prend en compte que de façon secondaire le matériau musical proprement dit, pour se concentrer, comme je l’ai déjà annoncé, presque exclusivement sur deux autres aspects : la performance vocale et le recours à la technologie (notamment, la présence d’effets sonores). Pour une analyse des paramètres musicaux dans « Stan », voir Woods (2004 : 52-55).
-
[24]
Notons la présence presque systématique d’un coup de tonnerre au moment de passer des couplets aux refrains (1:36 et 3:12), du pont au refrain (5:00), ou encore des refrains aux couplets (0:48 et 3:36). Une seule exception : le passage du refrain au couplet 2A (2:00).
-
[25]
Dans le schéma formel, ce coup de tonnerre est d’ailleurs indiqué par un « T » (en caractères gras).
-
[26]
D. McKinney interprète de façon élégante ce passage : « Un extrait de chanson qui flottait dans le monde à la dérive est soudainement usiné et astiqué dans un but précis : la boucle sonore tournant maintenant sans cesse dans la mémoire d’un désaxé, la voix de Dido semble moins vivante que lorsqu’elle était entendue sans artifice sous la statique et l’orage. L’effet produit ici est celui du sentiment de perte, de ruine qui semble s’installer de façon définitive dans le quotidien, du destin fermant toute issue vers la réalité ; et tout ce qui suit ne sert qu’à concrétiser et justifier toute la peur contenue dans ce seul moment » (2005 : 315. nt).
-
[27]
C’est entre autres ce que suggère le vidéoclip de la chanson qui commence par montrer une fenêtre de laquelle on se rapproche. À partir de 0:24, la caméra se trouve tout à coup dans la pièce où Stan s’apprête à rédiger sa première lettre. Pour une analyse du vidéoclip de « Stan », voir Woods (2004 : 56-60).
-
[28]
Je remercie C. Savoie pour cette observation.
-
[29]
Il faut savoir que c’est parce qu’il a entraîné sa petite fille de deux ans dans le meurtre de Kim que Shady, dans le refrain de « 97’ Bonnie and Clyde », compare le couple qu’il forme avec sa fille avec celui des criminels Bonnie Parker et Clyde Barrow, dont l’histoire (quelque peu romancée) est racontée dans le film Bonnie and Clyde, réalisé par A. Penn (1967) : autre lien intertextuel. Les controverses auxquelles ont donné lieu cette chanson et d’autres, comme « Kim », au moment de leur lancement ne concernaient pas tant leur contenu violent (présent dans un grand nombre de chansons, tous genres confondus), que le fait que les noms des personnages et leurs voix sont ceux des véritables membres de la famille de Marshall Mathers : sa fille Hailey, et son ex-femme Kimberley. Ici, plus qu’ailleurs, Eminem fait (dangereusement) se chevaucher les frontières entre ses personnages, sa persona et sa personne.
-
[30]
On note bien entendu des exceptions, ou des cas extrêmes : « Le concert le plus lent et le plus long du monde – il doit s’achever en 2639 – s’est enrichi hier d’un nouvel accord, qui doit être joué plusieurs mois sur l’orgue d’une église de Halberstadt. C’est dans cette église abandonnée que se tient depuis le 5 septembre 2001 le récital d’une oeuvre du compositeur expérimental américain John Cage (1912-1992), intitulée Organ2/ASLSP, abréviation de “ As SLow aS Possible ” » (Agence France Presse). Je remercie R. Saint-Gelais pour cette référence. Pour une analyse approfondie de la durée des oeuvres d’art, voir Genette (1994 : 72-74).
-
[31]
Dans son enregistrement (troisième couplet), Stan dit « It’s been six months and still no word » (3:42-3:43). Puis, dans le dernier couplet, on apprend que deux semaines se sont écoulées entre le moment de l’accident et celui où Eminem répond à Stan : « I seen this one shit on the news a couple weeks ago that made me sick / Some dude was drunk and drove his car over a bridge » (6:20-6:26). Il demeure pourtant un doute sur cette période de six mois, qui pourrait être plus longue. En effet, dans le premier couplet, Stan mentionne qu’il avait déjà écrit deux lettres avant celle qu’il est en train d’écrire : « Dear Slim, I wrote but you still ain’t callin’ / […] I sent two letters back in autumn, you must not-a got them » (0:48-0:57). Toutefois, dans la mesure où Stan présume que Shady n’a pas reçu ces deux lettres à cause de problèmes émanant du service postal ou d’une adresse trop imprécise, je prends pour acquis que la période de six mois à laquelle il se réfère ne prend pas en compte les moments où il a écrit ces deux lettres ; ce qui, de toute façon, ne changerait pas grand-chose à notre analyse : ce qu’il faut noter ici est l’écart important entre le temps du récit et celui de l’histoire.
