
Résumés
Abstract
A multilingual comparable corpus is a corpus containing texts that are collected using the same sampling frame and similar balance and representativeness. According to McEnery and Xiao (2007: 20), presenting proportion, genre, domain, and time constitutes the main criteria when compiling a comparable corpus and these criteria must match in the different languages for the corpus to be considered comparable. The problem is that these criteria do not always guarantee that the different language subcorpora in a comparable corpus match. This study, which analyzes two comparable corpora compiled by the authors, shows that, even when the text selection criteria are refined, genre theory cannot always guarantee enough linguistic similarities between language for specific purposes (LSP) texts in different languages. Genre seems to suffice to establish a good comparable corpus for scientific abstracts. However, the comparable corpus of wine tasting notes is not truly comparable, since the English and Spanish texts differ in register.
Keywords:
- language for specific purposes,
- genre,
- comparable corpora,
- translation studies,
- pragmatics
Résumé
Un corpus comparable est un corpus multilingue qui contient des textes recueillis en utilisant les mêmes critères tout en reflétant un équilibre et une représentativité similaires. Selon McEnery and Xiao (2007 : 20), la proportion, le genre, le domaine et l’époque constituent les principaux critères de compilation d’un corpus comparable, et ces critères doivent correspondre dans les différentes langues pour que le corpus soit comparable. Malheureusement, ces critères n’assurent pas toujours le caractère comparable des corpus de langues différentes. Notre étude, qui analyse deux corpus comparables compilés par les auteurs, démontre que, même si on raffine les critères de sélection de textes, la théorie des genres ne garantit pas toujours assez de ressemblances linguistiques entre les textes de langues de spécialité dans les langues différentes. Le genre semble suffire pour établir un bon corpus comparable des résumés d’articles scientifiques. Cependant, le corpus comparable de fiches de dégustation de vin n’est pas vraiment comparable, surtout à cause des variations de registre.
Mots-clés :
- langues de spécialité,
- genre,
- corpus comparables,
- traduction,
- pragmatique
Resumen
Los corpus comparables son corpus multilingües que se construyen usando los mismos criterios de compilación y representatividad. Como afirman McEnery y Xiao (2007: 20), los criterios principales a la hora de compilar un corpus comparable, deben ser proporcionalidad, género, campo de especialidad y año de publicación de las muestras; además, estos autores destacan que se tienen que aplicar estos criterios en las diferentes lenguas o en los diferentes subcorpus que integran el corpus comparable. Sin embargo, el uso de estos criterios no garantiza que los subcorpus de diferentes lenguas sean parejos en términos de comparación. El presente estudio, que analiza dos corpus comparables de dos lenguajes de especialidad diferentes, la enología y la medicina y compilados ad hoc, demuestra que, incluso aunque se definan minuciosamente los criterios de compilación, el uso del mismo género no es un criterio de comparación suficientemente válido en diferentes lenguas. El análisis de nuestro corpus demuestra que el concepto de género parece ser válido para establecer una comparación en el caso de los abstracts científicos, pero no ocurre lo mismo en el caso de las fichas de cata ya que los textos incluyen registros diferentes en inglés y en español.
Palabras clave:
- lenguajes de especialdiad,
- género,
- corpus comparables,
- traducción,
- pragmatica
Corps de l’article
1. Introduction
Corpora are used in linguistics mainly for applied purposes since they are considered valuable resources that allow researchers to describe real utterances of a language in the context in which they are produced. As Aijmer and Altenberg (1996: 12) observe, corpus-based studies are often used for applied purposes such as lexicography, contrastive and translation studies, or language teaching, among others.
For cross-linguistic studies, the corpus has to be multilingual, but it can take the form of a parallel corpus or a comparable corpus. A parallel corpus is a translation corpus, consisting of source texts (ST) and their corresponding target texts (TT). A comparable corpus is a multilingual corpus containing texts in two or more languages that are collected using the same sampling frame and presenting similar balance and representativeness (McEnery 2003: 450). The focus of this paper is the comparable corpus, which is considered to be better suited for contrastive analysis and some translation-relevant research than a parallel corpus, since it presents texts originally written in the languages covered and thus allows researchers to obtain empirical findings that are not affected by the influence of the source language on the target texts.
For a comparable corpus to produce reliable results, it must contain texts in the two languages that are very similar on different levels. However, as the EAGLES group (Expert Advisory Group on Language Engineering Standards) stated in 1996, “There is as yet no agreement on the nature of the similarity,” (1996: 12), and this is still true to a large extent today.[1] The question being examined here is what precisely makes a corpus comparable and what can take away from comparability.
This question was addressed to some extent by McEnery and Xiao (2007: 20), who stated that comparable corpora are to include “the same proportions of the texts of the same genres in the same domains in a range of different languages in the same period.” In other words, according to these authors, proportion, genre, domain, and time constitute the main criteria when compiling a comparable corpus and must match in the different languages for the corpus to be considered comparable. The problem is that these external criteria do not always guarantee that the different language subcorpora in a comparable corpus match, because the same genre may be used to address a different audience or may show different features in its construction in different languages. In fact, the same genre, when compared interlinguistically, may show differences in content or in style, making it difficult to draw valid contrastive conclusions.
The present study aims to show that genre, one of the main criteria used to set up a comparable corpus, is not always enough to guarantee the required similarities between texts in certain specific domains, even when it is supplemented by other criteria. What seems to undermine the comparability of some comparable corpora seems to be register variation.
2. Theoretical Concepts
Given our hypothesis that genre is not enough to guarantee corpus comparability and that register variation is often responsible for a lack of comparability between corpora, this study is based not only on theoretical concepts from corpus linguistics, such as McEnery and Xiao’s design criteria presented above (2007), but also on concepts drawn from genre theory, register theory and discourse analysis.
