
Résumés
Abstract
Little research has been conducted so far into the translation-specific features that are dependent on both the source and the target language. This study aims at examining whether Modern Greek translated popular science articles differ from non-translated ones by being closer to the source language, which is English, in terms of the frequency and the word order of the passive voice constructions. This is one of the few Modern Greek studies that use a comparable corpus in order to better understand the nature of the translation practice. The corpus analysed consists of Modern Greek popular science articles and is divided into two subcorpora: the translated language corpus and the non-translated language corpus. The study indicates that there is substantial evidence that Modern Greek articles employ some translation-specific features which are dependent on the source language, at least in terms of some passive voice features. More importantly, it suggests that the non-translated texts tend to be similar to the translated ones, which are in turn closer to the English source texts. Even though it is early to conclude that translation encourages the different usage of particular linguistic features in non-translated texts, the data provide indirect evidence that translation is a potential field of language contact with important consequences.
Keywords:
- corpus-based translation studies,
- passive voice,
- Modern Greek,
- popular science articles,
- comparable corpus
Résumé
Peu de recherches ont été menées jusqu’à présent sur les caractéristiques spécifiques de la traduction qui dépendent à la fois de la langue source et la langue cible. La présente étude vise à déterminer si les articles de vulgarisation scientifique traduits en grec moderne diffèrent de ceux qui sont rédigés originalement dans cette langue, de par une plus grande proximité avec la langue source, l’anglais, en ce qui a trait à la fréquence de la voix passive et à l’ordre des mots dans les constructions passives. Il s’agit de l’une des rares études portant sur le grec moderne qui utilise un corpus comparable afin de mieux comprendre la nature de la pratique de la traduction. Le corpus analysé est constitué d’articles de vulgarisation scientifique en grec moderne et est divisé en deux sous-corpus : le corpus traduit et le corpus non traduit. L’étude indique qu’il y a des preuves substantielles que les articles en grec moderne non traduits emploient certaines caractéristiques de traduction qui dépendent de la langue source, du moins en termes de certaines fonctionnalités de la voix passive. Plus important encore, l’étude suggère que les textes non traduits sont généralement semblables à ceux qui sont traduits, qui, à leur tour, sont plus proches des textes sources anglais. Même s’il est trop tôt pour conclure que la traduction encourage l’usage différent des particularités linguistiques des textes non traduits, les données fournissent des preuves indirectes que la traduction est un champ potentiel de contact de langues avec des conséquences importantes.
Mots-clés :
- études fondées sur l’analyse de corpus,
- voix passive,
- grec moderne,
- articles de vulgarisation scientifique,
- corpus comparable
Corps de l’article
1. Introduction
In the modern world, most scientific research is written in English (Sharkas 2009: 42). Although the reasons for this are numerous and involve historical, socio-cultural and political circumstances, what has heavily contributed to the preference of English among other languages is its status as a lingua franca. The era of the information society has increased the demand for “communicating scientific knowledge to the public” (Sharkas 2009: 42), and this resulted in an increase in the number of translations of popular science texts mainly from English and, eventually, in the creation of the genre of popular science in numerous countries of the world. Given the amount of popular science articles (both translated and non-translated) in Modern Greek at the beginning of the 21st century, it is interesting to explore whether translated articles employ passive voice features that differ from those of non-translated texts and are closer to the English patterns. Studying the implications of this phenomenon will reveal translation as a language contact phenomenon with important implications.
It has been argued that the nature and process of translation must leave their trace on the language of translation (Baker 1998: 481). When talking about the language of translation, it is common to refer to the linguistic features that characterize it and are independent of the source and the target language. A number of studies have focused on the nature of the language of translation and the linguistic features that are typically employed in it (Olohan and Baker 2000; Mutesayire 2005; Laviosa 2000). However, little is known about the way in which the language of translation is influenced by the two languages that come into contact during the process of translation. Although most studies employing comparable corpora try to investigate translation-specific features that are independent of the source and target language, this study is particularly interested in the language-dependent features of translated texts. By taking into consideration the linguistic systems that are involved in the translation process, we can better understand not only the language of translation, but also the specific linguistic and cultural pressures and constraints that influence translators and affect the translation product (Baker 1998: 484). Such constraints are not only the linguistic differences between the two languages, but also their respective statuses. In cases where English is involved, its status as a modern lingua franca cannot be ignored.
This corpus-based study aims to investigate the translation-specific features of Modern Greek translated popular science articles and is part of a larger project that investigates translation as a language contact phenomenon. In particular, it aims to examine whether and how features of the passive voice of Modern Greek translated popular science articles, namely the frequency and the word order of the passive constructions, are affected by both English and Modern Greek. A comparable corpus of Modern Greek translated and non-translated popular science articles was created, involving 20,000 words and consisting of two subcorpora, namely the Translated Language Corpus (TLC) and the Non-Translated Language Corpus (NTLC), in order to assist in the identification of linguistic features that may result from the complex nature of the translation process. So far, very few references have been made to the features of the passive voice in translated and non-translated texts (Amouzadeh and House 2010) and no detailed and comprehensive analysis of the language of translated texts has been carried out in the Modern Greek context. This is one of the few Modern Greek studies that employ a comparable corpus in order to investigate the language of translation, stimulate reflections on the use of comparable corpora in translation studies, and increases our awareness of their importance in the systematization of translation-specific features.
2. The language of translation
The idea of a translation-specific language is not new in translation studies and is related to both issues of foreignization and negative evaluation (Øverås 1998: 559). Thus, there are two perspectives to the analysis of the language of translation. The first one refers to a particular variety of language that is found in translated texts, which is the inescapable consequence of the contact between two linguistic systems. This is best known as the third code, a term introduced by Frawley (1984) to refer to a distinct linguistic code that is used in translated texts. The second way of viewing the language of translation is a pejorative one, which considers the deviations from the target linguistic norms as a result of the translator’s linguistic incompetence or inexperience. The latter case is widely known as translationese. The main difference between these two approaches is that the third code implies that the deviations from the target linguistic norms are not only expected and normal, but also worthy of systematic investigation. The aim of this study is not to evaluate the quality of the language of Modern Greek translated popular science articles, but rather to understand the way in which translated texts differ from non-translated ones. For that reason, the idea of the third code is more relevant.
