Abstracts
Résumé
Cette recherche s’articule autour du modèle structural de lecture, dans lequel la structure syntaxique de la phrase guide l’intégration des unités sémantiques. Notre objectif est d’étudier l’impact sur les résultats en lecture d’un entraînement spécifiquement conçu pour renforcer les habiletés syntaxiques. Nous présentons les modalités didactiques du plan expérimental à travers trois exercices mis en place pour travailler la syntaxe dans l’activité de lecture, avec des élèves du secondaire. Les résultats ne montrent aucune incidence de l’entraînement sur la vitesse de lecture. En revanche, on observe une amélioration de la compréhension chez les sujets qui ont participé à l’entraînement.
Mots clés:
- compréhension en lecture,
- vitesse,
- syntaxe,
- modèle structural de lecture,
- secondaire
Summary
The study is based on the structural reading model, in which syntactic structure guides the integration of semantic units into a sentence during the reading process. Our objective is to study the impact of a training session designed to reinforce syntactic skills on reading results. We present the didactic methodology of the experimental plan through three exercises for developing syntactic skills during reading activities with secondary school students. The results do not reveal any impact of the training on reading speed. However, we observe an increase in comprehension among the students participating in the training.
Key words:
- reading comprehension,
- speed,
- syntax,
- structural reading model,
- secondary level
Resumen
Esta investigación se basa en el modelo estructural de lectura en el cual la estructura sintáctica de la frase guía la integración de las unidades semánticas. Nuestro objetivo es estudiar el impacto sobre los resultados en lectura de un entrenamiento específicamente concebido para reforzar las habilidades sintácticas. Presentamos las modalidades didácticas del plan experimental a través de tres ejercicios elaborados para trabajar la sintaxis en la actividad de lectura, con alumnos de la secundaria. Los resultados no muestran ninguna incidencia del entrenamiento sobre la velocidad de lectura. En cambio, se observa una mejoría de la comprensión en sujetos que participaron al entrenamiento.
Palabras claves:
- comprensión de lectura,
- velocidad,
- sintaxis,
- modelo estructural de lectura,
- secundaria
Article body
1. Introduction
Depuis une vingtaine d’années, un débat scientifique parcourt la presse spécialisée autour des processus susceptibles d’expliquer une des observations les plus robustes de la psychologie expérimentale : l’effet de la lettre omise (Corcoran, 1966). Quand on présente un texte à un lecteur en lui demandant de détecter toutes les occurrences d’une lettre, on observe un certain nombre d’oublis, non pas répartis au hasard, mais beaucoup plus importants dans les mots fonctionnels ayant une fréquence élevée que dans les mots lexicaux plus rares.
Deux grands modèles explicatifs ont été progressivement élaborés pour expliquer cette répartition non aléatoire des oublis de lettres.
Le premier d’entre eux, initié très largement par Healy (1976), repose prioritairement sur l’observation de taux d’oubli plus importants dans les mots fréquents, comme par exemple, and, the ou for. Plusieurs auteurs (Drewnowsky et Healy, 1977 ; Healy, 1976, 1980 ; Healy et Drewnowsky, 1983) postulent que le processus de lecture d’un texte met en jeu, de manière simultanée, différents domaines d’analyse, portant sur les formes des lettres ainsi que sur les lettres, les syllabes, les mots et des groupes de mots. Ils supposent que, dès que le lecteur identifie une unité par un de ces domaines, les processus de tous les niveaux parallèles sont stoppés même s’ils n’ont pas été menés jusqu’à leur terme. L’oubli de lettres s’explique, selon Healy (1994), par la reconnaissance rapide (globale) d’un mot fréquent, ce qui stoppe les niveaux parallèles d’analyse comme la reconnaissance des lettres, et provoque donc un plus fort taux d’oubli.
Le second modèle explicatif a été élaboré à partir des expériences menées depuis 1991 par Koriat (Greenberg et Koriat, 1991 ; Greenberg, Koriat, et Shapiro, 1992 ; Koriat et Greenberg, 1991, 1993, 1994, 1996 ; Koriat, Greenberg, et Goldshmid, 1991). En notant que les mots les plus fréquents étaient souvent ceux qui jouaient un rôle bien particulier dans la syntaxe, ils ont supposé que c’était ce rôle syntaxique qui induisait l’effet de la lettre omise. Un grand nombre d’expérimentations leur a permis de consolider ce point de vue. Ces observations se sont d’abord concentrées sur certaines caractéristiques de l’hébreu écrit, permettant de distinguer les effets de fréquence et de rôle (fonctionnel par rapport à sémantique) des mots ou morphèmes étudiés. Tous ces éléments ont conduit Koriat et Greenberg (1991, 1996) à proposer un modèle concurrent à celui de Healy (1994). Ce modèle, dit de lecture structurale, postule que cet effet de la lettre omise est dû au rôle syntaxique du mot dans une phrase et non à sa fréquence. Le point central de cette hypothèse suggère la prégnance de l’organisation structurale. Ainsi, selon Koriat et Greenberg (1996), en lisant, le lecteur tente d’établir un cadre structural de la phrase (ou du groupe de mots) et d’en intégrer le sens, même si, en fait, c’est la structure qui mène la danse (lead the way). D’une certaine manière, le lecteur tente d’élaborer un squelette du groupe de mots ou de la phrase qu’il parcourt, sur la base d’une analyse rapide et superficielle, éventuellement à l’aide de la vision parafovéale. Notons que la fovéa est une petite zone de la rétine où la vision est la plus nette ; elle couvre environ 1° (degré) du champ visuel. La dégradation de la netteté se fait progressivement, au rythme d’environ 50 % de dégradation par degré d’écartement : on est alors dans la zone parafovéale. Or, l’information se prend à l’aide de deux zones : fovéale et parafovéale. Ces deux zones ont des caractéristiques différentes : la zone fovéale, réduite dans sa taille, apporte des informations très détaillées, alors que la zone parafovéale semble performante dans l’exploitation de zones floues, plus en rapport avec les formes globales de mots sans distinction précise des lettres. Leur interaction dans les processus de lecture fait l’objet de nombreuses recherches.
Ce squelette du groupe de mots ou de la phrase que le lecteur tente d’élaborer accueille les informations sémantiques de la phrase. Les mots fonctionnels comme les prépositions, articles, conjonctions sont donc les premiers indices traités par le lecteur pour établir ce cadre ; ils sont ensuite rejetés à l’arrière-plan, alors que l’intégration du sens se poursuit sur le cadre structural pré-construit. Signalons, à ce propos, que cette construction de l’organisation syntaxique semble contredire certaines descriptions classiques de l’acte lexique. En particulier, l’idée, reprise par Lecocq, Casalis, Leuwers et Watteau (1996), d’une analyse syntaxique on line, dépendante d’une identification des mots par un accès au lexique mental, et séquentielle, dans la mesure où elle s’effectue pas à pas au fur et à mesure de l’identification des mots, devrait ici être questionnée dans la mesure où le modèle structural prévoit que la formation de la structure syntaxique de la phrase (ou d’un groupe de mots) est édifiée a priori à l’aide, en partie, d’une prise d’information parafovéale (Koriat et Greenberg, 1991 ; Saint-Aubin et Klein, 2001). Dans ces conditions, la lecture experte ne relèverait donc pas d’abord d’une activité séquentielle qui implique l’identification des mots les uns après les autres afin de leur attribuer un rôle (syntaxique ou non), mais serait pilotée par le repérage d’unités syntaxiques qui organisent le contenu sémantique de la phrase parcourue.
