

Abstracts
Résumé
Depuis novembre 2022, les acteurs de l’éducation s’émeuvent de l’apparition de services informatiques qui permettent de générer des textes, des images ou des sons en une simple requête. Ces programmes désignés sous le nom d’intelligences artificielles génératives font l’objet d’une forte médiatisation. En évaluation, de nouveaux enjeux apparaissent : 1) Sait-on déterminer les compétences à évaluer chez les élèves, utilisateurs potentiels de ces technologies ? 2) Sait-on faire la différence entre production humaine et machinique ? 3) Peut-on évaluer, sur le fond, des productions qui pratiquent l’illusion de la forme ? 4) Comment évaluer la dimension authentique d’une production d’élève ? 5) Sait-on évaluer les potentialités éducatives de ces technologies ? Relever ces cinq enjeux suppose une sensibilisation des enseignants et des formateurs à la pratique d’une évaluation éthique et formative apte à tirer parti de ces technologies pour préparer les élèves à des technologies qui seront bientôt banales à l’école.
Mots-clés :
- éthique,
- évaluation formative,
- illusion,
- intelligences artificielles génératives
Abstract
Since November 2022, educators have been concerned about the emergence of computer services that generate texts, images, or sounds based on a simple textual request. These computer applications, referred to as Generative Artificial Intelligence (GAI), have been heavily publicized. In the area of evaluation, new challenges arise: 1) Can we determine the skills to assess in students, who are potential users of GAI ? 2) Can we differentiate between human and machine production ? 3) Can we evaluate, in substance, productions that use the form as an illusion generator ? 4) How can we realize an authentic evaluation of a student’s production ? 5) Do we know how to evaluate the educational potential of these technologies ? To address these five challenges, it is necessary to raise teachers and trainers’ awareness to the practice of ethical and formative assessment capable of harnessing these technologies to prepare students for technologies that will soon become commonplace in schools.
Keywords:
- ethics,
- formative evaluation,
- generative artificial intelligence,
- illusion
Resumo
Desde novembro de 2022, os atores da educação estão preocupados com o surgimento de serviços de informática que permitem gerar textos, imagens ou sons com uma simples solicitação. Estes programas, conhecidos como inteligências artificiais generativas, têm recebido grande atenção mediática. Na avaliação, surgem novos desafios: 1) É possível determinar as competências a serem avaliadas nos alunos, utilizadores potenciais dessas tecnologias ? 2) É possível distinguir entre produções humanas e maquinais ? 3) É possível avaliar, no fundo, produções que praticam a ilusão da forma ? 4) Como avaliar a dimensão autêntica de uma produção de um aluno ? 5) É possível avaliar as potencialidades educativas destas tecnologias ? Enfrentar estes cinco desafios exige uma sensibilização dos professores e formadores para a prática de uma avaliação ética e formativa, capaz de tirar proveito destas tecnologias para preparar os alunos para tecnologias que em breve serão comuns nas escolas.
Palavras chaves:
- avaliação formativa,
- ética,
- ilusão,
- inteligências artificiais generativas
Article body
Introduction
La diffusion galopante des textes générés par les machines supprime le lien univoque entre le langage et l’être humain. Un système d’intelligence artificielle qui parle est bien plus qu’un perroquet qui nous singe : grâce aux techniques d’apprentissage automatique, les phrases qu’il émet ne sont pas de simples copier-coller. La machine les construit d’une façon radicalement différente de celle de l’homme. Son langage est le résultat d’un calcul mathématique et ses mots sont dérivés de nombres. Avec la machine parlante, le nombre se fait verbe.
C’est à partir de ce constat qu’Alexei Grinbaum, dans son ouvrage Parole de machines (2023, p. 13), explique l’attraction récente, mais aussi les sentiments ambigus que nous éprouvons, face à des machines qui produisent du langage, des textes et des images. Nous voilà dépouillés de notre exclusivité à échanger des idées puisque désormais la machine semble capable de faire passer ses productions pour humaines.