The language of translation is often closely related to the results of literal translation. Every process of more or less literal translation can create a translation language (Rabin 1958). By providing an equivalent for every semantic or morphosyntactic feature of the source text, the target text is likely to employ linguistic features and structures that are unknown to the target language or linguistic means that the target language would not normally employ. However, it is possible that some linguistic features of the translated text seem to belong to the target language, but are under the obvious influence of the source language. Since translation always involves two languages, the language of translation is a hybrid linguistic code somewhere in-between the source and the target language and it can either be a moderate innovation or a radical one regarding the codes that created it (Frawley 1984). In the first case, the code is closely linked to either the source or the target language, generating instances of what is widely known as foreignization and domestication, respectively. In the latter case, the linguistic code employed in the translated text is different from both the source and the target language. Thus, a new code in its own right is created with its own standards and rules of usage, which are however derived from both the source and the target language (Frawley 1984). The unique character of this new code, which is the inevitable result of the process of translation, is what makes it worthy of scholarly investigation. This phenomenon is considered to be so natural that almost all translations employ a unique linguistic code and its linguistic features allow the native speakers of a language to distinguish translated from non-translated texts (Toury 1979).
Although empirical studies into the intricacies of the language of translated texts are limited, theoretical models, and especially descriptive translation studies, seem to have been greatly influenced by the idea of the language of translation. Toury (1995) views the idea of the translation-specific language as a translation law, namely, the law of interference. According to it, the target text tends to take over the linguistic phenomena that belong to the source text (Toury 1995: 275). Such transfer is conditioned on the translator’s professional experience and on the socio-cultural environment surrounding the translation. The more experienced the translator, the less he or she will be affected by the make-up of the source text. Additionally, interference tends to increase when the translation is conducted from a widely spoken into a less widely spoken language (Toury 1995: 278). This last condition is particularly interesting as far as Modern Greek popular science articles are concerned. It is possible that Modern Greek, being a less widely spoken language in terms of production of popular science texts, is less resistant to the influence of English, which on the opposite is prestigious when it comes to scientific production and is also a lingua franca. Thus, Modern Greek translators are more prone to create a text “not by retrieving the target language via their own linguistic knowledge, but directly from the source utterance itself” (Laviosa-Braithwaite 1998: 291).
It has also been argued that the more texts are translated from a particular source language, the less translation-specific features are used (Rabin 1958). However, there are instances where texts have been translated for decades from a particular source language and translation-specific features can still be found in the target texts. A possible explanation for this is that the texts translated at the early stages of translation were so widely circulating and respected, or the volume of translated texts was so vast, that the audience has grown used to the foreign or unfamiliar style and tends to believe that this is the only possible style for the particular genre (Rabin 1958). This is often the case in cultures where particular genres were introduced through translation. Thus, it is most probable that the large number of translations of well-known English magazines at the beginning of the 21th century, e.g. Scientific American and New Scientist in Greece, has considerably influenced the language employed in the Modern Greek translations of such texts. It is possible that those early translations established a language of their own that is still employed today. This is one of the reasons why we can hypothesize that Modern Greek translated popular science articles employ translation-specific features, some of which are likely to be the different frequency at which the passive voice is being employed and the preference for syntactically less flexible passive voice constructions.
3. The passive voice
Bennett argues that the Scientific Revolution, which took place during the 16th and 17th century, brought on “a positivist philosophy, which would gradually replace the old anthropocentric theory of knowledge,” and that the passive voice was a powerful tool for establishing this new status quo (Bennett 2007: 160). However, the turn towards new ideas in sciences did not occur homogeneously around the world, and Bennett notes that in Portuguese the passive voice is less frequent than it is in English due to Portugal’s profound Catholic identity that favours a more anthropocentric world view (Bennett 2011). It is possible that the well-known historical circumstances that tantalized Greece during that period, i.e. the Turkish Occupation (1453-1821), did not allow the language to fully develop an impersonal discourse in which the passive voice would play a central role. This provides a rather plausible explanation of why the frequency of the passive voice is likely to be different in English than in Modern Greek. Numerous studies have shown that the Modern Greek passive voice differs from the English one and that it is used more frequently in the former than in the latter (Warburton 1975). Indeed, a study conducted by Marmaridou (1987) indicated that the passive voice is used more frequently in the English announcements of Olympic Airlines than in the Modern Greek ones. In terms of popular science texts, no study has ever been conducted on the frequency of the passive voice in Modern Greek texts.
3.1. The Modern Greek passive voice
Passive voice in Modern Greek is a complicated field of study, that being mainly due to the fact that purely morphological criteria cannot be employed for the description of this phenomenon. Numerous studies have tried to take into consideration the rather unique voice morphology of Modern Greek (Theophanopoulou-Kontou 2000; Tsimpli 1989; 2005; 2006) and there is a very heated debate around the issue of what passive voice is and how it differs from middle voice. Middle voice stands between the active and the passive and is used when the subject has elements of both agent and patient in order to describe events that have characteristics of reflexivity or reciprocity. Since Modern Greek is an inflectional language, all verb forms are marked for voice, which is indicated in “a portmanteau realisation which also encodes tense, aspect and modality” (Manney 2000: 38). What is problematic is that, although Modern Greek verb forms are inflected for active and passive voice, they cannot be inflected for middle voice; “[t]he same passive form […] is also used with reflexive meaning” (Warburton 1970: 77). For example, the sentence Τα παιδιά χτενίστηκαν γρήγορα [The children were combed quickly] has two meanings: either that the children combed themselves quickly, in which case the children are both the agents and the patients of the action, or that someone else combed them quickly, i.e. a hairdresser or their mother, in which case the children are the patients. However, for the purposes of this study and in order to avoid any confusion, Mackridge’s description of the passive will be used. According to him,
[a] verb in the morphological passive […] may be used with one or more of the following meanings: (a) truly passive (i.e. the grammatical subject is the object or patient of the action and the sentence may be replaced by an active one without change of meaning), (b) reflexive; or (c) reciprocal
Mackridge 1985: 86
Thus, morphological criteria are used rather than semantic or other criteria, and all instances referred to as passive in this study imply morphologically passive verb forms.
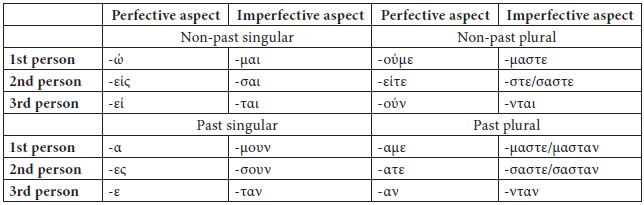
In terms of inflections, the passive voice uses the suffixes shown in Table 1 (Smirniotopoulos 1992: 29-32). The past in the perfective aspect also makes use of the element -ηκ- before the suffixes.
