Abstracts
Résumé
La finalité du présent article est de montrer l’intérêt de l’analyse de la néologie lexicale dans le cadre de la description de la langue. Le travail dont nous faisons état fait partie d’un vaste projet de recherche ayant pour objectif la description comparée des néologismes et des ressources de néologie utilisées dans les diverses modalités de la langue catalane. Ainsi, nous avons axé la recherche sur la néologie utilisée dans les médias et formée par composition populaire, qui est l’un des mécanismes permettant aux locuteurs catalans de former des mots nouveaux au moyen de ressources qui leur sont propres. Nous avons analysé les néologismes de langue catalane formés par composition et relevés dans un corpus diachronique de textes de presse couvrant une période de quinze ans. L’étude met en évidence le passage d’une productivité de 8 % à 2 % pour la composition populaire. Elle révèle également que la structure de la plupart des néologismes par composition est de type NN, et que la représentativité d’autres structures productives dans le passé se révèle être nulle ou peu importante dans le corpus de néologismes étudié.
Mots-clés:
- néologie,
- composition,
- diachronie,
- langues romanes,
- vitalité linguistique
Abstract
The purpose of this paper is to discuss the utility of lexical neology analysis in linguistic description. This work is part of a large project aiming at contrasting the description of neologisms and neologistic resources used in different modalities of the Catalan language. In this context, we focus our research on neologisms used in the media that are formed by Catalan compounding, which is one of the mechanisms allowing Catalan speakers to form new words using their own linguistic resources. We have analyzed Catalan neologisms formed by compounding in a diachronic corpus of newspaper articles covering a period of fifteen years. The study shows how the productivity of popular compounding has diminished from 8% to 2%. It shows also that the structure of most compounds is NN while the representativity of other structures, significant and productive in the past, appears to be null in the neologism corpus under study.
Keywords:
- neology,
- compounding,
- diachrony,
- roman languages,
- linguistic vitality
Article body
1. Introduction
La créativité linguistique est une condition de la vitalité des langues. Bien que l’innovation se manifeste dans toutes les composantes d’une langue (phonologique, morphologique, lexicale, syntaxique), c’est dans le lexique que son dynamisme transparaît le plus clairement, en particulier avec une approche synchronique de l’étude la langue. Étudier la créativité lexicale revient à étudier la néologie (Guilbert 1975). L’apparition de néologismes dans les langues vivantes est un fait naturel. Ainsi, le catalan, comme toutes les langues, renouvelle constamment son lexique, tant avec des mots désignant des réalités nouvelles (et ayant une fonction avant tout référentielle) qu’avec des mots se référant à une réalité déjà nommée (et ayant une fonction principalement expressive). Les locuteurs du catalan alimentent leur lexique avec : a) des mots formés à partir des ressources propres au catalan ; b) des formes déjà existantes ayant de nouvelles propriétés sémantiques ; c) des mots empruntés à d’autres langues. En fait, plus une langue est sociopolitiquement consolidée, plus elle est susceptible de s’enrichir de mots nouveaux. Toutes les langues sont à même de tout exprimer, mais toutes ne le font pas de la même manière.
La composition populaire en catalan, conçue comme la ressource morphologique permettant de former des mots à partir de lexèmes de la langue catalane, a longtemps été une ressource importante de la langue catalane[1] (picasoques [/grimpereau/], parallamps [/paratonnerre/], escurabutxaques [/pickpocket/], penja-robes [/portemanteau/], llepaculs [/lèche-cul/], escalfatecles, espiadimonis [/libellule/], trencaclosques [/puzzle/], paraigua [/parapluie/], terratrèmol [/tremblement de terre/], camatrencar [/casser les pattes d’un animal/], corferir [/avoir une attaque au coeur/], menystenir [/mépriser/], camacurt [/court sur pattes/], agredolç [/aigre-doux/], sord-mut [/sourd-muet/], etc.). On peut toutefois se demander si sa représentativité est toujours aussi forte que les différentes grammaires le prétendent, et c’est ce que la présente étude cherchera à déterminer. Notre position est que l’étude de la néologie permet d’approfondir la connaissance d’une langue, que ce soit au plan de la théorie ou au plan de la description linguistique (Lehrer 1996). Elle se justifie pleinement en tant qu’objet d’étude de la linguistique appliquée, car elle constitue un carrefour clé pour divers contextes professionnels, tels que la planification linguistique, la sociolinguistique, la terminologie ou la rédaction ou la traduction de textes.
En dehors des grammaires, plusieurs travaux en langue catalane se sont penchés sur la néologie faisant appel au procédé de composition (Cabré 1994 ; Gràcia 2002 ; Rull 2004 ; Feliu, Garcia et al., 2002 ; Lladó et Talamino 2002 ; Solé et Vázquez 2002 ; Vallès 2002, 2004). Toutefois, rares sont les recherches exploitant des données comparées extraites de corpus textuels (Estopà 2004 ; Feliu, Garcia et al. 2002), et plus rares encore sont celles qui se sont attaquées à des corpus oraux (Domènech, Estopà et al. 2002, 2007). Par ailleurs, peu d’études traitant de la néologie des langues romanes ont été réalisées sous l’angle de la diachronie pour mettre en relief la créativité linguistique d’une communauté au cours d’une longue période, données pourtant précieuses, car permettant de réaliser une « radiographie » des changements linguistiques plus complète que la description basée sur des données synchroniques. Le français, par exemple, bénéficie de la thèse doctorale de Sablayrolles (2000), mais aucune étude récente comparant les modes de formation lexicale dans les diverses langues romanes n’est jusqu’à présent connue.
En ce qui concerne le catalan, nos données confirment la tendance selon laquelle de nombreux néologismes formés par composition nominale sont utilisés dans un registre populaire et vulgaire. Dans ce contexte, la comparaison des données issues de la presse écrite avec les données provenant des médias faisant appel à la communication orale s’est révélée essentielle, la radio étant souvent plus spontanée et moins contrôlée linguistiquement que les journaux.
