Abstracts
Résumé
Nous traitons dans le cadre de cet article de la nécessité d’élaborer une banque de données de locutions verbales et d’expressions figées classées syntaxiquement et sémantiquement afin que tous les usagers puissent avoir un outil performant qui leur permettrait de disposer de toute l’information nécessaire pour pouvoir réaliser des analyses contrastives et des regroupements de ces expressions par groupes parasynonymes. Pour la traduction de ces locutions, nous expliquons comment il faudra tenir compte de certaines valeurs diasystématiques, comme le niveau de langue, des valeurs diatopiques, et surtout de la possibilité de connaître grâce aux outils linguistiques et informatiques que certaines langues sont en train de créer (Frantext, CREA, CORDE) de la fréquence d’emploi de ces locutions afin d’essayer de trouver la traduction la plus équivalente[2].
Mots-clés/Keywords:
- paradigme,
- schéma d’arguments,
- traduction,
- collocation conceptuelle,
- phraséologie
Abstract
In this paper we deal with the necessity of developing an idiom data bank. These idioms would be syntactically and semantically classified so that all users could have at their disposal an efficient tool providing access to the information they need to make contrastive analyses. This tool would enable them to retrieve all these idioms in groups of parasynonyms. In respect to translation, this paper examines the relevance of considering several diasystematic criteria (diastratic, diatopic criteria, etc.) and, especially, the possibility of knowing how often these idioms are used thanks to linguistic and data-processing tools – which are being developed in several languages: Frantext (French), CREA and CORDE (Spanish) – in order to try to find the most equivalent translation.
Article body
La formation et le fonctionnement des langues sont déterminés non seulement par les règles de libre composition, mais aussi par un grand nombre de phénomènes linguistiques, à structures bien différenciées, utilisés fréquemment dans tous les actes de communication linguistique et qui sont caractérisés par le figement[3]. En effet, depuis que l’humain utilise le langage comme un système complexe de communication, il crée des phrases libres, les répète et les conserve dans sa mémoire. La répétition fréquente de ces combinaisons identiques de mots qui réapparaissent spontanément lors des mêmes situations contextuelles de communication va être ainsi l’élément catalyseur qui initiera le figement de ces formes. Avec ce procès de répétition, les locuteurs les visualisent finalement comme un tout, ce qui leur permettra de les identifier et de les représenter comme des unités stables et perdurables dans le temps. Ce type de combinaisons va aider à la cohésion des groupes linguistiques en créant un fonds traditionnel composé d’un savoir culturel et social commun qui sera déposé dans la mémoire collective de la communauté linguistique qui les utilise.
Ainsi donc, une langue ne s’apprend pas uniquement par l’étude de ses règles grammaticales et de ses mots. La connaissance d’une langue se mesure également d’après la maîtrise et l’adéquation contextuelles avec lesquelles les usagers utilisent tous les éléments figés caractéristiques et représentatifs de chaque langue, qui sont responsables de nombreux problèmes de compréhension. D’abord, chez les locuteurs natifs qui, même s’ils les acquièrent spontanément au fur et à mesure de leur initiation et apprentissage linguistique et communicatif, ne sont cependant pas à même de les connaître dans leur totalité étant donné l’étendue du phénomène. Mais aussi et, surtout, chez les apprenants d’une langue étrangère qui se trouvent face à de nombreuses combinaisons parfois mystérieuses, opaques, voire indéchiffrables, qu’ils ne comprennent pas toujours ou, ce qui est plus grave, ils ne sont pas dans les dictionnaires papier monolingues et bilingues.
1. Délimitation du travail
S’il est bien vrai qu’il existe aujourd’hui dans de nombreux pays des unités de recherche qui analysent systématiquement les séquences figées[4] ou les unités phraséologiques[5], en revanche, l’analyse contrastive impliquant deux ou plusieurs langues, ainsi qu’une traduction poussée et exhaustive, reste encore à faire. D’autre part, si le grand nombre de SFS ou UPS et le traitement insuffisant que leur ont donné les dictionnaires classiques sont deux aspects qui ont freiné l’étude de ces unités, la charge significative et conceptuelle de ces unités est sûrement l’aspect qui a rendu le plus difficile leur traduction.
Nous désirons analyser ici la possibilité de compréhension, de traduction et d’utilisation correcte dans la langue d’arrivée de ces formes figées. Mais, étant donné la grande variété de structures présentes dans le figement, qui inclut des phénomènes de nature très diverses, nous limiterons ce travail afin de suivre une méthode d’analyse et de comparaison rigoureuse aux locutions verbales en espagnol (Corpas 1996 ; Gurillo 1997 ; Mogorrón 2002) et en français (Gross 1996 ; González Rey 2002), c’est-à-dire aux suites verbe + complément dans lesquelles cet assemblage ne serait pas compositionnel.
De même, étant donné les dimensions d’un tel travail[6] (et les objectifs que nous poursuivons), il nous semble important de limiter ici notre analyse à un groupe de LVS bien ciblées dans les deux langues, pour pouvoir tirer des conclusions qui aideront les usagers à mieux cerner, comprendre et traduire ces expressions. En effet, réaliser des comparaisons et des traductions, puis tirer des conclusions de plusieurs milliers de LVS[7] (que nous pourrons représenter dorénavant également par LV/LVS), n’est pas chose facile dans le cadre d’un article. Pour résoudre ce problème, nous avons choisi de travailler par champs lexicaux. Le champ lexical choisi pour illustrer nos recherches est celui des LVS du discours, c’est-à-dire celles qui font référence à un acte de parole. De cette façon, nous avons constitué un inventaire d’environ 975 LVS en espagnol et 1000 en français[8].
2. La traduction des locutions verbales
Pour Jakobson (1958), toute expérience cognitive peut s’exprimer dans n’importe quelle autre langue grâce à des emprunts, calques, traductions littérales, néologismes, paraphrases. Cependant, si la traduction d’une unité lexicale simple ou composée sans valeur idiomatique présente déjà parfois quelques difficultés, la traduction des séquences figées, et encore plus celle des séquences figées à valeur idiomatique, comme c’est le cas des locutions verbales que nous traiterons ici, est sans nul doute une des tâches les plus difficiles à réaliser pour les traducteurs.
Il existe dans toutes les langues de nombreux procédés lexicaux pour exprimer une idée, un concept. Cependant, l’utilisation par les usagers d’une locution verbale, c’est-à-dire d’une construction verbale à sens idiomatique qui ne correspond pas à l’union du sens des composantes qui forment cette LV, est une option qu’ils utilisent pour rehausser l’expressivité du contenu conceptuel qu’ils veulent transmettre. Ainsi, pendant une conversation, un locuteur, pour dire qu’une personne parle beaucoup, peut dire : a) Jean parle beaucoup ; b) Jean est très bavard ; c) Jean est un vrai moulin à paroles ; d) Jean [bavarde, cause, jase] comme une pie. Les images utilisées dans les exemples (c) et (d) pour désigner une personne très bavarde renforcent l’expressivité de la conversation grâce à des formules visuelles qui appuient les contenus conceptuels.
Si donc le message et le sens global d’un texte sont importants, un traducteur devra reproduire le plus fidèlement possible, en respectant dans la mesure du possible ces formes et les nuances stylistiques, culturelles, historiques, géographiques, etc. qui les caractérisent.
Se podría decir que la utilización de la estructura original, de la forma, de los mecanismos lingüísticos o estilísticos de un texto en otra lengua, no es sino una mera descodificación de todos los componentes que integran ese texto, pero todos esos detalles son los que permiten, a la hora de la verdad, cuando se trata de juzgar el grado de adecuación y de corrección de una traducción, el conseguir una traducción más o menos correcta, buena o perfecta.
Mogorrón 2002 : 79
Et nous sommes tout à fait d’accord avec Delisle (1993 : 390).
Le traducteur ne saurait par conséquent les bannir systématiquement de ses textes. Il en serait bien incapable, car les clichés, entendus au sens très large de formules figées, constituent l’humus, le fonds de la langue.
Il existe ainsi d’énormes quantités de LVS dans les systèmes phraséologiques de toutes les langues, mais la traduction de ces formes n’a été traitée exhaustivement ni par les dictionnaires ni par les linguistes. Le procédé traditionnel et pour ainsi dire universel, utilisé pour reproduire dans une autre langue une LV/SF, a consisté et consiste encore aujourd´hui soit à utiliser le dictionnaire bilingue puis à transcrire dans l’autre langue la forme proposée, si avec un peu de chance celle-ci était traitée, soit, si le traducteur avait une bonne, pour ne pas dire excellente, compétence phraséologique dans les deux langues, à mettre celle-ci à l’épreuve afin de trouver une forme plus ou moins équivalente dans l’autre langue. Nous insistons sur cette appréciation, « forme plus ou moins équivalente », car nous allons voir, en utilisant les deux bases de données en français et en espagnol[9], qu’il existe une multitude de situations et de possibilités qu’un bon traducteur ne peut connaître et contrôler mentalement à chaque occasion pour trouver la meilleure équivalence possible, étant donné la grande quantité d’informations qui caractérise ces séquences.
2.1. Traitement et traduction des LVS dans les dictionnaires
Le premier réflexe lorsqu’il y a une expression figée qui n’est pas de la compétence linguistique d’un usager, et encore plus s’il s’agit d’une langue étrangère, c’est de la rechercher dans un dictionnaire afin d’être capable de l’interpréter correctement et de pouvoir la traduire. Les nombreuses consultations de ce type nous ont permis alors d’observer que les LVS retenues sur contextes et recherchées sont fréquemment absentes de ces ouvrages. S’il y a donc très souvent impossibilité de consulter ces formes, les usagers d’une langue, les étudiants d’une langue étrangère ou les traducteurs éprouvent inévitablement un problème de compréhension.
Le deuxième réflexe, une fois la LV détectée et interprétée, c’est évidemment de la traduire dans la langue d’arrivée. Et là, l’ampleur du phénomène, les limitations physiques du support papier ainsi que celles des critères économiques et des compétences linguistiques des lexicographes qui participent à l’élaboration de ces ouvrages conduisent à une inévitable économie de la présence de ces formes dans les dictionnaires bilingues.
Pour démontrer l’insuffisance du traitement des formes figées dans ces ouvrages, nous utiliserons comme preuve à l’appui le traitement des LVS qui constituent notre inventaire dans deux dictionnaires bilingues espagnol-français/français-espagnol : El Gran Diccionario Larousse bilingüe dans son édition de 1999 et El Gran Diccionario Espasa dans son édition de 2000.
Nous avons vérifié la présence des LVS espagnoles de notre inventaire, dont le verbe commence par les lettres A, B ou C, c’est-à-dire 149 formes, dans ces deux dictionnaires bilingues. De ces 149 LVS, 61 LVS (qui équivalent à 41 %) apparaissent dans le LARBI et 34 (qui équivalent à 23 %) apparaissent dans le GDE. Finalement, de ces 149 LVS, seulement 18, c’est-à-dire 12 %, apparaissent à la fois dans les deux dictionnaires bilingues.
Les résultats de cette recherche nous montrent clairement que la proportion des LVS qui apparaissent dans les deux dictionnaires bilingues analysés est nettement insuffisante. Nous pouvons comprendre l’absence de certaines formes[10] :
trop orales, voire vulgaires, elles sont cependant utilisées couramment : Callarse como un muerto = (se taire comme un mort), callarse como una puta = (se taire comme une pute), cagarse en los muertos de = (chier sur les morts de qq’un), etc.
elles commencent à être incomprises parce que les références culturelles et les pratiques sociales, voire religieuses, sont en train de changer : adorar el becerro de oro = (adorer le veau d’or), cumplir con [la parroquia, con la iglesia]= (satisfaire aux préceptes religieux).
Nous ne comprenons pas l’absence de formes aujourd’hui standards et plus que courantes, qui sont très connues et utilisées par toutes les couches sociales de la population espagnole : No abrir el pico = (ne pas ouvrir le bec), asentir con la cabeza = (opiner [de la tête, du bonnet, du chef, du menton]), cambiar de disco = (changer de disque), calentarle a alguien la cabeza = (échauffer les oreilles à qq’un), etc. Mais ce n’est pas la seule déficience. En effet, pendant la recherche de ces formes, nous avons également pu observer dans les dictionnaires analysés :
un traitement insuffisant des régimes prépositionnels des LVS.
Tableau 1