Ce point de vue explique particulièrement bien le taux plus élevé d’oublis dans les morphèmes fonctionnels, puisque, traités de prime abord, ils ne sont plus cognitivement actifs au moment où les sujets de l’expérience biffent la lettre indiquée. La détection des lettres se passerait après l’analyse morphologique des mots, ce qui diffère du point de vue de Healy (1994), qui considère que les différents traitements ont lieu en parallèle jusqu’au succès de l’un d’entre eux. La construction en ligne du cadre structural de la phrase est soumise à des hypothèses générées par le contexte aussi bien qu’à des clés (au sens musical) syntaxiques présentes dans le texte. Ces indices dirigent l’attention du lecteur vers les éléments les plus signifiants. En conséquence, ces clés sont repérées très précocement dans la lecture de la phrase mais, une fois utilisées pour établir une structure, elles sont reléguées à l’arrière-plan et cèdent la place aux unités sémantiquement riches. Avec Koriat et Greenberg (1996) qui supposent finalement que l’extraction de ce cadre structural se fait à partir de l’interaction de trois grands facteurs (syntaxique, sémantique et visuel), il faut souligner que les informations d’ordre parafovéale sont essentielles à la mise en place de ce modèle (Saint-Aubin et Klein, 2001).
Finalement, l’année 2004 a vu la parution d’un article commun où ces différents auteurs incorporent certains aspects de leurs modèles respectifs dans un modèle plus étendu capable d’intégrer l’ensemble des différentes observations : le modèle GO (guidance – organisation) précise que les mots, très fréquents, organisant la syntaxe, sont repérés, dans la mesure du possible, en vision parafovéale par les processus décrits à l’origine par Healy (1976, 1994) et son modèle d’unités concurrentes. Ils servent ensuite de pivots autour desquels va s’organiser la syntaxe de la phrase. Cette organisation syntaxique guidera ensuite l’attention vers les mots lexicaux et permettra l’analyse et l’intégration des informations sémantiques de la phrase (Greenberg, Healy, Koriat et Kreiner, 2004).
Notre expérimentation se situe dans la mouvance du modèle de lecture structurale où l’extraction de la structure syntaxique de la phrase est essentielle au processus de lecture de texte. La question à laquelle nous souhaitons répondre vise à savoir si un entraînement systématique à la construction précoce de la structure syntaxique améliore les performances en lecture. Doit-on considérer que cette habileté syntaxique est une conséquence de l’acte lexique et se développe donc à notre insu, seulement par nos lectures et des rencontres variées avec l’écrit ? Un entraînement ciblé permettrait-il de développer cette capacité structurante ? En quoi ce développement améliorerait-il la performance de lecture, tant sur le plan de la vitesse que sur celui de la compréhension ? En effet, l’intérêt du pédagogue est bien dans l’aide à la maîtrise de lecture, et non dans l’augmentation d’un différentiel d’oubli de lettres entre mots à rôle syntaxique et mots à rôle sémantique. Dans cette optique, l’objectif principal de cet article est d’étudier l’impact d’un entraînement spécifiquement conçu pour renforcer les habiletés syntaxiques sur les résultats en lecture. Notre hypothèse est de considérer qu’un tel entraînement améliore les performances des lecteurs, dans leur compréhension comme dans leur vitesse.
2. Description de la procédure expérimentale
Afin d’explorer les possibles effets d’un entraînement de cette habileté à construire des squelettes syntaxiques, nous avons préparé un programme reposant sur trois exercices, chacun exerçant respectivement un aspect particulier de ce qui pourrait être à l’oeuvre lors de cette construction. Chacun de ces exercices tente d’aider le lecteur à prendre conscience du statut particulier des mots à rôle syntaxique, à mieux les reconnaître en situation et à les percevoir plus rapidement en travaillant avec les informations qui les entourent. Les trois exercices sont intégrés dans un logiciel que nous avons développé spécialement dans le cadre de cette recherche. Ils sont conçus pour des élèves du secondaire qui les utilisent au cours de séances de travail d’une durée de 20 minutes pendant un trimestre. Précisons que l’expérimentation s’est déroulée en classe de cinquième de collège français (2e année du secondaire en France, où le primaire dure cinq ans).
2.1 Premier exercice : la reconnaissance des mots à rôle syntaxique
Le premier exercice (voir l’annexe) que nous proposons travaille la reconnaissance des mots à rôle syntaxique ainsi que la vitesse à laquelle elle a lieu. Le travail est divisé en trois parties qui arrivent dans un ordre aléatoire. Pour chacune des parties, il s’agit de cliquer le plus rapidement possible, à l’intérieur d’un texte, sur tous les mots appartenant à une même catégorie grammaticale. Les trois catégories successives sont :
les prépositions ;
les déterminants ;
les complémenteurs, qui comprennent les différentes conjonctions et les pronoms relatifs. Ces complémenteurs ont la capacité de lier deux syntagmes flexionnels ; ce seront donc également des mots fonctionnels comme les conjonctions ou les pronoms relatifs (Pollock, 1997). Pour des raisons de facilité lexicale, nous avons appelé cette catégorie, avec les élèves, la catégorie des relationnels.
Trente textes, issus, pour la plupart, d’ouvrages de littérature jeunesse, ont été choisis et ont servi à fabriquer les trente séries de ce premier type d’exercice. Une présentation du texte est toujours limitée dans le temps pour obliger les élèves à travailler rapidement. Pour une présentation, le calcul du temps maximum d’affichage du texte (minimum = 174 s ; maximum = 384 s ; moyenne = 291 s) est calculé par la formule [Temps = (0,4 * N) + (0,4 * Q)] où N représente le nombre de mots du texte et Q le nombre de mots à trouver dans la catégorie concernée.
Le logiciel propose à l’élève un texte et la catégorie de mots sur laquelle il devra cliquer. Un clic sur un mot n’appartenant pas à la catégorie demandée ne provoque aucune action ; le mot se colorie en bleu s’il appartient à la bonne catégorie. Si l’élève trouve toutes les unités à chercher, on passe à la deuxième présentation du même texte, avec une nouvelle demande d’une autre catégorie à repérer. Si le répondant n’arrive pas à terminer dans le temps maximum de la présentation, le logiciel présente la correction de la recherche en cours. Les unités oubliées apparaissent alors successivement sur l’écran en clignotant pendant quatre secondes. Si un élève est performant, il va finir les trois présentations avant la fin des cinq minutes ; on lui présentera alors le texte suivant. Au bout de cinq minutes, l’exercice se termine pour pouvoir passer au deuxième type d’exercices (voir l’annexe). Si, au moment de l’interruption, l’élève est encore dans la première présentation du texte, le logiciel lui proposera à nouveau ce même texte lors de son prochain passage, sinon il travaillera ensuite sur un nouveau texte.