2. Corpus et méthodologie
La présente étude se fonde sur l’analyse des néologismes résultant du dépouillement de textes provenant de divers médias de grande diffusion. Deux corpus de néologismes ont été constitués, l’un à partir de la presse quotidienne, l’autre à partir de transcriptions de l’oral, grâce à la base de données de l’Observatori de Neologia (OBNEO) de l’Institut Universitari de Lingüistica Aplicada de l’Universitat Pompeu Fabra, BOBNEO, qui rassemble des néologismes lexicaux provenant des médias, écrits et oraux, en espagnol et en catalan, depuis 1992. L’équipe de l’OBNEO a mis au point un moteur de recherche, dit « Cercador BOBNEO », permettant de consulter librement BOBNEO par Internet. Cet outil est accessible à l’adresse <http://obneo.iula.upf.edu/>, qui regroupe par ailleurs l’ensemble des ressources linguistiques de l’Observatori de Neologia. De plus, grâce à une entente avec le Centro Cervantes, une interface web a été créée sur le site Internet de ce dernier, le « Centro Virtual Cervantes », de manière à permettre la consultation des données relatives au catalan depuis 2004 et à les comparer avec celles de l’espagnol (http://cvc.cervantes.es/obref/banco_neologismos/).
Le corpus de presse écrite est constitué des journaux édités en langue catalane : Avui, El Periódico[2], El Punt (quotidiens) et El Temps publiés de 1995[3] à 2007. Le corpus de radio est constitué de programmes diffusés de 2000[4] à 2007 par trois stations : Catalunya Ràdio, Rac1 et COM ràdio ; ces programmes radiophoniques sont classés selon quatre catégories établies par l’OBNEO : R1 (bulletins d’information), R2 (entrevues et magazines), R3 (discussions et débats), R4 (bulletins sportifs).
2.1. Concept de néologisme et corpus d’exclusion
Il est bien connu que la nouveauté n’existe pas en elle-même, sinon par référence à autre chose ; une recherche sur la néologie impose donc de définir le cadre dans lequel une lexie est nouvelle ainsi que le code avec lequel elle est en relation. Le critère avec lequel travaille l’OBNEO pour établir la néologicité d’un mot est lexicographique : on considère comme néologisme tout mot n’apparaissant pas dans le corpus lexicographique d’exclusion, constitué par un ensemble de dictionnaires sélectionnés dans cette optique[5].
Établir un corpus d’exclusion permet ainsi de repérer les néologismes dans les textes soumis au dépouillement ; si les dictionnaires sélectionnés sont des ouvrages normatifs (dictionnaires élaborés ou adoptés par l’Institut d’Estudis Catalans[6]), la quantité de néologismes issus du dépouillement sera significativement supérieure à la quantité de néologismes issus d’un dépouillement semblable, réalisé, cependant, à partir d’un corpus d’exclusion constitué de dictionnaires descriptifs, dont la nomenclature est généralement plus exhaustive. Depuis ses débuts, l’OBNEO travaille avec un corpus réunissant des ouvrages normatifs et descriptifs, constamment mis à jour avec les dictionnaires nouvellement parus. Si un mot figure dans l’un de ces ouvrages, il ne peut être considéré comme un néologisme. En ce qui concerne le corpus radiophonique, l’application du critère lexicographique a conduit à une observation d’une néologie exclusivement lexicale, ce qui a mis au second plan les formes néologiques résultant de phénomènes strictement phonétiques (sons adventices ou de support, propres au registre oral) ou dialectaux (ex : paiella au lieu de paella ; aixíns au lieu de així [/ainsi/] ; mentres au lieu de mentre [/pendant/]).
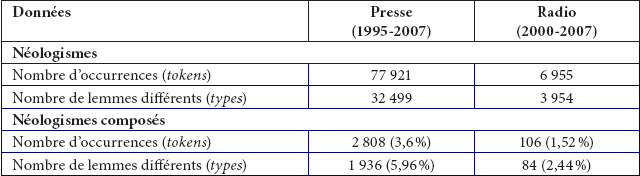
La représentativité de la ressource étudiée peut être déduite en tenant compte du nombre total de néologismes correspondant à la période analysée (Ashen et Aronoff 1989). Le tableau 1 présente le nombre total de mots nouveaux pour chacun des corpus étudiés.
Tableau 1
Corpus de données
2.2. Enregistrement des données
Le dépouillement des corpus diffère, notamment, par la chaîne de détection de néologismes : dans le cas de la presse écrite, le dépouillement est semi-automatique. Dans celui du corpus oral, le repérage et l’extraction demeurent encore intégralement manuels, malgré l’évolution de la technologie, qui ne permet pas encore d’avoir recours à un traitement automatique ou semi-automatique. Le corpus oral est accessible sur support électronique, ce qui en facilite le dépouillement. La plupart des textes du corpus de presse écrite quotidienne sont traités semi-automatiquement avec l’extracteur de néologismes BUSCANEO, qui repère tous les mots ne figurant pas dans le corpus lexicographique utilisé[7] et les propose comme candidats néologismes : le néologue doit les valider et les compléter au moyen d’informations linguistiques et extralinguistiques. Étant donné que BUSCANEO ne détecte ni la néologie sémantique, ni la néologie syntagmatique, ni la néologie résultant de changement de syntaxe ou de catégorie grammaticale, l’OBNEO continue de dépouiller manuellement et de manière systématique ce type de textes, parallèlement aux dépouillements automatiques.
Les informations relatives aux néologismes repérés se répartissent entre deux grands blocs : d’une part, celles qui concernent tous les néologismes (oraux et écrits), d’autre part, celles qui sont spécifiques aux différents types de néologismes. Les informations concernant tous les néologismes de l’OBNEO sont les suivantes : l’entrée (sous forme lemmatisée), la catégorie grammaticale, le type de néologisme, le contexte d’apparition, la référence complète de la source, la présence de marques pragmatiques de nouveauté et, si nécessaire, une note explicitant certains aspects du néologisme (orthographique, sémantique, contextuel, renvois, etc.). Les informations spécifiques aux différents types de néologismes se rapportent aux deux corpus, écrit ou oral. Dans le cas du corpus écrit, il s’agit des marques métalinguistiques. Dans le cas du corpus oral, la transcription phonétique et la description des caractéristiques de l’émetteur (rôle, âge, sexe, dialecte et langue maternelle)[8] sont indiquées.