Nous vivons une période durant laquelle les géants de l’informatique sont engagés dans une forte concurrence visant le développement de l’intelligence artificielle (IA). Les récentes capacités génératives de ces machines, qui nous semblent aptes à communiquer par elles-mêmes, marquent notre imaginaire. Il est difficile d’ignorer ce phénomène car, presque chaque jour, les médias internationaux présentent des épisodes nouveaux de ce développement technologique. Les articles de presse, laudateurs ou critiques, se focalisent aussi sur les stratégies des entreprises dont l’IA est le coeur de métier, les lancements de produits ou encore l’accès public aux interfaces, et débattent des conséquences de l’IA sur les pratiques du quotidien, renforçant ainsi une fascination technologique qui se double d’anxiété.
Le monde de l’éducation et de la formation n’est pas épargné par ces débats autour de l’IA générative. En lien avec les enjeux contemporains de l’évaluation, deux questions principales émergent : quelles seront, et sont peut-être déjà, les compétences indispensables pour vivre dans un monde où les productions artificielles seront monnaie courante ? Comment pourra-t-on évaluer ces compétences et qui saura le faire ? Sans apporter de réponses immédiates et tranchées à ces deux questions, cet article ambitionne plus modestement de dégager cinq enjeux qui permettent de mieux distinguer ces compétences en les répartissant en plusieurs catégories et d’esquisser quelques pistes d’action.
IA génératives : de quoi parle-t-on ?
Les questionnements actuels sur les enjeux de l’IA en éducation apparaissent alors que la recherche en la matière existe depuis plus d’un demi-siècle, même si les algorithmes pilotés par les données (Cardon et al, 2018), c’est-à-dire ceux qui exploitent les principes de l’apprentissage automatique (machine learning), puis de l’apprentissage profond (deep learning[1]), sont plutôt récents et datent d’un peu plus de dix ans[2]. Ces technologies d’IA récentes mettent en oeuvre des réseaux de neurones informatiques pré-entraînés à repérer et à classer des informations aux structures complexes[3], qui sont ensuite confrontés à des quantités gigantesques de données leur permettant d’élaborer par eux-mêmes des modèles de calcul statistique prédictifs imitant l’apprentissage humain. Cette convergence entre algorithmes sophistiqués et données massives permet, depuis une dizaine d’années déjà, de construire des IA spécialisées en très grand nombre, visant à apporter une assistance efficace aux humains à tous les niveaux de la société.
D’abord prédictives, les IA ont eu pour objectif de trier et de classer statistiquement une quantité gigantesque de données afin d’aider l’humain à repérer des tendances ou à isoler des cas critiques destinés à produire des recommandations. Depuis plus d’une dizaine d’années, ces IA sont couramment exploitées au quotidien, embarquées dans des applications numériques spécialisées, sans que l’appellation IA soit forcément mise en avant. Les professionnels utilisent ces programmes dans le cadre de tâches d’assistance (aide au diagnostic en radiologie et biologie, retouche d’images, systèmes de maintenance prédictive des machines, etc.). Ces IA sont aussi présentes dans des applications informatiques utilisées par le grand public (suggestion de trajets dans les navigateurs GPS, suggestion de mots dans les messageries instantanées, recommandations d’achat sur les plateformes commerciales, etc.). Ces IA prédictives suggèrent des réponses ou attirent l’attention de l’expert ou de l’usager sur des éléments difficilement repérables dans une grande masse de données parfois disparates. En ce sens, elles complètent les compétences humaines.
Les IA aux fonctions dites génératives, qui sont au coeur de cet article, visent quant à elles la fabrication de toutes pièces (ou l’optimisation) de productions textuelles, visuelles, sonores ou programmatiques. Elles ont progressivement été mises au point depuis 2020 grâce à l’association de plusieurs types d’algorithmes issus de la recherche en IA. Les productions de ces IA génératives (textes, images, sons) sont globalement cohérentes et plausibles, mais pas aussi fiables ou pertinentes que ce qu’un utilisateur naïf pourrait penser, car elles dépendent de l’intégrité des données qui leur servent de sources et des algorithmes statistiques qui peuvent effectuer des généralisations abusives. L’évolution de leur fiabilité est sans doute possible, à l’instar des IA prédictives[4], même si cette perspective reste encore en débat.