2.2 Deuxième exercice : l’exercice à trous
Classiquement, l’exercice à trous a essentiellement pour but de stimuler la réflexion métalinguistique de l’apprenant (Besse et Porquier, 1991 ; Mutta, 2003), dans la mesure où il permet des […] activités de contrôle conscient et de planification intentionnelle par le sujet de ses propres procédures de traitement linguistique (Gombert, 1990, p. 27). Cet exercice propose un texte dans son entier. L’objectif est ici de retrouver un mot du texte en s’aidant d’informations contextuelles, aussi bien d’ordre sémantique que syntaxique ou syntagmatique. La réalisation de l’exercice suppose donc une réflexion métalinguistique. Toujours pour les mêmes raisons que celles présentées précédemment, la catégorie grammaticale des mots supprimés est soit un article, soit une préposition, soit un relationnel (notons que, pour cet exercice, on fait explicitement appel à la dénomination exacte de la catégorie des mots ; on aura trois possibilités pour cette dernière catégorie : les conjonctions de subordination, les conjonctions de coordination ou les pronoms relatifs).
Ici encore, trente autres textes, issus, pour la plupart, de la littérature jeunesse ont été sélectionnés comme supports de travail. Pour chacun des textes, dix mots ont été choisis pour être retrouvés dans l’exercice. Pour chaque trou, l’élève a un temps maximum de recherche d’une minute.
Un texte est proposé à un élève. L’ensemble du texte est visible, et le premier trou s’affiche par un rectangle rouge d’une largeur exactement égale au mot qu’il masque. Comme les mots ont été choisis pour être des têtes de syntagme (Pollock, 1997), on attire l’attention sur ce syntagme en l’écrivant d’une manière dégradée. Un chronomètre égrène le temps restant pour trouver le mot. L’élève peut, à tout moment, demander à voir les aides qui y sont associées et qui sont présentées toujours dans le même ordre : on affiche d’abord en bleu et dans sa police d’origine le syntagme introduit par le mot à trouver, puis on indique à l’élève la catégorie grammaticale du mot recherché, avant de lui présenter le mot à trouver avec une apparence visuellement dégradée. Si l’élève n’a pas trouvé la bonne réponse au bout d’une minute, le logiciel lui présente le mot qu’il recherchait et passe au mot suivant.
2.3 Troisième exercice : les structures syntaxiques en vision parafovéale
Le troisième exercice proposé aux élèves diffère sensiblement des deux premiers. Différents travaux expérimentaux ont précisé le rôle des informations de type parafovéal dans l’établissement des cadres structuraux (Greenberg et collab., 2004 ; Saint-Aubin et Klein, 2001). En conséquence, ce que nous essayons d’exercer ici, c’est le traitement des informations perçues par la vision parafovéale et leur meilleure intégration dans un processus de construction syntagmatique en cherchant à travailler sur la qualité de la perception dans un temps le plus court possible.
Cent cinquante-cinq groupes de trois phrases ont été construits d’une manière méthodique. Les trois phrases d’un triplet utilisent un matériel lexical le plus proche possible. Elles démarrent de manière absolument identique et se différencient au bout d’un nombre variable de mots suivant les triplets. Une des phrases est la phrase cible, celle présentée en flash à l’écran (voir le déroulement ci-dessous). Une deuxième se différencie de la première et le mot qui initie cette différenciation est de même catégorie grammaticale dans les deux phrases, respectant par là la contrainte d’une même structure syntaxique. Une troisième, enfin, se différencie des deux premières à partir d’un mot qui est non seulement de catégorie différente mais, plus radicalement, de fonction différente : par exemple, si le mot qui initie la variation a un rôle syntaxique dans les deux premières phrases, il aura un rôle sémantique dans la troisième. Mais, dans la mesure du possible, le mot initiant la différenciation entre les phrases (qui est de catégorie différente de celui de la phrase cible) a une apparence visuelle proche ou, du moins, des éléments visuels peuvent se ressembler (Figure 1).
Figure 1
Exemple de triplet : le mot initiant la différenciation a un rôle syntaxique
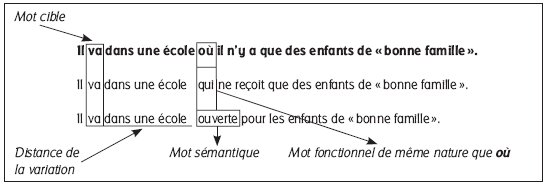
La figure 2 synthétise l’ensemble des modalités de passation de cet exercice. Un point apparaît sur l’écran pendant 500 millisecondes, point qu’il est demandé à l’élève de fixer. La première phrase apparaît et reste affichée pendant 500 ms. Le logiciel demande alors à l’élève de choisir parmi quatre mots lequel était sous le point qu’il devait fixer (Figure 2, étape 1).
Figure 2
Déroulement de l’exercice triplet
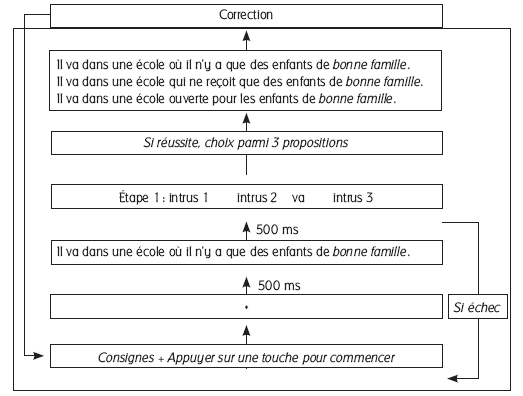
Si l’élève se trompe, on passe au triplet suivant. S’il réussit, on lui présente alors simultanément les trois phrases du triplet et on lui demande de choisir celle préalablement présentée en flash. L’ordre d’affichage des phrases du triplet est aléatoire. Une correction est systématiquement apportée, portant mention du type de réponse donnée, permettant une dernière conscientisation des structures travaillées.
2.4 Visées des trois exercices
Les deux premiers exercices proposés dans le cadre de cet entraînement reposent sur l’idée qu’une meilleure connaissance des mots organisant la syntaxe de la phrase et qu’une plus grande familiarité avec leur fonctionnement favorisent, par la suite, la mise en place des cadres structuraux grâce à une identification plus facile des têtes de syntagmes. Notons que le propos est bien de faire porter l’attention, de manière explicite, sur ces unités structurantes.
Par exemple, le deuxième exercice proposé (exercices à trous) isole visuellement la structure que commande le mot fonctionnel à trouver. Non seulement la taille de la structure est mise en valeur dès le départ, mais la première aide consiste précisément à l’expliciter, à la rendre visible par son changement de couleur. L’élève est ainsi amené à voir l’intégration de chacun des mots fonctionnels qu’il doit trouver dans la structure qu’il introduit.
Le premier exercice (les clics), lui, nécessite un traitement plus automatique. Il suffit simplement de chercher, de manière rapide, la succession des mots introduisant une structure identique. Il s’agit de conduire l’élève à focaliser son attention sur ces mots peu nombreux par rapport à la totalité des mots du français, mais très nombreux et indispensables dans chacun des textes écrits. Par ce premier exercice qui nommait a priori la catégorie recherchée dans les textes, nous voulions travailler sur la catégorie en elle-même, non de manière abstraite, mais par le repérage rapide des unités la constituant dans leur environnement naturel. Force a bien été de constater que, pour les élèves de secondaire engagés dans ces exercices, l’identification de tous ces mots à rôle syntaxique n’est pas aussi automatique qu’on pouvait l’espérer. Le premier exercice nécessite également une prise en compte des informations parafovéales. En effet, par sa dynamique qui oblige à se déplacer rapidement dans un texte tout en gardant une discrimination fine, il est probable que les informations périphériques sont utiles pour percevoir l’ensemble des mots demandés.
