
Résumés
Résumé
En 2018, La Presse Canadienne a mis au point Ultrad, un système de traduction automatique (TA). Ultrad est un des rares systèmes de TA à être utilisé quotidiennement par des journalistes au Canada. Toutes les traductions d’Ultrad sont révisées avant d’être publiées dans la langue cible. Notre article porte sur l’évaluation des traductions fournies par l’outil et sur les révisions apportées par les journalistes de l’agence de presse. Pour mener à bien ce travail, nous avons dépouillé un échantillon de 148 articles en anglais comportant une version traduite automatiquement en français et une version révisée par un rédacteur ou une rédactrice de La Presse Canadienne. L’évaluation des traductions, d’une part, et, d’autre part, la comparaison entre les textes traduits automatiquement et les textes révisés en post-édition (PE) ont reposé sur différentes méthodes d’analyse outillées : la comparaison des fréquences de mots, de l’alignement des paragraphes et de leur sous-segmentation en phrases graphiques pour chacun des deux groupes de bitextes (anglais avec la traduction brute, puis anglais avec la version révisée en PE) et des volumes informationnels des paires de segments; la distance euclidienne (DE) à trois dimensions entre segments source et cible et la correction linguistique fournie par le logiciel de correction linguistique Antidote sur la totalité des articles révisés. Notre étude est l’une des rares à s’être penchée sur l’utilisation de la TA par des journalistes. Elle met en évidence les lacunes de la TA et le caractère incontournable des interventions humaines en PE, même si ces interventions ne sont pas infaillibles.
Mots-clés :
- traduction automatique,
- post-édition,
- journalisme,
- La Presse Canadienne,
- erreurs de traduction
Abstract
In 2018, La Presse Canadienne (the French-language counterpart of The Canadian Press) developed Ultrad, a machine translation (MT) system. Ultrad is one of the few MT systems used daily by journalists in Canada. All Ultrad English to French translations are reviewed before being published in the target language. Our article focuses on the evaluation of the translations provided by the tool and post-editing by the news agency’s journalists. To conduct this work, we examined a sample of 148 English-language articles with both machine-translated and post-edited versions in French. The evaluation of the translations, on the one hand, and the comparison of the machine-translated and post-edited texts, on the other, relied on different methods of analysis: comparison between word frequencies, paragraph alignment and their sub-segmentation into graphic sentences for each of the two groups of bitexts (English with the raw translation and English with the revised post-edited translation) and the information volumes of the pairs of segments; the three-dimensional Euclidean distance (ED) between the source and the target segments; and the linguistic correction provided by the Antidote linguistic correction software on the entirety of the post-edited articles. Our study is one of the few that has examined the use of MT by journalists. It highlights the shortcomings of MT and the importance of human interventions in post-editing, even if these interventions can be error-prone.
Keywords:
- machine translation,
- post-editing,
- journalism,
- The Canadian Press,
- translation errors
Corps de l’article
Introduction
Les recherches sur la traduction en contexte journalistique ont mis au jour le rôle crucial qu’a joué la traduction dans le développement du journalisme. Du XVIIe siècle jusqu’à la fin du XIXe, les premiers journaux européens remplissaient leurs pages en grande partie grâce à des articles traduits d’autres journaux publiés dans les pays voisins, rapportent entre autres Valdeón (2015, pp. 637-639) et Zanettin (2021, pp. 44-47).
La recherche en communication l’atteste, notamment au Canada où se côtoient deux langues officielles. Dans son ouvrage phare sur le développement de la presse québécoise dans les trente années qui ont précédé la Première Guerre mondiale, Jean de Bonville (1988, pp. 165-172) mentionne que les journaux du Canada français puisaient allègrement dans des périodiques britanniques, américains ou canadiens anglais pour du contenu, à l’époque. On retrouve en outre, dans plusieurs récits de journalistes, des traces de ces pratiques. L’historien Thomas Chapais raconte par exemple que lorsqu’il a commencé à pratiquer le journalisme, à la fin du XIXe siècle à Québec, la « traduction des dépêches » était la première des « besognes qui ont pour objectif de remplir les colonnes du journal » (1905, p. 8).
Avec le développement du télégraphe, les activités de traduction journalistique ont eu tendance à être centralisées par des agences de presse. Quand la première de ces agences (Havas, ancêtre de l’Agence France-Presse) a été créée en 1835, Honoré de Balzac lui-même a remarqué très tôt que la traduction était l’une des principales fonctions qu’elle permettait de mutualiser :
Tous les journaux de Paris ont renoncé, par des motifs d’économie, à faire, pour leur compte, les dépenses auxquelles M. Havas se livre d’autant plus en grand qu’il a maintenant un monopole, et tous les journaux, dispensés de traduire comme autrefois les journaux étrangers [...], subventionnent M. Havas par une somme mensuelle pour recevoir de lui, à heure fixe, les nouvelles de l’étranger.
1840, pp. 246-247; italiques dans l’original
La traduction est à un tel point au coeur du travail des agences de presse, selon certains, qu’il serait en réalité plus juste de les décrire comme des agences de traduction (Bielsa et Bassnett, 2009, chap. 4). Cette affirmation est un peu forte, à notre avis. La cueillette, la vérification et la diffusion d’information demeurent les principales activités des agences de presse contemporaines. La traduction y est une activité secondaire. Cela dit, l’importance de cette activité est souvent occultée par les journalistes ou les chercheurs en communication.
C’est ainsi que le rôle de la traduction au sein de la principale agence de presse au Canada est méconnu, autant en traductologie qu’en communication. Fondée en 1917 sous le nom de Canadian Press, elle n’a créé son Service français qu’en 1951 et embauché son premier journaliste francophone qu’en 1959. « CP [Canadian Press] was an English-language institution, headquartered in Toronto, that operated almost entirely in English. There was no original reporting in French; the Service français was essentially an improved translation service » (Allen, 2013, p. 216).
L’agence qu’on appelle en français La Presse Canadienne (LPC) compte une quarantaine de journalistes aujourd’hui parmi les quelque 180 de l’organisation. Ces journalistes rédigent principalement des textes dans leur langue maternelle. Mais la traduction continue néanmoins de faire partie de leurs responsabilités. En effet, plusieurs journalistes de La Presse Canadienne traduisent les textes de leurs collègues anglophones et ceux de l’Associated Press, dont LPC est le distributeur exclusif au Canada.
Si la recherche sur la traduction en contexte journalistique s’est souvent penchée sur le travail d’agences ou d’organisations de presse produisant des contenus dans plusieurs langues, comme la BBC, Al-Jazeera, Belga ou Keystone ATS, par exemple (Davier, 2017; Nelissen et Hendrickx, 2023; Valdeón, 2015), les organisations journalistiques canadiennes ont rarement fait l’objet de travaux. Conway (2015) a étudié l’échec des réseaux anglais et français de Radio-Canada de mutuellement traduire leurs bulletins de nouvelles; Boulanger et Gagnon (2018, 2020) ont analysé la couverture des questions financières dans les médias écrits anglophones et francophones du pays. Mais nous n’avons trouvé aucune étude sur La Presse Canadienne dans le corpus de plus en plus important des recherches sur la traduction en contexte journalistique, alors que c’est l’une des seules organisations de presse au Canada à traduire ses contenus d’une langue officielle à l’autre. Il appert en outre que la traduction automatique en contexte journalistique ait rarement eu l’occasion de faire l’objet de recherches. Martín Ruano (2021) a récemment examiné son utilisation par un média de Salamanque, en Espagne. Mais sinon, la littérature est muette à ce sujet.
Notre contribution est donc doublement originale dans le cadre de la recherche sur la traduction journalistique. Non seulement cet article est le premier à se pencher spécifiquement sur La Presse Canadienne, mais il est aussi un des rares à scruter l’utilisation qui peut être faite de la traduction automatique dans un contexte de travail journalistique.
1. Ultrad : la TA dans un contexte journalistique
Afin d’alléger et d’accélérer le travail de traduction de ses journalistes, la direction de La Presse Canadienne a mis au point en 2018 un outil appelé Ultrad. « C'est l’API “traditionnelle”[1] de Google Translate qui est utilisée en arrière-plan, avec quelques outils supplémentaires de “nettoyage” pour respecter les guides stylistiques de LPC », indique la personne qui a conçu l’outil (Laget, 2022). Ultrad prend la forme d’une interface web séparée en deux panneaux (figure 1). Un utilisateur peut afficher, dans n’importe lequel de ces deux panneaux, l’une ou l’autre de trois versions d’un même texte : la version originale dans sa langue source, la traduction automatique dans la langue cible, la post-édition de cette traduction dans la langue cible.