In keeping with Swales, we see genre as a group of texts which share a set of communicative purposes and are recognized as having legitimacy within a discourse community (1990: 58). Lee (2001: 46) specifies that such a grouping of texts is culturally defined: genres are cultural constructs, socially constituted, functional categories of texts. Allen (1989) notes that
“for most of its 2,000 years, genre study has been primarily nominological and typological in function. That is to say, it has taken as its principal task the division of the world of literature into types and the naming of those types – much as the botanist divides the realm of flora into varieties of plants”
1989: 44
The classification and hierarchical taxonomy of genres is not a neutral and objective procedure. There are no undisputed ‘maps’ of the system of genres within any medium. Furthermore, there is often considerable theoretical disagreement about the definition of specific genres: “A genre is ultimately an abstract conception rather than something that exists empirically in the world” (Feuer 1992: 144).
One theorist’s genre may be another’s sub-genre or even super-genre. Defining genres may not initially seem particularly problematic but it is a theoretical minefield. Specific genres tend to be easy to recognize intuitively but difficult (if not impossible) to define. Particular features which are characteristic of a genre are not normally unique to it; it is their relative prominence, combination and functions which are distinctive (Neale 1980: 22-23). And there are differences within a genre. Neale declares that “genres are instances of repetition and difference” (1980: 48). The issue of difference also highlights the fact that some genres are “looser” – more open-ended in their conventions or more permeable in their boundaries – than others.
The connection between genre and register can clearly be seen in Kress’s definition of a genre as “a kind of text that derives its form from the structure of a (frequently repeated) social occasion, with its characteristic participants and their purposes” (Kress 1988: 183). Halliday, who introduced the concept of register into linguistic discourse, made a distinction between dialect and register, calling the former “a variety according to the user” and the latter “a variety according to the use” (Halliday 1978: 35).
Halliday also argues that a particular register is determined by three controlling variables: field, tenor and mode. Hence, register is a variety of language which is used in a particular communicative setting. It is “a conventional way of using language that is appropriate in a specific context, which may be identified as situational (as in church), occupational (as among lawyers) or topical (as talking about language)” (Yule 2007: 210-211).
A recent framework for register analysis has been proposed by Biber and Conrad (2009), central to which is the generally shared view that lexico-grammatical features of registers are situationally determined and functionally motivated. In other words, their approach foregrounds the impact of extralinguistic factors on language choices. Regarding the situational characteristics of registers, the two analysts draw on previous frameworks (Hymes 1974; Biber 1988), and propose the following set of seven variables determining language use: participants, relations among participants, channel, production circumstances, setting, communicative purposes, topic (Biber and Conrad 2009: 40-47). While Biber and Conrad make a distinction between register and style, diatypic variation as outlined above is generally termed register by Halliday (1978) and style by Crystal and Davy (1969). Like Halliday (1978) and Crystal and Davy (1969), we do not make a distinction between register and style. For us, register is the level and style of writing which is dictated by the situation one is in. Register covers the lexico-grammatical and discoursal-semantic patterns associated with situations (as linguistic patterns) (Lee 2001). Each genre may invoke more than one register.
Finally, the texts that comprise a genre need to be analyzed and Swales’ Move-Step model for research articles (1990) provides us with a framework for text analysis. Swales’ description of the constituent parts (moves and steps) of the research article is detailed and comprehensive. He modifies Hill, Soppelsa, and West’s diagram of the overall organization of the research paper, to which he refers as “the IMRD structure,”[2] and to underscore the additions he makes to the IMRD structure, he calls his model the “Create a Research Space (CARS) model” (1990: 140).
These concepts will underlie our study of corpus comparability.
3. Abstracts and Wine Tasting Notes as Metatexts of the Study
In the present paper we will analyze two different genres, produced in two different communicative situations but written by and addressed to the same type of interlocutors, at least in principle: experts. Experts constitute a discourse community, i.e., a group of users characterized by six defining features: (1) “an agreed set of common public goals,” (2) “mechanisms of intercommunication among its members,” (3) “mechanisms to provide information and feedback,” (4) “one or more genres in the communicative furtherance of its aims,” (5) “specific lexis,” and (6) a reasonable number of members with “a suitable degree of relevant content and discoursal expertise” (Swales 1990: 25-26). Experts in a specialized field are supposed to comply with all these conditions, and to be able to produce the specific genre(s) of their field as part of the discoursal expertise that can be expected from them.
The two genres which interest us in the present study are abstracts and wine tasting notes. They have been selected because they are both highly structured genres and are of limited scope, factors which allowed us to set up English and Spanish corpora of reasonable size and similar structure for each genre and then to analyze the level of comparability of the English/Spanish corpus for each genre.
While abstracts and wine tasting notes are two distinct genres despite some similarities, the analysis of comparable corpora of these two genres allows us to better determine what precisely makes a corpus comparable and what can take away from comparability. Moreover, since we believe that register variation may be responsible for differences between two apparently similar language corpora, we have heeded Biber and Conrad’s words cited below: “effective register analyses are always comparative. It is impossible to know what is distinctive about a particular register without comparing it to others” (2009: 36).
3.1. Abstracts
Abstracts constitute a secondary genre functioning as independent discourse as well as advance indicators of the content and structure of longer texts, the scientific Research Papers (RP) from which they derive. Nord (1997: 54) defines abstracts as a complementary or secondary genre based on primary texts, Research Papers (RP), which may have a metatextual function. On the other hand, an abstract is defined by ISO 214-1976 (E), as an “abbreviated, accurate representation of the contents of a document, without added interpretation or criticism and without distinction as to who wrote the abstract”; that is to say, according to this definition, an abstract is merely a shortened version of a fully elaborated text, derived from the latter by condensing its relevant information. This concept is supported by Sager et al. (1980: 318) who affirm that specialized language abstracts were developed for additional economy in order to select information or concentrate on limited groups or purposes, making the message more specific for a subgroup of readers of the whole text.
Abstracts are often classified on the basis of content, purpose and structure as well as authorship. Russell (1988: 4), among others, distinguishes two standard types of abstracts with two different functions: descriptive and informative abstracts. The former summarize the scope of the text, but do not contain extensive data and are not designed to replace the source text (ST), whereas the latter give more detailed information on the content of the article, replacing, in some cases, the ST. Since informative abstracts can replace the ST, they have to be divided into the same sections as RPs, following the IMRD pattern[3] referred to in section 2 above. In other words, informative abstracts contain information on purpose, scope, methods, results and conclusions or recommendations, just as RPs do.