Table 1
Modern Greek passive voice inflections
As far as the frequency of the passive voice is concerned, Lascaratou argues that the active voice is more common than the passive one in Modern Greek, and that, in fact, the active voice will be used even in cases when the agent is irrelevant or not known (1984: 53). However, she does not provide any detailed frequency counts of the passive voice. Further, Warburton explicitly states that the “[p]assive voice is not very widely used in Modern Greek” (1970: 82). The reason she provides for this is that the logical subject of the construction seems to impose certain restrictions, that is, “a passive construction is more freely generated in cases where we can omit (delete) the agent” (Warburton 1970: 82). Although no particular reference is made about specific genres, it can be argued with some caution that popular scientific texts are likely to follow at least to some extent the passive voice frequential patterns identified by Warburton. More recently, a corpus-based study conducted by Fotiadou (2010) indicated that the active voice is used more frequently in Modern Greek, with a rate of approximately 68%. Although none of these claims have been made with relation to popular science articles, the corpus analysed by Fotiadou (2010) consisted of both formal and informal texts, indicating that popular scientific texts are not likely to be an exception.
Finally, in terms of word order, no explicit reference is made to a particular passive word order in Modern Greek, although most examples provided in grammars (Tzartzanos 1946; Kleris and Babiniotis 2005) imply that passive sentences follow the active order of SV(O) (Subject – Verb – (Object)) and are transformed into SV(Ag) (Subject – Verb – (Agent)). However, this is only one possibility. As Alexiadou explains (1999: 45), Modern Greek is a “null subject language in which various arrangements of the arguments are possible.” Thus, apart from the active SVO order, the passive voice can follow any other word order. In her study, Lascaratou summarizes all the syntactic possibilities of the passive voice that were found in her corpus, which are presented in Table 2 (Lascaratou 1984: 236).
Table 2
Frequency of the passive voice word orders[*]
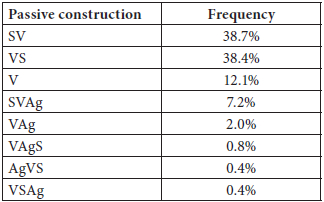
From Lascaratou (1984: 236)
Thus, there are many possible word orders that are allowed in both primary and subordinate passive voice clauses (Smirniotopoulos 1992: 45), and the agent can appear both before and after the passive verb form.
3.2. Comparing the passive voice in English and Modern Greek
Although the active voice is more common than the passive one in both languages, the passive voice seems to be more frequent in English than in Modern Greek (Warburton 1975; Marmaridou 1987). The reason for this difference can be primarily found in the functional sentence perspective (FSP) possibilities of the two languages. More particularly, as Warburton readily explains, “the English passive is often used in order to accommodate FSP requirements, while [Modern] Greek uses enclitics, word order and intonation for that purpose” (Warburton 1975: 576). Such claims have been made in relation to general language usage. Since no study on English and Modern Greek popular scientific texts has ever been conducted, it is rather difficult to argue with any certainty that Modern Greek informative texts employ passive voice with the same frequency as non-informative ones. However, the different linguistic possibilities between the two languages, especially in terms of FSP possibilities, as well as recent corpus-based studies (Fotiadou 2010) provide supportive evidence for the preference of the active voice in Modern Greek. Thus, the passive voice seems to play a more central role in English than in Modern Greek. In terms of specific text genres, it has been argued that the English passive voice is more common “in informative than imaginative writing, and is notably more frequent in the objective impersonal style of scientific articles and news reporting” (Quirk, Greenbaum et al. 1985: 166). Although no particular reference is made to popular science articles, it is generally believed that they are informative texts sharing numerous characteristics with both science and news articles. Thus, it can be reasonably assumed that, when it comes to popular science articles, the passive voice is more frequent in English than in Modern Greek.
As far as the passive word order in English is concerned, it follows the general fixed word order of the language, which is a result of the loss of inflection in the historical development of the language, with the agent always appearing after the passive verb form. Thus, the only available word order in English is that of SV(Ag). In contrast, many more possibilities are available in Modern Greek. Lascaratou (1984) has found that the most frequent passive word orders in Modern Greek are SV, VS and V, thus reflecting the syntactic flexibility of the language.
Taking into consideration the status of English in the contemporary information society, as well as the linguistic differences between English and Modern Greek, the present study examines the influence of the English structures on the usage of the passive voice in Modern Greek translated texts. This influence is considered to be the inescapable result of the translation process.
4. Corpus analysis
In order to closely investigate the language of translated texts, the use of comparable corpora has been proposed by Baker (1993). Corpora refer to collections of texts that are available in machine-readable form and can be analysed automatically or semi-automatically using different software. Baker (1995) proposes a number of different types of corpus-based research that can be used within the field of translation studies, i.e. parallel corpora, multilingual corpora and comparable corpora. Her understanding of a comparable corpus is one that consists of two sets of texts in the same language, the first consisting of translations from a particular source language or languages and the second of non-translated texts in that language (Baker 1995). What makes comparable corpora distinctive is that they consist of monolingual texts, while both parallel and multilingual corpora include different languages. Research using comparable corpus-based methods can identify patterns that are either exclusively used in translated texts or present a marked distribution in translated texts. For the purposes of this study, a comparable corpus is used in order to investigate the extent to which particular linguistic features found in translated texts are dependent on both the source and the target language of the translation.
4.1. Data and methodology
The popular science articles analysed in this study come from Βήμα Science (VimaScience), which is a section of the Modern Greek broadsheet newspaper To Βήμα (To Vima) as part of its Sunday edition, dedicated to scientific issues. This scientific section includes both translated Modern Greek texts from New Scientist, as well as non-translated Modern Greek articles. Since both translated and non-translated articles are from the same publication, the style and editorial guidelines as well as the variety of language are kept constant, thus allowing for a true comparable study.
The data set consists of a comparable corpus of approximately 20,000 words, that is, eight articles, published in 2010 and divided into two equally balanced subcorpora. The first subcorpus, the Translated Language Corpus (TLC), includes four Modern Greek popular science articles translated from English. The second subcorpus, the Non-translated Language Corpus (NTLC), involves four Modern Greek non-translated popular science articles. The size of the articles is the same, that is, approximately 2,000 words each. It is worth mentioning that the TLC includes translations of articles that were originally published in 2010. Thus, all the articles analyzed in this study were published and translated during the same period, i.e. between January and June 2010. The articles were selected based on their subject matter, and an attempt was made to incorporate different fields of science. The reason behind this is that subtle but important differences may be observed across popular scientific texts that deal with different domains. Thus, the four domains that are included in both subcorpora are: (a) technology, (b) psychology, (c) evolution and (d) physics. The corpus size is relatively small, due to the fact that manual analysis was also involved during the examination of the corpus, which would have been inhibited by a large corpus.