un manque de rigueur dans le traitement des variantes paradigmatiques des LVS. Nous trouvons ainsi dans le GDE, irse por los cerros de Úbeda alors que dans notre inventaire nous avons [andarse, echarse, irse] por los cerros de úbeda.
Tableau 2

Si nous regardons maintenant les traductions des LVS qui apparaissent dans notre inventaire et dans les deux ouvrages analysés
Tableau 3
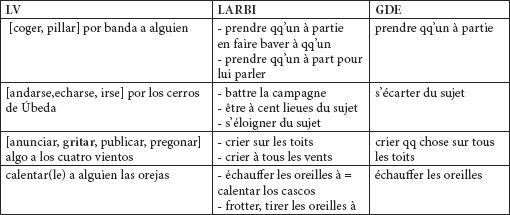
Nous observons immédiatement que le LARBI réalise un travail supérieur à l’autre dictionnaire car il propose souvent plusieurs équivalences de traduction, soit parce qu’il s’agit de parasynonymes, soit parce qu’il s’agit de LVS polysémiques. S’il est évidemment impossible qu’un dictionnaire bilingue propose pour chaque unité lexicale non figée ou figée toutes les traductions des situations connotatives possibles, il devrait au moins essayer de proposer plusieurs traductions ou correspondances référentielles.
2.2. La traduction des LVS dans la réalité
Mais qu’en est-il dans la réalité ? Les LVS sont-elles traduites ? Les traductions utilisées sont-elles correctes ou appropriées ? Pour répondre à ces questions, nous nous servirons d’exemples de séquences figées tirées de El Capitan Alatriste, de Pérez-Reverte (1996), ainsi que de sa traduction en français aux éditions du Seuil (1998) :
« […] y eso que Lope a tales alturas no necesitaba darle jabón a nadie. »
172« […] célèbre et adulé de tous, Lope de Vega n’avait cependant nul besoin de flatter personne. »
190« Era obvio que igual le daban dos que veinte ; heridos, muertos o en escabeche. »
45« À n’en pas douter, deux hommes ou vingt, blessés, morts ou à l’escabèche ne lui faisaient ni chaud ni froid. »
50« Eso de que una infanta de Castilla matrimonie con un príncipe anglicano les huele a azufre […] el valido no tiene intención de dar su visto bueno a la boda, […]. »
113« Qu’une infante de Castille épouse un prince anglican leur semble sentir le soufre […] le ministre n’a pas l’intention de donner son aval aux épousailles […]. »
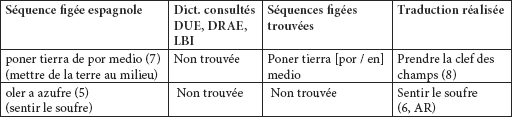
126« Así que no podía imaginar en nombre de qué pensaba ese pisaverde que iba a abrirle su corazón por las buenas. De todos modos a pesar del interés que sentía por averiguar qué carajo era todo aquello, el capitán empezó a pensar si no sería mejor poner tierra de por medio. »
91« À quoi pensait donc ce godelureau ? Qu’il allait lui ouvrir son coeur pour ces beaux yeux ? Et malgré son envie de savoir ce que recelait toute cette affaire, le capitaine commença à songer qu’il serait peut-être préférable de prendre la clef des champs. ».
100« […] pero ese oro y esa plata se perdían en manos de la aristocracia, el funcionariado y el clero, perezosos, maleados e improductivos, y se derrochaban en vanas empresas como mantener la costosa guerra reanudada en Flandes, donde poner una pica, o sea, un nuevo piquero o soldado, costaba un ojo de la cara. »
65« Mais cet or et cet argent se perdaient entre les mains de l’aristocratie, des fonctionnaires et du clergé, paresseux, corrompus et oisifs. On les gaspillait en vaines entreprises comme cette nouvelle et coûteuse guerre de Flandre où l’entretien du moindre piquiercoûtait une fortune. »
72
Ces extraits en espagnol et leur traduction en français nous permettent de faire les observations suivantes :
des séquences figées qui apparaissent dans les dictionnaires monolingues et bilingues :
Tableau 4

des séquences figées qui n’apparaissent pas dans les dictionnaires monolingues et bilingues :
Tableau 5
-
des séquences figées qui ne sont pas traduites en français par une autre séquence figée mais par une unité lexicale simple ou par une périphrase verbale.
Ex : darle jabón a (1) est traduit par flatter, alors qu’il existe en français de nombreuses séquences figées ayant ce sens :
Tableau 6

des séquences figées déformées qui n’apparaissent pas avec leur forme canonique, ce qui rend difficile leur localisation et leur compréhension pour de nombreuses personnes :
Tableau 7