-
[32]
On retrouve toutefois d’innombrables cas d’anachronies phonographiques de toutes sortes dans le répertoire de la chanson populaire enregistrée (en plus, bien entendu, de celles présentes dans les textes). Voir, par exemple, mon analyse de la chanson « Front Row » d’Alanis Morissette (Lacasse, 2002).
-
[33]
Pour cette section de l’analyse, je me suis en partie inspiré du modèle proposé par J. Châteauvert dans son livre sur la voix over au cinéma (1996). Châteauvert propose une catégorisation des configurations vocales organisée selon deux critères : la visibilité des sources vocales à l’écran (source visible versus source non visible), et l’accessibilité par les autres personnages de la diégèse à ces sources vocales (accessibilité diégétique versus accessibilité extradiégétique). Découlent du croisement de ces critères les quatre catégories de base suivantes : 1) la voix in, qui est intradiégétique et dont la source est visible, et qui rend compte de la vaste majorité des voix entendues au cinéma (personnages qui parlent ou qui pensent, et qui sont visibles à l’écran) ; 2) la voix off, qui est également intradiégétique, mais dont la source n’est pas visible (souvent momentanément) : par exemple, quelqu’un qui crie « laissez-moi entrer! » derrière une porte close ; 3) l’aparté, qui constitue un cas intéressant, puisque, bien que la source soit visible et occupe l’espace diégétique, son discours n’est pas accessible aux personnages partageant la diégèse ; 4) la voix over, laquelle est à la fois invisible et extradiégétique : il s’agit de la configuration classique du narrateur omniscient invisible dont la voix n’est pas accessible aux personnages peuplant la diégèse (1996 : 141-150).
-
[34]
Bien que l’expression soit d’Altman (1992b : 23-25), j’ai plutôt choisi de citer la définition proposée par A. Truppin : « On peut définir la signature spatiale comme l’empreinte auditive d’un son, laquelle ne peut jamais être absolue, plutôt sujette à la localisation de la source sonore dans un environnement physique donné. Les marqueurs responsables de cette signature sont le niveau de réverbération, le niveau sonore, le spectre des fréquences et le timbre, qui permettent aux auditeurs d’interpréter l’identité du son en termes de distance et du type de lieu dans lequel ce son semble avoir été produit ou perçu » (1992 : 241. nt).
-
[35]
Bien que je ne sois pas très familier avec les accents étatsuniens, il me semble également que chaque personnage parle avec un accent légèrement différent.
-
[36]
F. Poyatos nous dit ce qui suit au sujet de la voix rauque : « On peut l’utiliser pour ajouter au langage verbal [...] les connotations négatives associées à la colère, le ridicule, le dédain, le mépris, la cruauté, et autres émotions violentes » (1993 : 212. nt).
-
[37]
A. Woods s’est quant à elle intéressée aux diverses interprétations que pouvait susciter l’insertion de cet extrait dans « Stan » (2004 : 44-63). Elle résume ainsi : « Eminem s’approprie la musique de Dido, mais pour faire prendre conscience de l’importance trop grande qu’accorde la société aux médias, et du rôle qu’elle donne souvent au divertissement comme source de modèles comportementaux. La manière dérangeante de présenter ces éléments constitue une façon très efficace d’exprimer le message désiré » (ibid. : 63. nt).
-
[38]
Je suis donc ici en désaccord avec A. Woods, qui prétend plutôt ce qui suit : « “Stan” débute avec deux itérations du refrain. Puisque le refrain n’a pas encore été situé dans le contexte du récit de «Stan», l’auditeur est libre d’interpréter les paroles du refrain pour ce qu’elles sont. Ce n’est qu’après le passage du premier couplet que l’auditeur peut saisir le sens du refrain dans le contexte spécifique de la chanson » (2004 : 48-49. nt). Paradoxalement, alors que Woods souligne ailleurs l’importance des effets sonores dans la chanson (ibid. : 53), l’interprétation qu’elle suggère du premier refrain semble prendre en compte le seul texte.
-
[39]
D’autres analyses ont déjà abordées cette question. Voir, entre autres, les travaux récents d’E. G. Armstrong (2004), T. G. Shaffer (2004), L. R. Calhoun (2005), et V. Stephens (2005).
Références bibliographiques et audiovisuelles
- Abbate, C. [1991] : Unsung Voices : Opera and Musical Narrative in the Nineteenth Century, Princeton, Princeton University Press.