Figure 1
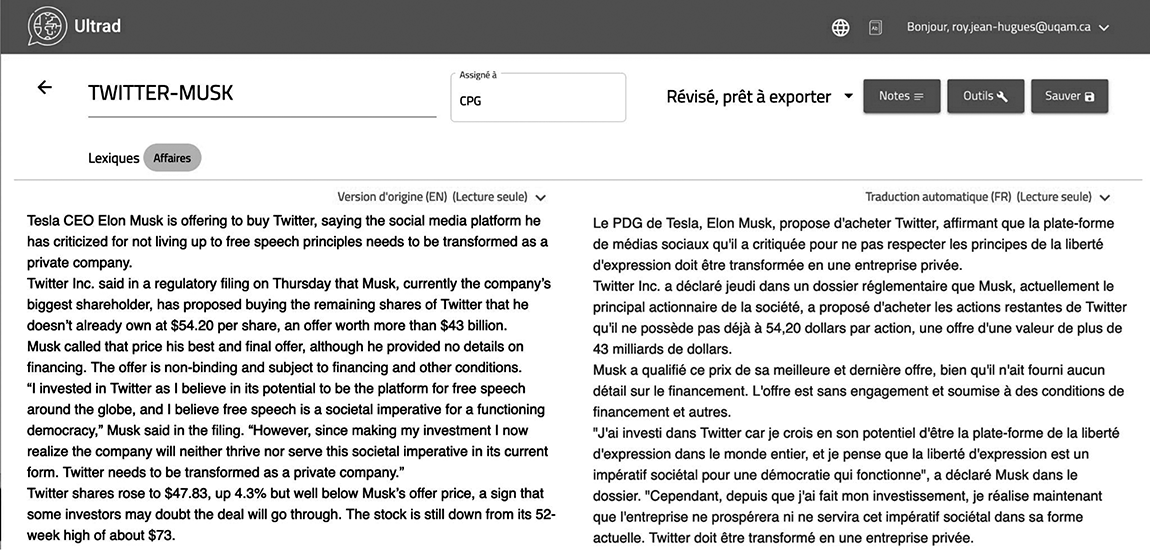
Interface de l’outil Ultrad, telle qu’elle apparaissait en avril 2022
En plus des trois versions incluses dans Ultrad, un texte traduit par La Presse Canadienne est révisé par un journaliste au pupitre. Il est ensuite diffusé sur le fil de presse de LPC et peut être publié par un média d’information et subir encore différentes révisions. Il peut donc y avoir quatre versions françaises d’un même article. Seule la première est une traduction automatique; les trois suivantes sont toutes le fruit d’une intervention humaine. La figure 2 illustre les différentes étapes du cheminement d’un texte entre sa version source et sa version publiée dans les médias.
Figure 2
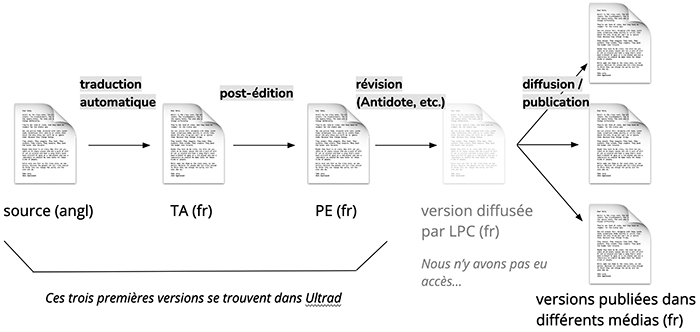
Cheminement d’un texte produit par La Presse Canadienne
Pour cet article, nous avons eu accès à quatre des cinq versions présentées dans la figure 2 (plus de détails dans la méthodologie, ci-dessous). Il n’y a que la version révisée avant diffusion qu’il ne nous a pas été possible de consulter. Notre article porte donc sur le travail qui est effectué à l’interne (à La Presse Canadienne), pour ce qui est des trois premières versions, et à l’externe, pour ce qui des versions publiées par les médias. Les chercheurs qui s’intéressent à la traduction journalistique ont rarement accès à des corpus parallèles, les textes sources étant généralement très difficiles à repérer (Davier et Van Doorslaer, 2018, pp. 245-249). Notre article ouvre donc une rare fenêtre sur les pratiques de traduction journalistique.
2. État de l’art en post-édition (révision de traductions brutes)
La conception de la traduction automatique neuronale (TAN) a considérablement amélioré la qualité du rendu des traductions, ce qui a favorisé l’utilisation à grande échelle des services de traduction automatique qui sont offerts gratuitement en ligne. Cette utilisation massive des services de TAN a aussi favorisé l’émergence de l’activité de révision des textes traduits par ces services. Cette activité est désignée par l’emprunt en français (et vraisemblablement dans les autres langues en Europe et dans le monde) du néologisme anglais post-edition qui s’appuie sur la fusion de deux acceptions du verbe to edit en anglais, soit celle de « réviser » en traduction et de « modifier » en informatique (Robert, 2010, p. 138), lesquelles risquent de se greffer au français par suite de cet emprunt.
Pour l’être humain ou, préférablement, le professionnel qui effectue cette activité, la principale fonction de la post-édition consiste à corriger les erreurs de traduction qui peuvent subsister dans les textes traduits automatiquement. Différentes modalités de travail (post-édition interactive ou statique (Bays, 2022), post-édition traditionnelle, adaptative et interactive (O’Brien, 2022), post-édition d’épreuve (intégrale) ou ponctuelle (Poirier et al., 2022)) ont été proposées de la part des traducteurs, en plus de celles qui ont cours dans l’industrie et qui ont été définies par le centre d’études et de recherches TAUS. Cet organisme a d’abord proposé de distinguer la post-édition rapide et la post-édition complète (TAUS et CNGL, 2010; Hu et Cadwell, 2016). Il a adopté par la suite une autre grille d’évaluation (Massardo et al., 2016; Poirier, 2020) qui intègre les deux types de post-édition dans une nouvelle grille de qualité à trois dimensions. La grille comporte un premier niveau de qualité sans intervention humaine qui correspond à la sortie brute des systèmes de TA, un deuxième où un être humain effectue une « post-édition rapide » et un troisième qui correspond à une « post-édition complète » par une ou plusieurs personnes.
D’après notre analyse et nos observations du système Ultrad, la révision de la TA qui est effectuée à LPC est une post-édition intégrale, statique et complète. Le premier avantage de la post-édition, et celui qui semble avoir été déterminant dans la mise en oeuvre du projet Ultrad à LPC, est celui du gain d’efficacité et de rapidité de l’opération de traduction. Cet avantage a été relevé par différentes études qualitatives comme celles de Koponen (2016), qui a dressé un état de la question. L’étude de Jia et al. (2019) a conçu un dispositif expérimental de comparaison des paramètres de traduction chez des sujets étudiants qui s’acquittaient d’une traduction intégrale de l’anglais au chinois et de la post-édition de la TAN brute de Google pour deux groupes de textes généraux et spécialisés. Ces auteurs ont conclu que seule la post-édition de textes spécialisés a entraîné un gain de temps significatif par comparaison avec la traduction intégrale. L’absence de gains de temps significatifs pour les textes généraux est une donnée pertinente qui devrait être prise en compte dans le contexte de la mise en oeuvre d’Ultrad qui porte sur des textes journalistiques de nature générale.
Dans son étude qualitative sur des textes du domaine financier (donc spécialisés), à laquelle nous revenons plus loin, Peraldi estime que « l’évaluation des dépenses en termes de temps et coûts de la post-édition est largement en faveur d’un recours à la traduction automatique » (2016, p. 86). Sur le plan qualitatif, Jia et al. (2019) ont établi qu’il n’y avait pas de différence sur les plans de la fluidité et de la précision des traductions traduites intégralement ou post-éditées. Dans son dispositif expérimental, Schumacher (2020) a fait traduire à 28 étudiants trois textes sources suivant trois méthodes : la traduction humaine intégrale (sans outil), la TA statistique (de Bing, révisée par les étudiants) et la TAN (de DeepL, révisée par les étudiants). L’auteure fait état de notes légèrement plus élevées pour les traductions issues de la post-édition par rapport à la traduction humaine pour les trois textes traduits par les participants (étudiants en traduction). Elle relève aussi le fait que les écarts de notes pour les textes post-édités sont moins grands que pour la traduction humaine. Enfin, en comparant les notes individuelles des étudiants en mode traduction intégrale et post-édition, l’auteure a observé un « effet nivelant » de la PE de TAN qui est inversement proportionnel au niveau de compétence des étudiants : les étudiants faibles sont ceux qui bénéficient le plus de la PE car ils ont obtenu en PE une note plus élevée tandis que les étudiants forts sont ceux qui sont le plus pénalisés par l’utilisation de la PE puisqu’ils obtiennent une note inférieure en PE par rapport à la traduction intégrale.