3. Compréhension et classification des LVS/SFS
La présence/l’absence de ces formes dans les dictionnaires ; les solutions parfois adoptées et utilisées par les dictionnaires bilingues pour leur(s) traduction(s) possible(s), qui se limitent généralement à donner une seule forme équivalente sans fournir pour les deux langues en jeu une définition des séquences figées utilisées ; le traitement plus qu’insuffisant donné aux formes dans les deux langues ; les traductions ou les solutions adoptées dans les exemples ci-dessus ; tout cela pose de nombreux problèmes.
La première observation qui surgit est qu’avant de pouvoir se lancer dans la traduction des LVS/SFS, le traducteur devrait pouvoir les reconnaître (grâce à sa propre compétence phraséologique), et les comprendre, ou bien, disposer d’un outil lexicographique qui lui permettrait de connaître pour chaque LV les différentes possibilités qu’il y a dans l’autre langue ainsi que disposer de toutes les informations nécessaires à leur bonne utilisation.
Mais comment élaborer, mettre en oeuvre cet ouvrage lexicographique, et surtout classer les LVS, en évitant de reproduire les mêmes erreurs que nous venons de constater et de dénoncer ? Devons-nous suivre une classification alphabétique, sémasiologique, qui part du signifiant pour arriver au signifié ou bien devons-nous suivre une classification onomasiologique qui partirait du sens ? Ainsi, Lakoff (1987) soulignait l’énorme importance que revêt pour la phraséologie et la traduction le fait que de nombreuses séquences figées sont des signes motivés.
3.1. Analyse et classement sémantique
Les dictionnaires ont généralement suivi une classification alphabétique pour ordonner et présenter les éléments sélectionnés, en s’appuyant sur l’objectivité et l’impartialité de ce critère face à la possible subjectivité des classifications extralinguistiques. Pourtant, de nombreux linguistes étaient conscients de la nécessité de compléter ce procédé avec des systèmes de renvois conceptuels. Quelques auteurs classiques (Comenius, Francis Bacon) avaient déjà réalisé des tentatives de classification onomasiologique qui n’avaient pas eu de succès car elles impliquaient, d’une part, un travail de catalogage et de classification très laborieux, que certains pourront traiter de subjectif, et, d’autre part, un travail de recherche et de consultation plus lent que la classification alphabétique.
L’apparition et le développement de l’informatique, des dictionnaires électroniques et de leurs multiples applications et possibilités font disparaître ces inconvénients. Car toute langue est en fait un système linguistique de communication qui organise et représente le monde à travers des structures grammaticales et des systèmes lexicaux plus ou moins semblables, selon leur degré de proximité linguistique et culturelle. Or, puisque le passage d’une langue à une autre, c’est-à-dire la traduction, est cependant généralement possible, c’est probablement parce que certains concepts trouvent une représentation lexicale dans toutes les langues. Il existe en effet, des réalités extralinguistiques communes à tous les êtres humains. Mais le grand problème, c’est que les réalités, les univers communs peuvent se découper et se représenter plus ou moins similairement ou différemment selon les langues comparées. En effet, pourquoi des langues si diverses devraient-elles être réduites à des microlangages isomorphiques, avec le même lexique et les mêmes structures ?
Sur le plan conceptuel, les SF sont généralement considérées comme ce qu’il y a de plus propre à une langue parce que le parcours suivi par chaque séquence traduit en quelque sorte certains systèmes de pensée de la collectivité. Si le figement en tant que processus est un phénomène universel impliquant les mêmes mécanismes linguistiques et plusieurs caractéristiques communes telles que la polylexicalité, la globalisation, la conceptualisation, la figuration, […] il donne lieu dans chaque langue à des SF propres car les transferts de domaine et les sélections sémiques sont rarement les mêmes.
Mejri 2000 : 605
Pour faciliter la compréhension notionnelle et la meilleure traduction possible des séquences figées, le premier pas consiste inévitablement à réaliser une classification de mots sémantiquement apparentés qui va regrouper les LVS en champs lexicaux-phraséologiques[11], afin d’élaborer pour les différentes langues des listes exhaustives des formes figées à comparer et à traduire. Une base de données avec une classification thématique exhaustive. Dans ces champs, chaque expression va être analysée d’abord syntaxiquement dans l’optique du lexique-grammaire, et articulée de façon rigoureuse en sous classes, en tenant compte, d’après M. Prandi (1998) de leur pertinence relationnelle[12]. La classification par champs et sous classes implique la systématisation et la caractérisation des différentes valeurs et emplois des expressions analysées à travers ces classes sémantiques. Cela donnera la possibilité de disposer d’une information très systématisée qui permettra de trouver rapidement, grâce à des descripteurs et aux définitions, les éléments que nous recherchons d’après leur sens, d’établir et de déterminer clairement des relations de polysémie, d’antonymie, d’hyponymie, de synonymie qui vont à leur tour être très importantes pour pouvoir trouver la LV ou l’expression figée qui sera la meilleure équivalence en traduction. Ce genre de classification implique un énorme effort d’analyse et de classification des unités sélectionnées dans la même optique de classification et de description syntaxique et sémantique entreprises par le LLI[13]. Les descripteurs, les situations référentielles des LVS devront être très bien délimités pendant toute la durée de l’élaboration du dictionnaire électronique, et de la catalogation des LVS pour ne pas commettre des erreurs ou des contradictions comme nous explique Pamies (1998 : 208) :
El primer peligro procede de la sinonimia entre descriptores : p. ej., el lexicógrafo puede asignar en un momento dado el descriptor DINERO a un refrán como lo barato sale caro, ¿pero qué garantía tenemos de que el usuario no pregunte por COMERCIO ? Tampoco hay garantías de que el mismo lexicógrafo asigne unos meses más tarde el descriptor ECONOMÍA o incluso AVARICIA a un duro es un duro, con lo cual ambas expresiones quedarían desconectadas para siempre en el pozo sin fondo de la base de datos.
La délimitation de ces situations dans les champs sémantiques devrait suivre le même principe que celui utilisé par le LLI pour la délimitation des classes d’objets :
Il faut alors, pour délimiter une classe d’objets, recourrir à la conjonction de plusieurs critères (comme on le fait pour les phonèmes) : deux ou trois verbes suffisent souvent pour constituer une sorte de « gerbe » ou de « faisceau » définitionnel.
Le Pesant et Mathieu-Colas 1998 : 13
Pour l’objectif que nous avons énoncé, c’est-à-dire la compréhension et la traduction des LVS des actes de parole en espagnol et en français, la classification des LVS qui appartiennent à ce champ lexical va ainsi faciliter à une grande majorité d’utilisateurs de la langue, entre autres possibilités, la compréhension globale du champ lexical analysé ; l’usage d’un outil qui permettra par la suite de réaliser toutes les comparaisons et les recherches pertinentes ; finalement la possibilité de disposer sur-le-champ des séquences, de leur correspondance/équivalence dans l’autre langue ; et celle d’observer les coïncidences conceptuelles et les cas où l’autre langue ne dispose pas de séquence pour représenter un concept déterminé. La classification de ces actes de parole devra donc spécifier avec des descripteurs et des définitions pour chaque LV le genre de situation référencielle et conceptuelle. Par exemple :
-
Parler :
parler avec qq’un : bavarder, discuter, négocier
être une personne qui aime parler / qui n’aime pas parler beaucoup
répéter qqch
-
Parler en tant qu’activité physique
Avoir une prononciation défectueuse
Avoir une petite voix
Avoir une grosse voix
Parler haut
Parler bas
Crier
Se taire
-
Tenir des propos favorables à l’égard de qq’un
Féliciter, louer, flatter, glorifier, défendre qq’un verbalement, etc.
-
Tenir des propos défavorables à l’égard de qq’un
Critiquer, faire des remarques
Faire des attaques verbales (réprimander, se moquer de, menacer, etc.)
Il faudrait également tenir compte, dans ces classifications, entre autres des situations qui font référence à des (félicitations, accusations, observations, réprobations, ordres, insultes, affirmations, souhaits, remerciements, excuses, vérités, promesses, sentiments, etc.).
Exemple de classification par champs lexicaux-phraséologiques qui permettra en même temps de réaliser grâce à l’informatique une classification onomasiologique.
Tableau 8