The data analysis combines both quantitative and qualitative techniques, based on computer-based methods of analysis. The software used in the analysis was the Concordance Tool from WordSmith Tools 5.0, since it allows for quite sophisticated word search queries and, most importantly, for the refinement of the results, i.e. the deletion of concordance lines. The analysis was based on semi-automatic methods, since the nature of the linguistic features demanded refinement of the concordance lines. The unit of analysis was considered to be the passive verb form. Since auxiliary verbs do not provide any lexical information, they were excluded from the counts in this study. A part-of-speech (POS) tagger was not used, since available Modern Greek POS taggers, such as Unitex or Tree Tagger, either do not specify the degree of accuracy they can achieve, or present an overall relatively low accuracy with voice identification. Since Modern Greek is an inflectional language, wildcards based on verb inflections can be used in order to identify verb occurrences.
4.2. Frequency of the passive voice
First, a count of the number of verb forms was conducted, as well as a frequency count of the passive voice instances in both subcorpora. This was achieved with the use of wildcards. Since verb forms in Modern Greek are inflected for tense, aspect and person, the software was asked to find all the possible Modern Greek verb form inflections, both active and passive. The wildcards for all the verb forms, both active and passive were the following: *ω/*εις/*ει/*ώ/*είς/*εί/*ουν/*ούν/*α/*ά/*άς/*άν/ *αν/*ες/*ε/*τας/*ου/*αι/*μεν*/*μέν*.
Next, wildcards were used in order to identify the morphologically passive voice verb forms. These were: *ώ/*είς/*εί/*ούμε/*είτε/*ούν/*ηκα/*ηκες/*ηκε/*ήκαμε/ *ήκατε/*ηκαν/*μαι/*σαι/*ται/*στε/*μουν/*σουν/*ταν/*μεν*/*μέν*/*ου.
The wildcards cover all possible verb forms, including participles, with the minimum amount of wildcards. The reason why the number of wildcards is larger in the second frequency count is that by condensing the number of all Modern Greek verb form inflections, of which there are more than fifty, the computerized analysis captures all possible verb phrases with the minimum number of wildcards. The results were examined closely and refined, in order to omit auxiliaries and cases where the same inflections were used for nouns and adjectives, as well as to distinguish between instances where the same suffix is used for both active and passive voice, such as *ώ/*είς/*εί. The relatively small size of the corpus allowed for such manual analyses to be conducted accurately, despite the high level of noise in the data. The aim was to examine whether the TLC texts employ the passive voice more frequently and are thus closer to English patterns.
In order to normalize results, those were brought to a common base of 100. By comparing the results, it was found that the frequency of the passive voice is very similar in both subcorpora, that is, approximately 20%, as can be seen in Table 3.
Table 3
Frequency of the passive voice in the NTLC and the TLC

The results are quite surprising, since it seems that the frequency of the passive voice in the two subcorpora does not differ; in fact it is almost exactly the same, namely 20%. However, this should not be perceived as a lack of influence from English. A possible explanation is that it is not the TLC texts that follow the NTLC patterns, but rather the reverse. The frequency of the passive voice in both subcorpora seems to be closer to the distribution of the passive voice in English. In particular, Biber, Johansson et al. note that, according to their corpus findings, the English passives account for approximately 25% of all finite verbs in academic prose and for 15% in news (Biber, Johansson et al. 1999: 476). If we are to consider that popular science articles stand somewhere in between these two genres, since they present scientific issues in an accessible way, the frequency of passive voice in English popular science articles can be considered to be somewhere between these two proportions, i.e. approximately 20%. The figures of all passives in both subcorpora represent exactly this proportion. Thus, it is possible that, due to reasons whose investigation is outside the scope of this study, the NTLC texts tend to follow the patterns of the TLC texts, which are closer to the English patterns. An alternative interpretation of the results is that the passive voice is more frequent in formal genres than in non-formal ones, and that TLC texts simply mirror the frequencies found in the NTLC. Of course, the fact that some academic articles must have been the source of these popular science articles is not to be neglected, however the communicative conventions employed in the articles analyzed for this study closely resemble those found in news articles. For example, a rather informal language is used in the titles of both the translated and the non-translated popular science articles, such as Παρά Τρίχα δεν θα Ήμαστε Άνθρωποι [Thank Hair, We are Humans], Εγώ ο Ιός: Γιατί είμαστε άνθρωποι μόνο κατά το ήμισυ! [I, Virus: Why we are only half human!], Κάτω τα χέρια απ’το τιμόνι [Put the wheel down]. Thus, it is more probable that the non-translated texts have started to follow patterns found in translated texts rather than that they mirror the more formal language employed in Modern Greek scientific articles.
In the analysis of the data, some findings were recorded, which are worth mentioning since they reveal that Modern Greek is affected by English when it comes to translating the passive voice. The phrase αναμένεται να λανσαριστεί το Μάιο [it is expected to be launched in May] was identified, which is interesting not only for the use of two passive voice verb forms next to each other, but most importantly for the use of the verb λανσαριστεί [to be launched]. This verb is a reborrowing of the Ancient Greek λόγχη [spear], which came to Modern Greek with its contemporary meaning from French relatively recently (Babiniotis 2008). Loan words, and especially recent ones, take some time before they can be fully inflected. Thus, although the passive form of this verb exists, it may strike native speakers of Modern Greek as rather odd, since there is a Modern Greek equivalent that is much more widely used, i.e. κυκλοφορήσει. The fact that λανσαριστεί is preferred here is because the English text uses the phrase will be launched, thus illustrating that the use of a reborrowing, but more importantly its passive form, is a possible result of the influence from the English source text. Similarly, the phrase τα οχήματα χωρίζονται από απόσταση [the vehicles are separated by a distance] includes the passive voice occurrence of the verb χωρίζω [to separate]. Although such a phrase is grammatically and syntactically correct, it could have been transformed into τα οχήματα έχουν απόσταση [the vehicles have a distance], where the more frequently occurring collocation έχω απόσταση [to have distance] is employed, with the verb appearing in the active form. As with the previous example, the English source text prefers the passive voice, i.e. are separated, providing a likely explanation for the passive voice preference in the translated text. Another interesting case is the phrase οχήματα που οδηγούνταν από ανθρώπους [vehicles driven by humans]. Such a phrase might sound rather awkward to at least a few people and a possibly better alternative would be οχήματα που οδηγούσαν άνθρωποι [vehicles that humans drive]. In the latter case, the same verb is used, albeit in the active voice. In the English text, a past participle is used, namely human-driven, which was most probably perceived by the translator as an underlying passive voice construction, i.e. vehicles that are driven by humans. Although, it can be argued that the use of a specific verb in the passive might have to do with the subject matter of the article, the context or even personal preferences, the number of similar instances in the translated corpus suggests that it is likely that there is some other reason behind the preference of the passive voice, namely some kind of influence from the source texts. The examples provide further support for the claim that the frequency with which the passive voice is used in translated texts is a feature of the Modern Greek language of translation. If we accept that the frequency with which the passive voice is used in the translated texts is higher due to the influence from the English source texts, as the examples indicate, then it can be argued that the similar proportion of the passive voice in the non-translated texts is a result of some kind of interaction between the translated and the non-translated texts. A diachronic study of the passive voice in Modern Greek would shed more light on any linguistic changes attested in terms of frequency. Such a study is planned to be conducted in the future as part of the current project. Until then, we can only speculate about the impact of translated texts on non-translated ones.