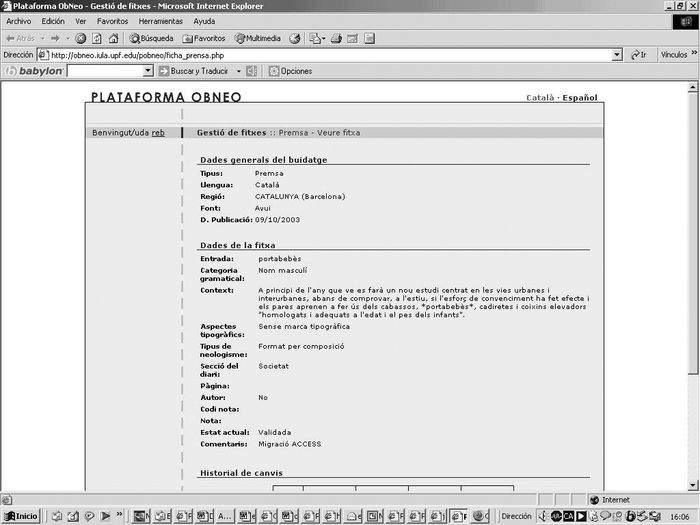
La figure 1 présente la fiche du néologisme portabebès (/porte-bébés/), qui a été repéré dans la presse écrite.
Figure 1
Fiche du néologisme portabebès issu du corpus de presse écrite
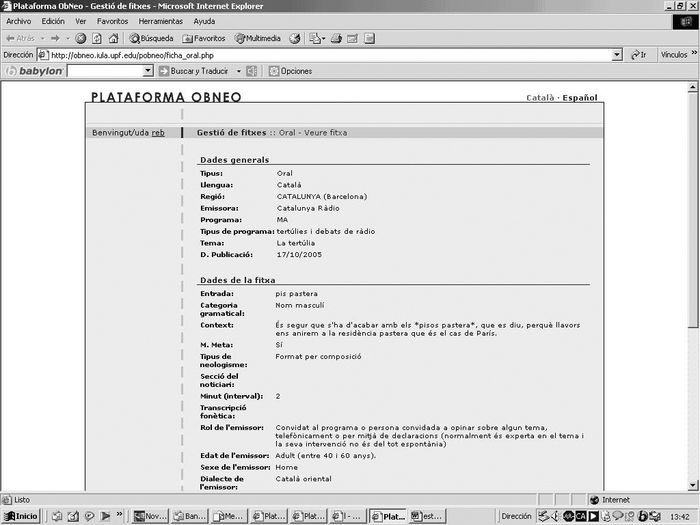
La figure 2 présente la fiche du néologisme de pis pastera (/logement dans lequel plusieurs familles d’immigrés en situation de précarité vivent entassées/), qui est un exemple de néologisme oral.
Figure 2
Fiche du néologisme pis pastera issu du corpus radiophonique
Les données sont enregistrées sur la plateforme de travail en ligne élaborée par l’OBNEO et qui permet à plusieurs collaborateurs de travailler simultanément par télématique. Lorsqu’elles sont complètes, les données font l’objet de deux révisions et sont ensuite introduites dans la base de données qui peut être consultée librement sur Internet à l’adresse <http://obneo.iula.upf.edu/>.
3. La composition populaire
La définition de la composition représente l’un des points les plus controversés de la théorie lexicale. Les linguistes ayant effectué des recherches durant de nombreuses années sur ce sujet doivent reconnaître qu’il n’existe pas, à ce jour, de consensus (Benveniste 1966 ; Mascaró 1985 ; Corbin 1987 ; Lang 1990 ; Gaztelu, Zabala et al. 2004). La composition, comprise au sens large comme la formation de mots à partir de plus d’une racine ou plus d’un lexème, a suscité, aussi bien dans les études traditionnelles de grammaire que dans les propositions les plus récentes de la linguistique, une grande diversité de positions menant à une certaine confusion.
Ainsi, derrière le procédé de composition se trouve un ensemble d’amalgames théoriques qui en dissimule la portée et qui l’assimile souvent à d’autres procédés de formation de mots comme la préfixation, la composition savante et, plus particulièrement, la syntagmation. De plus, traditionnellement, on oppose deux types de compositions : a) la composition populaire, qui a recours aux bases de la langue, le catalan dans notre cas, et qui obéit à ses règles syntaxiques ; b) la composition savante, qui emprunte aux langues classiques, le grec et le latin, ses bases et sa syntaxe interne (Badia 1962 ; Corbin 1991 ; Cabré 1994 ; Bosque et Demonte 1999 ; Solà, Lloret et al. 2002). Ainsi, biblioteca (/bibliothèque/) est un composé savant et rentaplats (/lave-vaisselle/) est un composé populaire. Dans le cadre de ce travail réalisé à l’aide des critères de l’OBNEO, nous avons distingué tous les procédés de formation de mots, mais nous avons privilégié les néologismes formés par composition populaire, c’est-à-dire à partir d’au moins deux lexèmes du catalan[9].
4. La composition populaire dans les grammaires catalanes et autres travaux linguistiques
À partir de la description de la formation de nouvelles unités lexicales de plus d’un lexème en langue catalane, il se dégage diverses perspectives correspondant à trois niveaux linguistiques différents : structures lexicales, dénominations et conceptions.