Dans leur ensemble, ces deux premiers exercices travaillent sur la conscientisation de l’existence des unités syntagmatiques, par un repérage explicite et le plus exhaustif possible des mots les initiant. Ainsi, il s’agit de bien maîtriser le fonctionnement de ces unités linguistiques grâce à une analyse en amont comme en aval du contexte.
En revanche, le troisième exercice a une ambition différente. Cette fois, il ne s’agit plus de travailler sur l’explicite, mais de devenir plus performant dans des activités dont les modalités restent le plus souvent hors de portée de la conscience. Grâce aux travaux de l’équipe de Dehaene (1998), nous savons maintenant que des éléments dont nous n’avons pas conscience influent non seulement sur nos réponses ou nos sensations, mais également sur nos processus cognitifs (Dehaene et collab., 1998). Un des objectifs de cet exercice est de faire en sorte que l’élève, à l’instar d’un lecteur expert, prenne conscience de ces éléments qui, dans la vision parafovéale, influent sur le processus cognitif de construction des cadres syntaxiques.
Ici, il s’agit de vérifier l’hypothèse que l’exercice systématique de ce processus participe à l’amélioration de la compréhension ou de la vitesse en lecture. Les travaux sur l’apprentissage perceptif (Ahissar et Hochstein, 2004 ; Ahissar, Hochstein, Walsh et Kulikowski, 1998 ; Poggio, Fahle et Edelman, 1992) nous ont montré qu’il est tout à fait possible de conduire un entraînement pour améliorer l’habileté perceptive, à condition de positionner les éléments à percevoir dans un système qui les intègre et où on les cherche, d’où l’importance de la correction donnée juste après l’essai. C’est pourquoi la fenêtre qui apparaît présente le lieu de la séparation des trois phrases proposées et l’ensemble des structures qui en découlent. L’élève peut ainsi mettre en relation le mot qui initiait le syntagme avec la structure construite. Il nous semble que cet exercice va dans le sens de ce que Goldstone (1998) propose, à savoir porter attention aux formes discriminantes, séparer psychologiquement des stimuli jusqu’alors indistinguables, et détecter une construction unique sous des configurations multiples (Goldstone, 1998).
Deux points principaux ressortent de l’observation du fonctionnement des experts perceptifs (Abernethy, 1991 ; Chase et Simon, 1973 ; Gobet et Simon, 1998 ; Greenfield, deWinstanley, Kilpatruck et Kaye, 1994 ; Nougier, Ripoll et Stein, 1989) et du développement de leur maîtrise : d’une part, leur capacité à organiser les stimuli par la présence d’un cadre conceptuel et, d’autre part, l’accélération et l’accroissement de cette maîtrise par la prise de conscience des informations décisives qui organisent la tâche à effectuer (Biederman et Shiffrar, 1987). Pour Léontiev (Léontiev, 1984, p. 302), […] la prise de conscience d’un contenu est déterminée par la place qu’il occupe dans la structure de l’activité, ce qui implique que ce qui est accommodé dans la conscience d’un élève faisant une activité, c’est […] ce qui entre dans l’activité en tant qu’objet d’une action qu’il réalise, en tant que but immédiat de cette action.
Pour cet auteur, ne pas amener un contenu ou un processus à un niveau conscient empêche l’amélioration de ses propres procédures de traitement, tout en le maintenant dans un état figé et rigide, donc incapable de participer de manière efficace à une action nouvelle ou inconnue. C’est seulement lorsque le processus ou le contenu est susceptible d’être actualisé de manière consciente (le processus devient éventuellement conscient), qu’il acquiert cette efficacité lorsqu’il est requis (alors à un niveau inconscient) dans une autre tâche. C’est, modestement, ce que nous voulons tenter ; ainsi, afin d’améliorer l’habileté des élèves dans l’établissement de l’architecture d’une phrase (processus inconscient dans une situation de lecture normale), nous exposons à leur conscience les éléments qui autorisent ce fonctionnement. Lors de l’exercice, nous hissons le processus du stade inconscient à celui d’éventuellement conscient pour pouvoir travailler sur ces mots fonctionnels repérés en vision parafovéale, de façon à permettre à l’apprenti, en situation réelle, de tirer le meilleur parti de ce qui sera redevenu inconscient mais non ignoré.
En outre, la disposition des salles impliquant le partage d’un ordinateur entre deux élèves, l’un commandant la machine, l’autre le regardant travailler et inversement, nous a encouragé à faire de ces exercices des supports de discussions métalinguistiques entre élèves. En accord avec les professeurs, nous avons sollicité les élèves pour qu’ils échangent entre eux pendant le déroulement des exercices. Nous avons transformé cette contrainte matérielle en une chance didactique, dans la mesure où cette coopération métalinguistique pouvait favoriser la prise de conscience, par les élèves, de l’importance de la syntaxe dans leur habileté de lecture. Cependant, cet aspect nous invitera à la prudence quant à l’interprétation des résultats.
2.5 Descriptif des séances de travail
Les élèves du groupe expérimental ont consacré une séance par semaine, prise à l’intérieur de l’horaire normal de français, à l’entraînement décrit plus haut. Pour les élèves du groupe témoin, ce temps était consacré aux activités habituelles du cours de français en cinquième. Les équipements informatiques standards des collèges français pour les classes de lettres obligent les élèves à n’utiliser un ordinateur que pendant la moitié de l’horaire total. En effet, on compte approximativement moitié moins d’ordinateurs que d’élèves par classe. En conséquence, deux élèves se trouvaient devant un poste de travail, alors qu’un seul en tenait les commandes : nous avons profité de cette situation pour favoriser les échanges métalinguistiques autour des exercices, au prix d’un bruit parfois un peu plus élevé qu’à l’accoutumée.
L’entraînement s’est déroulé pendant tout le deuxième trimestre de l’année scolaire, soit un maximum de 10 séances pour chaque élève, 200 minutes d’entraînement personnel et 200 minutes d’accompagnement d’un camarade (toujours le même) sur les exercices.
Le volume horaire de l’enseignement de français était donc inchangé et restait identique entre groupe témoin et groupe expérimental. Ce qui était introduit dans le groupe expérimental, c’est une substitution d’activités représentant 25 % de l’horaire d’un trimestre. Pendant le temps consacré à l’entraînement, les élèves du groupe témoin poursuivaient leurs activités habituelles de français : lecture, grammaire, travail sur ordinateur, travail en groupe, etc.
3. Méthode
Nous avons mis en place un plan quasi-expérimental classique, comprenant pré-test et post-test individuels avec constitution d’un groupe recevant le traitement expérimental et d’un groupe contrôle.
3.1 Population
Deux groupes d’élèves de cinquième (deuxième année du collège français, élèves âgés d’environ 12-13 ans) ont été constitués : un groupe expérimental qui travaille avec le logiciel décrit précédemment et un groupe témoin. Deux classes de cinquième ont participé à l’expérimentation. Le groupe témoin a été constitué par tirage au sort parmi les élèves d’une troisième classe. À partir de cette souche témoin, l’appariement sujet par sujet a été fait pour le groupe expérimental en respectant les variables suivantes :
la note globale obtenue à l’épreuve de français de l’évaluation nationale (classe de 5e du secondaire français) (± 5 %) ;
l’âge de l’élève ;
la note globale obtenue à l’épreuve de mathématiques de l’évaluation nationale de 5e n’a servi qu’à départager les élèves respectant les deux premiers critères.