Parmi les effets négatifs, Martikainen et Kübler (2016) signalent que l’attention des traducteurs est principalement transférée du texte source au texte cible par l’interposition de la TA dans le processus traductionnel, ce qui entraîne une plus grande influence du texte source sur le texte cible (calques) et l’accoutumance à la sortie de la TA qui renforce l’équivalence formelle et la traduction littérale. La prépondérance accordée à la cible a été confirmée par l’étude de Volkart et al. (2021). L’accoutumance à la sortie de la TA peut s’expliquer par la tendance à ne pas remettre en question la TA en raison de l’effet d’amorçage [priming effect] (Carl et Schaeffer, 2017) qui décrit non plus l’influence du texte source sur la traduction mais plutôt celle de la formulation proposée par la TA en langue cible sur la formulation définitive de la traduction post-éditée. Comme effet négatif, cette méthode de traduction entraîne un plus grand effort cognitif en PE qui serait attribuable à une deuxième déverbalisation du message dans la langue cible. Comme l’avait relevé Pascale Amozig-Buckszpan, traductrice indépendante spécialisée en Israël, et ce, bien avant l’arrivée de la TAN, la post-édition « demande donc un niveau de concentration et de vigilance extrêmement élevé pour les non-initiés » (2014, n.p.). Cette plus grande attention nécessaire à l’opération de révision est illustrée par la difficulté de détection de certaines erreurs produites par la TAN appelées « hallucinations naturelles » (Raunak et al., 2021) ou « non perturbées » (Lee et al., 2018). Ces types d’erreurs sont d’autant plus difficiles à détecter qu’elles ne découlent pas d’une anomalie ou d’une « perturbation » repérable dans le texte source, comme l’ajout d’un élément étranger au texte ou une mauvaise segmentation de celui-ci, par exemple.
Nous nous intéresserons plus loin à un type particulier d’hallucinations naturelles donnant lieu à un énoncé cible qui, sans être agrammatical (la construction syntaxique respecte les règles usuelles de sélection et d’ordonnancement), soulève des problèmes notables d’impropriété en langue cible, par opposition à d’autres hallucinations naturelles d’imprécision qui soulèvent plutôt des problèmes de fidélité ou d’exactitude avec le segment source, lesquelles s’apparentent alors aux contresens. Les hallucinations naturelles impropres s’apparentent au résultat (fautif) du procédé de traduction bien connu qu’est le calque et qui donne lieu à des traductions mot à mot dont l’acceptabilité est toujours accidentelle (Poirier, 2023 [2019], p. 185). En situation de PE, ces hallucinations naturelles impropres mais grammaticales en langue cible sont fortement susceptibles de passer inaperçues, en raison de l’effet d’amorçage que nous avons mentionné précédemment. Cet effet négatif de la PE est susceptible d’être présent dans la mise en oeuvre d’Ultrad si les journalistes réviseurs adoptent comme version de départ le texte traduit automatiquement et ne se réfèrent qu’occasionnellement au texte source.
3. Questions de recherche et méthodologie
Puisque nous avons eu accès à différentes versions des textes traduits, l’introduction d’Ultrad a suscité chez nous les deux questions de recherche suivantes :
La TA est-elle appropriée pour répondre aux besoins d’une organisation journalistique comme La Presse Canadienne, notamment sur le plan de la qualité des traductions qu’elle doit faire sur plusieurs dizaines de dépêches chaque jour; et
Le type de post-édition traditionnelle mené par les journalistes est-il approprié pour répondre à ces besoins?
Pour nous permettre de répondre à ces questions, La Presse Canadienne nous a donné accès à Ultrad entre le 7 février et le 11 avril 2022. Au cours de cette période, 2 122 textes se trouvaient dans la base de données de l’outil. Les artisans de LPC nous ont indiqué qu’ils allaient identifier les textes ayant fait l’objet d’une post-édition en ajoutant la mention « révisé » à la suite du titre de ce texte (figure 3). Dans l’ensemble des textes se trouvant dans la base de données d’Ultrad, 178 portaient cette mention.
Figure 3
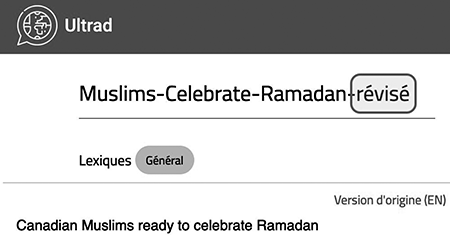
Exemple d’un article révisé dans l’outil Ultrad
Parallèlement, nous avons remarqué un attribut appelé state [état] dans les métadonnées associées à chaque texte. La valeur de cet attribut pouvait être revised [révisé]. La figure 4 en est une illustration. Dans l’ensemble de la base de données d’Ultrad, la valeur de l’attribut state de 624 textes était revised.
Figure 4
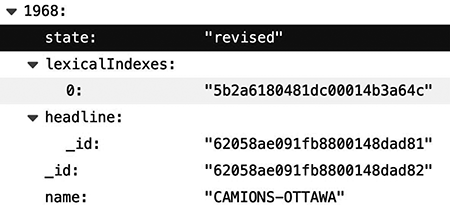
Extrait des métadonnées d’un texte de la base de données d’Ultrad montrant l’attribut state de valeur revised, indiquant que l’état de ce texte est « révisé »
Nous avons donc constitué notre corpus avec l’intersection de ces deux sous-ensembles. Ainsi, 148 textes avaient à fois la mention « révisé » dans leur titre et un attribut state de valeur revised.
3.1 Alignement des textes et constitution de corpus parallèles
Nous avons ensuite élaboré trois corpus parallèles à partir des trois versions de ces 148 textes :
texte source aligné avec sa TA (TS-TA)
texte source aligné avec la TA révisée en PE (TS-PE)
TA alignée avec la TA révisée en PE (TA-PE)
L’unité de l’alignement est la paire de segments source et cible qui sont réunis (alignés) pour former une unité textuelle séquentielle. L’alignement consiste à parcourir chaque texte source et cible d’un corpus en suivant séquentiellement la délimitation des phrases (grâce au symbole du point final suivi d’une majuscule), des retours à la ligne grâce au symbole du retour de chariot (↲) ou les changements de paragraphes grâce au symbole pied-de-mouche (¶).
Malgré la nature opératoire des critères utilisés, la segmentation automatique des textes en phrases est toujours partiellement réussie dans une même langue (l’emploi des signes délimiteurs varie), et a fortiori d’une langue à l’autre dans les corpus parallèles ou entre le texte source et sa traduction. Seule une validation manuelle des segments permet de bien aligner les phrases scindées ou fusionnées différemment dans le texte cible.
L’étude empirique de Raunak, Menezes et Junczys-Dowmunt (2021) sur les différents types d’hallucinations des systèmes de TAN a mis en évidence le rôle des bruits des corpus parallèles (ou mauvais alignements) dans la production de certains types d’hallucinations non naturelles (issues de perturbations du segment source), ce qui montre hors de tout doute que la qualité des alignements dans les corpus parallèles a un impact sur la qualité des traductions produites par les systèmes de TA.
De manière à choisir l’alignement optimal, nous avons utilisé deux logiciels d’alignement automatique des corpus : LF Aligner (Farkas, 2019) et Logiterm (Terminotix, 2022). Grâce à un module de dénombrement des phrases dans les segments source et cible à partir de la phrase graphique (présence d’un point non abréviatif) en accès libre pour l’anglais que nous avons adapté pour le français, il a été possible de déterminer combien de phrases graphiques source et cible contient chaque paire de segments alignés. Cette analyse a permis par exemple de comparer le nombre de phrases graphiques contenues dans les paires de segments alignés par les deux logiciels d’alignement que nous avons utilisés et qui présentent un traitement très différent dans certains cas.
3.2 Catégorisation des paires de segments
La comparaison des résultats des deux logiciels d’alignement fait ressortir cinq types de paires de segments :
les paires à segment zéro (dont un des segments, source ou cible, ne contient aucun contenu textuel);
les paires à phrases symétriques simples (qui contiennent, de manière symétrique, une phrase graphique dans le segment source et une phrase graphique correspondante dans le segment cible);
les paires à phrases symétriques multiples (qui contiennent, de manière symétrique, deux phrases graphiques ou plus dans le segment source et le même nombre de phrases graphiques correspondantes dans le segment cible);
les paires à phrases asymétriques simples (qui contiennent deux phrases graphiques ou plus dans le segment source ou cible et seulement une phrase graphique en moins dans l’autre segment);
les paires à phrases asymétriques multiples (qui contiennent deux phrases graphiques ou plus dans le segment source ou cible et deux phrases graphiques en plus dans l’autre segment).
L’analyse de la performance des logiciels d’alignement à l’aide de cette typologie est reportée à une autre publication puisqu’elle vise l’évaluation de la qualité des alignements dans les textes parallèles, ce qui ne fait pas l’objet du présent article. Par contre, cette comparaison nous a permis de choisir l’alignement optimal des textes proposé par LF Aligner et d’établir la typologie des paires de segments qui s’est avérée utile dans la comparaison entre la TA et la PE sur le plan de la structure phrastique des textes. Le tableau qui suit illustre les différences formelles dans les deux alignements du corpus de 148 textes sources (TS) avec la TA d’abord puis avec les mêmes textes révisés en PE. L’alignement des deux corpus parallèles a été effectué avec le même logiciel LF Aligner.