Medical journal editorial committees typically direct contributors to write informative abstracts, in order to have a “report in miniature” (Jordan 1991: 507), that is to say, in order to have a condensed version of the content and structure of the primary text. As Ventola says (1994: 333), abstracts “have become a tool of mastering and managing the ever increasing information flow in the scientific community” since they direct medical readers to RPs of potential clinical research value and help journals to select contributions. In this sense, the writers of abstracts and the audience or readers they address share the same level of expertise in a particular field.
Sometimes, an informative abstract is the only piece of writing that is read by the target audience (Martyn and Slater 1964: 212). This is because there are now so many research journals that experts do not have time to read all the RPs they contain. Thus, these abstracts have become a key to the content of the whole text. The importance of abstracts is further heightened by the fact that several journals now only publish abstracts (and not full texts) (Martyn and Slater 1964: 212-235). In such cases, informative abstracts, the only pieces of published writing, serve to direct readers to articles of potential value.
There have been different studies analyzing the differences in the construction of abstracts in English and Spanish (Luzón Marco 2000; López Arroyo 2001, 2004; López Arroyo and Méndez Cendón 2005; Mendiluce Cabrera 2005; Vázquez y del Árbol 2006 among others), most of them focusing on the information distribution of abstracts in the two languages under study. However, the starting point for many of these works was Nwogu’s hallmark study (1997) which deals only with the rhetorical structure of abstracts in English.
3.2. Wine Tasting Notes
Wine tasting notes, a genre used in oenology, are standardized texts, used either during professional wine tasting or when new wines are released, to record the different organoleptic features or components of a wine. Silverstein defines them as the “verbal translation” of the “ritual” of wine tasting (2004: 640). While these notes are also written by so-called experts, there are in fact various kinds of wine experts. First there are those who are very experienced in tasting wines but do not necessarily have any experience in making wines or have not studied the chemistry of wine. Another group of experts would be wine scientists, the oenologists – those who are primarily interested in the science of winemaking. In between are individuals in the wine trade – shippers, sellers, sommeliers, wine writers. These differences in writers of wine tasting notes may explain why it is difficult to define and classify this discourse and why there is such a great variety in their writing.
Wine tasting notes can be considered as a subsidiary genre of Wine Tasting Technical Sheets since they often form part of the latter and have the same function, one that is relevant for the professional discourse community.
A wine tasting note can have an evaluative as well as a descriptive function, where the former is the basis for the latter (Lehrer 2009: 7). Descriptive wine tasting notes are used to describe, in the most objective way possible, the features of a wine, whereas evaluative wine tasting notes classify the features of a particular wine according to the wine tasting steps (what is known as nose, mouth and palate or aroma, taste and texture).
These texts, which vary in length between thirty and a hundred words,[4] include identifying and technical information. The identifying information commonly includes the name of the winery and of the wine, its denomination of origin (if any), the country of origin, type of grape and year of vintage. The technical information is often structured in sections presenting a description of the wine’s appearance (color, depth, hue, clarity, viscosity and effervescence), its aromas (fragrance, development and intensity), and its taste and texture (flavors, astringency, body, balance, mouthfeel and finish), and often concludes with general statements on its maturity, value or quality.
Although there are standardized wine tasting sheets, set up by the discourse community, that include all these aspects, the amount of information tasting notes cover may vary depending on the oenologist or sommelier who is tasting the wine and releasing the note, because the methods of tasting and recording tend to be tailored differently (Clarke and Bakker 2004: 200-201).
Tasting notes are found in a great variety of publications from wine journals, wine guides, bottle labels, to websites of wine producers; in short, as Wipf says “wherever wine is, there are tasting notes” (2010: 14).
While wine-tasting notes have attracted the attention of a number of linguists, research on the language of these notes has mainly concentrated on two aspects: the figurative nature of the language of wine, and the subjective/objective dichotomy characterizing this language. The heavy reliance on imagery has been studied extensively by Caballero and Suárez-Toste (2008, 2010), Suárez-Toste (2007), Negro (2012), and Paradis and Eeg-Olofsson (2013) and Rossi (2012). The need to reconcile the inherently subjective quality of wine tasting with the use of more objective descriptors that can be recognized by all members of the wine tasting community has also received considerable attention from researchers such as Lehrer (2009), Gawel (1997) and Lawless (1984). However, little attention has been paid to the register of wine tasting notes, especially from the point of view of two languages.
4. Corpus Compilation
Since our purpose was to examine whether the criterion of genre, supplemented by the criteria of proportion, domain, and time, is sufficient to build comparable corpora, as McEnery and Xiao (2007) have suggested, our next step was to compile the corpora, using these general criteria.
We built our two specific purpose comparable corpora using two genres (abstracts and wine tasting notes), and a similar number of texts in each language, with the texts focusing on the domains of medicine on the one hand and oenology on the other, and published between 2003 and 2012. In addition to these general criteria, we added the following more specific text selection criteria:
4.1. Abstracts Corpus
The following procedure was followed for the compilation of the abstracts corpus in the two languages under study (English and Spanish). We started our search on the Internet in broad scientific community databases. However, in a second stage, we restricted our search to medical abstracts[7] and consulted more focused search engines such as Medscape, which selects abstracts and research papers based on their scientific validity, importance, originality and contribution to the scientific community, i.e., to medicine. For our English subcorpus, each journal had to meet at least one of the following criteria, over and above the Medscape selection criteria:
Be highly ranked according to the expert opinion of pre-eminent clinicians and researchers.
Be one of the nine English-language international general medical journals whose full-time editors are members of the International Committee of Medical Journal Editors.
Be included in the 1994 internal JAMA (Journal of American Medical Association) journal list.
Have a journal impact factor greater than 2 as ranked by the Institute for Scientific Information’s Journal Citation Reports.
Boast high readership scores as determined by PERQ (Pharmaceutical and Health Care-related Promotion Research).
However, all these criteria could not be applied when compiling the Spanish subcorpus. For example, international impact could not be used as a criterion because ISI (Institute for Scientific Information) does not include any Spanish medical journals in its ranking. Nevertheless, Medscape covers two Spanish journals and so we took abstracts from those two journals: Revista Española de Cardiología, the official publication of the Sociedad Española de Cardiología, and Medicina Clínica, an Elsevier publication.