Ces deux catégories d’IA utilisent les principes de l’apprentissage automatique mais la deuxième catégorie se distingue de la première, d’une part, par le fait que la fonction principale des algorithmes n’est plus de l’ordre de l’assistance ou de la recommandation, mais plutôt de délivrer un produit humanisé à un utilisateur, et, d’autre part, parce que l’appellation IA, parfaitement assumée cette fois, fait partie intégrante de la stratégie de communication des concepteurs.
Les IA génératives obéissent à une logique qui, au-delà de la recommandation, a l’ambition de substituer une production numérique artificielle à la création humaine, ce qui fait débat au sein des sciences humaines et sociales. Par ailleurs, le traitement opéré par une IA générative repose non seulement sur des données massives industriellement ordonnées, mais également sur l’interprétation informatique d’une invite de commande (prompt), saisie a l’initiative de l’utilisateur, ce qui entretient l’idée, chez ce dernier, qu’il est possible de mener une interaction quasi-naturelle avec la machine. Les IA génératives font ainsi bien plus que suggérer : elles interprètent nos demandes et délivrent des symboles intelligibles et cohérents en réponse à ces requêtes. C’est à l’utilisateur, armé de ses compétences, que revient la responsabilité d’en faire usage.
Le grand public n’a découvert que récemment ces IA génératives à la faveur de la mise en accès libre du générateur conversationnel ChatGPT[5] développé par la société OpenAI (Ramponi, 2022). Ce robot conversationnel (chatbot en anglais) exploite les potentialités de grands modèles de langage (large language models[6]) ou GML. Son interface est mise à la disposition de tout utilisateur qui accepte, en échange, de créer un compte sur le site de OpenAI, en y enregistrant son adresse courriel. Après un peu plus d’une année d’existence, ce type de service informatique tend à se développer chez les concurrents et à être intégré à des outils connus (moteurs de recherche, logiciels de traitement de l’information…)[7]. Par ailleurs, de nombreux systèmes générant d’autres types de productions numériques (images, vidéo, musique) imitant des productions humaines ont été progressivement mis sur le marché.
En résumé, l’IA, telle qu’on la désigne au singulier, c’est-à-dire le plus souvent, n’a rien d’un ensemble homogène. Derrière ce terme, se cachent de nombreuses technologies aux diverses finalités, qui parfois s’imbriquent, parfois se complètent, ou parfois encore sont des éléments complètement intégrés à des projets bien plus larges. Il faut donc peut-être mettre à distance la dimension strictement technologique et plurielle des IA. Par conséquent, cet article portera plus spécifiquement sur les algorithmes dits génératifs.
L’utilisation des IA : connaissances et incertitudes en éducation et en évaluation
Parmi les grands enjeux contemporains, l’un des plus importants, mais aussi le plus trivial, est de comprendre les potentiels et les limites des technologies des IA dans le contexte de l’éducation et de la formation. Ainsi, Gaudreau et Lemieux (2020) ont abordé, pour le compte du Conseil Supérieur de l’Éducation du Québec, des enjeux éducatifs quelques années avant la prise de conscience récente de l’importance des IA au sens général, dans le domaine de l’éducation. Mais, jusqu’à la fin de 2022, la recherche et le développement rapide des IA prédictives ne suscitaient que peu d’inquiétudes dans les instances politiques d’évaluation en éducation et en formation. Les recherches menées au sein du courant de l’IA en éducation (artificial intelligence in education) ou AIED (Zhai, 2022) pariaient essentiellement sur les effets positifs de cette IA (Unesco, 2019, art. 14) et les chercheurs en la matière s’intéressaient alors principalement à l’automatisation et à l’aide que les IA pouvaient apporter aux enseignants dans diverses tâches de formation et d’évaluation (Holmes & Tuomi, 2022)[8]. À titre d’exemple, des outils comme Nolej (nolej.io), Cognii (cognii.com) ou Compilatio (compilatio.net) sont de puissants alliés, respectivement, dans des domaines de la mise en forme de contenus à enseigner, de systèmes de contrôle de connaissance automatisés ou de recherche de plagiat.