Pour chaque élève du groupe témoin, on retrouve, dans le groupe expérimental, trois élèves qui lui correspondent au regard de l’âge, de la performance en français et éventuellement de la performance en mathématiques lors des épreuves de l’évaluation cinquième. Au total, nous avons constitué une population de 67 élèves, 16 appartenant au groupe témoin et 51 au groupe expérimental. Cette population (Tableau 1) se partage en 41 garçons et 26 filles, avec une différence non significative entre les groupes (Chi² de Pearson : 0,015 ; dl = 1 ; p < 0,91). L’âge, calculé par le nombre de jours écoulés entre la première évaluation et la date de naissance ne présente pas de différence significative entre les deux groupes (ANOVA âge x groupe : F(1, 64) = 0,27 ; p < 0,61).
Tableau 1
Répartition du sexe, de l’âge, de la note en mathématiques et de la note en français suivant les deux groupes, à l’évaluation nationale de 5e (ces deux notes sont exprimées sur 100)
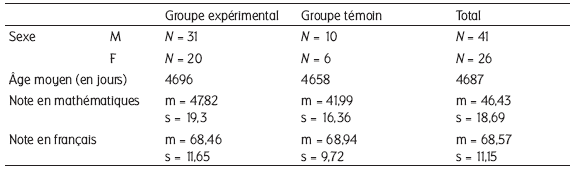
Note : m signifie moyenne et s signifie écart-type.
La note en mathématiques ne les différencie pas plus (ANOVA Mathématiques x Groupe : F(1, 65) = 1,19 ; p < 0,29). Enfin, une analyse de variance ANOVA entre les groupes constitués à partir de la note de français à l’évaluation cinquième corrobore leur homogénéité (F(1, 65) = 0,022 ; p < 0, 89).
3.2 Épreuves d’évaluation de la lecture
Les épreuves d’évaluation du niveau de lecture des élèves ont été passées, pour le pré-test, durant la dernière semaine du premier trimestre de l’année scolaire et pendant la dernière semaine du deuxième trimestre pour le post-test, donc à trois mois d’intervalle. Pour évaluer la compréhension et la vitesse, nous nous sommes servi de deux épreuves différentes, déjà utilisées dans de précédents travaux (Foucambert, 2000, 2003).
La première épreuve tente d’évaluer la performance dans une forme de lecture très courante, sans doute à l’oeuvre dans plus de 60 % des situations ordinaires, celle où il s’agit de prendre connaissance simplement de l’explicite d’un texte, ce qui correspond à ce que l’ex‑Direction des Études et Prospective du ministère de l’Éducation nationale décrivait comme une compétence approfondie (Vugalic, 1996). L’épreuve se déroule sur un ordinateur dont la résolution d’écran est contrôlée (800 x 600). Chacun des neuf textes s’affiche, et le sujet indique, en pressant une touche du clavier, qu’il en a terminé la lecture et répond alors à une question. Les textes, diversifiés entre presse, documentaire et fiction, sont d’une taille similaire d’environ 20 lignes et de même niveau de difficulté, aussi bien pour le lexique employé que pour la complexité des phrases. Les questions portent sur des points explicitement présents dans le texte et sont systématiquement introduites par la formule Le texte parle, suivie de trois propositions parmi lesquelles une seule est correcte.
Une seconde épreuve fait travailler sur l’implicite du texte, ce que l’ex-Direction des Études et Prospective dénommait compétence remarquable et dont sembleraient disposer moins de 20 % des élèves entrant au secondaire. Il s’agit de franchir ce que dit le texte pour atteindre l’intention de l’auteur et apprécier les moyens qu’il emploie. Un texte de fiction de Rodari (1988), long de 1 526 mots, est présenté sur un écran d’ordinateur ; ce texte permet de nombreuses interprétations, en partie par l’usage que fait l’auteur de différents épilogues. Le sujet peut parcourir à sa guise les neuf pages écran pendant le temps qu’il estime nécessaire. Ensuite, il répond à 12 questions par un système de questions à choix multiples (QCM), le texte n’étant alors plus consultable. Un barème a été établi par un groupe de juges formés d’enseignants et de bibliothécaires pour décrire des degrés d’interprétation et ne pas s’enfermer dans le tout ou rien. Ainsi, toutes les réponses proposées sont possibles, mais certaines témoignent d’un niveau plus approfondi de compréhension qui est calculé en s’efforçant de correspondre aux conceptions de la lecture experte d’un texte littéraire par des élèves de premier cycle de l’enseignement secondaire (Rouxel, 1996). Ce score de compréhension peut s’échelonner de 15 à 94 points.
Pour éviter la répétition des mêmes épreuves aux pré-test et post-test, nous avons opté pour un passage contrebalancé. Ainsi, la moitié de l’effectif de chacun des groupes passera, au pré-test, l’épreuve sur les textes courts pendant que l’autre moitié passera l’autre épreuve (Tableau 2). Pour les épreuves de post-tests, les élèves passent l’épreuve qu’ils n’ont pas faite au pré-test.
Tableau 2
Répartition des individus en fonction des épreuves. Les effectifs figurent entre parenthèses

Nous avons veillé à ce que la répartition des épreuves soit indépendante des résultats en français à l’évaluation de 5e. Une analyse de variance cherchant à expliquer la note de français par le groupe, et le type d’épreuve donne une interaction non significative entre ces deux variables (effet courant : F(1, 63) = 0,12 ; p < 0,73), montrant par là que le groupe témoin et le groupe expérimental possèdent une répartition homogène suivant le niveau de départ des élèves entre les deux épreuves.
Pour décider si l’entraînement a eu des effets sur la compréhension ou sur la vitesse en lecture des élèves, il faut que nous ayons une notation homogène entre les deux épreuves dont la nature est légèrement différente. Aussi, afin de neutraliser la notation et la différence des épreuves, nous avons standardisé séparément leurs résultats pour pouvoir raisonner, toutes choses étant égalespar ailleurs, quant à la dispersion de chaque distribution. Cette transformation permet de positionner chaque individu par rapport à une grille de performance commune aux résultats des deux épreuves ; il devient possible d’effectuer des comparaisons de résultats d’un même individu dans des situations (épreuves, moments, etc.) différentes. La valeur ainsi obtenue représente, pour chaque élève, la qualité de la compréhension ou de la vitesse au pré-test ; l’élève ayant la valeur brute la plus forte obtiendra, après transformation, le score z positif le plus élevé parmi ceux qui ont été obtenus, alors que l’élève ayant la valeur la plus faible obtiendra le score z négatif le plus élevé. La même opération est répétée pour le post-test, ce qui nous permet d’obtenir deux variables comparables représentant la compréhension, dans un jeu à somme nulle. La transformation des résultats en score z, le contre-balancement des épreuves au sein des pré-tests et des post-tests et l’introduction du type d’épreuve passé au pré-test comme covariant, permettent de mener de manière fiable les traitements statistiques ci-dessous.