Tableau 1
Différences entre TA et PE dans les types de paires de segments alignées
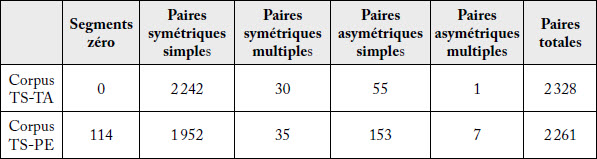
Les données du tableau 1 montrent que les paires de segments symétriques simples comptent respectivement pour 96 % de toutes les paires de segments en TA, tandis que ces paires de segments représentent 86 % des paires de segments en PE. La diminution du nombre de paires de segments symétriques simples en PE s’explique de différentes façons. On trouve tout d’abord un plus grand nombre de segments à paire zéro, ce qui s’expliquerait par l’ajout de phrases graphiques isolées à partir d’informations contextuelles non fournies dans le texte source ou à partir d’informations complémentaires fournies dans une même phrase graphique en anglais. Il s’agirait dans ce cas d’une réorganisation de l’information fournie dans une phrase du texte source ou de l’ajout de certaines informations fournies par le contexte ou ajoutées tout simplement à l’information du texte source. Ce phénomène se combine aussi à la subdivision d’une phrase graphique composée ou complexe (dont les propositions sont juxtaposées, coordonnées ou subordonnées) en anglais en de plus petites phrases graphiques en français. La diminution des paires de segments simples du corpus en PE s’explique aussi par l’augmentation du nombre de paires de segments symétriques multiples, mais surtout du nombre de phrases asymétriques simples et multiples. Ce dernier phénomène traduit le fait que des phrases simples qui ne contiennent qu’une seule phrase graphique en anglais sont alors fractionnées en français en plusieurs phrases graphiques. Ces particularités phrastiques des textes révisés en PE mettent en évidence le fait que la TA produit des textes dont la structure phrastique (et discursive voire argumentative) est généralement ou dans une plus forte proportion calquée sur le texte source. Nos données ne nous permettent pas de comparer directement la PE et la biotraduction sans recours à la TA, mais la plus grande symétrie phrastique et segmentale de la TA par rapport à la PE pourrait expliquer en partie la prépondérance des traductions littérales en PE par rapport à la biotraduction, ce que Carl et Schaeffer (2017) ont constaté dans leur étude.
Il importe de noter que ces données ne nous renseignent pas sur les caractéristiques de la PE par comparaison à la biotraduction sans recours à la TA. Sur le plan de la qualité des textes révisés en PE, ces données donnent à penser que l’intervention humaine en PE contribue pour une bonne part à une segmentation différente du texte qui se traduit par une augmentation des phrases graphiques sans qu’il soit possible dans l’état actuel de l’analyse de savoir s’il s’agit de l’ajout d’informations en français qui ne sont pas présentes en anglais ou d’une réorganisation de l’information du texte source, notamment par le fractionnement d’une phrase composée ou complexe en plusieurs phrases graphiques dans le texte cible.
Nous avons également procédé à une analyse lexicale simple par une approche « sac de mots » [bag of words] en comptant le nombre d’occurrences de chaque mot dans les deux sous-corpus en français (TA et PE) et en les comparant. Ces comparaisons ont servi à repérer quelques interventions humaines en PE. Les cas où nous avons observé des différences significatives entre la fréquence d’un même mot dans les corpus TA et PE sont présentés dans les résultats.
4. Résultats
Les méthodes que nous venons de décrire nous ont permis de repérer un grand nombre de différences entre les textes en anglais, leur traduction automatique et la version révisée en PE. Nous avons regroupé nos résultats en deux grandes catégories. Nous présentons d’abord des cas où la PE a permis d’améliorer la traduction produite automatiquement pour ensuite en présenter d’autres que la PE n’a pas permis d’améliorer.
4.1 Améliorations normatives
Les normes auxquelles nous faisons référence dans cette section renvoient aux règles décrites dans les deux éditions du Guide de rédaction (2006, 2023) de La Presse Canadienne[2]. Pour les exemples cités (sauf pour les fréquences absolues de mots-formes seuls), nous avons indiqué en gras dans le texte source, la TA et la révision en PE, les éléments qui font l’objet du contenu informationnel modifié et amélioré. Dans quelques cas, lorsqu’il s’agit de l’ajout d’une information par exemple, l’élément qui sert d’ancrage à la modification a également été mis en gras, comme dans le tableau 3 ci-dessous.
4.1.1 Les titres de civilité
Une première amélioration importante de type normatif consiste à ajouter les titres de civilité monsieur ou madame en français lorsqu’une personne est mentionnée dans un article. Le tableau qui suit décrit la fréquence absolue des abréviations Mme et M. dans la version traduite automatiquement des articles et dans la version révisée en PE de ces mêmes articles. Le pourcentage indiqué correspond à la proportion des titres que l’on trouve dans les versions révisées en PE.
Tableau 2
Amélioration normative repérée par la fréquence de mots-clés

Dans le tableau suivant, nous fournissons un exemple illustrant l’amélioration normative d’un titre de civilité tel que relevé dans notre corpus.
Tableau 3
Exemple d’amélioration normative tirée du corpus : ajout du titre de civilité

Nous constatons que ce type d’amélioration normative est pratiquement absent du traitement offert par la traduction automatique. Cette situation concernant les titres de civilité est d’autant plus révélatrice des limites du logiciel Ultrad que cet usage en français est fortement recommandé et, dans le contexte de La Presse Canadienne, prescrit par le Guide de rédaction (2006, p. 127). Peut-être pourrait-on pallier ce problème à l’aide de l’apprentissage automatique?
4.1.2 Les jours de la semaine
Un deuxième type d’amélioration normative et de renforcement de la cohérence textuelle apportés par la révision est l’intégration dans la version révisée des jours de la semaine qui ne semblent pas être aussi souvent utilisés dans les textes sources, comme en témoigne la fréquence en PE des différents jours de la semaine.
Tableau 4
Amélioration normative de la précision du jour
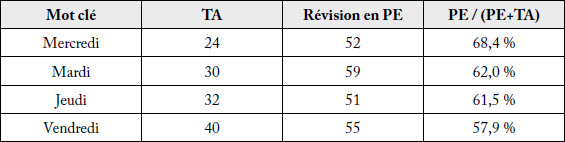
Tableau 5
Exemple d’amélioration normative tirée du corpus : précision du jour

Il s’agit ici d’une amélioration normative, mais relative aux normes journalistiques. Dans la presse quotidienne nord-américaine, on précise le jour de la semaine, plutôt que d’écrire aujourd’hui, hier ou demain, car un texte peut se retrouver dans un journal publié le lendemain de l’événement dont il est question (Associated Press, 2000).
Mais pourquoi alors les versions source (en anglais) contenaient-elles plus souvent today alors que dans les versions révisées en PE, on a senti le besoin de préciser le jour de la semaine dans plusieurs cas? Peut-être les versions anglaises soumises dans Ultrad étaient-elles des versions destinées à une publication rapide sur le web (d’où les mentions today), alors que les versions traduites en français étaient davantage destinées à être publiées dans des médias imprimés? Il faudrait interroger des artisans de La Presse Canadienne pour répondre à cette question (nous y reviendrons en conclusion).
4.1.3 Plusieurs verbes pour traduire to say
Un autre type d’amélioration normative que nous avons observé est l’utilisation plus grande des verbes introducteurs de discours (performatifs) autres que dire ou déclarer pour traduire le verbe to say. On pense par exemple aux verbes indiquer, soutenir, affirmer, prévenir, etc. Comme le montre le tableau 6, nous avons relevé un plus grand nombre de ces verbes dans les textes révisés en PE que dans les TA. Il est probable que cette situation se produise surtout dans le cas de complétives en complément d’objet du verbe to say, comme l’illustre l’exemple du tableau 7.
Tableau 6
Amélioration normative du verbe « dire »
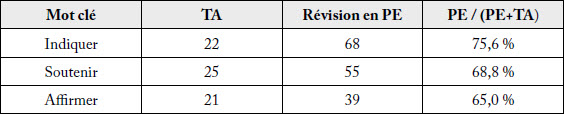
Tableau 7
Exemple d’amélioration normative tirée du corpus : le verbe « dire »

Cette différence découle de traditions journalistiques propres à chaque langue. En anglais, l’utilisation du verbe to say est privilégiée dans les textes journalistiques pour citer quelqu’un. C’est un verbe qui est considéré comme étant neutre (Boulanger et Gagnon, 2018, pp. 391 et 398), qui correspond davantage à la norme journalistique d’objectivité lorsqu’une personne est citée. En français, le Guide de rédaction de La Presse Canadienne considère que le verbe dire est « terne » et propose plus de 80 termes à utiliser comme synonymes, tels que soutenir, affirmer ou prétendre (La Presse Canadienne, 2006, p. 134).
Nous avons compté 802 occurrences du verbe to say (said, say, says, saying) dans les textes de notre corpus source. En revanche, voici les fréquences que nous avons observées pour quelques-unes des équivalences repérées dans les textes révisés en PE :
déclarer : 301 occurrences
dire : 151 occurrences
indiquer : 68 occurrences
soutenir : 55 occurrences
affirmer : 39 occurrences
4.1.4 Les emplois figuratifs unilingues
Certains emplois figuratifs ne sont possibles ou valorisés que dans une langue à l’exception de l’autre. C’est le cas de l’emploi du mot-forme anglais province qui peut servir à désigner une administration ou un gouvernement. Le plus grand nombre d’occurrences du mot province en TA (tableau 8) montre que ces emplois figuratifs en anglais ont le plus souvent été calqués par la TA et qu’ils ont été remplacés par une périphrase en PE comme le montre l’exemple du tableau 9.