La médiatisation de l’IA générative ChatGPT a provoqué une agitation assez inhabituelle chez les élèves et chez les enseignants jusqu’alors majoritairement centrés sur la dimension humaine des pratiques d’évaluation (Agostini & Abernot, 2011 ; Hadji, 1987). En effet, depuis novembre 2022, le caractère spectaculaire des capacités conversationnelles de ChatGPT, son aptitude à générer des réponses à la syntaxe cohérente et claire dans un grand nombre de langues, et l’apparente facilité d’utilisation des invites de commande ont été à l’origine d’une prise de conscience. Ainsi, les élèves du collège à l’université sont aujourd’hui en mesure de produire des contenus acceptables à moindre effort et ces contenus ne témoignent pas nécessairement de l’existence de la compétence évaluée. Même si ce phénomène ramène en mémoire les inquiétudes dues au développement d’Internet et, plus généralement, du numérique (Kambouchner et al., 2012) son ampleur semble tout autre.
Le succès de cette technologie tient sans doute, d’une part, à la nature des réponses ou des productions élaborées par le programme qui ont la capacité de passer pour quasi-humaines comme le souligne Grinbaum (2023) ; d’autre part, à la facilité d’usage d’une interface comme celle de ChatGPT 3.5, par exemple, qui permet de dialoguer (chatter) gratuitement avec la machine en langage naturel. L’ensemble ouvre un large spectre d’applications qui a immédiatement séduit le grand public, ce dernier percevant, peut-être pour la première fois, l’intérêt pratique et concret d’une application des principes de l’intelligence artificielle.
Depuis 2022, de nombreuses recherches ont levé une partie du voile sur cette technologie et sur son utilisation en éducation (Holmes & Tuomi, 2022), sur l’accueil qu’elle suscite auprès des élèves du secondaire et des étudiants (Hornberger et al., 2023) et sur les facteurs de son succès (Polyportis & Pahos, 2024). Malgré ces travaux, prendre en compte tous les enjeux évaluatifs sous-jacents reste encore ardu tant il est difficile d’apprécier ou de se faire une image précise du fonctionnement de ces algorithmes complexes, combinés entre eux, qui s’alimentent de données massives issues d’Internet et dont on ne connaît pas clairement l’origine. Concernant, par exemple, le moissonnage massif de ces données par des compagnies privées, se préoccuper de propriété intellectuelle et de contrôle de qualité reste très compliqué, voire impossible. Pourtant, les données qui alimentent ces IA devraient toujours être soumises à la critique humaine, c’est-à-dire évaluées, y compris au regard du Droit, et pour cela, reposer a minima sur une certaine transparence (Le Cam & Maupomé, 2023).
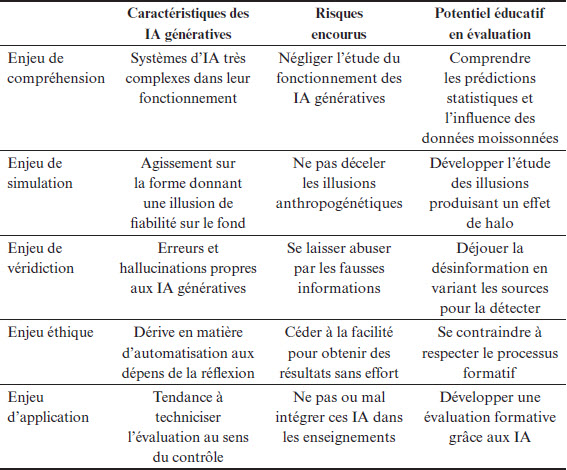
Cinq enjeux majeurs en évaluation
Face à ces obstacles à la compréhension qui brouillent le paysage et rendent difficilement perceptibles les enjeux en éducation et en évaluation, cet article dégage cinq enjeux contemporains relatifs à l’évaluation en éducation et en formation relevant de différentes catégories : la compréhension, la simulation, la véridiction, l’éthique et l’application. Ces enjeux permettent également de souligner plusieurs types de compétences à développer chez les utilisateurs des IA génératives, qu’ils soient élèves ou enseignants. En effet, ces derniers peuvent tout à fait tirer parti des algorithmes génératifs pour mettre en place un système d’évaluation facilement renouvelable dans sa forme (génération de questions, de textes d’entraînement, de réponses possibles, etc.).