- Agence France Presse [2006] : « Le plus long concert du monde, joué en Allemagne, s’enrichit d’un accord », Le Devoir, 6 janvier, B4.
- Altman, R. [1992a] : La Comédie musicale hollywoodienne. Les problèmes de genre au cinéma, trad. par R. Altman et révisé par J. Lévy, Paris, Armand Colin ;
- ———— [1992b] : « The Material Heterogeneity of Recorded Sound », dans R. Altman (dir.), Sound Theory, Sound Practice, New York, Routledge, 15-31.
- Armstrong, E. G. [2004] : « Eminem’s Construction of Identity », Popular Music and Society, vol. XXVII, no 3, octobre, 335-355.
- Auslander, P. [2004] : « Performance Analysis and Popular Music : A Manifesto », Contemporary Theatre Review, vol. XIV, no 1, 1-13.
- Béthune, C. [2004] : Pour une esthétique du rap, Paris, Klincksieck.
- Burns, L. et A. Woods [2004] : « Authenticity, Appropriation, Signification : Tori Amos on Gender, Race, and Violence in Covers of Billie Holiday and Eminem », Music Theory Online, vol. X, no 2, juin. En ligne : http://mto.societymusictheory.org/issues/mto.04.10.2/ mto.04.10.2.burns_woods.html#FN16REF (page consultée le 20 avril 2006).
- Calhoun, L. R. [2005] : « “ Will the Real Slim Shady Please Stand Up ? ” : Masking Whiteness, Encoding Hegemonic Masculinity in Eminem’s Marshall Mathers LP », The Howard Journal of Communications, no 16, 267-294.
- Châteauvert, J. [1996] : Des mots à l’image : la voix over au cinéma, Québec, Nuit blanche éditeur.
- Cone, E. T. [1974] : The Composer’s Voice, Berkeley, University of California Press.
- Eminem [1999] : The Slim Shady LP, Interscope, 90287.
- ———— [2000] : The Marshall Mathers LP, Interscope, 490629.
- Escal, F. [1990] : Contrepoints : musique et littérature, Paris, Klincksieck.
- Frith, S. [1996] : Performing Rites : On the Value of Popular Music, Cambridge (Mass.), Harvard University Press.
- Genette, G. [1972] : « Discours du récit », dans Figures III, Paris, Seuil, 67-282 ;
- ———— [1983] : Nouveau Discours du récit, Paris, Seuil ;
- ———— [1994] : L’Oeuvre de l’art : immanence et transcendance, vol. 1, Paris, Seuil ;
- ———— [2004] : Métalepse, Paris, Seuil.
- Grabócz, M. [1998] : « Les théories du récit d’après Paul Ricoeur et leurs correspondances avec la narrativité musicale », dans C. Amey (dir.), Le Récit et les Arts, Paris, L’Harmattan, 75-98.
- Hatten, R. [1991] : « On Narrativity in Music : Expressive Genres and Levels of Discourse in Beethoven », Indiana Theory Review, vol. XII, nos 1-2, printemps/automne, 75-98.
- Herman, D., M. Jahn et M.-L. Ryan (dir.) [2005] : Routledge Encyclopedia of Narrative Theory, Londres, Routledge.
- Katz, M. [2004] : Capturing Sound : How Technology Has Changed Music, Berkeley, University of California Press.
- Keathley, E. L. [2002] : « A Context for Eminem’s “ Murder Ballads ” », Echo : A Music-Centered Journal, vol. IV, no 2, automne. En ligne : http://www.echo.ucla.edu/volume4-issue2/keathley/keathley_1.html (page consultée le 20 avril 2006).
- Kramer, L. [1991] : « Musical Narratology : A Theoretical Outline », Indiana Theory Review, vol. XII, nos 1-2, printemps/automne, 141-162.
- Lacasse, S. [2000] : “ Listen to My Voice ” : The Evocative Power of Vocal Staging in Rock Music and other Forms of Vocal Expression, thèse de doctorat, University of Liverpool. En ligne : http://www.mus.ulaval.ca/lacasse/texts/THESIS.pdf (page consultée le 20 avril 2006) ;
- ———— [2002] : « Vers une poétique de la phonographie : la fonction narrative de la mise en scène vocale dans “ Front Row ” (1998) d’Alanis Morissette », Musurgia : analyse et pratique musicales, vol. IX, no 2, automne, 23-41 ;
- ———— [2005a] : « Composition, performance, phonographie : un malentendu ontologique en analyse musicale ? », dans P. Roy et S. Lacasse (dir.), « Une étoile qui danse » : Mélanges à la mémoire de Roger Chamberland, Québec, Presses de l’Université Laval, 65-78 ;
- ———— [2005b] : « La musique populaire comme discours phonographique : fondements d’une approche analytique », Musicologies, no 2, printemps, 23-39.