Tableau 8
Amélioration normative des emplois figuratifs unilingues

Tableau 9
Exemple d’amélioration normative tirée du corpus : emploi figuratif[3]

4.1.5 La restructuration phrastique
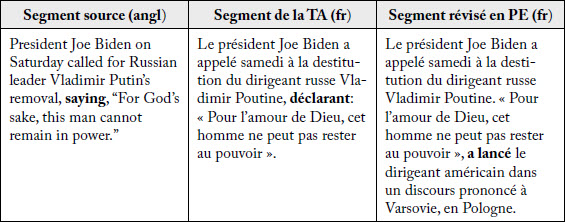
Le prochain exemple a été repéré par la sous-segmentation des paires de segments français-français qui fait état d’une asymétrie après qu’une longue phrase graphique ait été scindée en deux phrases graphiques au moment de la PE. Le tableau 10 fait aussi état d’une solution originale de traduction lorsque la complétive est associée à un gérondif qui consiste à déplacer la complétive en position sujet d’une deuxième et nouvelle phrase graphique.
Tableau 10
Exemple d’amélioration normative : restructuration phrastique
4.1.6 Les améliorations apportées aux traductions littérales
Deux méthodes formelles ont permis de repérer les améliorations de ce type entre les TA et les versions révisées en PE. Nous avons eu d’abord recours à l’analyse du ratio de la précision de l’information traduite (PIT), lequel peut être positif (lorsqu’il y a un ajout de mots-formes) ou négatif (lorsqu’il y une ou des omissions de mots-formes). Nous avons également évalué la distance euclidienne (DE) à trois dimensions (longueur en caractères, longueur en mots totaux et longueur en mots lexicaux).
4.1.6.1 Les formules consacrées qui nécessitent un étoffement
La méthode d’analyse fondée sur le ratio PIT positif a permis de repérer certaines formules figées synthétiques de l’anglais, comme celle qui figure dans le tableau 11, qui ont été traduites littéralement en TA et qui ont donné lieu à un étoffement nécessaire dans les textes révisés en PE.
Tableau 11
Exemple d’amélioration normative : formule figée
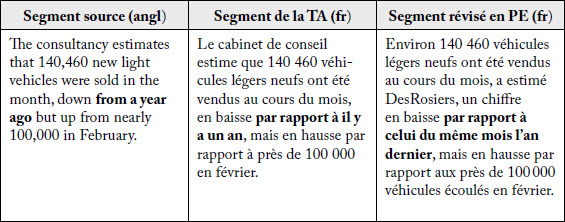
La paire de segments contient d’autres modifications apportées dans le texte révisé en PE, comme consultancy -> cabinet de conseil -> DesRosiers, mais ces modifications nous semblent neutres quant à l’amélioration ou à la détérioration de la TA. L’exemple trouvé ici se rapporte à l’expression en caractères gras qui désigne la façon en français de présenter la comparaison d’une donnée avec la même donnée établie l’année précédente. Même si d’autres formules sont envisageables en français, nous estimons surtout que la formulation proposée en TA n’est pas conforme aux tournures idiomatiques en français utilisées pour formuler cette information, notamment dans la langue spécialisée (par comparaison avec la langue générale de registre familier).
4.1.6.2 Non-reconnaissance d’une ellipse du passif en langue source
Le prochain exemple illustre une traduction littérale fautive en TA qui a pu être corrigée en PE. Contrairement à l’exemple précédent, il s’agit ici d’une erreur grave de la TA qui donne lieu à un contresens important. Le contresens tient au fait que si le texte source indique qu’un tribunal a rejeté la demande de madame Lich, la traduction automatique affirme plutôt que c’est madame Lich qui a refusé sa mise en liberté.
L’erreur de la TA vient du fait que l’auxiliaire du passif (was) n’a pas été répété dans la coordination des deux prédicats : was arrested and [was] denied. L’interprétation du deuxième verbe à la voix active correspond ici à une interprétation littérale (voix active) d’un verbe qui est en fait utilisé à la voix passive (avec l’auxiliaire was qui est implicite). Nous avons pu repérer cette erreur par la mesure de la DE entre le texte révisé en PE et la TA.
Tableau 12
Exemple d’amélioration normative : contresens par la non-reconnaissance d’une ellipse

4.1.6.3 Interférence atypique de la TA
La mesure de la DE nous a également permis de trouver d’autres améliorations de la TA grâce à la révision en PE. Le tableau 13 illustre un exemple où la TA propose une erreur grave de traduction, notamment par l’emploi d’un calque lexical. Contrairement à l’usage précédent qui découle d’une mauvaise analyse du texte source (sans prise en compte de l’auxiliaire implicite), l’erreur qui suit provient d’une interférence atypique d’un mot-forme en langue source qui est généralement traduit en langue cible par un mot-forme similaire.
Tableau 13
Exemple d’amélioration normative : calque lexical

Cette interférence de la TA s’explique par le fait que la plupart des acceptions et emplois du mot-forme mandate correspondent en français au mot-forme similaire (mandat), sauf pour l’acception qui est illustrée dans l’exemple et qui concerne l’obligation qui était faite de porter un masque pour lutter contre la COVID-19, appelée en anglais mask mandate. Ce type d’erreur rappelle que la TA ne prend absolument pas en compte les acceptions et le sens des unités linguistiques qu’elle traite comme des mots-formes auxquels se rattachent des probabilités d’occurrence dans certains contextes. Cet exemple montre bien les lacunes de la TA comme méthode probabiliste formelle qui ne prend pas en compte la nature de l’information communiquée. Malgré sa faible probabilité, cette information joue un rôle cardinal et incontournable dans la traduction de ce segment.
4.1.6.4 Améliorations dans la précision du vocabulaire
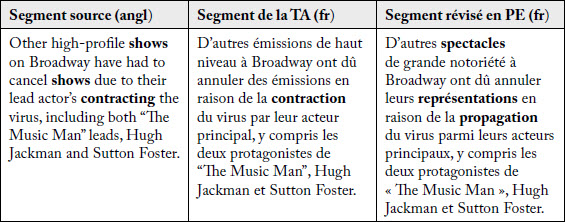
Les techniques de reformulation de la TA exploitent les formulations qui se retrouvent dans les textes en langue source. C’est en quelque sorte la démarche inverse de celle des traducteurs professionnels qui misent sur leur créativité et exploitent la richesse lexicale de la langue cible. L’exemple qui suit a été trouvé par hasard dans l’exploration de nos données puisque les méthodes que nous avons utilisées ne nous permettent pas de repérer les traductions non conventionnelles qui ne se manifestent pas par des décalages informationnels, comme les correspondances non conventionnelles. Ces choix peuvent être négatifs (entraîner une erreur de traduction), positifs (corriger une erreur de traduction) ou neutres (n’avoir aucune conséquence négative sur la traduction). Dans le passage que nous présentons au tableau 14, les choix de correspondances améliorent le texte en faisant usage d’un vocabulaire plus juste.
Tableau 14
Exemple d’amélioration normative : enrichissement du vocabulaire
4.2 Erreurs de la TA non corrigées en PE
Dans cette section des résultats, nous présentons maintenant quelques cas qui témoignent de révisions en PE qui n’ont pas permis de corriger une erreur produite par la TA. Nous avons également vérifié si les erreurs non corrigées en PE l’ont été aux étapes ultérieures, soit par un journaliste au pupitre de LPC, soit par les médias qui ont publié les articles de l’agence de presse. L’intérêt de cette dernière démarche est de vérifier l’influence que l’on peut attribuer à la TA dans la propagation des usages fautifs et des traductions erronées. Nous verrons que la situation à cet égard est plutôt préoccupante.
4.2.1 Propagation d’un calque fautif grave
Le prochain exemple a été relevé grâce à l’analyse fournie par Antidote. Il illustre l’effet d’amorçage [priming effect] mentionné précédemment.
Tableau 15
Calque fautif non corrigé en PE

La similitude de forme des mots sections en anglais et en français a probablement contribué à ce que cette erreur passe inaperçue en PE. L’erreur est à la fois grossière et grave parce qu’aucun rédacteur ne pourrait confondre la section d’un texte (subdivision formelle ou informelle) avec l’article d’une loi qui est une appellation univoque correspondant à section en anglais.
Nous avons découvert que le calque fautif a été propagé dans un article publié par différents médias, dont La Presse (25 mars 2022). Le passage complet se lit comme suit : « Le projet de loi C-11 met à jour des sections d’un projet de loi précédent, après que certains ont craint que le gouvernement réglemente les gens qui publient des vidéos sur YouTube » (Woolf, 2022). En date du 16 novembre 2022, l’article, erreur incluse, est toujours en ligne et a également été publié par au moins deux autres médias.