Un enjeu de compréhension : évaluer le processus technologique et ses principes
Si les spécialistes s’accordent sur la nécessité de former les jeunes générations à un usage raisonné des IA en général (Unesco, 2019), la complexité des IA génératives actuelles et l’évolution de leurs capacités à générer des contenus pertinents (mais qui ne sont peut-être pas fiables) rendent cette tâche difficile. Même auprès des personnes les plus avancées en informatique, les IA génératives restent une sorte de boîte noire. Les milliards d’opérations élémentaires peuvent être le fruit de l’activité d’une myriade de classements élémentaires réalisés par des opérateurs humains combinés à des opérations statistiques, mais peuvent aussi provenir de corrélations que la machine opère sur ses propres données.
Il est donc difficile d’évaluer concrètement et de manière détaillée les mécanismes et les paramètres sur lesquels se base la performance de ces systèmes. La concurrence entre les sociétés qui les commercialisent a aussi pour conséquence une très faible diffusion d’informations stratégiques. Les secrets industriels sont toujours bien gardés. Les principes de traitement de données ne sont le plus souvent qu’indicatifs et exprimés en nombre de paramètres, sortes d’aiguillages réalisant des fonctions de tri élémentaires. Ainsi, la société américaine OpenAI pour son système GPT-3 déclare 175 milliards de paramètres, Switch C de Google, 1 700 milliards, et BAAI, le constructeur chinois de Wu Dao2, 1 780 milliards de paramètres. Il s’agit là de chiffres vertigineux qui n’ont aucun sens pour un utilisateur moyen. Face à cette lutte quasi-géopolitique entre compagnies mondiales, le souhait présent dans la déclaration de Montréal (2018) de développer « une IA responsable et digne de confiance » (Gaudreau & Lemieux, 2020, p. 6-7) semble avoir bien peu de chances de se réaliser.
La seule opération évaluative que peut réaliser l’utilisateur final est d’estimer la qualité de la production à l’aune de ses propres connaissances et de ses propres compétences d’usager. Mais connait-on suffisamment les principes de ces programmes pour être capable de déterminer les compétences à évaluer chez les élèves confrontés à cette évolution technologique ? Quelques pistes peuvent être esquissées afin d’évaluer le potentiel de ces technologies. Si, en matière de composition et de forme, la machine dépasse le plus souvent les compétences d’un utilisateur moyen (comme c’est souvent le cas pour n’importe quel robot hautement spécialisé), c’est sur le fond que l’utilisateur pourra mener son évaluation en fonction de ses connaissances et de ses compétences. En ce qui concerne l’éducation et la formation, s’ils ne sont pas incités à la prudence, les plus jeunes peuvent être tentés d’idéaliser la machine, lui attribuant des vertus magiques. De même, les plus avertis, étudiants ou professionnels, peuvent être tentés de lui déléguer sans trop de discernement des tâches qu’il faudrait réserver à un esprit humain, misant sur la quantité plus que sur la qualité.
L’enjeu de compréhension est là : un déluge de textes, d’images et de sons générés par des IA où l’illusion de la forme cache parfois l’indigence du fond, peut rendre, en fin de compte, l’exercice de l’esprit critique et de l’évaluation des contenus quasiment impossible. Des vulgarisateurs, ou des chercheurs, comme par exemple Alexandre et al. (2021), préconisent alors, a minima, l’apprentissage de principes généraux afin de mieux comprendre le fonctionnement des IA grâce à des manipulations simulées sur un Mooc à destination de populations francophones.
Un enjeu de simulation : évaluer les illusions fondées sur la forme
Les IA génératives sont conçues, d’une part, pour donner l’illusion à l’utilisateur d’avoir affaire à un raisonnement humain (Opara et al., 2023), et, d’autre part, pour engendrer une forme de satisfaction grâce aux artefacts qu’elles produisent (Assunção et al., 2022 ; Xia et al., 2023). Or, une évaluation basée sur la satisfaction n’est pas une évaluation basée sur la qualité. En raison de leur forme qui peut entretenir une illusion de qualité, les produits (textes, images, sons) de ces systèmes sont de plus en plus souvent employés comme substituts à des productions humaines qui relèvent d’un haut niveau de spécialisation. Ajouté à cela, le recours à des machines autorise un usage et une diffusion à dimension industrielle. Saura-t-on alors déceler les indices qui caractérisent les productions de ces générateurs et faire la différence entre production humaine originale et production machinique (Dugan et al., 2023) ?