Mais nous avons vu le traitement plus qu’insuffisant donné aux formes dans les deux langues, qui se contente de reproduire partiellement les formes figées sans donner leur extension maximale, leur(s) régime(s) prépositionnel(s), les variations paradigmatiques possibles, d’où la difficulté pour les traducteurs et les étudiants étrangers de les connaître entièrement, ce qui occasionne des erreurs syntaxiques. La solution pour résoudre ces problèmes implique donc obligatoirement l’élaboration pour les différentes langues de listes exhaustives des formes figées à comparer et à traduire, qui puissent remplir les vides constatés dans les ouvrages de consultation. Pour que ces listes soient vraiment exhaustives, il faudrait réaliser au moins une triple recherche.
D’abord dans les dictionnaires monolingues et bilingues, utilisés pour constituer l’inventaire. La comparaison des LVS trouvées dans ces ouvrages, qui incorporent un nombre d’expressions communes, mais aussi beaucoup de formes qui n’apparaissent pas dans les autres, est très utile.
Ensuite, il faudrait également incorporer toutes les formes couramment utilisées dans la langue orale, la presse quotidienne, et qui n’ont pas été incorporées à ces dictionnaires, ou qui ne le seront jamais si ces formes connaissent une vie active courte[14]. Mais il faudrait aussi incorporer toutes les LVS/SFS vieillies, considérées comme littéraires, appartenant à la langue écrite, parce que les traducteurs pourraient, qui sait, avoir maille à partir avec elles.
Finalement, la troisième consisterait à effectuer des recherches informatisées sur les nombreux corpus existants, par exemple FRANTEXT, pour le français, CORDE pour l’espagnol, etc., afin de pouvoir vérifier l’utilisation réelle de ces formes et si elles présentent des variations ou des variantes paradigmatiques non recueillies par les dictionnaires.
3.2. Classification syntaxique
Les LVS seront incorporées en tenant compte de leur extension maximale, de leur(s) régime(s) prépositionnel(s), des variations paradigmatiques possibles. De la même façon, afin de pouvoir tirer des conclusions sur les différentes langues analysées, chaque LV sera classée selon sa structure syntaxique et les propriétés distributionnelles qui la caractériseront. Les principes de classification suivis seront ceux que M. Gross et le LADL[15] ont utilisés pour l’élaboration d’un lexique-grammaire des phrases simples du français.
Nous avons trouvé dans les deux langues les résultats suivants :
Tableau 9

Du point de vue syntaxique, nous observons que les structures des expressions figées spatiales qui forment le corpus sont tout à fait régulières car elles coïncident exactement avec les combinaisons du discours libre. Il n’a été trouvé en effet aucun exemple avec une combinaison irrégulière ou inacceptable dans les deux langues. Nous observons également que les deux langues utilisent généralement les mêmes structures[16] :
Exemple de liste alphabétique d’expressions figées en français, exemple tiré du dictionnaire électronique des expressions figées de M. Gross.
Tableau 10

Exemples espagnols
Tableau 11

Cette méthode d’analyse (de type distributionnel et transformationnel) permet de distinguer les différents comportements et constructions syntaxiques d’une expression figée en permettant l’utilisation correcte de ces séquences figées dans des contextes beaucoup plus amples des langues analysées, et de réaliser des applications contrastives approfondies grâce à toutes les informations qu’elle met à la disposition des usagers, contrairement aux dictionnaires bilingues classiques qui se limitent à présenter de simples équivalences traductologiques.
4. Correspondances entre les formes figées de deux ou plusieurs langues
Avec l’inventaire correctement classifié, les étapes que tout traducteur devrait suivre pour une traduction correcte de ces formes, sont les suivants : identification et compréhension, puis recherche de correspondances. Nous sommes conscient que la traduction de ces formes devrait être envisagée non pas isolément, mais à l’intérieur du texte, et du contexte présent dans le texte, et qu’on ne devrait pas établir de correspondances de façon automatique. Mais il est également vrai que l’on peut et que l’on doit parler de nombreux parallélismes conceptuels et référentiels entre les systèmes phraséoloqiques d’une grande quantité de langues[17]. Nous avons vu que les LVS étaient des formes figées qui s’utilisaient dans les mêmes situations discursives de communication et que ces situations conceptuelles existaient généralement dans les différentes langues. Ainsi donc, la première tâche à réaliser consisterait à définir ces situations discursives afin de pouvoir proposer aux traducteurs, et à un niveau microtextuel pour chaque situation référentielle possible, la ou les correspondances utilisées par l’autre langue. Puis, finalement, de trouver la meilleure correspondance pour le niveau macrotextuel.
Le nombre de LVS qui n’ont pas de correspondant conceptuel figé dans nos deux inventaires est inférieur à 8 %[18], c’est le cas par exemple pour les expressions françaises avoir un boeuf sur la langue (se taire après avoir reçu de l’argent), avoir un cheveu sur la langue (avoir un petit défaut de prononciation) qui doivent donc se traduire dans l’autre langue par des paraphrases verbales.
Avoir un boeuf sur la langue = « callarse debido a un soborno ».
Avoir un cheveu sur la langue = « tener un defecto de pronunciación, cecear, ser sopitas ».
En espagnol, nous aurions la même situation avec par exemple colgarle un sambenito a alguien ; (attacher un saint Benoît à qq’un) qui se traduirait en français par la paraphrase suivante : (faire, donner mauvaise réputation à qq’un).
On va trouver des correspondances pour la plupart des LVS et des SFS de l’espagnol et du français (ainsi d’ailleurs que de l’immense majorité des langues). Mais ici, il faut distinguer très clairement les cas pour lesquels il n’existe dans l’autre langue qu’une seule LV de ceux dans lesquels il y en a plusieurs. Ex :une seule LV dans les deux langues
Tableau 12

Plusieurs LVS pour représenter la même situation conceptuelle.
Nous avons trouvé ici :
-
des LVS qui permettent des variations paradigmatiques. Ainsi, en espagnol, sur les 973 LVS de notre inventaire, nous avons trouvé plus de 510 LVS dans lesquelles il y avait dans une position donnée une possibilité de paradigme[19]. Soit
d’un verbe : [alzar, levantar] el gallo (lever, hausser le coq) = hausser la voix, le ton contre, [cerrar, sellar] los labios de (fermer, sceller les lèvres de) = sceller les lèvres de ;
d’une préposition : hablar [con la nariz, por la nariz] (parler avec) par le nez) = parler du nez ;
d’un déterminant : limar [asperezas, las asperezas] (limer les rugosités) = arrondir les angles ;
d’un substantif : arrastrar [por el fango, por los suelos] (traîner par la boue, par terre) = traîner dans la boue.
des situations conceptuelles qui sont reproduites dans les deux langues par plus d’une LV à structures et composantes différentes. Ici, il est possible de trouver un continuum de cas qui pourront aller de situations avec deux ou trois LVS synonymes ou parasynonymes. Ex. :
Tableau 13

jusqu’à plusieurs dizaines de parasynonymes. C’est le cas par ex. des LVS utilisées en espagnol et en français pour dire qu’une personne est bavarde, qu’elle aime beaucoup parler. Ex. :
Tableau 14
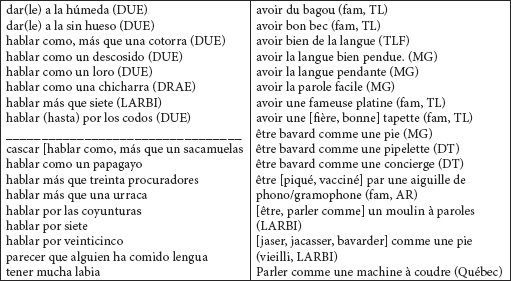
Comment traduire ces différentes situations de correspondances de LVS[20] en espagnol et en français ? Il faut évidemment séparer les cas où il n’y a pas d’équivalent figé dans l’autre langue, ce qui revient à dire qu’il y aura une correspondance nulle entre les systèmes phraséologiques, de ceux dans lesquels il y aura des correspondances de LVS entre les deux systèmes conceptuels (Zuluaga 1980 ; Corpas 2003 ; Mogorrón 2002).
Mais avant de nous lancer dans cette aventure, la lecture du tableau précédent nous conduit inévitablement à nous poser la question suivante : Laquelle de toutes ces séquences figées est la meilleure correspondance dans l’autre langue ? Nous observons qu’il y a des LVS qui sont totalement similaires, d’autres qui présentent des variations dans leur structure, certaines LVS qui utilisent le même lexique, d’autres qui utilisent les mêmes images et des mots totalement différents. Beaucoup de possibilités dont il faudra cependant tenir compte pour le propos que nous recherchons. La première sélection qui va s’effectuer pour trouver une correspondance se fera en fonction de la structure syntaxique et du lexique présent dans chaque LV, car bien sûr cette correspondance passe à la fois par le sens mais aussi par la structure et le lexique. Pour cela nous utiliserons donc les classes syntaxiques que nous avons déjà constituées.
4.1
Lorsqu’il n’y a pas de correspondance conceptuelle figée, nous aurons alors un cas de correspondance nulle. Il faudra, comme nous a dit Jakobson (1958-1959), reproduire le sens grâce à des emprunts, calques, traductions littérales, néologismes, paraphrases. Cependant, si nous observons les exemples que nous avons donnés, nous pouvons observer qu’il s’agit de séquences figées qui font référence à des aspects historiques, culturels ou toponymiques propres à chaque communauté culturelle linguistique. Il y a en effet des réalités socioculturelles propres à chaque communauté linguistique qui ne vont pas trouver de correspondants conceptuels figés dans la langue cible. Ex. :
Tableau 15