4.3. Word order of the passive constructions
As for the word order of the passive constructions, the TLC and NTLC texts were compared in terms of the most frequent passive word order. This was achieved by a manual comparison of the concordances generated. The instances of the passive voice that were found in the previous phase of analysis were closely analysed in order to examine the word order of each passive voice occurrence. The aim was to examine whether differences can be observed between the two subcorpora and whether the TLC texts follow more closely the English word order or if they allow more flexibility.
Attention was mainly paid to the position of the subject, the verb form and the agent whenever it was included; in the description, no reference is made to the other possible sentence constituents. Table 4 summarizes the findings in both the NTLC and the TLC texts. The results were normalized with the common base of 100. The percentages refer to the proportion of each syntactic structure out of all passives.
Table 4
Frequency of the passive voice orders in the NTLC and the TLC
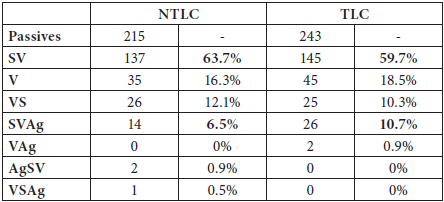
The most frequent syntactic structure in both subcorpora is that of SV(Ag), which accounts for approximately 70% of the passive constructions examined in both the NTLC and the TLC. The percentages of SV and SVAg are combined, since they both refer to the same structure, namely SV(Ag), that follows the general active word order SV(O) which is the only possible passive voice structure in English. Differences are observed in the variety of different syntactic structures employed. In particular, in the NTLC texts, four alternative syntactic structures were also employed, namely, V, VS, AgSV and VSAg, whereas in the TLC texts, there were only three alternative patterns, namely, V, VS and VAg. This difference in the number of alternative structures seems to indicate that the NTLC allows for less flexibility. However, due to the small proportion of the alternative orderings, more research is required in order to reach more robust conclusions.
The fact that in both subcorpora the most frequent order is SV(Ag) is not surprising, since Lascaratou’s corpus findings confirm that it is the most frequent passive order used in Modern Greek, accounting for approximately 45.9% of the passive voice constructions in that language (Lascaratou 1984: 236). What is surprising is that, on the one hand, in both subcorpora the proportion of this structure is much higher than what was suggested by Lascaratou. On the other hand, this proportion, namely approximately 70%, is the same in both subcorpora. The high percentage of the SV(Ag) structure in the TLC texts suggests that the structures employed in these texts are most probably affected by the English patterns. Additionally, the same percentage of such structures in the NTLC texts suggests that they may be affected by the patterns employed in the TLC texts.
A closer examination of both the TLC and NTLC texts reveals that the SV(Ag) was preferred even in cases when it would have been easier or preferable to employ a VS(Ag) word order. For example, the sentences:
Sentences (1) to (3) are taken from the TLC texts, and sentences (4) to (6) come from the NTLC texts. All examples, apart from the last one, could have been easily rearranged in order to allow for the subject to appear after the verb form, and in some cases this rearrangement would have probably resulted in a less marked construction. This is particularly the case for sentence (5), which involves a subordinate clause where the VS ordering, i.e. όταν τηρείται αυτή η προϋπόθεση [when is met this condition], is also possible and probably would have been preferred, since the VS structure is particularly frequent in subordinate clauses. The last example, which is taken from the NTLC, is an instance of a SV word order that could have been transformed into a V order. In particular, it could have been rewritten as μπορούμε να οδηγηθούμε σε σημαντικά συμπεράσματα [can be driven to important conclusions], with the subject we being implied by the verb inflection and thus being omitted. The inclusion of a generic subject, such as one, seems to reflect English communicative preferences where the subject always has to be included, even if it is a generic one or the dummy subject it. The inclusion of this generic subject in a non-translated text reflects the possible influence of English on Modern Greek patterns and provides support for the assumption that the NTLC texts have been affected by the TLC ones.
Apart from significant similarities, some differences are also observed in the two subcorpora. The NTLC texts seem to allow more flexibility in terms of the passive voice syntactic structures, since they allow for greater variety of patterns. An example of this flexibility is the AgSV ordering which is found twice in the NTLC. This structure did not occur at all in Lascaratou’s study which examined 3,525 instances of Modern Greek passive voice structures. Thus, it seems to be a marginal pattern, which, nonetheless, is found here supporting the fact that more flexibility is observed in the NTLC texts and for that reason more marginal cases can be found.
The VS (and VSAg) ordering manifests the great syntactic flexibility of Modern Greek. This syntactic pattern is the basic structure used in subordinate clause, but has also been claimed to be quite frequent in main clauses (Philippakki-Warburton 1985; 2001; Spyropoulos and Philippakki-Warburton 2001; Roussou and Tsimpli 2006). In fact, Lascaratou found that this ordering is the second most common in Modern Greek passive voice constructions (Lascaratou 1984: 236). The non-translated texts seem to use this ordering more frequently than the translated ones and the difference between the two subcorpora seems to be statistically significant (χ2=0.46, p<0.05). A possible explanation is that the translated texts are affected by the English ordering found in the source texts, where the subject is not inverted, and thus prefer the SV or V structure. An interesting study would be to compare the frequency of main and subordinate clauses in the texts and compare their preferred word order. If the TLC texts are found to have fewer subordinate clauses, this will provide a possible explanation for the lower percentage of the VS(Ag) structure and confirm the idea that translated texts prefer simpler syntactic options (Baker 1993; 1995; Laviosa-Braithwaite 1996).