4.2.2 Propagation d’une hypercorrection
Le prochain exemple a été repéré grâce au ratio PIT positif de la version révisée en PE par comparaison avec la TA. Il illustre un cas où non seulement la révision en PE n’a pas amélioré la TA, mais y a également introduit une erreur qui consiste à ajouter un pléonasme. L’erreur, moins conséquente que la précédente, témoigne ici davantage d’une anomalie de l’intervention humaine sur la TA qui s’en était bien tirée.
Tableau 16
Hypercorrection de la révision en PE

Une vérification en ligne montre que le pléonasme a survécu dans la version publiée de l’article par Le Devoir le 25 mars (Larson, 2022). En date du 16 novembre 2022, l’erreur n’est toujours pas corrigée et a été reprise par au moins un autre média. La solution, ici, consiste bien évidemment à ne pas apporter la précision « avec les ailes ouvertes » qui fait partie du sens du terme envergure. On pourrait cependant avancer l’hypothèse qu’il s’agit d’un excès de zèle des journalistes de l’agence qui sont invités à rédiger des « textes faciles à lire et dénués de jargon » (La Presse Canadienne, 2023).
On peut cependant considérer que cet ajout est une forme de « traduction » typique du journalisme. La littérature montre en effet que lorsqu’ils parlent de traduction, les journalistes ne désignent pas uniquement la traduction interlinguale (de l’anglais vers le français, par exemple). Ils peuvent faire référence à des pratiques discursives propres à leur profession et qui consistent à simplifier ou vulgariser des textes scientifiques, des propos experts ou des rhétoriques alambiquées. Le travail journalistique s’apparente alors à celui des interprètes (Bassnett, 2005, p. 125) qui, lorsqu’ils reformulent un discours parlé dans une autre langue, vont parfois l’altérer, ajouter ou retrancher des éléments, afin de rester dans le registre de l’oral. Il s’agit de créer une nouvelle version intelligible pour un auditoire cible.
4.2.3 Métaphore employée dans un nouveau domaine cible
Le prochain exemple illustre les insuccès de la traduction d’une métaphore qui ne se traduit pas littéralement en français. La TA propose en premier lieu une traduction littérale qui crée un non-sens en français car l’interprétation métaphorique ne fonctionne pas avec la même unité lexicale centrale (chorus -> choeur) ni avec les mêmes éléments d’information périphériques (growing -> grandissant, complaints -> plaintes). La révision en PE réussit en partie en employant la bonne unité lexicale centrale (chorus -> concert), mais conserve les mêmes éléments périphériques (grandissant, plaintes) et ajoute même un pléonasme avec le complément « de voix ». Le tableau 17 présente les deux versions traduites de la métaphore.
Tableau 17
Propagation d’une formulation laborieuse en PE

Une vérification en ligne montre que la maladresse de traduction de la métaphore a survécu dans la version publiée de l’article par RDS (28 mars 2022) :
On assiste à un concert de voix grandissant de plaintes d’athlètes. Aviron Canada a annoncé le mois dernier qu’il prévoyait un examen indépendant de sa culture et de sa gouvernance de haute performance dans la foulée des préoccupations exprimées par les membres de la communauté de l’aviron à la fin de 2021 et au début de 2022.
Ewing, 2022
Au 16 novembre 2022, l’article contenant l’erreur est toujours en ligne et il a également été publié par au moins un autre média.
Plusieurs solutions de rechange sont pourtant envisageables pour bien traduire cette métaphore. On peut recourir à une traduction sémantique seulement, comme dans : « Les athlètes sont de plus en plus nombreux à se plaindre. » On peut aussi rendre la métaphore avec la bonne unité lexicale centrale, moyennant quelques aménagements de l’information périphérique, comme dans la proposition suivante : « On assiste à un concert de protestations [de plus en plus nombreuses] de la part des athlètes. » Dire que les protestations sont de plus en plus nombreuses peut cependant être considéré comme redondant puisque la métaphore du concert rend déjà l’idée d’un grand nombre.
4.2.4 Hallucination naturelle impropre en PE
Le prochain exemple illustre deux cas de non-sens qui sont attribuables à une hallucination naturelle qui comporte une formulation grammaticalement correcte, mais tout de même impropre à la langue cible, qui est une traduction mot à mot de l’anglais. La première concerne l’expression « puer le désespoir », qui s’avère impropre car elle n’est pas attestée dans les dictionnaires de langue générale, dans le logiciel de correction Antidote ou dans les dictionnaires spécialisés d’expressions idiomatiques. La deuxième concerne la collocation « appeler une course à la direction » dans le sens de demander qu’une course à la direction (d’un parti politique) ait lieu.
Comme les versions de la TA et de la révision en PE sont formellement identiques, il n’est pas possible de détecter les hallucinations impropres par une comparaison formelle des deux versions. La comparaison entre la traduction et le segment source a pu être relevée grâce à la distance euclidienne qui prend en compte le nombre de mots et de caractères, qui est calculé en fonction d’une estimation probabiliste de la longueur d’une traduction compte tenu de la longueur du segment source et de la longueur moyenne des segments cibles d’un texte traduit. Une autre méthode de repérage des hallucinations impropres en PE consiste à soumettre les textes révisés ou traduits automatiquement à l’analyse d’un correcteur orthographique qui pourra relever les emplois impropres des mots figurant dans la traduction littérale d’une expression anglaise. Cependant, cette méthode n’est pas infaillible puisque l’analyse fournie par le correcteur orthographique Antidote n’a détecté aucune des deux erreurs contenues dans l’exemple du tableau 18.
Tableau 18
Propagation de traductions littérales dénuées de sens

La maladresse de traduction a survécu dans la version publiée de l’article par L’actualité (24 mars 2022) : « M. Guthrie, le député d’Airdrie-Cochrane, dit que la décision “pue le désespoir” et qu’il est temps d’appeler une course à la direction immédiate et de trouver quelqu’un d’autre pour prendre la barre » (La Presse Canadienne, 2022). En date du 16 novembre 2022, la même publication est toujours en ligne et le même article a aussi été publié, avec ses deux erreurs, par au moins quatre autres médias.
4.2.5 Hallucination naturelle impropre en PE d’une expression idiomatique, malgré des modifications
Le prochain exemple contient une erreur de traduction automatique d’une expression idiomatique qui n’a pas été corrigée en révision de PE et ce, même si des modifications conséquentes et nombreuses ont été apportées par rapport à la TA. Ces modifications témoignent en fin de compte des efforts des intervenants sur le texte pour rendre l’expression acceptable. Les modifications ont pu être repérées grâce à la DE sur trois dimensions qui met en évidence les différences formelles entre la TA et la révision en PE. Cette dernière compte en effet plus de mots lexicaux, de mots totaux et de caractères que la TA. Le tableau 19 présente les modifications apportées en révision de PE qui ont porté sur différents éléments de l’expression sans toutefois corriger adéquatement la traduction littérale proposée par la TA.
Tableau 19
Propagation d’une traduction forgée d’une expression diomatique

Les cinq médias qui ont publié cette dépêche ont cependant publié une version différente qui se lit comme suit : « Environ 15 000 membres devaient se réunir à Red Deer le 9 avril pour se prononcer sur le leadership de M. Kenney, avec le lancement d’une course à la direction en l’absence d’un appui majoritaire au chef » (La Presse Canadienne, 2022).
C’est un rare cas de correction d’une erreur de traduction automatique qui n’avait pas été corrigée à l’étape de la post-édition. Comme la nouvelle formulation est identique dans les cinq médias repérés (Beauce média, L’actualité, La Nouvelle Union, Le Devoir et L’écho de La Tuque), nous soupçonnons que la correction n’a pas été effectuée par les médias eux-mêmes, mais par un journaliste de La Presse Canadienne à l’étape de la révision (voir figure 2), avant que l’article soit diffusé par l’agence ce jour-là. Il ne nous est cependant pas possible d’affirmer avec certitude que cela est bel et bien le cas, car nous n’avons pas eu accès à la quatrième version des textes de notre corpus.
Discussion et conclusion
Malgré les progrès de la TA, les erreurs d’Ultrad que nous avons présentées dans la section précédente et qui ont été corrigées témoignent du rôle crucial de la post-édition dans l’utilisation de la TA dans les publications professionnelles. Dans notre état de l’art de la post-édition, nous avons bien vu en effet que la TA brute était destinée à des publications d’une importance secondaire ou à diffusion restreinte, ce qui n’est certainement pas le cas des textes journalistiques. Il ne fait donc aucun doute que l’exploitation de la TA dans un contexte professionnel doit être pilotée par des professionnels.
D’un autre point de vue, les progrès récents et continus de la qualité des traductions produites par les systèmes de TA renforcent l’intérêt d’une intégration de la TA dans la fonction de traduction des entreprises. Les journalistes de La Presse Canadienne, tout comme les traducteurs professionnels, sont ainsi invités à profiter des avantages indéniables de la « traduction augmentée » : automatisation de certaines techniques de traduction (ne plus jamais devoir traduire plusieurs fois le même passage), exploitation de glossaires et de ressources terminologiques personnalisées, reformulations normalisées (fondées sur des probabilités), documentation en ligne, etc.