By following the compilation method outlined above, we ended up with a comparable corpus of 50 informative abstracts in each language (since these are the type of abstracts demanded by journals): 14,484 words in English and 15,113 words in Spanish.
4.2. Wine Tasting Notes Corpus
As in the case of abstracts, we started our search for wine tasting notes on the Internet in broad community databases. However, using the keywords wine tasting note and ficha de cata led to notes that were very varied in style and content, and often unlike the standardized tasting notes mentioned above. This made us realize that there were, in fact, several types of wine tasting notes (see the Analysis section below). So, in a second stage, we restricted our search to more focused websites such as the Denomination of origin websites in Spain that give access to texts written by winery oenologists and the VQA Ontario Appellations of Origin website that groups together all the different Denominations of origin and hence wineries in that Canadian province. As we stated before, although communication regarding the sensory description of wine frequently occurs between people with similar levels of expertise (Gawel 1997: 269), there are many types of writers who produce a great variety of tasting notes with different levels of accuracy and expertise. To avoid disparity in the texts selected for the corpus, we decided to use only those wine tasting notes included in wine tasting technical sheets released by wineries so as to ensure that the writer was an expert and that the audience being addressed also consisted of experts. This methodological adjustment also allowed for more parallelism between the English and Spanish texts and hence for more accurate interlingual comparison of the wine tasting notes.
The wine tasting notes corpus includes 750 wine tasting notes in Spanish and 716 wine tasting notes in English, which amounts to 54,545 and 55,339 words respectively.
4.3. Concluding Remarks on Corpus Compilation
Both the abstracts and the wine tasting notes corpora were considered comparable because the texts in the two languages belonged to the same genre (abstracts or wine tasting notes), the same fields (Bio science in the case of abstracts and Oenology in the case of wine tasting notes) and the same time period.
The corpora were compiled completely by computerized means, although the labeling and rhetorical tagging they went through at a second stage (see section 5 below) had to be coded manually (Flowerdew 2008: 15), since the computer obviously could not recognize the various moves and steps of the rhetorical structure. The need for manual annotation of the corpora explains why the corpora are not very large. However, both the number of texts and the word count exceed in both cases Biber’s (1993: 254) proposals of “at least twenty texts per register” and between 2,000 and 5,000 words, and meet Bowker and Pearson’s (2002: 48) more ambitious requirements of “anywhere from about ten thousand to several hundreds of thousands of words.”
5. Methodology
The starting point of our study was identification of the rhetorical structure for each of the genres in both English and Spanish. We began by identifying what Swales calls moves and steps: moves are semantic units based on the writer’s purpose (Swales 1990, 2004) and steps are subdivisions within moves. Once these semantic units were identified, all the samples were tagged in order to find the preferred rhetorical structure in the two languages under study. This qualitative analysis was completed by a quantitative one in order to assure reliability of the results (Upton 2002: 66).
Our purpose was to distinguish the most recurrent moves from the secondary ones by the frequency of occurrence of each rhetorical move in the abstracts and wine tasting notes. The most frequently recurrent moves, which range between 40 and 100 percent frequency, were considered ‘conventional’ (Biber et al. 2007: 24) or ‘compulsory’ (Suter 1993: 119). This category includes Suter’s compulsory high-priority and medium-priority moves and steps as listed below. The moves occurring least frequently (<40 percent) were deemed low priority and occasional and are called ‘optional.’ Overall, the moves comprise
Compulsory moves and steps (C): appearing in between 80 and 100 percent of their section or move.
High priority moves and steps (HP): appearing in between 60 and 80 percent of their section or move.
Medium priority moves and steps (MP): appearing in between 40 and 60 percent of their section or move.
Low priority moves and steps (LP): appearing in between 20 and 40 percent of their section or move.
Occasional moves and steps: appearing in less than 20 percent of their section or move.
The moves and steps with the highest occurrences, as C, HP and MP, were considered the most prototypical.
The analysis of moves and steps led to the identification of the rhetorical structure of abstracts and wine-tasting notes presented below.
5.1. The Rhetoric of Abstracts
Table 1
Rhetorical Structure of Abstracts
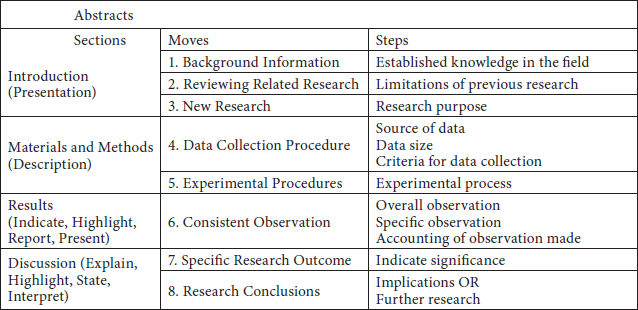
Table 2
Distribution of Moves and Steps in Abstracts
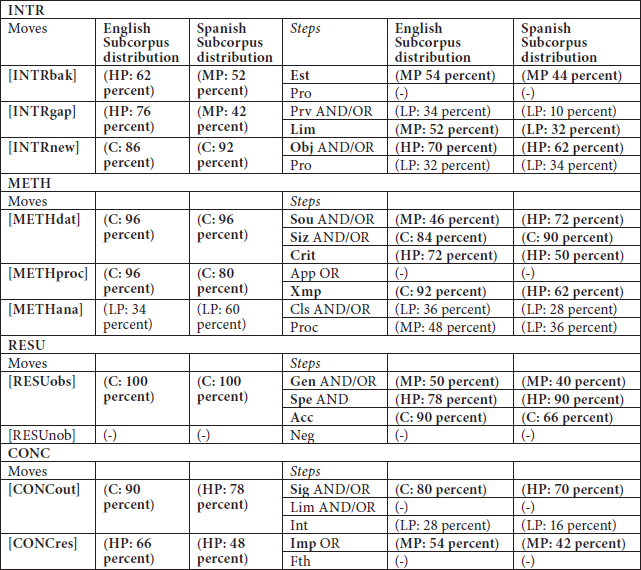
Table 2 shows the results of the qualitative and quantitative analysis (structure and distribution) of the abstracts in the two languages under study. The classification of moves and steps as high, medium or low priority has also been included, and the prototypical structure is shown in bold. (See Appendix 3 for a key to the abbreviations).