As for the V (and VAg) ordering, it is used more frequently in the translated texts, the difference between the two subcorpora being statistically significant (χ2=0.51, p<0.05). This is logical if this pattern is considered to be the surface structure of an underlying SV or VS structure. Modern Greek being an inflectional language, it is also a pro-drop language, and the subject in a sentence is often omitted, especially in the translation of English text that employs the dummy subject it. Thus, when a dummy it appears in the English texts, translators will often omit it, making use instead of the V(Ag) structure. If they included it, unnecessary emphasis would be placed on the subject, since it is an optional element in such cases. Indeed, it was found that 52% of the V(Ag) structures in the TLC involved the omission of a dummy it, compared to 42% in the NTLC. However, because of the small size of the corpus, further research is needed in order to confirm this hypothesis.
5. Discussion
With reference to the frequency of the passive voice and the word order of the passive constructions, the two subcorpora present striking similarities which are not in accordance with what the scholarly literature has suggested about the use of the passive voice constructions in Modern Greek. The frequency of the passive constructions was found to be remarkably similar in both the translated and non-translated texts, that is, approximately 20%. This seems to be in accordance with Sifianou’s (2010) findings on the passive voice as employed in announcements in the Athens Metro stations. She notes that no clear difference was observed between the English and the Modern Greek announcements in terms of the frequency of the passive voice (Sifianou 2010: 33). The most frequent word order in both subcorpora was found to be SV(Ag), with a frequency of approximately 70%. Differences were observed in the distribution of alternative syntactic structures. The similarities observed in the two subcorpora indicate that some other process is in action, apart from the influence of the English source texts. At first sight, it seems as if the TLC texts follow the patterns found in the NTLC and that the NTLC texts prefer a more formal register that would justify the preference of the passive voice. However, as the titles of the articles illustrate, the language used in the articles can be characterized as rather informal and rather close to the style used in news articles. Thus, after a careful examination of the findings, it seems that it is highly likely that the non-translated texts follow the patterns found in translated texts. The process in progress here appears to be language change. Although a diachronic study would provide further evidence to support this idea, it seems that some kind of language change is most probably taking place, and that the NTLC texts are influenced by some features of the passive voice found in the TLC texts and resulting from the influence of English.
It has been argued that the passive voice is becoming more frequent in Modern Greek (Apostolou-Panara 1991; 1999) and that its frequency tends to match that found in English texts. Studies (Bennett 2007; 2011) have shown that the discourse organization of academic texts in some languages, such as Portuguese, seems to increasingly favor the use the passive voice under the influence of the linguistic conventions found in respective English texts. Similarly, corpus-based studies have shown that the frequency of the passive voice in Persian has increased under the influence of the translations of English scientific texts (Amouzadeh and House 2010). It is reasonable to hypothesize that the extensive translation of popular science texts from English has encouraged the circulation of some translation-specific passive voice features of the TLC in the NTLC texts across the years, thus eliminating the differences between the two subcorpora.
If we were to accept that the translated texts have encouraged the different usage of the passive voice features in non-translated contemporary texts, then the translated texts must have been characterized by a translation-specific language at least at some point in time. In terms of the passive voice, these features would have been the more frequent use of the passive voice and the strong preference for SV(Ag) structures. It should be stressed, however, that in order to reach more robust conclusions about the nature of the language of translated texts and the rules of grammar that it tends or tended to follow, not only in terms of the passive voice but also in terms of other linguistic features, more research is required that will include the study of a larger corpus as well as a greater variety of linguistic features.
The aforementioned translation-specific features of the passive voice are mostly a result of the influence of English. However, not all translation-specific features can be explained by the source language interference. An example is the lower proportion of VS(Ag) structures in the TLC than in the NTLC. This can be explained by the fact that the TLC texts tend to prefer simpler morphosyntactic structures. Although the investigation of the reasons for such a preference is outside the scope of this study, an explanation can be found in the tendency of translated texts towards “disambiguation and simplification” (Baker 1993: 244). Vanderauwera was the first to note that complex syntactic patterns tend to be made simpler in translated texts (Vanderauwera 1985: 97-98). Translators tend to make use of simpler syntactic and grammatical options because they want to make their text more accessible to the readers. This involves both issues of mediation between the source and the target culture and the tendency of translators to avoid ambiguous structures that may result in a misinterpretation of the meaning of the text. It is probable that such is the case with the passive word order employed in the TLC texts. However, this should not rule out the possible explanation of the TLC texts being influenced by the English syntactic patterns.
The most important finding of this study is probably the fact that there is indirect, yet crucial, evidence that translation practice can encourage changes in language practice. Although this is a small-scale study that was not interested in examining this issue, it seems that translated texts not only take features from the target linguistic system, but also give it some of their translation-specific features, which are then absorbed by the target language. As a result, some features, which were once considered to be translation-specific, cease to be part only of translated texts and are widely used by non-translated texts as well.
Figure 1
Direction of influence among translated text, English and Modern Greek

The use of a comparable corpus revealed numerous advantages and considerably facilitated the identification of translation-specific features. Indeed, it allowed for a better understanding of the language of translation, since the primary concern was the translated text and its features and not the way in which these differ from the source text. The number of the passive voice instances analyzed allowed for valid conclusions to be drawn in most cases. By using computer-based methods of analysis and by combining quantitative and qualitative techniques, a descriptive account of translation was provided. A parallel corpus would not have been able to reveal the nature of the translated texts as independent texts, since the primary focus would have always been on how the translated texts differ from the source texts. Here, translation was presented as part of the target culture, influencing the target language and being influenced by it. Finally, it is only with the use of a comparable corpus that the implications of translation as a form of language contact can be adequately analyzed. However, in terms of Modern Greek, there are numerous problems that are still to be resolved, if computerized methods are to be used more effectively. On the one hand, a large part of the analysis was still carried out manually, which indicates that an accurate POS tagger for Modern Greek would considerably facilitate the analysis and provide results faster and more accurately. On the other hand, there is a necessity to create a widely accessible corpus of translated texts in Modern Greek, which would make the analysis of similar phenomena much more detailed and systematic.