- Lacasse, S. et T. Mimnagh [2005] : « Quand Amos se fait Eminem. Féminisation, intertextualité et mise en scène phonographique », dans C. Prévost-Thomas, H. Ravet et C. Rudent (dir.), Le Féminin, le masculin et la musique populaire aujourd’hui : Actes de la journée du 4 mars 2003, Paris, OMF, 109-117.
- Lynch, G. [2005] : Understanding Theology and Popular Culture, Malden (MA), Blackwell.
- Maus, F. E. [1991] : « Music As Narrative », Indiana Theory Review, vol. XII, nos 1-2, printemps/automne, 1-34 ;
- ———— [2000] : « Narratology, Narrativity », dans L. Macy (dir.), Grove Music Online. En ligne : http://www.grovemusic.com (page consultée le 16 avril 2006).
- McClatchie, S. [1997] : « Narrative Theory and Music ; or, the Tale of Kundry’s Tale », Revue de musique des universités canadiennes, vol. XVIII, no 1,
- 1-18.
- McKinney, D. [2005] : « Cruising a Road to Nowhere : Mechanics and Mysteries of the pop moment », Popular Music, vol. XXIV, no 3, 311-321.
- Meyer, L. [1956] : Emotion and Meaning in Music, Chicago, University of Chicago Press.
- Micznik, V. [2001] : « Music and Narrative Revisited : Degrees of Narrativity in Beethoven and Mahler », Journal of the Royal Musical Association, vol. CXXVI, no 2, 193-249. Nattiez, J.-J. [1990] : « Peut-on parler de narrativité en musique ? », Revue de musique des universités canadiennes, vol. X, no 2, 68-91.
- Newcomb, A. [1987] : « Schumann and Late Eighteenth-Century Narrative Strategies », 19th Century Music, vol. XI, no 2, automne, 164-174.
- Novak, J. K. [1997] : « Barthes’s Narrative Codes as a Technique for the Analysis of Programmatic Music : An Analysis of Janácek’s The Fiddler’s Child », Indiana Theory Review, vol. XVIII, no 1, printemps, 25-64.
- Poyatos, F. [1993] : Paralanguage : A Linguistic and Interdisciplinary Approach to Interactive Speech and Sound, Amsterdam, J. Benjamins.
- Russelson, L. [1992-93] : « More Than Meets the Ear », Poetry Review, vol. LXXXII, no 4.
- Ryan, M.-L. (dir.) [2004] : Narrative Across Media : The Languages of Storytelling, Lincoln, University of Nebraska Press ;
- ———— [2005] : « Media and Narrative », dans D. Herman, M. Jahn et
- M.-L. Ryan (dir.), 288-292.
- Shaffer, T. G. [2004] : The Shady Side of Hip Hop: A Jungian and Eriksonian Interpretation of Eminem’s “ Explicit Content ”, thèse de doctorat, Palo Alto (CA), Pacific School of Psychology.
- Sibilla, G. [2003] : I Linguaggi della musica pop, Milan, Strumenti Bompiani.
- Stephens, V. [2005] : « Pop Goes the Rapper : A Close Reading of Eminem’s Genderphobia », Popular Music, vol. XXIV, no 1, 21-36.
- Tarasti, E. [1991] : « Beethoven’s Waldstein and the Generative Course », Indiana Theory Review, vol. XII, nos 1-2, printemps/automne, 99-140 ;
- ———— [2004] : « Music As a Narrative Art », dans M.-L. Ryan (dir.), 283-304.
- Truppin, A. [1992] : « And Then There Was Sound : The Films of Andrei Tarkovsky », dans R. Altman (dir.), 235-248.
- Weiner, C. [2001] : Eminem : In His Own Words, Londres, Omnibus Press.
- White, H. [1981] : « The Value of Narrativity in the Representation of Reality », dans W.J.T. Mitchell (dir.), On Narrative, Chicago, Chicago University Press, 157-175.
- Wolf, W. [1999] : The Musicalization of Fiction : A Study in the Theory and History of Intermediality, Amsterdam, Rodopi ;
- ———— [2005] : « Music and Narrative », dans D. Herman, M. Jahn et
- M.-L. Ryan (dir.), 324-329.
- Woods, A. [2004] : Violence and the Negociation of Musical Meaning in Rock, Pop, and Rap Cover Songs, mémoire de maîtrise, Ottawa, Université d’Ottawa.
Liste des figures
Figure 1
Schéma formel de « Stan » (2000)
Figure 1 (suite)