Nous savons que les IA disposent d’algorithmes visant à sélectionner et à reproduire statistiquement des schémas existant déjà sur les réseaux. Dans un monde où ces productions deviennent monnaie courante (illusions dues à la forme, pensée toute faite, idées reçues ou reproduction des stéréotypes omniprésents sur les réseaux), développer des capacités d’analyse sera un enjeu majeur en éducation. Le caractère artificiel du traitement de l’information et de la restitution entretient une illusion fondée sur la forme, en lien avec les biais cognitifs et perceptifs d’origine humaine. À leur tour, ces biais influencent les données qui constituent la base informationnelle traitée par les algorithmes. Ceci est d’autant plus vrai que, dès leur conception, les IA génératives sont le plus souvent entraînées à produire des textes ou des images consensuelles en évitant les éléments négatifs ou critiques qui permettraient de repérer une dimension argumentative personnelle. Au-delà du leurre que constitue le produit, tous les ingrédients susceptibles de freiner toute innovation, toute évolution de la pensée et, par conséquent, de générer du conformisme, sont réunis.
Dugan et ses collègues (2023) concluent néanmoins, sur la foi d’une étude, qu’il est possible, pour des étudiants issus de l’enseignement supérieur, en situation expérimentale, de repérer des indices d’artificialité au sein des textes produits. Cependant, il en va tout autrement pour des élèves du primaire et, sans doute, également pour des élèves du secondaire, surtout si l’IA est utilisée massivement dans le contexte de la vie quotidienne. Comme l’écrit Julia (2019, p. 150), coconcepteur de Siri, l’agent vocal de la société Apple, « [ce] qui intéresse les gens, ce n’est pas la technologie en elle-même mais ce qu’elle permet, à savoir l’accès à des services de façon simple ».
À titre d’exemple, à la question « Quelle est la place du personnage d’Adèle dans Les Misérables de Victor Hugo ? », Chat-GPT 3.5 ne déçoit pas son utilisateur. En effet, aujourd’hui, au début de 2024, il répond en première instance qu’Adèle est « un personnage mineur », que c’est « la fille illégitime de Tholomyès et d’une jeune femme nommée Favourite ». Cependant, il n’y a pas d’Adèle dans le roman, et nous savons que Cosette (Euphrasie) est la fille naturelle de Tholomyès et de Fantine. Mais, tout bien considéré, il est facile de comprendre que le prénom Adèle est statistiquement attaché à Victor Hugo, époux d’Adèle Foucher et père d’une Adèle Hugo, sa seconde fille. Il y a de quoi embrouiller Chat-GPT qui, se fondant sur des algorithmes globaux et probabilistes rapproche le nom de Hugo du prénom Adèle et pronostique une relation entre les deux. Il n’en faut pas plus pour que l’algorithme, plaçant dans sa réponse un mot en fonction de celui qui le précède et s’appuyant sur la demande de l’utilisateur en prenant en compte l’affirmation implicite qui existe dans la question initiale de l’utilisateur, produise ce que l’on appelle une hallucination[9]. Ce dernier point montre l’importance du soin que l’utilisateur apporte à la requête, car, à la question « Existe-t-il un personnage prénommé Adèle dans Les Misérables de Victor Hugo ? » le robot répond immédiatement « Je m’excuse pour la confusion précédente. Après vérification, il n’y a pas de personnage prénommé Adèle dans le roman Les Misérables de Victor Hugo. Je vous prie de bien vouloir ignorer la réponse précédente, qui était incorrecte » . Un robot qui s’excuse, et voilà l’illusion anthropogénétique entretenue. En matière de fiabilité, les chercheurs laissent peu de place au doute : Wang et al. (2023) estiment à 64 % seulement la robustesse de l’information délivrée par ChatGPT à partir d’une expérimentation sur des bases de données médicales.