It must be admitted that this study is limited in many respects. There are still numerous issues that remain to be investigated in order to reach more robust conclusions. In terms of the passive voice translation-specific features of Modern Greek texts, more research into the intricacies of the grammatical phenomenon is necessary, in order to facilitate similar analyses in the future. An interesting study would be the investigation of ‘true’ passive voice (as opposed to middle voice) instances in translated and non-translated texts, which will, however, imply a manual analysis of texts. Additionally, since the differences in the distribution of the different passive word orders were marginal in some cases, a study of a larger corpus is required. A diachronic corpus-based study of the distribution of the passive voice is also necessary in order to provide substantial evidence about whether or not a linguistic change in terms of the passive voice has taken place in Modern Greek and will be attempted in the future as part of a more general study on translation and language change. The passive voice is just one feature out of the many that can be investigated. Since such an analysis is innovative in Modern Greek, a more systematic analysis of more grammatical and syntactic features is necessary in order to better understand the translation-specific language of Modern Greek texts. The results found in this study can only point towards a particular direction, but the picture will never be complete without a more systematic and detailed categorization of numerous translation-specific features.
6. Conclusion
The present study has a dual importance for translation studies. On the one hand, it is one of the few Modern Greek studies that use a comparable corpus in order to investigate the nature of the translation practice. Contrary to most comparable corpus-based studies that employ corpora in order to investigate the language of translation as it is formulated independently of the source and target language, this study focuses on the linguistic features of the language of translation that are dependent on the both English and Modern Greek. On the other hand, this study indicates that translation has the potential of being an important field of language contact with important consequences. Even though it is still very early to conclude with certainty that translation encourages the different usage of particular linguistic features in non-translated texts, it seems however that not only the translated texts use the linguistic features of the target language, but also the target language absorbs some of their linguistic features.
A number of scholars have taken interest in investigating translation as a form of language contact and its effects on the target language, mainly within the English-German context (Steiner 2008; House 2004; 2008; Baumgarten and Özçetin 2008), although French and Spanish (House 2008) and Persian (Amouzadeh and House 2010) have also been investigated. However, apart from the studies conducted by German scholars, translation scholarship so far seems to have neglected the impact that translational behaviour can have on the target linguistic system, while language change specialists have failed to explore in depth the phenomenon of translation as a form of language contact. If this scholarly strand is to be consolidated, more research has to be conducted across a wider range of language pairs. In the era of the information society, the translation of popular science texts tends to be very much a unidirectional process from the dominant lingua franca, which is English, into less-spoken languages such as Modern Greek. Against this backdrop, changes in the communicative conventions of the target language due to the influence of English are likely to emerge. The study of these changes should stimulate reflection on current translator training practices and raise collective awareness of how the hegemony of English can affect linguistic and cultural diversity, along the lines discussed by Bennett (2007).
Parties annexes
Acknowledgements
I would like to thank my two anonymous reviewers for their valuable comments. Also, the Lilian Voudouris Foundation for providing the necessary financial support for the completion of this study.
Note
-
[1]
All glosses are from the author.
Bibliography
- Alexiadou, Artemis (1999): On the Properties of Some Greek Word Order Patterns. In: Artemis Alexiadou and Geoffrey Horrocks, eds. Studies in Greek Syntax. Dordrecht/London: Kluwer Academic Publishers, 45-65.
- Amouzadeh, Mohammad and House Juliane (2010): Translation and Language Contact: The case of English and Persian. Languages in Contrast. 10(1):54-75.
- Apostolou-Panara, Athena Maria (1991): English Loanwords in Modern Greek: An overview. Terminologie et Traduction. 1(1):46-60.
- Apostolou-Panara, Athena Maria (1999): Glossiki Metarithmisi ke Eksoterikos danizmos: I periptosi tis Neas Ellinikis [Language reform and External Borrowing: The case of Modern Greek]. In: 1976-1996: Ikosi Xronia apo tin Kathierwsi tis Neellinikis (Dimotikis) os Episimis Glossas [1976-1996: Twenty Years from the Establishment of Modern Greek as the Official Language]. Athens: Tsiveriotis, 333-341.
- Babiniotis, Georgios, ed. (2008): Leksiko tis Neas Ellinis Glossas [Dictionary of the Modern Greek Language]. 3rd ed. Athens: Kentro Lexikologias.
- Baker, Mona (1993): Corpus Linguistics and Translation Studies: Implications and applications. In: Mona Baker, Gill Francis and Elena Tognini-Bonelli, eds. Text and Technology: In honour of John Sinclair. Amsterdam/Philadelphia: John Benjamins, 233-250.
- Baker, Mona (1995): Corpora in Translation Studies: An overview and some suggestions for future research. Target. 7(2):223-243.
- Baker, Mona (1998): Réexplorer la langue de la traduction: une approche par corpus. Meta. 43(4):480-485.
- Baumgarten, Nicole and Özçetin Demet (2008): Linguistic Variation through Language Contact in Translation. In: Peter Siemund and Noemi Kintana, eds. Language Contact and Contact Languages. Amsterdam/Philadelphia: John Benjamins, 293-316.
- Bennett, Karen (2007): Epistemicide! The tale of a predatory discourse. The Translator. 13(2):151-169.
- Bennett, Karen (2011): The Scientific Revolution and its Repercussions on the Translation of Technical Discourse. The Translator. 17(2): 189-210.
- Biber, Douglas, Johansson, Stig, Leech, Geoffrey, et al. (1999): Longman Grammar of Spoken and Written English. Harlow: Longman.
- Frawley, William (1984): Prolegomenon to a Theory of Translation. In: William Frawley, ed. Translation: Literary, linguistic, and philological perspectives. London and Toronto: Associated University Press, 159-175.
- Fotiadou, Georgia (2010): Voice Morphology and Transitivity Transformations in Greek: Evidence from corpora and psycholingustic experiments. Doctoral thesis, unpublished. Thessaloniki: Aristotle University of Thessaloniki.
- House, Juliane (2004): English as a Lingua Franca and its Influence on Other European Languages. In: José María Bravo, ed. A New Spectrum of Translation Studies. Valladolid: Universidad de Valladolid, 49-62.
- House, Juliane (2008): Global English and the Destruction of Identity? In: Paschalis Nikolaou and Maria-Venetia Kyritsi, eds. Translation Selves: Experience and identity between languages and literatures. London/New York: Continuum, 87-107.
- Kleris, Christos and Babiniotis, Georgios (2005): Grammatiki tis Neas Ellinikis: Domolitourgiki-epikinoniaki [Modern Greek Grammar: Structural-functional-communicative]. Athens: Ellinika Grammata.