La meilleure traduction possible, dans les cas où nous n’avons pas trouvé de LV pour une situation semblable dans l’autre langue, serait de la traduire et de l’expliquer par une paraphrase verbale, car les calques et les traductions littérales nous semblent des tentatives de reproduire trop directement des aspects culturels, historiques qui n’ont souvent aucune relation avec l’autre langue et dans ces cas avec l’autre culture, d’où le rejet évident qui se produirait généralement par l’autre communauté culturelle et/ou linguistique.
4.2
Pour le deuxième cas, c’est-à-dire lorsqu’ il y a un ou des équivalents conceptuels figés dans la langue d’arrivée, nous allons trouver deux cas possibles de correspondances : correspondance totale entre les deux systèmes linguistiques impliqués et correspondance partielle.
Pour pouvoir établir ces cas de correspondance totale et partielle, il faudrait analyser encore une fois exhaustivement les structures que nous voulons comparer et traduire, afin d’être sûr que la séquence figée que nous comparons est la séquence correcte, syntaxiquement parlant.
4.2.1
Nous aurons une correspondance totale lorsqu’il y aura deux LVS ou SFS qui présenteront une forme totalement identique, avec la même structure (isomorphisme syntaxique) et les mêmes mots pleins[21] (isomorphisme lexical). Ce genre d’expression pourra être dû soit à une origine métaphorique commune, soit à une origine culturelle commune, soit à une assimilation de la SF d’une langue par une autre langue, etc. [22]
Tableau 16

Évidemment, c’est la situation idéale pour les traducteurs, lorsqu’il est possible de passer une LV, ou une SF, d’une langue à une autre, car il existe alors une correspondance totale sur le plan conceptuel et formel. Mais, malheureusement, ce n’est pas la situation la plus fréquente. Dans plusieurs études de ce genre que nous avons réalisées, nous avons recensé 10 % de cas de « la expresividad en las locuciones verbales » (2202), 12 % de locutions verbales spatiales (2003) et 15 % de locutions somatiques (2004).
Beaucoup de traducteurs ou de lecteurs lorsqu’ils essaient de donner un sens à un texte en langue étrangère, étant donné la symétrie des mots, des structures, les transparences relatives à première vue entre les deux systèmes linguistiques en jeu, s’appuient, lors de la phase de reconnaissance des formes, d’abord sur ces similitudes de forme pour élaborer une première hypothèse. Procédé qui peut conduire à une bonne compréhension et une traduction correcte, (revoir Tableau 14), mais qui peut également produire une interprétation erronée (voir Tableau 15).
Tableau 17

4.2.2
Entre les cas de correspondance totale et de correspondance nulle, il y aura également dans les deux langues toute une série de LVS qui représenteront le même concept mais avec des différences partielles dans la forme et/ou dans l’image représentationnelle.
4.2.2.1
Nous pourrons ainsi avoir de petites différences structurelles et formelles dans les deux langues.
Nous avons trouvé dans les deux langues des LVS qui présentent une très légère différence quant à leurs formes dues à des caractéristiques naturelles inhérentes à chaque langue. Ainsi, la différence qui existe entre les LVS des deux langues sera par exemple un déterminant défini en espagnol et un possessif en français :
Tableau 18

ou bien des différences dans les régimes prépositionnels des deux langues :
Tableau 19
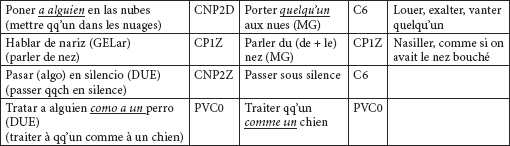
Les situations des tableaux 16 et 17 sont celles qui présentent le plus de difficultés pour les traducteurs et pour les apprenants d’une langue étrangère. Ces différences, qui sont presque inappréciables, causent justement, par cette « quasi- » symétrie, de nombreuses erreurs syntaxiques, car sachant que la forme de l’autre langue est quasiment similaire, ils s’appuient sur la forme de leur langue maternelle qu’ils essaient de reproduire inconsciemment ou par étourderie.
4.2.2.2. Des différences structurelles appréciables mais les mêmes mots pleins
Nous avons trouvé des LVS qui présentent des différences appréciables dans leurs structures. Nous pouvons encore apprécier une origine conceptuelle commune entre ces SFS grâce aux mots pleins qui sont présents et qui sont ceux qui leur confèrent réellement leur sens. Ex. :
Tableau 20
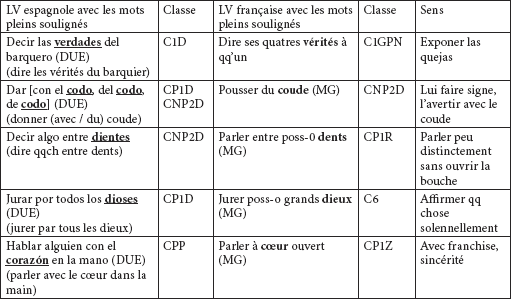
4.2.2.3. Des différences structurelles et des mots pleins différents
Parmi les LVS qui n’utilisent plus dans les deux langues analysées ni les mêmes structures ni les mêmes mots pleins qui conféraient un sens à ces séquences, nous avons trouvé deux groupes de correspondances.
4.2.2.3.1. Différence syntaxique et structurelle nulle mais correspondance expressive
Les LVS, malgré leur apparente différence représentationnelle, présentent cependant une similitude expressive. Elles ont effectivement une image très similaire dans les deux langues qui élimine les différences formelles et qui établit entre les LVS des deux langues des liens dont il faudra tenir compte lors de la recherche de la meilleure équivalence entre les deux langues.
Tableau 21
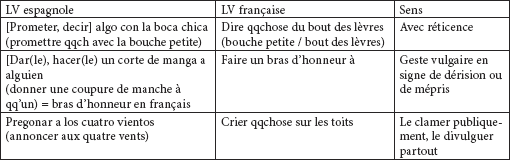
4.2.2.3.2. Différences syntaxiques et structurelles et images différentes
Il n’existe dans les origines conceptuelles qui s’établissent entre ce genre de LVS plus aucune correspondance. Il n’y a alors que le sens qui nous permet de savoir que ces LVS s’utilisent pour représenter la même situation dans les deux langues.
Tableau 22

5. Traduction des correspondances figées
Nous venons de voir les différentes possibilités de correspondances formelles et structurelles qui existent entre les LVS de deux langues analysées, à un niveau microtextuel. Bien évidemment, les cas où il n’y aura qu’une forme conceptuelle pour représenter une situation déterminée vont poser beaucoup moins de problèmes au traducteur. L’acte de correspondance va alors se limiter à observer que la relation qui existe entre les deux LVS des deux langues correspondra à tel ou tel genre de correspondance :
Tableau 23
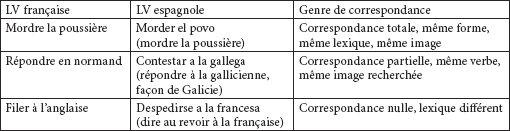
Par contre, les cas avec au moins deux LVS qui représentent le même concept dans une des langues vont poser davantage de problèmes, car il va falloir réaliser une sélection à partir d’une analyse des différentes formes qui reproduisent le même sens. Pour cela, le traducteur devra se livrer non plus seulement à un exercice de traduction et de recherche de correspondances, mais également à un exercice de recherche lexicologique et phraséologique contrastive afin de pouvoir établir et prévoir les possibles similitudes, correspondances et divergences de sens qui existent entre ces formes dans la langue d’origine et la langue cible.
La LV espagnole hablar por los codos a plusieurs synonymes en espagnol, ainsi que la possibilité d’avoir plusieurs correspondances en français :
Tableau 24