5.2. The Rhetoric of Wine Tasting Notes
Table 3
Rhetorical Structure of Wine Tasting Notes

Table 4 below shows the results of the quantitative and qualitative analysis of wine tasting notes in English and Spanish. The classification of moves and steps as high, medium or low priority has also been included, and the prototypical structure is shown in bold (See Appendix 3 for the abbreviations of moves and steps).
Table 4
Distribution of Moves and Steps in Wine Tasting Notes

As can be inferred from Table 4 above, our corpus shows that the central or prototypical structure corresponds to the different tasting phases; in other words, color, nose and palate are the compulsory moves for the construction of a wine tasting note in English and in Spanish. The main difference between the two languages is the frequency of occurrence of these moves and their steps; for instance, color occurs more frequently in Spanish than in English (40.66 percent in the English corpus and 71.03 percent in the Spanish corpus).
6. Analysis and Results
Once the rhetorical structure was identified for each of the genres in both English and Spanish and the corpus texts were tagged with rhetorical labels, we began our analysis of each comparable corpus to see just how similar the texts in English and Spanish were. The texts all belonged to the same genre, covered the same domain and the same time period, but did that mean that the corpora were fully comparable?
We focused our attention on the register of the texts included in the corpora, as, at first glance, there seemed to be a difference in the register of wine tasting notes in English and Spanish. Our analysis of register took into consideration text organization, vocabulary and structures. Highly organized texts, terms and complex vocabulary, as well as varied and complex structures were considered to be features of formal register, while less structured texts, use of more common words and of simple structures were considered to be characteristic of informal register.
Our detailed analysis is illustrated here by a very limited number of examples drawn from our corpus. They have been chosen for their typicality.
6.1. Analysis of Abstracts
The abstracts analyzed are found in Appendix 1. We have presented only one example per language here, as there is little variation in the abstracts of the corpus.
The first point that stands out is that all or at least most of the moves and steps identified as prototypical are found in most abstracts in both English and Spanish. A second aspect to be noted is that the moves and steps in both the English and Spanish abstracts follow the precise order indicated in the rhetorical structure above. These first two points pertain to text organization: they reveal a highly-organized text structure, which is typical of formal register.
Moving from the level of text down to that of vocabulary and structures, we found that the language used in the abstracts ranges from neutral to formal. Examples are the following:
The use of specialized terminology makes the language more formal. In addition to terms, Ex. 3 and Ex. 4 below include figures and percentages, which make the message more precise and consequently more formal:
The sentence structures are primarily compound, as Ex. 5 and Ex. 6 show, with an occasional simple or complex sentence intervening: we classify them as indicative of neutral register rather than of formal register.
Overall, the more neutral language is found in the first three moves (Background Information, Reviewing Related Research, and New Research) and the more formal language in the subsequent moves, which present more technical information.
It is clear from the above, that the English and the Spanish abstracts resemble each other not only in content but also in register.
6.2. Analysis of Wine Tasting Notes
The number of examples presented below to illustrate our analysis of wine tasting notes is far greater than the number for abstracts, because of the variety found in tasting notes in both languages, and especially in English. This variety exists despite our attempts to control the texts selected for the corpus by limiting ourselves to the tasting notes found in wine tasting technical sheets released by wineries.
Several points need to be made regarding text organization. The first observation is that not all five of the moves, and correspondingly not all of the steps associated with these moves, are found in all tasting notes. The moves that appear only occasionally are Introductory remarks, Appearance and Concluding remarks, whereas Aroma and Taste are found in most, if not all, tasting notes in both languages. Appearance appears more often in Spanish tasting notes (in 71.03 percent of texts) than in English tasting notes (in 40.66 percent of texts), while Concluding remarks appear more frequently in English (21.26 percent) than in Spanish (14.15 percent). This flexibility in the structure of the text reveals a certain level of informality in the register.
On the other hand, some of the tasting notes not only follow the rhetorical structure presented above (or at least some of the more important moves), but also indicate them explicitly using headings such as Color, Nose, Palate in English and Color, Nariz, Boca in Spanish, although the headings do vary to some extent. The use of these headings gives a more formal structure to the tasting note. It should be noted that a greater number of Spanish tasting notes use move headings than English notes, which could partially account for the overall impression that the English tasting notes are less formal than the Spanish ones.
Finally, tasting notes in English do not always follow the rhetorical structure in strict sequence. In a number of cases, there is a back and forth between Aroma and Taste, as illustrated in Ex. 7, which we have annotated in parentheses:
In addition, English tasting notes seem to focus more than the Spanish ones on aspects such as price or food pairing, which we have classified as Introductory remarks or Concluding remarks, depending on where they appear in the tasting note. Overall, English tasting notes appear less organized on the textual level than the Spanish ones, which adds to the impression that they are less formal.
As far as the language is concerned, the language used in Spanish tasting notes is generally neutral, as illustrated by Ex. 8a and 8b:
The language borders on formal when specialized terminology is used in the description of the wine, as in the following examples:
The tone remains objective in most of the Spanish tasting notes, although, occasionally, as in Spanish Ex. 3 in Appendix 2, a touch of subjectivity can be seen in the Introductory remarks and Concluding remarks. In the initial sentence of this example: Esta joyita procedente de la bodega Miguel Sánchez Ayala elaborada con uvas del Pago Balbaína presenta un bonito color oro Viejo (This small piece of jewllery from Miguel Sánchez Ayala’s winery made with grapes from Pago Balbaína, presents a nice old gold color. Our translation), the use of the word joyita introduces a subjective element, as do No se si era la botella and aunque claro in the closing sentence: No se si era la botella, pero lo vi algo cansado… aunque claro, siendo fruto de una saca de Enero 2009, ya han transcurrido más de 3 años… (I do not know whether it was the bottle or not, but I noticed the wine was a bit tired… although, of course, being made from fruits harvested in January 2009, it has been more than three years… Our translation)
But Spanish tasting notes rarely use language as informal or subjective as do English tasting notes. While many English tasting notes use neutral language, (see Appendix 2), and while parts of many English tasting notes do the same (e.g., English Ex. 1 of Appendix 2: A moderately aromatic wine with pure aromas of blackberry, raspberries, Dimetapp, dark chocolate, mineral notes, and herbs), they often contain language that is more informal or subjective. Let us use Ex. 10 below as an illustration and comment on specific elements of language therein:
The repetition of incredibly for emphasis is an informal device. The metaphor light on its feet applied to wine adds to the subjectivity of the description; and the use of the imperative, addressing the reader directly, adds to the informality of the note.