Un enjeu de véridiction sociale : évaluer la part des hallucinations
Comme nous le voyons, un texte généré, au ton très affirmatif simulant le discours d’un expert, peut être trompeur. Les IA génératives sont entraînées sur des données morcelées, la plupart du temps moissonnées sur les réseaux informatiques, et sont programmées afin de délivrer des réponses à toute requête. Elles produisent donc des réponses susceptibles d’être totalement fausses ou inappropriées si les règles déduites des corrélations sont fausses. Le cas de l’application Tay de Microsoft est célèbre. Le système Tay, entraîné à partir des échanges tenus sur un célèbre réseau social américain lancé le 23 mars 2016, a été réduit au silence par ses concepteurs à peine huit heures après son lancement du fait des propos racistes et insultants qu’il délivrait. Ceci démontre qu’il est difficile de s’en tenir aux propos, aux opinions et aux affirmations non vérifiables qui alimentent les réseaux sociaux et que les contenus des bases de données sont en grande partie responsables des hallucinations. Peut-on alors évaluer sur le fond des productions qui séduisent les utilisateurs par l’illusion de la forme ?
Les pratiques de véridiction sont des pratiques sociales complexes qui demandent force vérifications et l’établissement de sources de référence. De plus, la question de la vérité alimente depuis la nuit des temps les débats philosophiques : ce qui peut être considéré comme généralement vrai dans un groupe culturel peut être contesté dans un autre. Face à la diversité de croyances, d’opinions, de raisonnements et de justifications, les IA génératives, dépourvues de toute conscience, sont totalement désarmées. Elles ne peuvent établir ce qui est vrai pour elles qu’à partir de données statistiques. Par ailleurs la précision de la requête soumise, ou prompt, joue, comme nous l’avons expliqué, un rôle déterminant dans la qualité de la production d’une IA générative. Le prompt, en contextualisant la génération de texte, d’image ou de son, indique à l’IA ce que l’utilisateur souhaite obtenir comme production. La requête envoyée à une IA générative doit donc être elle-même le produit d’une évaluation humaine pour que la machine puisse fonctionner correctement.
L’enjeu de véridiction est donc étroitement lié à la capacité de l’utilisateur à évaluer par lui-même la qualité de sa requête, c’est-à-dire à exploiter ses connaissances et ses compétences pour être en mesure de la formuler correctement. Cet enjeu est d’ailleurs une caractéristique partagée avec les moteurs de recherche (Ladage & Chevallard, 2011) qui ne permettent d’obtenir des résultats pertinents que dans la mesure où la requête formulée précise des éléments de contexte qui éviteront de voir s’afficher des réponses inappropriées.
Un enjeu éthique : évaluer une production d’élève authentique
Lors du lancement de ChatGPT, les discussions entre enseignants se teintaient de crainte, car les élèves les plus technophiles et pouvant se connecter aux dispositifs informatiques d’IA ont vu dans les algorithmes générateurs de langage un moyen d’obtenir de meilleurs résultats scolaires à peu de frais. En effet, un élève peut être tenté de déléguer progressivement à la machine, fonctionnant sur la base des grands modèles de langage, la capacité de répondre sans faire l’effort de mettre en oeuvre son raisonnement ou son esprit critique. Comme on le sait, un algorithme générateur de texte ne se contente pas de répondre à des questions : il compose et disserte sur un ton véridictoire, il élabore des synthèses, il est en mesure de traduire des textes complexes, il dévoile des méthodes de résolution de problèmes mathématiques, il conseille et éclaire les personnes en demande de décision (en émettant parfois des conseils de prudence si ses concepteurs l’ont prévu).