La diversité des structures lexicales constitue le premier aspect d’hétérogénéité auquel font référence les auteurs lorsqu’ils illustrent ce procédé (Marvà 1932 ; Moll 1952 ; Fabra 1956 ; Badia 1962 ; Cabré 1994 ; Gràcia 2002). Ainsi, dans divers ouvrages et grammaires, des mots composés compris au sens large sont cités à titre d’exemples : pell-roja (/peau-rouge/), parenostre (/notre-père/), agredolç (/aigre-doux/), hispano-romà (/hispano-romain/), apagallums (/éteignoir/), allioli (/ailloli/), set-ciències (/je-sais-tout/), mal de cap (/mal de tête/), corprendre (/charmer/), estira-i-arronsa (/tirer et relâcher/), giravolta (/pirouette/), lliurecanvista (/libre-échangiste/), filferro (/fil de fer/), camió-cisterna (/camion-citerne/), faldilla-pantalon (/jupe-culotte/), rinofaringe (/rhinopharynx/), rau-rau (/remords/), primfilar (/pinailler/), avall (/en dessous/), blau marí (/bleu marine/), clau anglesa (/clé anglaise/), punt i coma (/point-virgule/), tenir por (/avoir peur/), mestre de cases (/maîtresse de maison/), trenta-quatre (/trente-quatre/), pruna clàudia (/reine-claude/), verd poma (/vert pomme/), etc. L’examen de ces séquences permet de reconnaître des unités qui, comme nous l’avons indiqué, sont formées de différentes manières : par préfixation, par composition populaire, par composition savante et par syntagmation.
Le deuxième aspect de la diversité concerne les dénominations faisant référence à toutes ces unités lexicales par différents auteurs. Les grammaires catalanes ne sont pas homogènes. Dans les six grammaires catalanes principales (Marvà 1932 ; Moll 1952 ; Fabra 1956 ; Badia 1962 ; Ruaix 1986 ; Solà, Lloret et al. 2002), différentes dénominations sont utilisées pour désigner la composition et la distinguer des autres modes de formation de néologismes (Solé et Vázquez 2002). Certains auteurs (Badia 1962 ; Ruaix 1986) distinguent également des ensembles de mots nommés locutions, qui ne sont pas toujours équivalents aux différentes catégories d’unités syntagmatiques lexicalisées de la langue catalane. Les dénominations utilisées dans les différentes grammaires sont résumées et illustrées au moyen d’exemples dans le tableau 2.
Tableau 2
Les dénominations de la composition dans les grammaires catalanes
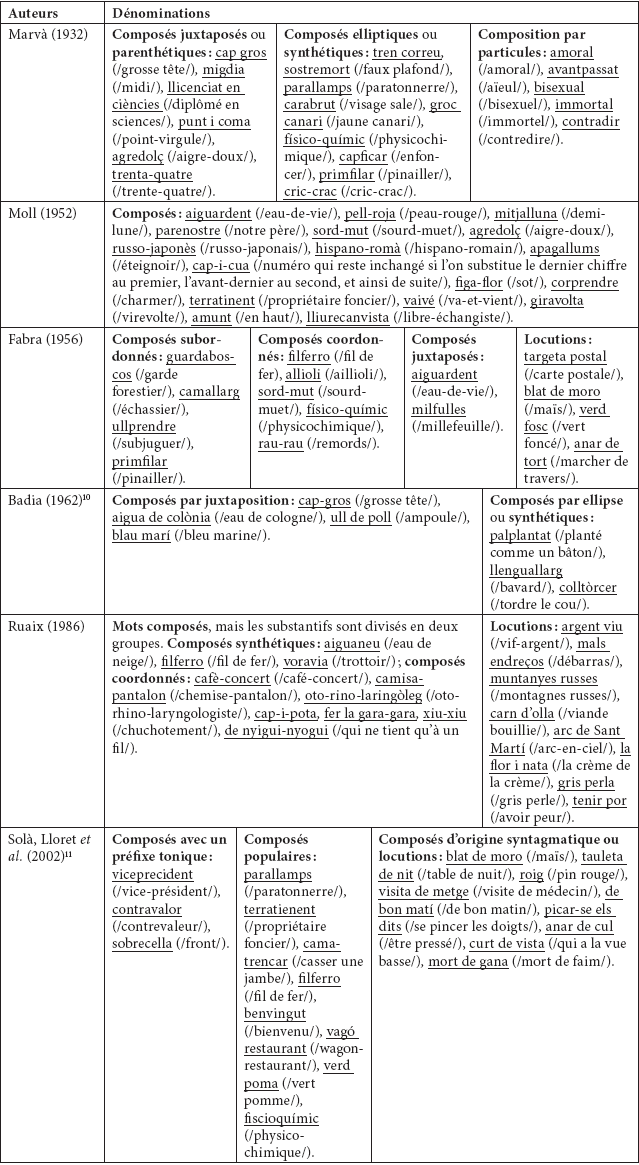
Ce tableau met en évidence la multiplicité des typologies de formations de mots proposées par les grammairiens catalans, avec le fait que les limites entre les différents types ne coïncident pas toujours. De plus, il souligne la grande diversité des dénominations utilisées dans les grammaires et, enfin, les interférences entre la composition, la préfixation et la syntagmation. Cette diversité est corroborée par le manque de consensus chez les linguistes : certains ont recours à l’étiquette composé pour faire référence à toutes les unités, comme Di Sciullo et Williams (1987) ou Zwanenburg (1990). D’autres auteurs utilisent plus d’une dénomination : Benveniste (1966) introduit le mot synapse, Varela (1990) a recours aux dénominations composé et syntagme lexical, Lieber (1992) distingue composé de phrase composée, Corbin (1992) emploie la dénomination unité polylexématique comme variante de composé et Cabré (1994) opte pour différencier composé de syntagme composé / complexe.
Enfin, la signification attribuée par les différents auteurs à une même dénomination constitue un troisième paramètre de divergence. Ainsi, le mot composé n’exprime pas toujours la même notion : il se produit une variation cognitive. De même, les grammairiens conçoivent les procédés de formation différemment. Comme le signalent Solé et Vázquez (2002), la plupart des grammaires catalanes proposent un traitement descriptif détaillé et exemplifié des aspects structurels, grammaticaux et orthographiques, mais la description sémantique y est souvent inexistante ou très vague.
L’OBNEO (Observatori de Neologia 2004), suivant les positions de Cabré (1994) et de Corbin (1992), aborde la composition comme une ressource lexicale de formation de mots : les mots composés font partie de la composante lexicale de la grammaire et sont expliqués par des règles lexicomorphologiques. La dénomination unité syntagmatique est réservée aux unités lexicales produites au sein de la composante syntaxique de la grammaire qui, sans transgresser aucune des règles syntactiques, se sont lexicalisées[12]. Ce qui implique que les mots formés par deux noms sont considérés à l’OBNEO et dans ce travail comme des mots composés.