Our analysis clearly shows that, despite the similarity in genre, there is a difference in register between wine tasting notes in English and Spanish.
7. Conclusion
Despite our having followed the same or similar criteria in English and Spanish during the process of compiling our abstracts and wine tasting notes comparable corpora, it is clear that the results are not the same. In the case of abstracts, the Spanish and English texts resemble each other in more ways than not:
They closely follow the order of the rhetorical structure.
The rhetorical structure is marked by headings.
The language is neutral to formal and the tone is objective.
All things considered, one can claim that the genre of abstracts, which is similar in English and Spanish, shows little linguistic variation in the two language corpora, having similar register features.
In the case of wine tasting notes, however, the Spanish and English texts differ in several respects:
The Spanish texts follow the order of the rhetorical structure more closely than do the English texts.
The Spanish texts mark the rhetorical structure by headings more often than do the English texts.
The language used in Spanish texts is neutral to formal and the tone is generally objective, whereas the language used in English texts is often informal and the tone more subjective.
Overall, there is more variation in the English texts compared to the Spanish texts.
Given that both the Spanish and English tasting notes were taken from wine tasting technical sheets, the differences cannot be explained by the origins of the texts, nor by the writers of these texts, who are all oenologists hired by wineries. One explanation for the differences could be that, while Spanish wine tasting technical sheets, and correspondingly the wine tasting notes they contain, are addressed by experts to other experts, English wine tasting technical sheets, and correspondingly the wine tasting notes they contain, are addressed by experts to a broader audience, which includes the wine drinking public. That could explain why the way information is presented and distributed varies in Spanish and English. Another possible explanation could be that the register of wine tasting notes in English is more general than the register of such notes in Spanish. Biber and Conrad (2009: 32-33) point out that registers can be more or less specialized and that general registers will have more variability than more specific registers. Indeed, the English wine tasting notes seem to have subregisters, which are not as apparent in the Spanish wine tasting notes. For example, some of the English texts use informal language and a subjective tone, but not all of them. But the ultimate reason for the differences between the English and Spanish wine tasting corpora seems to be that wine is a cultural phenomenon, as Coutier (1994: 662) pointed out: “Since the fifties the great interest in wine, a beverage with highly symbolic implications, has become a cultural phenomenon which is part of current social and dietary behaviours.” The cultural dimension of wine shows in the different languages and reflects a given linguistic group’s attitude towards wine. One could argue that wine has a long history in countries such as Spain and France, where it is taken very seriously, in contrast to its relatively recent emergence as part of social and dietary behaviours in the English-speaking world. This could account for the differences in register in wine tasting notes in English and Spanish.
Our analysis of the abstracts and wine tasting notes corpora shows that the criteria for compilation of a comparable corpus proposed by McEnery and Xiao (genre, proportion, domain and time) work well for certain fields, but not all. Our attempt to attain greater comparability in the wine tasting notes corpus by the addition of specific text selection criteria did not fully resolve the differences between the English and Spanish texts, although they may have increased, to some extent at least, the degree of comparability. Given the cultural factor that seems to intervene in the field of wine, perfect comparability seems impossible, no matter the care taken in the compilation of the corpus.
The lack of full comparability in certain corpora has implications, in turn, for translation and translation studies. In order to understand these implications, it is first necessary to identify the role of comparable corpora in translation and translation studies. To begin with, comparable corpora allow the translator or terminologist to establish lexical equivalence for key concepts in a given field, to find equivalent collocations and fixed expressions in two languages, and to determine how each of the two languages structures a given idea. If the comparable corpus is not fully comparable, then the lexical equivalents it might suggest or the language structures it might present will not be completely reliable and will need to be confirmed by other sources. Comparable corpora are also used to examine how different languages are used in a specific field. In this case, the fact that the corpus is not perfectly comparable is not an obstacle, as a translation researcher analyzing a corpus such as our wine tasting notes corpus should be able to identify the differences between the English and Spanish texts, as we have done. Finally, identification of the differences in the use of language in such texts might pave the way for less source text based translation and more target text based translation. Thus, even a comparable corpus that does not seem fully comparable has its uses in translation.