4. Résultats
4.1 Effets de l’entraînement sur la compréhension en lecture
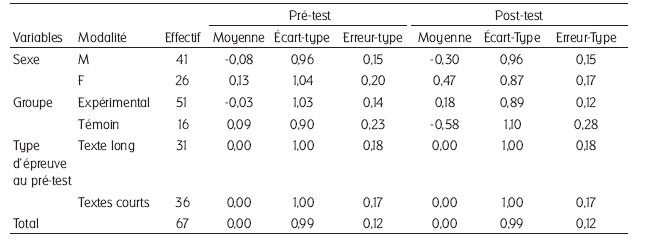
Une analyse de variance (ANOVA) avec mesures répétées va servir à comparer les deux groupes de pratiques au regard de leurs progrès en compréhension (les moyennes, écarts-types et erreurs-types des différentes variables sont présentés dans le tableau 4). Pour contrôler la variation intergroupe, nous introduisons dans le modèle, comme facteurs intergroupes, la note globale obtenue à l’évaluation de 5e en français et les variables sexe et type d’épreuve au pré-test. Notons que le facteur de mesures répétées est construit avec les scores z de compréhension au pré-test et au post-test.
Les résultats présentés dans le tableau 3 montrent que :
pour les facteurs intergroupes, seul le niveau de départ, illustré par la note en français, est significatif. Que ce soit au pré-test ou au post-test, meilleurs sont les élèves à l’évaluation de 5e, plus forte sera leur compréhension ;
pour la variation intra-sujet, et c’est ce qui nous intéresse en priorité dans cette analyse, les élèves du groupe expérimental montrent une progression significative de la qualité de leur compréhension comparativement à ceux du groupe témoin (Figure 3), toutes choses étant égales par ailleurs.
Tableau 3
Résultats de l’ANOVA à mesures répétées expliquant les compréhensions
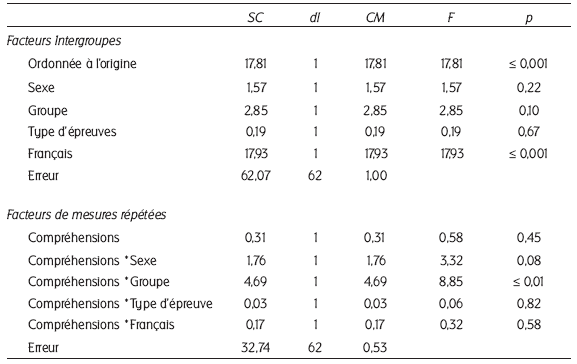
Note : SC = somme des carrés ; dl = degré de liberté ; CM = carré moyen ; F = statistique du F ; p = niveau de signification.
Figure 3
Score z des compréhensions au pré-test et au post-test du groupe témoin et du groupe expérimental
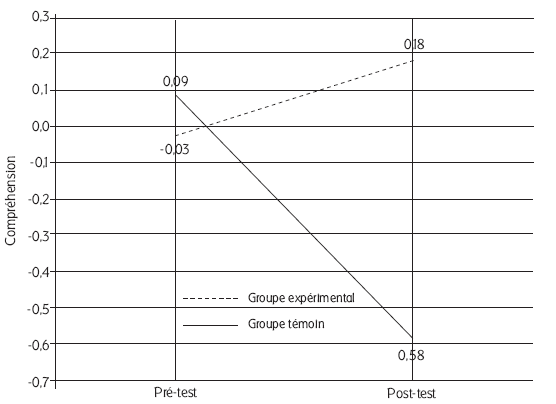
Tableau 4
Résultats de la compréhension en lecture au pré-test et au post-test
La figure 3 exprime les scores standardisés de compréhension des deux groupes au pré-test et au post-test. L’unité de mesure des scores z est l’écart-type lui-même. Ainsi, si au pré-test, les moyennes des deux groupes restent très proches (ce qui montre une répartition homogène des individus des deux groupes au sein de l’ensemble de la population), on observe en revanche que la différence s’établit significativement au post-test avec une chute des élèves du groupe témoin vers les rangs les plus faibles de l’ensemble de la population totale, alors que les élèves du groupe expérimental se placent globalement dans la partie haute de la distribution, ce qui n’était pas le cas au pré-test.
4.2 Effets de l’entraînement sur la vitesse de lecture
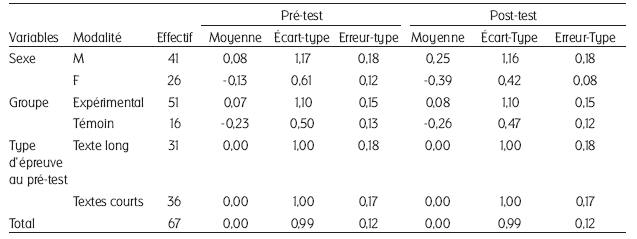
La même analyse de variance avec mesures répétées est reconduite en prenant cette fois comme facteur de mesures répétées les résultats au pré-test et au post-test en vitesse de lecture (les moyennes, écarts-types et erreurs-types des différentes variables sont présentés dans le tableau 5). Les résultats montrent que seul le sexe est significatif (p < 0,02), mais uniquement comme source de variation intergroupe, et non dans son interaction avec la mesure répétée (p < 0,9). Les résultats montrent que les élèves masculins ont une vitesse de lecture supérieure à celle des filles, que ce soit au pré-test ou au post-test (trois mois plus tard). En revanche, on n’observe aucune variation de la vitesse chez les élèves qui se sont entraînés pendant un trimestre.
Tableau 5
Vitesse en lecture au pré-test et au post-test
5. Discussion
Les résultats confirment une partie de nos attentes. Pour commencer, il est intéressant de constater que la vitesse de lecture n’est absolument pas sensible à l’entraînement. En revanche, on observe une amélioration manifeste de la compréhension des élèves ayant participé aux séquences expérimentales. Ainsi, nous enregistrons dans ces résultats qu’un entraînement explicitement conçu pour améliorer la connaissance et la reconnaissance des structures syntaxiques conduit les élèves à progresser de manière tout à fait significative dans la compréhension en lecture. Les résultats montrent que cette habileté est susceptible de s’entraîner par l’intermédiaire d’au moins deux facteurs :
un travail explicite sur la classe des mots fonctionnels qui cristallisent la structure de la phrase (Pinker, 1999). Une structure des phrases mieux maîtrisée, c’est un système où les informations lexicales vont mieux s’intégrer, pour le plus grand profit de la compréhension ;
un travail explicite sur une meilleure perception parafovéale de ces mots fonctionnels, avec une plus grande attention apportée aux formes discriminantes, amenant à une habileté dans la détection d’une construction unique représentant une configuration complexe, en lieu et place d’une multitude de parties séparées (Goldstone, 1998).