- Lascaratou, Chryssoula (1984): The Passive Voice in Modern Greek. Doctoral thesis, unpublished. Reading: University of Reading.
- Laviosa, Sara (2000): TEC: A Resource for Studying what is “in” and “of” Translational English. Across Languages & Cultures. 1(2):159-178.
- Laviosa-Braithwaite, Sara (1996): Comparable Corpora: Towards a corpus linguistic methodology for the empirical study of translation. In: Marcel Thelen and Barbara Lewandoska-Tomaszczyk, eds. Translation and Meaning. Maastricht: UPM, 153-163.
- Laviosa-Braithwaite, Sara (1998): Universals in Translation. In: Mona Baker, ed. Routledge Encyclopedia of Translation Studies. London/New York: Routledge, 288-291.
- Mackridge, Peter (1985): The Modern Greek Language. Oxford: Oxford University Press.
- Manney, Linda Joyce (2000): Middle Voice in Modern Greek: Meaning and function of an inflectional category. Amsterdam/Philadelphia: John Benjamins.
- Marmaridou, Sophia (1987): Semantic and Pragmatic Parameters of Meaning: On the interface between contrastive text analysis and the production of translated texts. Journal of Pragmatics. 11(1):721-736
- Mutesayire, Martha (2005): Investigating Lexical Explicitation in Translated English: A Corpus-Based Study. Doctoral thesis, unpublished. Manchester: University of Manchester.
- Olohan, Maeve and Baker, Mona (2000): Reporting that in Translated English: Evidence for subconscious processes of explicitation? Across Languages and Cultures. 1(2):141-158.
- Øverås, Linn (1998): In Search of the Third Code: An investigation of norms in literary translation. Meta. 43(4):557-570.
- Philippaki-Warburton, Irene (1985): Word Order in Modern Greek. Transactions of the Philological Society. 83(1):114-143.
- Philippaki-Warburton, Irene (2001): Glossologiki Theoria ke Sintaxi tis Ellinikis: I pikilia sti sira ton oron tis protasis [Linguistic Theory and Greek Syntax: Variation in clausal word order]. In: Yoryia Agouraki, Amalia Arvaniti, Jim Davy, et al. Greek Linguistics ‘99: Proceedings of the 4th International Conference on Greek Linguistics (Nicosia, September 1999). Thessaloniki: University Studio Press, 217-231.
- Quirk, Randolph, Greenbaum, Sidney, Leech, Geoffrey, et al. (1985): A Comprehensive Grammar of the English Language. London: Longman.
- Rabin, Chaim (1958): The Linguistics of Translation. In: Leonard Forster, Andrew D. Booth and David J. Furley, eds. Aspects of Translation. London: Secker and Warburg, 123-145.
- Roussou, Anna and Tsimpli, Ianthi Maria (2006): On Greek VSO Again! Journal of Linguistics. 42(1):317-354.
- Sharkas, Hala (2009): Translation Quality Assessment of Popular Science Articles: Corpus study of the Scientific American and its Arabic version. Trans-kom. 2(1):42-62.
- Sifianou, Maria (2010): The Announcements in the Athens Metro Stations: An example of glocalization? Intercultural Pragmatics. 7(1):25-46.
- Smirniotopoulos, Jane (1992): Lexical Passives in Modern Greek. New York/London: Garland.
- Spyropoulos, Vassilis and Philippaki-Warburton, Irene (2001): Subject and EPP in Greek: The discontinuous subject hypothesis. Journal of Greek Linguistics. 2(1):148-186.
- Steiner, Erich (2008): Empirical Studies of Translations as a Mode of Language Contact: “Explicitness” of lexicogrammatical encoding as a relevant dimension. In: Peter Siemund and Noemi Kintana, eds. Language Contact and Contact Languages. Amsterdam/Philadelphia: John Benjamins, 317-346.
- Theophanopoulou-Kontou, Dimitra (2000): Domes tis NE me Prooptiki tou Dekti ke i Katanomi –o/-mai: Ta antimetavatika ke ta pathitika [-O/-mai alternations in MG Patient Oriented Constructions: Anticausatives and passives]. In: Theodosia Pavlidou and Christos Tzitzilis, eds. Proceedings of the 20th Annual Meeting of the Linguistic Department of the University of Thessaloniki. Thessaloniki: Institute of Modern Greek Studies, 146-157.
- Toury, Gideon (1979): Interlanguage and its Manifestations in Translation. Meta. 24(2):223-231.
- Toury, Gideon (1995): Descriptive Translation Studies and Beyond. Amsterdam/Philadelphia: John Benjamins.
- Tsimpli, Ianthi Maria (1989): On the Properties of the Passive Affix in Modern Greek. ULC Working Papers in Linguistics. 1(1):235-260.
- Tsimpli, Ianthi Maria (2005): I Phoni stin Elliniki: Perigrafi tou sistimatos ke meleti tis anaptiksis tou stin elliniki os mitriki ke os deuteri kseni glossa [Voice in Greek: Description of the system and examination of its development in Greek asnative and second language]. In: Spyros Moschonas, ed. I Syntaksi sti Mathisi ke sti Didaskalia tis Ellinikis os ksenis glossas [Syntax in the Learning and Teaching of Greek as a foreign language]. Athens: Patakis, 62-116.
- Tsimpli, Ianthi Maria (2006): The Acquisition of Voice and Transitivity Alternations in Greek as native and Second Language. In: Sharon Unsworth, Teresa Parodi, Antonella Sorace,et al., eds. Paths of Development in L1 and L2 Acquisition: In honour of Bonnie D. Scwartz. Amsterdam/Philadelphia: John Benjamins, 15-55.
- Tzartzanos, Ahilleas (1946): Neoelliniki Sintaxis [Modern Greek Syntax]. Athens: OEDB.
- Vanderauwera, Ria (1985): Dutch Novels Translated into English: The transformation of a “minority” literature. Amsterdam: Rodopi.
- Warburton, Irene (1970): On the Verb in Modern Greek. Bloomington: Indiana University Press.
- Warburton, Irene (1975): The Passive in English and Greek. Foundations of Language. 13(4):563-578.
 10.7202/001951ar
10.7202/001951arListe des figures
Figure 1
Direction of influence among translated text, English and Modern Greek
Liste des tableaux
Table 1
Modern Greek passive voice inflections
Table 2
Frequency of the passive voice word orders[*]
From Lascaratou (1984: 236)
Table 3
Frequency of the passive voice in the NTLC and the TLC
Table 4
Frequency of the passive voice orders in the NTLC and the TLC