5. Néologismes formés par composition populaire au cours de la période 1995-2007 : résultats
Les néologismes composés populaires ont joui d’une représentativité variable au cours des dernières années. Le tableau 3 reflète la représentativité de la composition populaire entre 1995 et 2007, tel qu’il a été consigné dans la base de données de néologismes de l’OBNEO.
Tableau 3
Représentativité de la composition populaire dans BOBNEO (1995-2007)
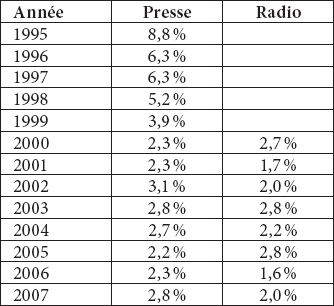
Le tableau 3 met en évidence deux constatations : d’une part, le pourcentage de néologismes formés par composition populaire est du même ordre dans les corpus de presse écrite et radiophonique ; d’autre part, on observe clairement un recul progressif de ce mode de formation au cours des années. Ce recul semble toutefois se stabiliser à partir de l’année 2000, laquelle correspond d’ailleurs au début du dépouillement du corpus oral. Par conséquent, le matériel dont nous disposons nous incite à penser que l’on observera également un recul progressif dans la langue orale. Il faudra vérifier si la baisse de productivité que l’on peut observer dans le corpus oral les deux dernières années se poursuivra.
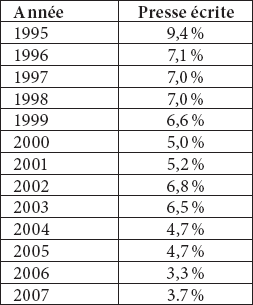
Parallèlement, nous avons également évalué la productivité de la composition populaire dans un corpus de presse écrite en castillan de l’OBNEO créé avec la même méthodologie que le corpus en catalan. Il s’agit des néologismes issus des journaux La Vanguardia et El País, compilés pendant la même période. Les résultats sont les suivants :
Tableau 4
Représentativité de la composition populaire en espagnol dans un corpus de presse écrite
Les résultats de l’analyse des structures morphosyntaxiques sont présentés dans le tableau 5 :
Tableau 5
Structures morphosyntaxiques des néologismes formés par composition catalane
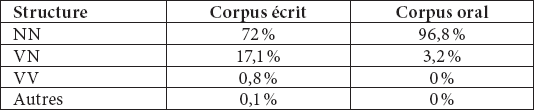
Actuellement, selon ces données, la structure la plus productive est celle qui permet de former des noms à partir de deux autres noms. En revanche, les noms formés à partir d’un verbe à la troisième personne du singulier et d’un nom au pluriel – structure considérée par les grammairiens comme prototype des noms composés – ont une faible représentativité dans notre base de données.
6. Discussion
Les données analysées montrent un changement progressif de la représentativité de la composition populaire parmi les différentes ressources de formation de mots nouveaux en langue catalane. Bien que ce changement de paradigme nous semble être déjà assez évident, il serait nécessaire de l’étudier de manière détaillée dans la formation de mots en le contrastant avec d’autres ressources. Cet objectif devrait être conforté grâce à l’analyse de données d’autres corpus et d’autres langues romanes pouvant être respectivement liées à la hausse de la productivité de ressources comme la syntagmation.
Cette baisse de l’une des ressources de création lexicale les plus typiques de la langue catalane – mais aussi d’autres langues romanes – soulève donc des questions de recherche telles les suivantes : 1) Au détriment de quelle ressource de formation la productivité de la composition populaire a-t-elle diminué ? 2) Ces diminutions de la productivité de la composition plus populaire correspondent-elles à un phénomène isolé de la langue catalane ou se produisent-elles dans d’autres langues romanes ?
6.1. Au détriment de quelle ressource de formation la productivité de la composition populaire a-t-elle diminué ?
Les données ont permis de constater que, dans les deux corpus, l’écrit et l’oral, la structure syntactico-morphologique prédominante des néologismes formés par composition est celle qui est formée de deux noms (72 % et 96,8 %), bien qu’il ressorte, du corpus de presse écrite, une plus grande diversité de structures, en particulier des noms constitués d’un verbe et d’un nom (VN) (17,1 % dans la presse et 3,2 % à la radio). Si nous analysons les composés formés de deux noms, nous constatons qu’ils se comportent sémantiquement comme un type de mots syntagmatiques (formés d’un nom et d’un adjectif) au sein desquels le second élément agit comme « catégorisateur » du premier (autobús [/autobus/], llançadora [/navette/], blau petroli [/bleu pétrole/], efecte dominó [/effet domino/], escot banyera [/décolleté/], hoquei gel [/hockey sur glace/]).
À ce sujet, il est convient de rappeler que la structure formée de deux noms (NN) n’est pas considérée par tous les linguistes comme composée, c’est-à-dire comme fruit d’une règle morphologique de formation de mots. Certains linguistes, dans le cadre de la grammaire générative, comme Di Sciullo et Williams (1987), défendent le fait qu’il s’agit d’une structure syntagmatique pouvant créer des unités syntagmatiques lexicalisées qu’ils affirment être formées dans la composante syntaxique de la langue, qui se sont postérieurement lexicalisées et qui ont ensuite intégré la composante lexicale. À l’OBNEO, les travaux de Corbin (1992) et de Cabré (1994), mais aussi de Gràcia (2002), nous permettent de distinguer entre les unités qui suivent les règles de la syntaxe, qualifiées d’unités syntagmatiques selon la typologie de l’OBNEO, des unités non syntagmatiques. Les composantes de certaines de ces unités de structure NN présentent des caractéristiques syntaxiques et sémantiques qui les rapprochent davantage des unités du type nom et adjectif (NA) ou nom et syntagme prépositionnel (NSprep) que des unités composées plus classiques. En effet, la structure est composée de deux noms, dont l’un agit comme un adjectif transgressant en général les règles syntactiques du catalan. Pour cette raison, il est possible de considérer que ce sont des mots nés dans la composante morphologique de la langue. Dans d’autres langues, comme l’anglais ou l’allemand, langues dans lesquelles l’apposition nominale est une structure syntactique type, la structure serait syntagmatique. Cependant, sémantiquement, aussi bien en catalan qu’en anglais, ces composés fonctionnent exactement de la même manière que les mots syntagmatiques de structure NA ou NSprep.