Parties annexes
Appendices
APPENDIX 1. EXAMPLES OF ABSTRACTS IN ENGLISH AND SPANISH
English
Spanish
APPENDIX 2. EXAMPLES OF WINE TASTING NOTES IN ENGLISH AND SPANISH
English
Spanish
APPENDIX 3. KEY TO THE RHETORICAL STRUCTURE OF ABSTRACTS IN THE PRESENT STUDY
Introduction: [INTR]
-
i. BACKGROUND KNOWLEDGE [INTRbak]
ii. Established knowledge in the field [INTRbakEst]
iii. Main research problems [INTRbakPro])
-
iv. INDICATING A GAP [INTRgap]
v. Previous studies [INTRgapPrv]
vi. Limitation of previous research/studies [INTRgapLim]
-
vii. NEW RESEARCH [INTRnew]
viii. Research purpose [INTRnewObj]
ix. Main Research procedure [INTRnewPro]
Materials and methods: [METH]
DATA COLLECTION PROCEDURE [METHdat]
x. Source of data [METHdatSou])
xi. Data size [METHdatSiz]
xii. Criteria for collection [METHdatCrit]
-
EXPERIMENTAL PROCEDURE [METHproc]
Experimental process [METHprocXpm]
Research apparatus [METHprocApp]
-
DATA-ANALYSIS PROCEDURE [METHana]
Data classification [METHanaCls]
Instrument procedure [METHanaProc]
Results: [RESU]
-
– CONSISTENT OBSERVATION [RESUobs]
Overall observation [RESUobsGen]
Specific observation [RESUobsSpe]
Accounting of observation made [RESUobsAcc]
-
– NON-CONSISTENT OBSERVATION [RESUnobs]
Negative results [RESUnobsNeg]
Conclusion: [CONC]
-
4. SPECIFIC RESEARCH OUTCOME [CONcout]
1. Indicate significance [CONcoutSig]
2. Interpret research results [CONcoutInt]
3. Limitation of present research [CONCoutLim]
-
5. RESEARCH CONCLUSION [CONCres]
1. Implications [CONCresImp]
2. Further studies [CONCresFth]
APPENDIX 4. KEY TO THE RHETORICAL STRUCTURE OF WINE TASTING NOTES IN THE PRESENT STUDY

Acknowledgements
The authors belong to the ACTRES (Análisis Contrastivo y Traducción Especializada) research group. This paper has been written within the research projects Análisis Contrastivo y traducción inglés-español: aplicaciones III (FFI2013-42994-R), supported financially by Ministerio de Educación y Ciencia, Análisis contrastivo y traducción inglés-español (ACTRES): Aplicaciones lingüísticas para la internacionalización de la industria de transformación agroalimentaria (LE-227413), supported financially by Junta de Castilla y León and FFI2016-75672-R: “CLANES Producción textual bilingüe semiautomática inglés-español con lenguajes controlados: parametrización del conocimiento experto para su desarrollo en aplicaciones web 2.0 y 3.0..”
Notes
-
[1]
In Creating a Persian-English Comparable Corpus, Hashemi et al. claim: “In this study, we build a Persian-English comparable corpus from two independent news collections: BBC News in English and Hamshahri news in Persian. We use the similarity of the document topics and their publication dates to align the documents in these sets. We tried several alternatives for constructing the comparable corpora and assessed the quality of the corpora using different criteria” (2010: 27). In other words, researchers are still seeking criteria for establishing good comparable corpora.
-
[2]
IMRD stands for Introduction, Materials and Methods, Results and Discussion.
-
[3]
The IMRD pattern is the structure RPs and abstracts must adhere to, according to journal requirements. The most striking characteristic of this pattern is that each section contains a unique rhetorical structure, which differs from the others, and readers of RPs and abstracts expect writers to adopt this structure.
-
[4]
While thirty words can be considered very little for a text, it must be remembered that many advertisements presenting verbal language, which are texts, contain even fewer words. Chujo and Masao (2005: 5), in their attempt to understand the role of text size in determining text coverage, use texts that begin at ten words.
-
[5]
We tried to ensure that the selected texts were written originally in the language under study primarily on the basis of the author´s name. While we realize that this can sometimes be misleading, we were unable to find a better solution.
-
[6]
We aimed at obtaining texts representing the language of experts by going to specialized websites.
-
[7]
The domain of medicine was selected because we had ready access to doctors who could serve as consultants, if necessary.
Bibliography
- Aijmer, Karim and Altenberg, Bengt (1996): Introduction, papers from a symposium on text-based cross-linguistic studies. In: Karim Aijmer, Bengt Altenberg, and Mats Johansson, eds. Lund studies in English 88. Languages in Contrast. Lund: Lund University Press, 11-16.
- Allen, Robert (1989): Bursting bubbles: “Soap opera” audiences and the limits of genre. In: Ellen Seiter, Hans Borchers, Gabriele Kreutzner, and Eva-Maria Warth, eds. Remote Control: Television, Audiences and Cultural Power. London: Routledge, 44-55.
- Biber, Douglas (1988): Variation Across Speech and Writing. Cambridge: Cambridge University Press.
- Biber, Douglas (1993): Representativeness in corpus design. Literary and Linguistic Computing. 8(4):243-257.
- Biber Douglas, Connor, Ulla and Upton, Thomas M. (2007): Discourse on the Move. Using Corpus Analysis to Describe Discourse Structure. Antwerp: John Benjamins.
- Biber, Douglas and Conrad, Susan (2009): Register, Genre and Style. Cambridge: Cambridge University Press.
- Bowker Lynne, L and Pearson, Jennifer (2002): Working with Specialized Languages: A Practical Guide to Using Corpora. London: Routledge.
- Caballero, Rosario and Suárez-Toste, Ernesto (2008): Translating the senses: Teaching the metaphors in winespeak. In: Frank Boers and Seth Lindstromberg, eds. Cognitive Linguistic Approaches to Teaching Vocabulary and Phraseology. Berlin: Mouton de Gruyter, 241-259.
- Caballero, Rosario and Suárez-Toste, Ernesto (2010): A genre approach to imagery in winespeak: Issues and prospects. In: Graham Low, Zazie Todd, Alice Deignan, and Lynne Cameron, eds. Researching and Applying Metaphor in the Real World. Amsterdam/Philadephia: John Benjamins, 265-290.
- Chujo, Kiyomi and Utiyama, Masao (2005): Understanding the role of text length, sample size and vocabulary size in determining text coverage. Reading in a Foreign Language. 17(1):1-22.
- Clarke, Roland J. and Bakker, Jokkie (2004): Wine: Flavour Chemistry. Oxford: Blackwell.
- Coutier, Martine (1994). Tropes et termes: le vocabulaire de la dégustation du vin. Meta. 39(4):662-675.
- Crystal, David and Davy, Derek (1969): Investigating English Style. Bloomington: Indiana University Press.
- EAGLES (1996): Preliminary recommendations on corpus typology. http://www.ilc.cnr.it/EAGLES96/corpustyp/corpustyp.html. Last consulted 11 April 2014.
- Feuer, Jane (1992): Genre study and television. In: Robert C. Allen, ed. Channels of Discourse, Reassembled: Television and Contemporary Criticism. London: Routledge, 138-159.
- Flowerdew, Lynne (2008): Corpus-based analyses of the problem-solution pattern. Antwerp: John Benjamins.