Nous devons cependant rester prudents devant les résultats obtenus. En effet, nous semblons tenir pour acquis que l’entraînement que nous avons conçu pour aider l’élève à bien anticiper l’organisation syntaxique dans laquelle va être traitée l’information sémantique, exerce effectivement ce pour quoi il a été conçu. On peut le penser, mais les progrès observés en lecture n’en établissent pas la preuve indiscutable. Il s’est évidemment passé quelque chose qui a un effet positif significatif sur la qualité de lecture des élèves. Ce qui s’est passé, comparé à ce qui ne s’est pas passé pour le groupe témoin, n’est pas lié à un temps supplémentaire consacré à l’horaire de français. Les autres différences entre groupe témoin et expérimental que nous n’avons pas contrôlées strictement sont liées au recours à l’informatique et à un accroissement probable des échanges métalinguistiques entre les élèves. En effet, il est commun d’observer des effets de cette coopération sur les améliorations de résultats des élèves, et pas simplement dans le domaine de la lecture (Greenwood et collab., 1984 ; Greenwood et collab., 1987 ; Pigott, Fantuzzo et Clement, 1986). Aussi, on pourrait imputer le gain de compréhension que nous observons dans ces expérimentations au seul effet de la coopération avec des pairs. Il aurait fallu que le groupe témoin pratique, lui aussi, pendant une heure par semaine, dans le cadre de l’horaire de français, une activité demandant une coopération entre les élèves. Le protocole expérimental en aurait été alourdi et aurait sans doute dépassé le cadre de cette recherche, où nous voulions étudier l’impact d’un entraînement spécifiquement conçu pour améliorer, d’une part, la conscience (au sens de Léontiev, 1984) que peuvent avoir les élèves des unités qui permettent au lecteur d’établir le cadre structural de la phrase qu’il parcourt et, d’autre part, l’habileté perceptive (par la vision parafovéale) de ces mêmes unités. Mentionnons une autre limite de cette expérimentation : la non prise en compte du type d’apprentissage de la grammaire et des connaissances grammaticales des élèves.
Cette analyse se voulait avant tout exploratoire, dans le sens où il ne semble pas qu’un tel entraînement, centré explicitement sur ces aspects, ait jamais été entrepris. Les discussions métalinguistiques entre les élèves, que nous avons encouragées, portaient soit sur le rapport entre les unités observées (les mots fonctionnels) et les structures construites, soit sur les structures perçues de manière parafovéale. Bien entendu, dans la réalité d’une classe, il est possible que toutes les discussions n’aient pas eu ce seul sujet… Cependant, nous en avons observé de nombreuses.
En participant à la prise de conscience des mécanismes de construction de l’architecture syntaxique, ces discussions sont partie prenante de l’apprentissage et ne sauraient en être retirées, même pour fabriquer un protocole expérimental plus convenable. Dans ce cas, il reste à espérer que le groupe témoin a, lui aussi, consacré du temps à des échanges métalinguistiques entre les élèves à propos d’expériences linguistiques ; on peut légitimement présumer d’une telle situation dans la mesure où elle est encouragée dans la formation des enseignants.
On peut cependant retenir de cette étude qu’un gain significatif de compréhension est obtenu quand les élèves du secondaire consacrent spécifiquement un temps d’entraînement à la connaissance et à la reconnaissance automatique des structures syntaxiques qui organisent les constructions des phrases.
Notons également que la nature même des apprentissages requis par une partie de cet entraînement nous oblige à prendre en compte les conclusions des recherches spécifiquement centrées sur l’apprentissage perceptif. Elles insistent sur le rôle primordial joué par le modèle dans lequel s’intègrent les perceptions visuelles : ce qu’on entraîne, c’est la détection systémique des modalités visuelles qui invalident ou corroborent les traitements cognitifs engagés (Ahissar et Hochstein, 2004). Dans ces conditions, c’est à partir de l’exposition à la conscience (Léontiev, 1984) des deux éléments qui permettent la construction de l’architecture de la phrase (la vision parafovéale et l’utilisation des mots fonctionnels), et qui restent, dans une pratique normale de lecture, inaccessibles à la conscience, que peut se mettre en place ce système nécessaire à une perception efficace. Nous voudrions rappeler ici que le travail que peuvent faire les élèves sur leurs perceptions parafovéales nécessite le recours obligatoire à l’ordinateur. C’est une occasion d’utiliser dans les classes cet outil de manière spécifique, dans une perspective qu’il est le seul à offrir. Trop souvent, les logiciels éducatifs sont de simples numérisations d’un contenu qui existe – ou pourrait exister – sans eux ; c’est ici l’occasion de créer des outils informatiques qui entraînent les élèves d’une manière spécifique, non redondante avec d’autres médias.
6. Conclusion
Pour terminer, nous voudrions revenir sur le sort habituellement fait à la syntaxe dans les pratiques scolaires. Sans doute parce qu’elle est considérée comme une sous-partie de la grammaire, spécialisée dans l’ordonnancement des mots en syntagmes et en phrases, la syntaxe est, le plus souvent, abordée lors d’activités grammaticales prescriptives ou stylistiques qui sont, avant tout, des moments de description de l’écrit ou de correction des phrases produites par les élèves. Dans ces conditions, le but immédiat de l’action didactique est de travailler la production de l’écrit plutôt que sa réception. Pourtant, les derniers programmes de français, pour l’école primaire comme pour le secondaire, commencent à accorder une place à l’étude de la syntaxe dans une optique de réception, mais l’apparente complexité de la théorie syntaxique sert parfois de repoussoir aux professeurs de français. Cependant, les résultats issus du présent travail confirment l’utilité de compléter l’approche traditionnelle de la syntaxe – en insistant sur sa fonction organisatrice de la réception de l’écrit – afin de participer à l’élévation du niveau de lecture des élèves.
Appendices
Annexe
Premier exercice : la reconnaissance des mots à rôle syntaxique
Les élèves doivent cliquer successivement sur trois catégories de mots, toujours les mêmes dans l’ensemble des textes. L’ordre de cliquage change suivant les textes et est donné par chaque chapeau présenté au-dessus du texte. On y trouvera également le nombre de mots par catégorie et le temps alloué. Les relationnels sont écrits en gras dans le texte (seulement dans cette présentation, pas sur les écrans d’ordinateur), les prépositions en italique et les déterminants en souligné. Pour une présentation, le calcul du temps maximum d’affichage du texte (minimum = 174 s ; maximum = 384 s ; m = 291 s) est calculé par la formule [Temps = (0,4 * N) + (0,4 * Q)] où N représente le nombre de mots du texte et Q le nombre de mots à trouver dans la catégorie concernée.

Deuxième type d’exercice : les exercices à trous
Les relationnels sont écrits en gras dans le texte (seulement dans cette présentation, pas sur les écrans d’ordinateur), les prépositions en italique et les déterminants en souligné. Pour cet exercice il est fait explicitement appel à la dénomination exacte de la catégorie des mots : on aura trois possibilités pour cette dernière catégorie, les conjonctions de subordination, les conjonctions de coordination ou les pronoms relatifs. Pour chaque trou, l’élève a un temps maximum de recherche d’une minute.

Références
- Abernethy, B. (1991). Visual search strategies and decision-making in sport. Special issue : information processing and decision making in sport. International journal of sport psychology, 22, 189-210.
- Ahissar, M. et Hochstein, S. (2004). The reverse hierarchy theory of visual perceptual learning. TRENDS in cognitive sciences,8(10), 457-464.
- Ahissar, M., Hochstein, S., Walsh, V. et Kulikowski, J. (1998). Perceptual learning. Dans V. Walsh et J. Kulikowski (Dir.) : Perceptual constancies : why things look as they do. Cambridge, United Kingdom : Cambridge University Press.
- Besse, H. et Porquier, R. (1991). Grammaire et didactique des langues. Paris, France : Didier.
- Biederman, I. et Shiffrar, M. S. (1987). Sexing day-old chicks : a case study and expert systems analysis of a difficult perceptual-learning task. Journal of experimental psychology : learning, memory and cognition, 13(4), 640-645.
- Chase, W. G. et Simon, H. A. (1973). Perception in chess. Cognitive psychology, 4, 55-81.