Mais, ces LVS sont-elles vraiment synonymes, voire parasynonymes, qu’est-ce qui les différentie ? Laquelle de ces formes va être la meilleure ?
Si une traduction est le passage des structures, des lexèmes ainsi que du ou des sens possibles d’un texte ou d’un discours d’une langue à une autre langue, nous pourrions penser qu’une fois les LVS sélectionnées par leur sens référentiel, la solution pour les cas ou la possibilité existe consistera à sélectionner, et toujours dans le même ordre, dans l’autre langue :
d’abord une LV/SF qui aura une correspondance totale avec les mêmes structures :
Tener la lengua larga (avoir la langue longue) = Avoir la langue pendante
Tener la palabra fácil (avoir la parole facile) = Avoir la parole facile
ensuite une correspondance partielle avec, les mêmes mots pleins :
Ser de palabra fácil ; (être de parole facile) = avoir la parole facile
ou bien les même images référentielles :
Hablar como un loro (parler comme un perroquet), hablar como, más que una cotorra (perruche) = Être bavard comme une pie ; jacasser comme une pie ; être bavard comme une pipelette.
Mais cette solution ne laisse voir que la pointe de l’iceberg, car en effet c’est aller un peu vite en besogne que de limiter la traduction à ces niveaux de correspondance.
Même s’il sera toujours préférable de traduire une LV/SF par une autre LV/SF dans la langue d’arrivée, cette possible correspondance n’implique pas automatiquement que le degré d’équivalence est le même, car la comparaison de deux langues proches ou lointaines et la traduction de l’une vers l’autre doivent également tenir compte d’autres éléments présents dans tout système linguistique. En effet, à part leur sens référentiel, toutes les LVS/SFS ont aussi un sens connotatif qui enrichit et nuance ce sens référentiel à travers les propriétés diasystématiques[23] (Blanco 2001) et dont il faudra tenir compte pour une bonne utilisation et une interprétation correcte, et donc aussi pour la recherche de la meilleure correspondance microtextuelle puis macrotextuelle. Pour chaque LV, il faudra vérifier ainsi des propriétés caractéristiques et inhérentes à chacune d’entre elles comme les niveaux de langue, les usages régionaux, générationnels et la fréquence d’usage, etc.
Il faudrait donc inclure dans le tableau précédent, pour les correspondances que nous venons de proposer, les marques de niveaux de langues trouvées dans les ouvrages consultés[24]
Tableau 25

Est-ce que les possibilités de correspondance que nous venons de compléter sont alors les mêmes ? Pour avoir bien de la langue, qui est caractérisée par le registre vieilli, la correspondance n’est plus alors aussi évidente.
De même pour la série (para)synonymiquem nous aurions alors :
Tableau 26

Nous remarquons qu’il faudrait obligatoirement voir, lors de la recherche de correspondances entre les LVS espagnoles et françaises, si elles appartiennent à un registre de langue (diastratique), ou si elles sont utilisées dans une certaine zone géographique comme régionalismes ou par l’influence d’une langue régionale (diatopique).
La classification traditionnelle envisage pour les registres de langue les possibilités suivantes : cultivé/littéraire, standard, populaire, familier (parfois on trouve également coloquial), vulgaire. Nous ne voulons pas entrer ici dans une discussion théorique, mais, il existe trop souvent une telle confusion à ce sujet qu’il est difficile de déterminer à quel niveau de langue appartiennent les unités lexicales libres et les figées. La confusion se produit généralement dans le cas des locutions avec des connotations considérées comme basses, car les limites entre ces niveaux de langue ne sont pas aussi clairement définies qu’entre les précédents. Ce qui, pour certains, est familier peut, pour d’autres, être populaire, ou ce qui pour une personne est vulgaire ne l’est peut-être pas pour une autre. De plus, face à l’immutabilité des critères antérieurs, nous trouvons le caractère créatif, évolutif et assimilateur de la langue qui finit par intégrer et faire siennes de nombreuses créations de groupes marginaux. De cette façon, ce qui aujourd’hui est considéré comme vulgaire ou argotique peut ne plus l’être dans quelques années.
Ainsi fermer sa boîte appartient au registre familier pour AR et au registre vulgaire pour le Larousse. Cantarlas claras (les chanter claires) = ne pas mâcher ses mots est familier pour le Larousse bilingue tandis que le DUE et le DRAE ne nous donnent pas d’information à ce sujet. Faut-il considérer alors que cette LV a un registre standard ?
Afin d’éviter ce genre de situations équivoques pour les usagers d’une langue et problématiques pour les traducteurs, nous pensons qu’il serait raisonnable afin d’éviter de nouvelles équivoques et divergences d’interprétations, qui surgiraient généralement entre les niveaux 3 et 4, de réduire les niveaux de registre de langue en laissant par exemple : 1. soutenu (littéraire cultivé) ; 2. standard ; 3. familier, populaire, coloquial ; 4. vulgaire, voir à la classification proposée par X. Blanco ci-dessus : soutenu, familier, vulgaire[25].
Pour vérifier le traitement donné par les dictionnaires à ces registres de langue et afin de nous assurer de la possibilité d’utiliser ces valeurs ou connotations lors de la traduction, nous avons analysé la série (para)synonymique de bavard en vérifiant en espagnol la présence de ces LVS dans les deux dictionnaires les plus connus et utilisés, le DUE et le DRAE ; et de même en français, nous avons utilisé les dictionnaires Le Petit Robert (PR) et le Larousse (L). Nous avons vérifié pour chaque LV si elle apparaissait dans ces dictionnaires (premier signe marqué positivement ou négativement) et si ces derniers fournissaient un registre de langue (deuxième signe marqué positivement ou négativement). Cette analyse fournit les résultats suivants.
Tableau 27
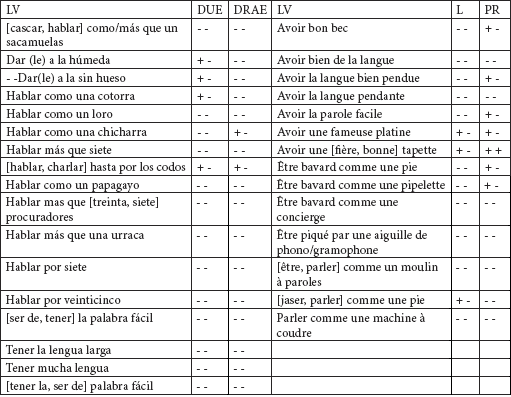
Nous voyons avec ces résultats que la difficulté majeure pour les usagers d’une langue qui consultent les dictionnaires n’est autre que la non inclusion des LVS/SFS dans les dictionnaires et pour le cas ou ceux-ci les incluent, le traitement très insuffisant accordé aux marques diastratiques. D’un autre côté, il ne faut pas oublier non plus la divergence de classification qui peut apparaître dans différents dictionnaires. Ainsi, en espagnol, hablar por los codos est classée comme coloquiale par le DRAE et ne reçoit aucun niveau de langue dans les DUE, LARBI, DT. Est-ce qu’ils la considèrent comme standard ?
Il s’agit donc de deux problèmes difficiles à résoudre afin de pouvoir appliquer cette information lors de la traduction.
Si, toujours avec la même série (para)synonymique, nous essayons d’utiliser les nouvelles technologies et de chercher à trouver comme correspondants de traduction les LVS/SFS les plus utilisées dans chaque langue, nous allons trouver les résultats suivants pour l’espagnol :
Tableau 28
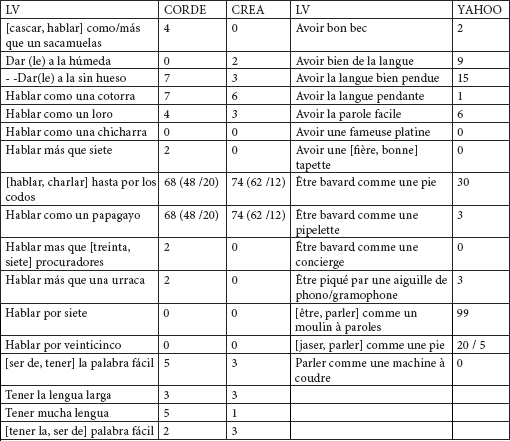
Que faire avec ces résultats, comment les utiliser ? Si nous reprenons les premières tentatives de traduction par correspondances structurelles et lexiques (page 20) et que nous ajoutons ces résultats, nous aurons alors :
Tableau 29