- Gawel, Richard (1997): The use of language by trained and untrained experienced wine tasters. Journal of Sensory Studies. 12:267-284.
- Halliday, Michael Alexander Kirkwood (1978): Language as Social Semiotic: The Social Interpretation of Language and Meaning. London: Edward Arnold.
- Hashemi, Homa, Shakery, Azadeh, and Faili, Hesham (2010): Creating a Persian-English comparable corpus. Multilingual and Multimodal Information Access Evaluation. 6360:27-39.
- Hymes, Dell (1974): Foundations in Sociolinguistics: An Ethnographic Approach. Philadelphia: University of Pennsylvania Press.
- ISO 214:1976. International Organization for Standardization. 1976. http://www.iso.org/iso/home.html. Last accessed 12 August 2013.
- Jordan, Michael P (1991): The linguistic genre of abstracts. In: Angela Della Volpe, ed. The Seventeenth LACUS Forum 1990. Lake Bluff: LACUS, 507-527.
- Kress, Gunther (1988): Communication and Culture: An Introduction. Kensington: New South Wales University Press.
- Lawless, Harry (1984): Flavour description of white wine by expert and non-expert wine consumers. Journal of Food Science. 49:120-123.
- Lee, David (2001): Genres, registers, text types, domains and styles: clarifying the concepts and navigating a path through the BNC jungle. Language Learning and Technology. 5:37-72.
- Lehrer, Adrienne (2009): Wine and Conversation. New York: Oxford University Press.
- López Arroyo, Belén (2001): Estudio descriptivo comparado inglés-español de la representación del conocimiento en los abstracts de las ciencias de la salud. Valladolid: Universidad de Valladolid.
- López Arroyo, Belén (2004): English and Spanish medical research papers and abstracts: How differently are they structured? In: José M. Bravo Gozalo, ed. A New Spectrum of Translation Studies. Valladolid: Universidad de Valladolid, 175-193.
- López Arroyo Belén and Méndez Cendón, Beatriz (2005): Describing phraseological devices in medical abstracts: An English/Spanish contrastive analysis. Meta. 52(3):506-516.
- Luzón Marco, M. José (2000): Collocational frameworks in medical research papers: A genre based study. English for Specific Purposes. 19:63-86.
- Martyn, John and Slater, Margaret (1964): Tests on abstracts journals. Journal of Documentation. 20(4):212-235.
- McEnery, Tony (2003): Corpus linguistics. In: Ruslan Mitkov, ed. Oxford Handbook of Computational Linguistics. Oxford: Oxford University Press, 448-463.
- McEnery, Tony, and Xiao Richard (2007): Parallel and comparable corpora: What are they up to? In: Gunilla Anderman and Margaret Rogers, eds. Incorporating Corpora: Translation and the Linguist. Clevedon: Multilingual Matters, 8-31.
- Mendiluce Cabrera, Gustavo (2005): Estudio comparado ingles/español del discurso biomédico escrito: la secuenciación informativa, la matización asertiva y la conexión argumentativa en la Introducción y la Discusión de artículos biomédicos escritos por autores nativos y no nativos. Unpublished PhD Thesis. Valladolid: Universidad de Valladolid.
- Neale, Stephen (1980): Genre. London: British Film Institute.
- Negro, Isabel (2012): Wine discourse in the French language. Rael: Revista Electronica de Linguistica Aplicada. 11:1-12.
- Nord, Christiane (1997): Translating as a Purposeful Activity. Manchester: St. Jerome.
- Nwogu, Kimny (1997): The medical research paper: Structure and functions. English for Specific Purposes. 16(2):119-138.
- Paradis, Carita and Eeg-Olofsson Mats (2013): Describing sensory experience. The genre of wine reviews. Metaphor and Symbol. 28(1):22-40.
- Rossi, Micaela (2012): Pour une description du processus de création des métaphores dans le langage du vin – étude comparative français-italien. In: Laurent Gautier and Eva Lavric. eds. Unité et diversité dans le discours sur le vin en Europe. Insbruck: Insbruck University Press, 23-40.
- Russell, Pamela (1988): How to Write a Précis. Ottawa: University of Ottawa Press.
- Sager, Juan C., Dungworth, David, and Mcdonald, Peter (1980): English Special Languages: Principles and Practice in Science and Technology. Wiesbaden: Brandsletter.
- Silverstein, Michael (2004): ‘Cultural’ concepts and the language-culture nexus. Current Anthropology. 45(5):621-652.
- Suárez Toste, Ernesto (2007): Metaphor inside the wine cellar: On the ubiquity of personification schemas in winespeak. Metaphorik.de. 12:53-63.
- Suter, Hans J (1993): The Wedding Report. A Prototypical Approach to the Study of Traditional Text Types. Antwerp: John Benjamins.
- Swales, John (1990): Genre Analysis: English in Academic and Research Settings. Cambridge: Cambridge University Press.
- Swales, John (2004): Research Genres. Cambridge: Cambridge University Press.
- The Jama network (2013): The Journal of the American Medical Association. http://jama.jamanetwork.com/journal.aspx. Last Accessed 11 April 2014.
- Upton, Thomas (2002): Understanding direct mail letters as a genre.’ International Journal of Corpus Linguistics. 7(1):65-85.
- Vázquez Y Del Árbol, Esther (2006): La redacción y traducción biomédica ingles-español. Granada: Universidad de Granada.
- Ventola, Eija (1994): From syntax to text: Problems in producing scientific abstracts in L2. In: Svĕtla Čmejrková and František Štícha, eds. The Syntax of Sentence and Text. Amsterdam: John Benjamins, 283-303.
- Yule, George (2007): The Study of Language. Cambridge: Cambridge University Press.
- Wipf, Betina (2010): Wine writing meets MIPVU: Linguistic metaphor identification of tasting notes. Master’s Thesis. Unpublished. Antwerp: VU University.
 10.7202/002423ar
10.7202/002423arListe des tableaux
Table 1
Rhetorical Structure of Abstracts
Table 2
Distribution of Moves and Steps in Abstracts
Table 3
Rhetorical Structure of Wine Tasting Notes
Table 4
Distribution of Moves and Steps in Wine Tasting Notes