- Corcoran, D. W. (1966). An acoustic factor in letter cancellation. Nature, 210, 658.
- Dehaene, S., Naccache, L., Le Clec’H, G., Koechlin, E., Mueller, M., Dehaene-Lambertz, G., Van de Moortele, P. F. et Le Bihan, D. (1998). Imaging unconscious semantic priming. Nature, 395(6702), 597-600.
- Drewnowsky, A. et Healy, A. F. (1977). Detection errors on the and and : evidence for reading units larger than word. Memory and cognition, 5(6), 636-647.
- Foucambert, D. (2000). Les effets d’une année d’entraînement à la lecture avec un logiciel éducatif : résultats en classe de sixième de collège. Revue française de pédagogie, 133, 63-73.
- Foucambert, D. (2003). Syntaxe, vision parafovéale et processus de lecture. Contribution du modèle structural à la pédagogie. Thèse de doctorat inédite, Université Grenoble 2, Grenoble.
- Gobet, F. et Simon, H. A. (1998). Expert chess memory : revisiting the chunking hypothesis. Memory, 6(3), 225-255.
- Goldstone, R. L. (1998). Perceptual learning. Annual review of psychology, 49(1), 585-612.
- Gombert, J. E. (1990). Le développement métalinguistique. Paris, France : Presses universitaires de France.
- Greenberg, S. N., Healy, A. F., Koriat, A. et Kreiner, H. (2004). The GO model : a reconsideration of the role of structural units in guiding and organizing text on line. Psychonomic bulletin and review, 11(3), 428-433.
- Greenberg, S. N. et Koriat, A. (1991). The missing-letter effect for common function word depends on their linguistic function in the phrase. Journal of experimental psychology : learning, memory and cognition, 17(6), 1051-1061.
- Greenberg, S. N., Koriat, A. et Shapiro, A. (1992). The effects of syntactic structure on letter detection in adjacent function words. Memory and cognition, 20(6), 663-670.
- Greenfield, P. M., Dewinstanley, P., Kilpatruck, H. et Kaye, D. (1994). Action video games and informal education : effects on strategies for dividing visual attention. Journal of applied developmental psychology, 15(1), 105-123.
- Greenwood, C. R., Dinwiddie, G., Bailey, V., Carta, J. J., Dorsey, D., Kohler, F. W., Nelson, C., Rotholz, D. et Schulte, D. (1987). Field replication of classwide peer tutoring. Journal of applied behavior analysis, 20(2), 151-160.
- Greenwood, C. R., Dinwiddie, G., Terry, B., Wade, L., Stanley, S. O., Thibadeau, S. et Delquadri, J. C. (1984). Teacher- versus peer-mediated instruction : an ecobehavioral analysis of achievement outcomes. Journal of applied behavior analysis, 17(4), 521-538.
- Healy, A. F. (1976). Detection errors on the word “the” : evidence for reading units larger than letters. Journal of experimental psychology : human perception and performance, 2(2), 235-242.
- Healy, A. F. (1980). Proofreading errors on the word “the” : new evidence on reading units. Journal of experimental psychology : human perception and performance, 6(1), 45-57.
- Healy, A. F. (1994). Letter detection : a window to unitization and other cognitive processes in reading texts. Psychonomic bulletin and review, 1(3), 333-344.
- Healy, A. F. et Drewnowsky, A. (1983). Investigating the boundaries of reading units : letter detection in mispelled words. Journal of experimental psychology : human perception and performance, 9(3), 413-426.
- Koriat, A. et Greenberg, S. N. (1991). Syntactic control of letter detection : evidence from English and Hebrew nonwords. Journal of experimental psychology : learning, memory and cognition, 17(6), 1035-1050.
- Koriat, A. et Greenberg, S. N. (1993). Prominence of leading functors in function morpheme sequences as evidenced by letter detection. Journal of experimental psychology : learning, memory and cognition, 19(1), 34-59.
- Koriat, A. et Greenberg, S. N. (1994). The extraction of phrase structure during reading : evidence from letter detection errors. Psychonomic bulletin and review, 1(3), 345-356.
- Koriat, A. et Greenberg, S. N. (1996). The enhancement effect in letter detection : further evidence for the structural model of reading. Journal of experimental psychology : learning, memory and cognition, 22(5), 1184-1195.
- Koriat, A., Greenberg, S. N. et Goldshmid, Y. (1991). The missing-letter effect in Hebrew : word frequency or word function ? Journal of experimental psychology : learning, memory and cognition, 17(1), 66-80.
- Lecocq, P., Casalis, S., Leuwers, C. et Watteau, N. (1996). Apprentissage de la lecture et compréhension d’énoncés. Villeneuve d’Ascq, France : Presses universitaires du Septentrion.
- Léontiev, A. (1984). Activité, conscience, personnalité. Moscou, Russie : Éditions du Progrès.
- Mutta, M. (2003). Activité (méta)langagière chez des locuteurs non natifs lors de l’exécution d’un test de closure. Marges linguistiques, 5(2), 147-167.
- Nougier, V., Ripoll, H. et Stein, J. F. (1989). Orienting of attention with highly skilled athletes. International journal of sport psychology, 20, 205-223.
- Pigott, H. E., Fantuzzo, J. W. et Clement, P. W. (1986). The effects of reciprocal peer tutoring and group contingencies on the academic performance of elementary school children. Journal of applied behavior analysis, 19(1), 93-98.
- Pinker, S. (1999). L’instinct du langage. Paris, France : Éditions Odile Jacob.
- Poggio, T., Fahle, M. et Edelman, S. (1992). Fast perceptual learning in visual hyperacuity. Science, 256(5059), 1018-1021.
- Pollock, J. Y. (1997). Langage et cognition. Paris, France : Presses universitaires de France.
- Rodari, G. (1988). Histoires à la courte paille. Paris, France : Hachette-Jeunesse.
- Rouxel, A. (1996) Enseigner la lecture littéraire. Rennes, France : Presses universitaires de Rennes.Saint-Aubin, J. et Klein, R. M. (2001). Influence of parafoveal processing on the missing-letter effect. Journal of experimental psychology : human perception and performance, 27(2), 318-334.
- Vugalic, S. (1996). Les compétences en lecture, en calcul et en géométrie des élèves à l’entrée au CE2 et en sixième(No Note d’information, 96.22.). France, Paris : ministère de l’Éducation nationale, de l’Enseignement supérieur et de la Recherche.
List of figures
Figure 1
Exemple de triplet : le mot initiant la différenciation a un rôle syntaxique
Figure 2
Déroulement de l’exercice triplet
Figure 3
Score z des compréhensions au pré-test et au post-test du groupe témoin et du groupe expérimental
List of tables
Tableau 1
Répartition du sexe, de l’âge, de la note en mathématiques et de la note en français suivant les deux groupes, à l’évaluation nationale de 5e (ces deux notes sont exprimées sur 100)
Note : m signifie moyenne et s signifie écart-type.
Tableau 2
Répartition des individus en fonction des épreuves. Les effectifs figurent entre parenthèses
Tableau 3
Résultats de l’ANOVA à mesures répétées expliquant les compréhensions
Note : SC = somme des carrés ; dl = degré de liberté ; CM = carré moyen ; F = statistique du F ; p = niveau de signification.
Tableau 4
Résultats de la compréhension en lecture au pré-test et au post-test
Tableau 5
Vitesse en lecture au pré-test et au post-test