Avec ces résultats, nous voyons que les LVS (para)synonymes les plus utilisées sont en espagnol [hablar, charlar] hasta por los codos avec 99 contextes trouvés et en français [être, parler] comme un moulin à paroles, avec 142 contextes trouvés. Nous observons d’après les résultats des fréquences d’apparition, qu’avec ce groupe de LVS la possibilité idéale de traduction par correspondance totale ne fonctionne pas parce que si nous cherchions à mettre en correspondances les LVS les plus utilisées, la correspondance que nous devrions établir serait :
Parler, être comme un moulin à paroles
hablar por los codos
et non pas :
Tener la palabra fácil ; (5) / Avoir la parole facile (6).
Que faire donc, quelle solution adopter, si pour trouver la correspondance exacte, il faut tenir compte :
de la correspondance conceptuelle
de la correspondance formelle
de la correspondance totale
de la correspondance partielle
des mêmes mots pleins sans correspondance formelle.
des mots pleins différents, mais avec la même image ;
des mots pleins différents avec des images différentes ;
-
du sens connotatif, avec au moins les critères suivants qui méritent d’être considérés :
le niveau de langage ;
la fréquence d’apparition dans les corpus consultés ;
les valeurs diatopiques : régionalismes, américanismes, francophonismes, etc.
Aucune traduction ne pourra égaler l’original dans l’autre langue. Car elle ne pourra pas rendre dans la langue d’arrivée toutes les valeurs, tous les effets stylistiques, toutes les informations et spécifications des valeurs dissystématiques qui accompagnent les mots et les textes dans la langue de départ. Avec les LVS/SFS, nous avons vu que pendant de nombreuses années les dictionnaires (monolingues et bilingues) les ont non marginalisées mais ignorées faute de moyens économiques, de compétence langagière, etc., mais nous avons également vu qu’il existe de plus en plus de moyens qui permettent leur connaissance, leur correcte interprétation et recherche dans des contextes et donc facilitent de plus en plus leur possible traduction en recherchant leur correspondance dans la langue d’arrivée ainsi que la LV la plus équivalente qui réunira un maximum de ressemblances conceptuelles, formelles, lexicales, diasystématiques avec la langue de départ[26]. Nous n’en sommes encore qu’au tout début de l’exploitation des énormes possibilités que nous offrent les nouvelles technologies, mais nous pensons que l’heure est venue de mettre la main à la pâte, voire à l’ouvrage, afin d’avancer non sans efforts dans la réalisation de grands dictionnaires électroniques qui mettront à la portée de la main des usagers, étudiants et traducteurs d’énormes ressources et leur faciliteront de nombreuses tâches qui de nos jours nécessitent souvent d’abondantes manipulations et consultations pour essayer de trouver l’équivalence la plus proche.
Même si nous sommes également conscient que la traduction, la correspondance, enfin l’équivalence parfaite et totale entre deux SFS/LVS sera pratiquement impossible, il faudra pour obtenir des résultats, non pas satisfaisants, mais fiables, basés sur des analyses contrastives et des recherches de correspondances qui s’appuient sur la description des faits linguistiques, inclure dans notre dictionnaire électronique plusieurs colonnes d’encodages complémentaires qui agiront comme filtres lors de la recherche de la meilleure correspondance possible[27]. Cette solution, qui ne peut s’appliquer qu’avec le concours des ressources informatiques, permettra alors, après une analyse plus qu’exhaustive, de posséder, pour chaque LV, une grille avec toutes ses caractéristiques qui fera en sorte qu’il sera possible de savoir, grâce aux supports informatiques, si telle LV est fréquente, rare, si elle a une correspondance conceptuelle et formelle, ou simplement conceptuelle, s’il s’agit d’une LV utilisée dans une région d’un pays ou dans un autre pays où se parle la même langue.
parler comme une machine à coudre (Québec)
echar alguien agua al molino (Guatemala) = dire des vérités désagréables.
Un traducteur devrait pouvoir à l’avenir connaître ces caractéristiques. S’il faut traduire en français un texte, un ouvrage littéraire d’Amérique du Sud, ou bien en espagnol un roman de l’Afrique francophone, combien de séquences figées seront différentes, combien ne seront pas incluses dans les dictionnaires généraux utilisés généralement par les traducteurs et les usagers d’une langue ?
Les dictionnaires ne pouvaient inclure toutes ces informations et ces correspondances et ont laissé ou laissent encore trop de lexèmes libres ou figés, trop d’informations non traitées. Nous sommes conscient de ces décalages, et les dictionnaires électroniques peuvent aujourd’hui enfin commencer à traiter et à inclure toutes ces informations. Nous ne sommes pas encore arrivés au bout de nos peines et il y a devant nous de longues années de travail afin de systématiser toutes ces caractéristiques propres à chaque LV/SF. Certains pourraient dire qu’avec toutes ces applications informatiques, nous n’avons fait que compliquer le tout, et qu’ils s’en tiraient fort bien en prenant l’équivalence qui apparaissait dans les dictionnaires bilingues. Mais que cette méthode était insuffisante et limitée ! Il s’agissait en fait de trouver une solution rapidement en parant au plus pressé.
L’activité traductrice doit être considérée contextuellement pour que le traducteur puisse reproduire dans le texte d’arrivée, pour les usagers, tous les éléments linguistiques et extralinguistiques présents dans le texte de départ. Nous sommes persuadé, après avoir vu la quantité de séquences figées existant dans toutes les langues, les énormes possibilités connotatives qui peuvent apparaître avec ces séquences, et toutes les vérifications et analyses qu’il faut effectuer pour trouver une bonne correspondance, que la traduction de celles-ci en général ne peut se réaliser contextuellement, du moins, sans ce genre d’analyse et un dictionnaire électronique dans lequel figurera une classification exhaustive : conceptuelle, formelle et interprétative de ces formes et de leurs possibles signifíés. Comment réaliser en effet en trente secondes, une ou deux minutes, toutes les étapes que nous avons suivies pour expliquer la difficulté de traduire et de trouver la meilleure équivalence possible[28].
Appendices
Notes
-
[1]
Nous désirons remercier X. Blanco et C. Camugli, qui ont lu et corrigé ce texte, pour leurs commentaires et leurs suggestions pertinentes.
-
[2]
Pour la réalisation de cet article, nous avons bénéficié de l’aide de la Generalitat Valenciana (GV/163-05).
-
[3]
Selon Dubois (1994 : 202), le figement est le processus par lequel un groupe de mots dont les éléments sont libres devient une expression dont les éléments sont indissociables. Le figement se caractérise par la perte du sens propre des éléments constituant le groupe de mots, qui apparaît alors comme une nouvelle unité lexicale autonome et à sens complet indépendant de ses composantes.
-
[4]
L’abondante bibliographie qui existe dans le monde entier ainsi que les nombreuses appellations terminologiques différentes utilisées dans le domaine du figement souvent pour désigner un même terme (voir Martins Baltar, 1997 : 23-24) montrent clairement l’importance du sujet. Pour une étude complète des séquences figées en français, voir Mejri (1996), González Rey (2002) et, pour l’espagnol, Corpas Pastor (1996).
-
[5]
Que nous pourrons représenter aussi par SF(S) / UP(S).
-
[6]
L’équipe de lexicométrie de Saint-Cloud a été la première à traiter des textes, les S.F.S. représentaient alors 20 %, un cinquième environ de ceux-ci (Mejri 1997 : 23). Les travaux de Gross et du LADL ont montré, leur importance ; ainsi, Gross (1993) est parvenu à effectuer un recensement de plus de 44 000 expressions figées de ce type.
-
[7]
Actuellement, nous sommes en train de rédiger un inventaire exhaustif de LV en espagnol. Nous en sommes arrivé à 9000 unités et nous espérons dépasser le chiffre de 20 000 unités.
-
[8]
Pour élaborer notre inventaire, nous avons utilisé plusieurs dictionnaires. Suivent les sigles qui font référence à ces ouvrages. Pour l’espagnol : DUE = Diccionario de uso del Español, DRAE = Diccionario de la Real Academia de la Lengua Española, DT = Diccionario temático de locuciones francesas con su correspondencia española, EnLar = Enciclopedia Larousse, LARBI = Dictionnaire Larousse bilingüe, GDE= Gran Diccionario Espasa español-francés/français-espagnol. Pour le français : TL = Thésaurus Larousse, TLF = Trésor de la langue française, MG = index alphabétique des expressions figées de Maurice Gross, AR = Dictionnaire des expressions et locutions d’Alain Rey, PR = Petit Robert, L = Larousse.
-
[9]
Chaque langue fait son propre découpage de la réalité. C’est pour cela qu’il ne faut jamais prendre une langue comme point de départ unidirectionnel. Il faut élaborer d’abord une base de données en chaque langue et ensuite faire des comparaisons et des croisements pour voir les oublis qui peuvent exister. Sinon les vocabulaires selon A. Rey (1992 : 103) souffriront de ce qu’on appelle une terminologie de départ.
-
[10]
Nous pouvons comprendre mais nous ne le justifions pas.
-
[11]
La notion de champ lexical se doit à la linguistique allemande (Jost Trier) et a été utilisée par de nombreux lexicologues comme Wartburg, Matoré, Guiraud, Coseriu.
-
[12]
« Les restrictions de sélection s’appuient sur un système de catégories conceptuelles classificatoires et relationnelles qui forment une véritable ontologie naturelle partagée ». (1998 : 34).
-
[13]
LLI : Laboratoire de linguistique informatique, CNRS, UMR 7546 : <http://www-lli.univ-paris13.fr>.
-
[14]
Un indice de lexicalisation traditionnellement reconnu qui vaut aussi bien pour les mots que pour les séquences figées est celui de l’insertion de la nouveauté dans un dictionnaire.
-
[15]
Laboratoire d’automatique documentaire et linguistique, aujourd’hui incorporé à l’IGM de l’Université de Marne-La-Vallée : <http://www-igm.univ-mlv.fr>.
-
[16]
Si nous observons quelques structures qui n’apparaissent pas dans les deux langues, cela correspond à des caractéristiques lexicales. Ainsi, étant donné que la langue française utilise beaucoup le verbe avoir, Maurice Gross avait classifié toutes les séquences figées qui utilisaient ce verbe en classes indépendantes marquées d’un A initial (d’avoir), tandis que l’espagnol là où le français utilise généralement le verbe avoir pourra utiliser soit le verbes haber, soit le verbe tener. Il n’y aura donc pas de classes en A en espagnol. De la même façon, l’espagnol, comme presque toutes les langues romanes, montre ses origines latines avec les verbes estar (classes commençant par E) et ser (classes commençant par S), mais le français n’a gardé que le verbe être (classes commençant par E). Ce genre de variations impliquera des classes différentes et inévitablement des difficultés pour la traduction dans les deux directions.
-
[17]
La phraséologie contrastive qui analyse généralement des séquences ou des structures hors contexte parlera de correspondances plus ou moins formelles, tandis que la traductologie va le faire à travers des contextes et parlera alors d’équivalences. Cependant, sans un travail de compilation exhaustif qui débroussaille le terrain et facilite la tâche aux traducteurs, il serait très difficile, voire presque impossible, de trouver la ou les traductions équivalentes.
-
[18]
Il correspond aux autres travaux de comparaison et de traduction que nous avons déjà réalisés (Mogorrón 2002). Ce qui ne veut pas dire forcément qu’il n’y ait pas de LV dans l’autre langue. Puisque les dictionnaires électroniques que nous sommes en train d’élaborer ne sont pas terminés, il existe des possibilités pour que nous trouvions des formes utilisées couramment dans l’autre langue, qui ne soient pas recueillies par les dictionnaires consultés, ou bien, une autre LV avec plusieurs sens non attestés par ces ouvrages.
-
[19]
Voir Mathieu-Colas (1996) pour des analyses en français sur les paradigmes. Nous montrons ici un exemple de traitement de ces variations paradigmatiques dans les ouvrages bilingues analysés :