De plus, les mots de structure NN constituent généralement des séries hyponymes dérivées de leur hyperonyme respectif, le premier nom. Il en est de même pour les mots de structure NA, dans lesquels l’hyperonyme est le nom. Dans ce cas, il est encore plus difficile de les traiter différemment ; selon la théorie du prototype, ils ont un « air de famille » avec les mots de structure NA, bien qu’issus de la composante morphologique, comme le reste des composés populaires. Le comportement sémantique et subcatégorisant du deuxième nom les assimile aux néologismes syntagmatiques, les rapproche de la syntagmation et de la composition ; les mots de structure NA s’éloignent de ce que l’on peut considérer comme composés populaires prototypiques. Ces mots pourraient, par conséquent, être considérés comme de faux composés ou des pseudo-composés.
Ainsi, si nous ré-étiquetions ces composés et si nous allions jusqu’à les éliminer de la liste des néologismes formés par composition populaire, nous pourrions alors affirmer que la productivité de la composition populaire en tant que ressource de création de mots serait quasiment nulle en langue catalane.
Dans un travail incluant des données de 1995, l’OBNEO (1998) avait déjà observé que certaines structures de la composition populaire étaient peu productives et présentaient même certaines restrictions quant au registre ; de nombreux néologismes documentés de structure VN correspondaient à un registre familier, voire vulgaire, observation confirmée par des données actuelles. Par exemple, matagegants (/tue-géants/), caçanazi (/chasse-nazi/), menja-home (/mange-homme/), extraits du corpus de 1995, et menjacocos (/personne qui a tendance à trop penser/), buscavides (/personne douée pour surmonter les difficultés qui se présentent à elle dans la vie/), punxadiscos (/disc-jockey/), vigilacotxes (/personne qui surveille les voitures/), caçatalents (/chasseur de talents/), rosegatextos (/personne qui lit beaucoup/), tocacollons (/casse-pieds/), qui apparaissent dans le corpus actuel, constitué de textes de la presse écrite et de discours radiophoniques. Toutefois, certaines grammaires soulignent le fait que la structure VN, qui permet de former des noms composés, est très productive, bien que les données de l’OBNEO ne le montrent pas. D’autre part, certaines structures, comme gérondif et nom (V+nt+N) (portantveus [/porte-parole/]) ou verbe et verbe (V+V) (alçaprem [/levier/]), apparaissent dans toutes les grammaires. Bien que caractérisées comme peu productives dans certains cas (Gràcia 2002), ces structures n’apparaissent pas dans notre corpus. Les données montrent donc que leur représentativité et leur productivité sont considérées comme étant quasiment nulles.
6.2. La diminution de la productivité de la composition populaire correspond-elle à un phénomène isolé de la langue catalane ou se produit-elle dans d’autres langues romanes ?
Afin d’obtenir des réponses définitives à cette seconde question, il serait nécessaire de réaliser des études détaillées de chacune des grammaires en ayant recours à une méthodologie similaire. Cependant, nous sommes en mesure de présenter certains indices incitant à des recherches plus approfondies sur le sujet. Ainsi, bien que la baisse ne soit pas aussi exhaustive et progressive que dans le cas du catalan, les données du tableau 4 confirment notre hypothèse : le recul de cette ressource de formation de mots pourrait être une caractéristique commune à plusieurs langues romanes. En analysant les données du castillan, nous avons également constaté que la plupart des néologismes formés au moyen de cette ressource correspondent à la structure NN, qui caractérise le même type de néologismes que dans le corpus en catalan. Il n’est pas possible de prévoir ce qui pourrait se produire dans les autres langues romanes, bien que des résultats similaires puissent être attendus. Pour pouvoir effectuer des études comparatives, il serait nécessaire de pouvoir réaliser un suivi des mots nouveaux de chaque langue au cours d’une période donnée, dans la mesure où ce type de constatation n’est observable objectivement que si un corpus réel et diachronique de données comme celui que l’OBNEO nous a permis de constituer peut être analysé. Les travaux menés à bien dans le cadre du projet NEOROM, projet coordonné par Cabré, qui réunit différents observatoires de langues romanes, permettront à long terme de réaliser des analyses contrastives très intéressantes. Cependant, pour le moment, seules les données des années 2007 et 2008 sont disponibles (la base de données peut être consultée librement sur Internet à l’adresse <http://obneo.iula.upf.edu/bneorom/index.php>). Ces données ont néanmoins permis de constater que la représentativité de la composition populaire dans certaines langues est un peu supérieure à celle de la langue catalane, mais que la structure syntaxique des composés documentés la plus fréquente est également formée de deux noms.
En conclusion, nous souhaitons aborder la question des causes du recul de la productivité de la composition populaire de structures différentes à NN et celle de la hausse de la productivité des noms formés de deux autres noms. Le traitement de cette question, qui présente un caractère sociolinguistique nécessite, selon nous, de déterminer l’influence actuelle de la langue anglaise au sein des sociétés dites « modernes », dans tous les domaines (scientifique, technique, technologique, économique). Cette influence s’étend aux autres langues et les changements lexicaux résultent de l’évolution sociale, économique et politique, les langues étant le miroir de la société. En ce sens, l’anglais facilite de manière évidente la création de mots nouveaux à l’aide de mots déjà existants ayant comme structure NN ou adjectif et nom (AN) qui, en catalan, se sont simplement transformés en NN et NA. En effet, le passage du lexique d’une langue à une autre et aussi de ses ressources de formation de mots constitue un phénomène récurrent dans l’histoire des langues. Néanmoins, cette dernière question exige une étude plus approfondie. En tout cas, notre article a permis de démontrer, à partir d’un corpus de données néologiques, qu’un changement s’est produit dans le paradigme de formation de mots en langue catalane au cours de ces trois dernières années.