Même si la collaboration homme-machine est ainsi convoquée de manière à en tirer le meilleur parti, les exemples présentés à la deuxième partie de la section 4 qui attestent des erreurs qui n’ont pas été détectées en PE, et qui se sont même propagées dans d’autres médias qui ont réutilisé les dépêches de LPC, montrent bien que des améliorations à cette collaboration sont absolument nécessaires.
En regard de notre première hypothèse, les exemples trouvés dans le corpus illustrent les différents risques que présentent l’utilisation de la TA et de la post-édition et montrent que le recours à des professionnels pour la PE n’est pas garant d’une efficacité de la révision à toute épreuve. Vu sous cet angle, le recours à la TA soulève un enjeu important sur le plan de la qualité de l’information et de la qualité du français écrit (la langue cible de la TA).
Cependant, pour donner une réponse complète, il faudrait prolonger ce projet de recherche en interrogeant les personnes qui se servent d’Ultrad et en les observant lorsqu’elles ont recours à cet outil. Commencent-elles par ouvrir le texte source, en anglais, afin de connaître le sujet de l’article, à l’origine, ou plongent-elles immédiatement dans la TA pour en faire la post-édition? En d’autres termes : cèdent-elles à l’effet d’amorçage [priming effect] observé par Carl et Schaeffer (2017)? Compléter une analyse textuelle comme celle que nous avons effectuée avec une étude sur le terrain, de type ethnographique, est une excellente façon de donner plus de relief à la recherche (Davier et Van Doorslaer, 2018, p. 254).
Il faut en outre savoir, selon un entretien avec deux responsables de La Presse Canadienne, qu’Ultrad se trouve « à l’extérieur » du système de gestion du contenu (CMS) de l’agence. S’en servir demande donc un certain effort, une certaine rupture dans le processus de production des artisans de LPC. C’est ainsi qu’il serait pertinent de se demander dans quelle mesure l’outil est utilisé par les artisans de La Presse Canadienne. Y a-t-il encore des textes qui sont traduits sans avoir recours à Ultrad? Y a-t-il des journalistes qui copient-collent le texte de langue anglaise qu’ils doivent traduire dans un autre outil, comme DeepL ou ChatGPT, par exemple? Si oui, comment la qualité de la traduction de ces textes se compare-t-elle avec celle des textes qui passent par Ultrad? Par ailleurs, les journalistes qui se servent d’Ultrad traduisent-ils plus rapidement les textes que ceux qui s’en passent? Observer les journalistes de l’agence dans sa salle de rédaction de Montréal permettrait de répondre à ces questions.
En outre, plusieurs interventions répétitives en post-édition, notamment l’ajout des titres M. et Mme, nous ont fait sourciller. Ainsi, nous nous demandons si La Presse Canadienne devrait avoir recours à certaines formes d’apprentissage automatique afin qu’Ultrad puisse « apprendre » à placer ces titres devant des noms qui reviennent régulièrement dans leurs textes, comme ceux des personnalités politiques, culturelles ou sportives. La question soulevée par ces erreurs se rapporte aux progrès qu’il est raisonnable d’attendre des systèmes de TA relativement aux règles de rédaction et à la possibilité même de corriger des failles récurrentes décelées dans les traductions produites par ces systèmes. L’utilisation d’un modèle personnalisé grâce à un entraînement spécifique, composé de textes produits par The Canadian Press et La Presse Canadienne, pourrait permettre de corriger ces failles dans la mesure où il serait possible de procéder à un nouvel entraînement de ce modèle au besoin. En somme, cela soulève l’enjeu du paramétrage des règles et protocoles de rédaction de ces outils.
Les exemples d’erreurs non repérées en post-édition montrent aussi les limites de l’utilisation intégrale et statique de la TA en post-édition d’épreuve. Cette modalité d’utilisation de la TA met en évidence un paradoxe de l’outil de la TA selon lequel plus ses utilisateurs sont compétents en traduction, moins ils ont tendance à s’en servir intégralement et à privilégier une utilisation ponctuelle de celle-ci; tandis qu’à l’inverse, plus ses utilisateurs proviennent du grand public, comme les artisans de La Presse Canadienne, plus ils ont tendance à utiliser la TA de manière intégrale, au même titre qu’un intervenant dans la chaîne de production des textes, alors qu’il s’agirait plutôt de considérer ces services comme des outils d’aide à la traduction.
Notre étude pose enfin la question du rôle que pourraient jouer les professionnels de la traduction dans la production journalistique au Québec. Pourraient-ils être intégrés à des organisations qui, comme La Presse Canadienne, doivent traduire quotidiennement un grand volume de textes et pour qui la TA produit des résultats mitigés? La formation des journalistes au Québec, aussi, pourrait-elle intégrer un cours de traduction? Sinon, la traduction devrait-elle être abordée plus systématiquement, et par des professionnelles de la traduction, dans les cours d’écriture journalistique et de révision de textes? Martín Ruano indique que l’une ou l’autre de ces mesures pourrait notamment permettre de développer un usage plus critique des outils de traduction automatique (2021, p. 406). Chose certaine, notre étude montre que les activités de traduction nécessitent encore d’être pilotées par des humains qualifiés.
Parties annexes
Remerciements
Les auteurs remercient Geneviève Rossier, éditrice et directrice générale du Service français, et Marie-Ève Ouellette, gestionnaire du développement numérique, toutes deux de La Presse Canadienne au moment de réaliser cette étude (printemps 2022). Elles nous ont donné accès à Ultrad et aux articles qu’il contient, ce qui nous a permis de constituer le corpus de cette étude. Les auteurs souhaitent également remercier les évaluateurs anonymes d’une première version du présent article. Leurs commentaires et suggestions nous ont beaucoup aidé dans l’établissement de la version définitive.
Notes biographiques
Éric André Poirier, professeur de traduction et directeur de programmes au Département des langues modernes et de traduction de l’Université du Québec à Trois-Rivières, a exercé le métier de traducteur professionnel pendant près de 20 ans et il enseigne principalement la méthodologie de la traduction et la traduction financière de l’anglais au français. Il est. Il est l’auteur du manuel Initiation à la traduction professionnelle : Concepts clés publié en 2019. Ses travaux de recherche portent sur l’évaluation empirique des textes traduits et sur la science des données traductologiques et ses applications dans l’enseignement de la traduction.
Jean-Hugues Roy, professeur de journalisme à l’École des médias de l’Université du Québec à Montréal, a exercé le métier de journaliste pendant près de 25 ans. Il enseigne les méthodes de recherche et le journalisme de données, entre autres. Il s’intéresse aux effets de la technologie sur les pratiques journalistiques et ses recherches, qui mobilisent des méthodes informatiques, portent notamment sur la diffusion de l’information sur les plateformes socionumériques. Il est membre du conseil éditorial des Cahiers du journalisme (cahiersdujournalisme.org/).
Notes
-
[1]
Acronyme de Application Programming Interface qui se traduit par interface de programmation et qui désigne le mode de communication entre des services Web et des applications externes. « Traditionnelle » dans le sens où il n’y a pas d’apprentissage automatique dans l’utilisation de ce service.
-
[2]
La Presse Canadienne a publié une mise à jour de son Guide au moment où ce texte était en évaluation.
-
[3]
Dans le style soutenu, les normes typographiques veulent généralement que les unités monétaires soient écrites en toutes lettres. Les normes de La Presse Canadienne sont différentes et proposent d’utiliser le symbole $ s’il est question d’une somme.
Bibliographie
- Allen, Gene (2013). Making National News. Toronto, University of Toronto Press.
- Amozig-Buckszpan, Pascale (2014). « À qui profite l’outil…. ». Circuit, 122. Disponible à : https://www.circuitmagazine.org/dossier-122/a-qui-profite-l-outil [consulté le 26 octobre 2022].
- Associated Press (2000). AP Stylebook. New York, The Associated Press.
- Bassnett, Susan (2005). « Bringing the News Back Home : Strategies of Acculturation and Foreignisation ». Language and Intercultural Communication, 5, 2, pp. 120-130.
- Bays, Camille (2022). Post-édition interactive vs statique : une étude comparative de Lilt et COPeCO. Mémoire de maîtrise, Université de Genève. Inédit. Disponible à : https://archive-ouverte.unige.ch/unige:163114 [consulté le 16 octobre 2022].
- Bielsa, Esperança et Susan Bassnett (2009). Translation in Global News. Londres et New York, Routledge.
- Boulanger, Pier-Pascale et Chantal Gagnon (2018). « Financial Innovation and Institutional Voices in the Canadian Press : A Look at the Roaring 2000s ». International Journal of Business Communication, 55, 3, pp. 383-405.
- Boulanger, Pier-Pascale et Chantal Gagnon (2020). « The Translation of “Transparency” in the Canadian Press : An Inquiry into Symbolic Power ». Perspectives, 28, 3, pp. 339-356.
- Carl, Michael et Moritz Jonas Schaeffer (2017). « Why Translation Is Difficult : A Corpus-Based Study of Non-Literality in Post-Editing and From-Scratch Translation ». HERMES – Journal of Language and Communication in Business, 56, pp. 43-57.