-
[20]
Nous pourrons ensuite suivre les mêmes étapes pour traduire les autres types de séquences figées.
-
[21]
Dans le sens de L. Tesnière (1959 : 53), par opposition aux mots vides non référentiels.
-
[22]
Cette différence de classe, et non de structure, est due au fait qu’en espagnol nous avons créé une table avec cette structure, étant donné la grande quantité de LVS avec cette structure.
-
[23]
X. Blanco retient pour l’élaboration de dictionnaires électroniques les étiquettes suivantes :
-
[24]
Lorsque nous n’avons pas inclus cette information dans ce tableau, c’est parce que les dictionnaires ne fournissent pas de références à ce sujet.
-
[25]
Mais nous sommes sûr qu’à ce propos il y aura autant d’opinions et de critères que de possibilités.
-
[26]
Nous n’avons traité ici que de la traduction des LVs sous une forme canonique ou lemmatisée. Nous n’avons abordé à aucun moment la traduction des LVS qui ont été déformées par l’auteur ou qui ont subi un procès de défigement volontaire, car pour ces cas, la traduction devra utiliser d’autres ressources.
-
[27]
Cette solution rejoint celle proposée pour l’étude des proverbes par C. Schapira (1999) en français et J. Sevilla Muñoz (1988) en espagnol, qui consiste à déterminer les proverbes en partant de traits prototypiques.
-
[28]
Nous sommes conscients que nous ne venons que d’ébaucher les possibilités et les difficultés de traduction des LVS entre le français et l’espagnol. Nous nous proposons comme défi au fur et à mesure de l’élaboration du dictionnaire multilingue que nous avons commencé, grâce au financement de l’Université d’Alicante en espagnol, français, russe, italien et catalan, de formuler, de perfectionner et de chercher des solutions qui faciliteront la traduction de ces séquences.


Références
- Blanco, X. (2001) : « Dictionnaires électroniques et traduction automatique espagnol-français », Langages 143, pp. 49-70.
- Corpas Pastor, G. (1996) : Manual de fraseología española, Madrid, Gredos.
- Delisle, J. (1993) : La traduction raisonnée. Pédagogie de la traduction, Ottawa, Presses de l’Université d’Ottawa.
- González Rey, I. (2002) : La phraséologie du français, Toulouse, Presses universitaires du Mirail.
- Gross, G. (1996) : Les expressions figées en français : noms composés et autres locutions, Ophrys, Gap-Paris.
- Gross, M. (1982) : « Une classification des phrases “figées” du français », Revue Québecoise de Linguistique 11-2, pp. 151-185.
- Gross, M. (1985) : « Sur les déterminants dans les expressions figées », Langages 79, pp. 89-117.
- Gross, M. (1988) : « Les limites de la phrase figée », Langages 90, pp. 7-22.
- Hurtado Albir, A. (2002) : Traducción y traductología, Madrid, Cátedra.
- Jakobson, R. (1958-1959) : “On Linguistic Aspects of Translation”, in Brower, R., On Translation, Cambridge, Harvard University Press, pp. 232-239.
- Lederer, M. (1994) : La traduction aujourd’hui. Le modèle interprétatif, Paris, Hachette.
- Le Pesant, D. et M. Mathieu-Colas (1998) : « Introduction aux classes d’objets », Langages 131, pp. 6-33.
- Mathieu-Colas, M. (1996) : « Typologie de la composition nominale », Cahiers de lexicologie 69, pp. 65-118.
- Mejri, S. (1997) : Le figement lexical. Descriptions linguistiques et structuration sémantique, Tunis, Publication de la faculté des lettres de la Manouba.
- Mogorrón, P. (2002) : La expresividad en las locuciones verbales en francés y en español, Alicante, Publicaciones Universidad de Alicante.
- Mogorrón, P. (2004) : “Los diccionarios electrónicos fraseológicos, perspectivas para la lengua y la traducción”, E.L.U.A. 12, pp. 381-400.
- Mounin, G. (1976) : Les problèmes théoriques de la traduction, Paris, Gallimard.
- Prandi, M. (1998) : « Contraintes conceptuelles sur la distribution : réflexion sur la notion de classes d’objets », Langages 131, pp. 34-44.
- Rey, A. (1992) : La terminologie. Noms et notions, Paris, Presses Universitaires de France.
- Ruiz Gurillo, L. (1997) : “Aspectos de fraseología española”, Anejo XXIV de Cuadernos de Filología, Valencia, Universitat de Valencia.
- Schapira, Ch. (1999) : Les stéréotypes en français : proverbes et autres formules, Paris, Ophrys.
- Sevilla Muñoz, J. (1988) : Hacia una aproximación conceptual de las paremias francesas y españolas, Madrid, Editorial de la Universidad Complutense.
- Tolosa, M. (2004) : “La traducibilidad de las locuciones somáticas : un afán utópico”, Tesina, Universidad de Alicante.
- Tricás Preckler, M. (1995) : Manual de traducción, Barcelona, Gedisa.
- Zuluaga, A. (1980) : Introducción al estudio de las expresiones fijas, Frankfurt, Verlag Peter Lang.
- Diccionario de la Real Academia Española (1992) : (vigésimo primera edición), Madrid, Ed Espasa-Calpe.
- Rey, A et S. Chantreau (1979) : Dictionnaire des expressions et locutions figurées (+ index final 1982), Paris, Larousse.
- Rey, A, Cottez, H. et J. Rey-Debove (1990) : Le Petit Robert 1. Dictionnaire alphabétique et analogique de la langue française, Paris.
- Sevilla Muñoz, J. y J. Cantera De Urbina (2004) : Diccionario temático de locuciones francesas con su correspondencia española, Gredos.
- Grand Diccionario Espasa español-francés / francés-español (2000) : Madrid.
- García-Pelayo, R y J. Testas (1993) : Larousse moderno français-espagnol español-francés, Paris, Larousse.
- González, J.L. (1990) : Dichos y proverbios populares, Madrid, Edimat.
- Larousse de la langue française, Lexis (1991) : Larousse. Paris.
- Moliner, M. (1977) (1988) (1999) : Diccionario de uso del español, 2 tomos, Madrid, Gredos.
 10.7202/602492ar
10.7202/602492arDictionnaires
List of tables
Tableau 1
Tableau 2
Tableau 3
Tableau 4
Tableau 5
Tableau 6
Tableau 7
Tableau 8
Tableau 9
Tableau 10
Tableau 11
Tableau 12
Tableau 13
Tableau 14
Tableau 15
Tableau 16
Tableau 17
Tableau 18
Tableau 19
Tableau 20
Tableau 21
Tableau 22
Tableau 23
Tableau 24
Tableau 25
Tableau 26
Tableau 27
Tableau 28
Tableau 29