Appendices
Remerciements
Le présent document a été traduit du catalan par Jenny Azarian et révisé par Meta. Je remercie spécialement Sylvie Vandaele et les relecteurs pour leurs précieux commentaires.
Notes
-
[1]
Ainsi que d’autres langues romanes : Varela (1993) et Val Álvaro (1999) pour l’espagnol, Adamo et Della Valle (2008) pour l’italien, Biderman (2001) pour le portugais et Corbin (1992) pour le français.
-
[2]
Ce journal est édité en catalan et en espagnol à Barcelone. Dans le cadre du présent travail, seule l’édition en catalan a été objet d’étude.
-
[3]
Date à laquelle les données de l’OBNEO ont été analysées et étiquetées par ressources de formation.
-
[4]
Date à laquelle l’OBNEO a commencé le dépouillement systématique de discours oraux.
-
[5]
En ce qui concerne le catalan, le corpus lexicographique d’exclusion de l’Observatori est constitué d’ouvrages de référence essentiels :
Institut d’Estudis Catalans (1995) : Diccionari de la llengua catalana. Barcelona, Palma de Mallorca, València : 3 et 4, Edicions 62, Editorial Moll, Enciclopèdia Catalana, Publicacions de l’Abadia de Montserrat. Jusqu’à la parution du nouveau dictionnaire normatif, le corpus lexicographique d’exclusion était constitué du Diccionari General de la Llengua Catalana de Pompeu Fabra.
Enciclopèdia Catalana (1998) : Gran diccionari de la llengua catalana. Barcelona : Enciclopèdia Catalana.
Enciclopèdia Catalana (1993) : Diccionari de la llengua catalana. 3e éd. Barcelona : Enciclopèdia Catalana.
Enciclopèdia Catalana (1992) : Gran Enciclopèdia Catalana. 2e éd. Barcelona : Enciclopèdia Catalana.
-
[6]
L’Institut d’Estudis Catalans (IEC) est la plus haute autorité de la langue catalane. La Secció Filològica de l’IEC tient lieu d’académie de la langue catalane. Elle a pour fonction l’étude scientifique de la langue, l’élaboration de la norme linguistique et le suivi du processus d’application de cette norme dans les domaines lui étant propres : les terres de langue et de culture catalanes (<http://www.iec.cat>).
-
[7]
BUSCANEO permet de sélectionner différents dictionnaires suivant les nécessités de chaque projet.
-
[8]
Les détails de la méthodologie concernant les différents dépouillements peuvent être consultés dans le document suivant : Metodologia del treball en neologia : criteris, materials i processos, accessible à l’adresse : <http://www.iula.upf.edu/repositori/04mon008.pdf>.
-
[9]
Il existe d’autres types de compositions (composition hybride et composition par troncation ou mots-valises), mais leur examen dépasse les objectifs de la présente étude.
-
[10]
Il faut noter que Badia (1962) propose, à partir de cette typologie fondée sur divers aspects structurels, deux autres classifications, l’une organisée selon la catégorie grammaticale des éléments qui constituent le composé, l’autre, selon la catégorie grammaticale du composé.
-
[11]
Les mots formés à partir de plus d’un radical sont traités dans les chapitres 7 et 8 écrits respectivement par Gràcia et Lorente (2002).
-
[12]
La lexicalisation (Bauer 1988 ; Corbin 1992 ; Cabré 1994), qui permet de distinguer les syntagmes lexicalisés des syntagmes libres, constitue aussi une notion problématique et difficile à définir. Les linguistes ont établi une série de critères de nature diverse qui contribuent à déterminer les cas où un segment cesse d’être une séquence du discours libre et devient une unité lexicale. Ces essais font allusion à des critères de nature linguistique affectant diverses composantes grammaticales de la langue : critères phonétiques, morphologiques, syntaxiques, sémantiques et pragmatiques, ainsi qu’à des critères extralinguistiques, graphiques, statistiques, référentiels et sémiotiques.
Références
- Adamo, Giovani et Della Valle, Valeria (2008) : Le parole del lessico italiano. Roma : Carocci.
- Ashen, Frank et Aronoff, Mark (1989) : Morphological Productivity, Word Frequency and the Oxford English Dictionary. In : Ralph W. Fasold et Deborah Schiffirn, dir. Language Change and Variation. Amsterdam : John Benjamins, 197-202.
- Badia, Antoni Maria (1962) : Gramática catalana. Madrid : Gredos.
- Bauer, Laurie (1988) : Introducing Linguistic Morphology. Edimburg : Edimburg University Press.
- Benveniste, Émile (1966) : Problèmes de linguistique générale. Paris : Gallimard.
- Biderman, Maria Teresa (2001) : Teoria Linguistica. Sao Paulo : Martins Fontes.
- Bosque, Ignacio et Demonte, Violeta, dir. (1999) : Gramática descriptiva de la lengua española. 3. Entre la oración y el discurso. Morfología. Madrid : Espasa-Calpe.
- Cabré, Maria Teresa (1994) : A l’entorn de la paraula. València : Universitat de València.
- Corbin, Danielle (1987) : Morphologie dérivationelle et structuration du lexique. Tübingen : Max Niemeyer Verlag.
- Corbin, Danielle (1991) : La morphologie lexicale : bilan et perspectives. Travaux de linguistique. 23:33-56.
- Corbin, Danielle (1992) : Hypothèses sur les frontières de la composition nominale. Cahiers de grammaire. 17:26-55.
- Di Sciullo, Anne-Marie et Williams, Edwin S. (1987) : On the Definition of Word. Massachussetts : Massachussets Institute of Technology.
- Domenèch, Ona, Estopà, Rosa, Mayoral, Cristina et al. (2002) : La recerca en neologia oral de l’Observatori de Neologia : primers resultats. In :Cabré, Maria Teresa, Freixa, Judit et Solé, Elisabet, dir. Lèxic i neologia. Barcelona : Observatori de Neologia, Institut Universitari de Lingüística Aplicada, Universitat Pompeu Fabra, 277-292.