- Chapais, Thomas (1905). Mélanges de polémique et d’études religieuses, politiques et littéraires. Québec, Imprimerie de la Compagnie de « L’Événement ».
- Conway, Kyle (2015). « Vagaries of News Translation on Canadian Broadcasting Corporation Television : Traces of History ». Meta, 59, 3, pp. 620-635.
- Davier, Lucile (2017). Les enjeux de la traduction dans les agences de presse. Villeneuve d’Ascq, Presses du Septentrion.
- Davier, Lucile et Luc van Doorslaer (2018). « Translation Without a Source Text : Methodological Issues in News Translation ». Across Languages and Cultures, 19, 2, pp. 241-257.
- De Balzac, Honoré (1840). « Chronique de la presse ». Revue parisienne. Disponible à : https://gallica.bnf.fr/ark:/12148/bpt6k1065498g [consulté le 26 juin 2023].
- De Bonville, Jean (1988). La presse québécoise de 1884 à 1914 : genèse d’un média de masse. Québec, Presses de l’Université Laval.
- Ewing, Lori (2022). Gymnastique : les gymnastes canadiens exigent une enquête pour des pratiques abusives. RDS.ca, Montréal, 28 mars. Disponible à : https://www.rds.ca/amateurs/gymnastique-les-gymnastes-canadiens-exigent-une-enquete-pour-des-pratiques-abusives-1.15568487 [consulté le 19 novembre 2022].
- Farkas, Andras (2019). LF Aligner. Disponible à : https://sourceforge.net/projects/aligner/ [consulté le 26 octobre 2022].
- Hu, Ke et Patrick Cadwell (2016). « A Comparative Study of Post-editing Guidelines ». European Association for Machine Translation Conferences/Workshops. https://aclanthology.org/W16-3420
- Jia, Yanfang et al. (2019). « How Does the Post-Editing of Neural Machine Translation Compare with From-Scratch Translation? A Product and Process Study ». The Journal of Specialised Translation, 31, pp. 60-86.
- Koponen, Maarit (2016). « Is Machine Translation Post-Editing Worth the Effort? A Survey of Research into Post-Editing and Effort ». The Journal of Specialised Translation, 25, pp. 131-146.
- La Presse Canadienne (2006). Guide de rédaction. 5e éd. Montréal, La Presse Canadienne.
- La Presse Canadienne (2022). « Deux députés d’arrière-ban exhortent le chef du PCU Jason Kenney à démissionner ». L’actualité, Montréal, 24 mars. Disponible à : https://lactualite.com/actualites/deux-deputes-darriere-ban-exhortent-le-chef-du-pcu-jason-kenney-a-demissionner/ [consulté le 19 novembre 2022].
- La Presse Canadienne (2023). Guide de rédaction. 6e éd. Montréal, La Presse Canadienne.
- Laget, Baptiste (2022). « Échange électronique avec Jean-Hugues Roy » , 13 mai.
- Larson, Christina (2022). « Une étude démystifie en partie le régime des chauves-souris vampires ». Le Devoir, Montréal, 25 mars. Disponible à : https://www.ledevoir.com/depeches/691392/une-etude-demystifie-en-partie-le-regime-des-chauves-souris-vampires [consulté le 19 novembre 2022].
- Lee, Katherine et al. (2018). « Hallucinations in Neural Machine Translation ». Conférence prononcée dans le cadre de la International Conference on Learning Representations. Disponible à : https://openreview.net/forum?id=SkxJ-309FQ [consulté le 26 octobre 2022].
- Martikainen, Hanna et Natalie Kübler (2016). « Ergonomie cognitive de la post-édition de traduction automatique : enjeux pour la qualité des traductions ». ILCEA, 27, pp. 1-17.
- Martín Ruano, M. Rosario (2021). « Towards Alternatives to Mechanistic Models of Translation in Contemporary Journalism ». Language and Intercultural Communication, 21, 3, pp. 395-410.
- Massardo, Isabella et al. (2016). MT Post-Editing Guidelines. Amsterdam, TAUS Signature Editions.
- Nelissen, Elisa et Jonathan Hendrickx (2023). « How Does a National, Multilingual News Agency Contribute to News Diversity? A Mixed-Methods Case Study ». Journalism. Disponible à : https://doi.org/10.1177/14648849231179784 [consulté le 16 août 2023].
- O’Brien, Sharon (2022). « How to Deal with Errors in Machine Translation Post-Editing », in Dorothy Kenny, dir., Machine Translation for Everyone: Empowering Users in the Age of Artificial Intelligence. Berlin, Language Science Press.
- Peraldi, Sandrine (2016). « De la traduction automatique brute à la post-édition professionnelle évoluée : le cas de la traduction financière ». Revue française de linguistique appliquée, XXI, 1, pp. 67-90.
- Poirier, Éric (2020). « Vers une évaluation empirique des textes traduits et de la qualité en traduction ». Journal of Data Mining & Digital Humanities, IV, pp. 1-20.
- Poirier, Éric et al. (2022). La TAN dans les cursus universitaires des membres de l’ACET: état des lieux. Montréal, Borealis. Disponible à : https://borealisdata.ca/dataset.xhtml?persistentId=doi:10.5683/SP3/WB7WLP [consulté le 22 octobre 2022].
- Poirier, Éric André (2023 [2019]). Initiation à la traduction professionnelle : Concepts clés. Montréal, Presses de l’Université de Montréal.
- Raunak, Vikas et al. (2021). « The Curious Case of Hallucinations in Neural Machine Translation ». Disponible à : arXiv preprint arXiv:2104.06683 [consulté le 2 août 2023].
- Robert, Anne-Marie (2010). « La post-édition : l’avenir incontournable du traducteur? ». Traduire, 222, pp. 137-144.
- Schumacher, Perrine (2020). « Post-édition et traduction humaine en contexte académique : une étude empirique ». Transletters. International Journal of Translation and Interpreting, 4, pp. 239-274.
- TAUS et CNGL (2010). Machine Translation Post-Editing Guidelines. TAUS the language data network. Disponible à : https://o.taus.net/insights/reports/taus-post-editing-guidelines [consulté le 2 août 2023].
- Terminotix (2022). Logiterm Pro : Logiciel complet d’aide à la traduction pour travailleurs autonomes. Disponible à : https://terminotix.com/index.asp?lang=fr [consulté le 2 août 2023].
- Valdeón, Roberto A. (2015). « Fifteen Years of Journalistic Translation Research and More ». Perspectives, 23, 4, pp. 634-662.
- Volkart, Lise et al. (2021). « Processus de post-édition chez les étudiants : influence des consignes ». Conférence prononcée dans le cadre du colloque interdisciplinaire Vers une robotique de traduire? (ROBOTRAD2021), Université de Genève, du 30 septembre au 1er octobre.
- Woolf, Marie (2022). « En promouvant le contenu canadien, YouTube craint que les créateurs perdent des revenus ». La Presse, Montréal, 25 mars. Disponible à : https://www.lapresse.ca/affaires/medias/2022-03-25/en-promouvant-le-contenu-canadien-youtube-craint-que-les-createurs-perdent-des-revenus.php [consulté le 19 novembre 2022].
- Zanettin, Federico (2021). News Media Translation. Cambridge, Cambridge University Press.
 10.7202/1028660ar
10.7202/1028660arListe des figures
Figure 1
Interface de l’outil Ultrad, telle qu’elle apparaissait en avril 2022
Figure 2
Cheminement d’un texte produit par La Presse Canadienne
Figure 3
Exemple d’un article révisé dans l’outil Ultrad
Figure 4
Extrait des métadonnées d’un texte de la base de données d’Ultrad montrant l’attribut state de valeur revised, indiquant que l’état de ce texte est « révisé »
Liste des tableaux
Tableau 1
Différences entre TA et PE dans les types de paires de segments alignées
Tableau 2
Amélioration normative repérée par la fréquence de mots-clés
Tableau 3
Exemple d’amélioration normative tirée du corpus : ajout du titre de civilité
Tableau 4
Amélioration normative de la précision du jour
Tableau 5
Exemple d’amélioration normative tirée du corpus : précision du jour
Tableau 6
Amélioration normative du verbe « dire »
Tableau 7
Exemple d’amélioration normative tirée du corpus : le verbe « dire »
Tableau 8
Amélioration normative des emplois figuratifs unilingues
Tableau 9
Exemple d’amélioration normative tirée du corpus : emploi figuratif[3]
Tableau 10
Exemple d’amélioration normative : restructuration phrastique
Tableau 11
Exemple d’amélioration normative : formule figée
Tableau 12
Exemple d’amélioration normative : contresens par la non-reconnaissance d’une ellipse
Tableau 13
Exemple d’amélioration normative : calque lexical
Tableau 14
Exemple d’amélioration normative : enrichissement du vocabulaire
Tableau 15
Calque fautif non corrigé en PE
Tableau 16
Hypercorrection de la révision en PE
Tableau 17
Propagation d’une formulation laborieuse en PE
Tableau 18
Propagation de traductions littérales dénuées de sens
Tableau 19
Propagation d’une traduction forgée d’une expression diomatique