- Domenèch, Ona, Estopà, Rosa et Mayoral, Cristina (2007) : Neologia lèxica i mitjans de comunicació. In :Actes del Tretzè Col·loqui Internacional de Llengua i Literatura Catalanes. Vol. 2. Barcelona : Publicacions de l’Abadia de Montserrat, 131-142.
- Estopà, Rosa (2004) : Neologismes formats per composició patrimonial i sintagmació. In :Observatori de Neologia, dir. Llengua catalana i neologia. Barcelona : Meteora, 131-158.
- Fabra, Pompeu (1956/1984) : Gramàtica catalana. Barcelona : Teide.
- Feliu, Judit, Garcia, Yanik et Obradós, Isabel (2002) : Aspectes de composició : neologismes nom-nom. In : Cabré, Maria Teresa, Freixa, Judit et Solé, Elisabet, dir. Lèxic i neologia. Barcelona : Observatori de Neologia, Institut Universitari de Lingüística Aplicada, Universitat Pompeu Fabra, 217-224.
- Gaztelu, Elixabete, Zabala, Igone et Gràcia, Lluïsa, dir. (2004) : Las fronteras de la composición en lenguas románicas y en vasco. San Sebastián : Universidad de Deusto.
- Gràcia, Lluïsa (2002) : Formació de mots : composició. In : Solà, Joan, Lloret, Maria Rosa, Mascaró, Joan et Pérez Saldanya, Manuel, dir. Gramàtica del català contemporani. Vol. 1. Barcelona : Empúries, 777-829.
- Guilbert, Louis (1975) : La créativité lexicale. Paris : Larousse.
- Lang, Mervyn F. (1990) : Formación de palabras en español : Morfología derivativa productiva en el léxico moderno. Madrid : Cátedra.
- Lehrer, Adrienne (1996) : Why Neologisms are Important to Study. Lexicology. 2(1):63-73.
- Lieber, Rochelle (1992) : Compounding in English. Rivista di Linguistica. 4(1):79-96.
- Lladó, Mireia et Talamino, Òscar (2002) : Aspectes de composició : neologismes verb-nom. In : Cabré, Maria Teresa, Freixa, Judit et Solé, Elisabet, dir. Lèxic i neologia. Barcelona : Observatori de Neologia, Institut Universitari de Lingüística Aplicada, Universitat Pompeu Fabra, 225-234.
- Marvà, Joan (1932/1934) : Curs pràctic de gramàtica catalana. Barcelona : Barcino.
- Mascaró, Joan (1985) : Morfologia. Barcelona : Enciclopèdia Catalana.
- Merle, Gabriel, Perret, Robert et vince, Jennifer (1986/1987) : Néologie lexicale. Paris : Université Paris 7.
- Moll, Francesc de Borja (1952/1991) : Gramàtica històrica catalana. València : Universitat de València.
- Observatori de Neologia (1998) : Anàlisi de neologismes documentats durant l’any 1995 a la premsa en català. In : Papers de l’IULA. Sèrie Informes, Vol. 23. Barcelona : Institut Universitari de Lingüística Aplicada, Universitat Pompeu Fabra.
- Observatori de Neologia (2004) : Llengua catalana i neologia. Barcelona : Meteora.
- Ruaix, Joan (1986) : El català/3 : Lèxic i estilística. Moià : Éd. J. Ruaix.
- Rull, Xavier (2004) : La formació de mots : questions de normativa. Vic : EUMO.
- Sablayrolles, Jean-François (2000) : La néologie en français contemporain. Examen du concept et analyse de productions néologiques récentes. Paris : Honoré Champion.
- Solà, Joan, Lloret, Maria Rosa, Mascaró, Joan et al., dir. (2002) : Gramàtica del català contemporani. 3 vol. Barcelona : Empúries.
- Solé, Xavier et Vázquez, Mercè (2002) : Aspectes de composició : neologismes amb estructures diferents de nom-nom i verb-nom. In : Cabré, Maria Teresa, Freixa, Judit, Solé, Elisabet, dir. Lèxic i neologia. Barcelona : Observatori de Neologia, Institut Universitari de Lingüística Aplicada, Universitat Pompeu Fabra, 235-250.
- Val Álvaro, José Francisco (1999) : La composición. In : I. Bosque et V. Demonte, dir. Gramática descriptiva de la lengua española. 3. Entre la oración y el discurso. Morfología. Madrid : Espasa-Calpe, 4757-4841.
- Vallès, Teresa (2002) : La productividad morfológica en un modelo dinámico basado en el uso y en los usuarios, In : Cabré, Maria Teresa, Freixa, Judit, Solé, Elisabet, dir. Lèxic i neologia. Barcelona : Observatori de Neologia, Institut Universitari de Lingüística Aplicada, Universitat Pompeu Fabra, 139-157.
- Vallès, Teresa (2004) : La creativitat lexica en un model basat en l’ús. Thèse de doctorat, Barcelona : IULA.
- Varela, Soledad (1990) : Fundamentos de morfología. Madrid : Síntesis.
- Varela, Soledad, dir. (1993) : La formación de palabras. Madrid : Taurus.
- Zwanenburg, Wiecher (1990) : Compounding and Inflection. In :Dressler, Wolfgang U., Luschützky, Hans C., Pfeiffer, Oskar E. et al., dir. Contemporary Morphology. Trends in Linguistics. Studies and Monographs. Vol. 49. Berlin : Mouton de Gruyter, 133-138.
List of figures
Figure 1
Fiche du néologisme portabebès issu du corpus de presse écrite
Figure 2
Fiche du néologisme pis pastera issu du corpus radiophonique
List of tables
Tableau 1
Corpus de données
Tableau 2
Les dénominations de la composition dans les grammaires catalanes
Tableau 3
Représentativité de la composition populaire dans BOBNEO (1995-2007)
Tableau 4
Représentativité de la composition populaire en espagnol dans un corpus de presse écrite
Tableau 5
Structures morphosyntaxiques des néologismes formés par composition catalane