Comment, alors, l’éducateur peut-il respecter une éthique professionnelle en évaluant la dimension authentique d’une production d’élève, forcément imparfaite, dans une visée formative ? Ces interrogations sur les pratiques évaluatives ne sont pas nouvelles. De nos jours, il apparait forcément complexe à certains enseignants de demander à un élève de composer un texte ou de résoudre un problème, chez lui et sans supervision, en guise d’évaluation, et simultanément de prendre en compte l’authenticité de sa production. Il est facile de comprendre les réserves de ces enseignants et les décisions d’un certain nombre d’établissements d’interdire le recours aux IA génératives en situation de contrôle certificatif ainsi que la tentation de recourir à l’IA pour renforcer ce contrôle (Nigam et al., 2022). Pourtant, des auteurs défendent l’idée que l’évaluation peut être authentique, même dans un cadre informatisé comme l’est l’enseignement à distance (Gérin-Lajoie et al., 2021), à condition de privilégier l’évaluation formative, de procéder à des rétroactions fréquentes et de faire pratiquer l’autoévaluation.
Bien d’autres questions se posent : De quel type de compétence la production de résultats concrets grâce aux IA est-elle l’indicateur ? En quoi une recherche automatisée d’information doublée d’une production témoigne-t-elle d’une réflexion ou d’un apprentissage (Deng et al., 2022) ? Ces questions importantes ont déjà été posées au moment de l’introduction de la calculatrice à l’école, de l’arrivée des moteurs de recherche et de la montée en puissance de Wikipédia. Dans le cas de l’usage des IA génératives, comme dans les cas qui viennent d’être énoncés, l’utilisation ponctuelle, encadrée et accompagnée des services des IA peut tout à fait être envisagée.
Il est important également de s’interroger sur l’éthique, comme le fait Jean-Marc Nolla (2021), face au risque de plagiat lors d’une évaluation : l’acte de plagier ou de déléguer la rédaction d’un texte à une IA spécialisée est-il une tromperie intentionnelle et à quel degré ? L’évaluation conçue par l’enseignant consiste-t-elle toujours à opérer un contrôle des connaissances ou des pratiques des élèves et des étudiants ? Où l’évaluation intègre-t-elle l’objectif d’amener étudiants et élèves à réfléchir sur la valeur qu’il est possible d’accorder à leurs propres productions ?
Ce type de questionnement peut être une occasion pour mieux distinguer l’intention pédagogique qui se cache derrière chaque dispositif évaluatif. Savoir comment exploiter le processus formatif d’une IA générative (Nguyen et al., 2023) peut être éclairé par un questionnement comme celui de Hadji (2012), plus large, qui s’interroge sur la façon de mener une évaluation constructive. Ces questionnements et ces propositions doivent conduire les enseignants à imaginer des scénarios leur permettant de contourner ces problèmes en intégrant l’usage des instruments numériques de telle sorte que ces systèmes servent à des fins éducatives ou évaluatives. Même si l’opérationnalisation de l’IA générative reste à venir (Colin & Marceau, 2021), l’expérience a montré que ceci n’était possible que lorsque les enseignants étaient familiers avec les technologies.
Ceci n’est pas hors de portée. En effet, l’approche de l’audit techno-éthique proposée par Krutka et al. (2021) qui consiste à évaluer avec les élèves, à partir d’une question assez pratique, soit « Devrait-on utiliser Google dans les écoles ? » (traduction libre de Should we use Google in schools?), la part du bénéfice tiré de l’usage d’une technologie (facilitation de certaines opérations en situation éducative) et la part que tire la compagnie commerciale qui la propose (les données moissonnées), est aussi une piste intéressante. Elle permet notamment de développer une attitude éthique et responsable amenant les élèves à se confronter aux questions complexes que soulève l’emploi généralisé des technologies avancées.
Un enjeu d’application : améliorer l’évaluation grâce aux IA génératives
Les questions entourant le rôle que peuvent jouer les IA génératives en éducation et en formation débouchent principalement sur une réflexion sur la dimension formative de l’évaluation, qui retient de plus en plus souvent l’intérêt des chercheurs en évaluation (Morissette, 2010). Jusqu’à présent, les recherches menées au sein du courant AIED pour utiliser l’IA classique avaient majoritairement pour but de concevoir ou d’optimiser des systèmes susceptibles d’aider les enseignants ou les établissements dans leurs missions. C’est notamment le cas de l’optimisation des parcours individuels d’apprentissage grâce à une évaluation dite adaptative permettant de doser la difficulté des exercices en fonction des réponses de l’élève (Gaudreau & Lemieux, 2020 ; Holmes & Tuomi, 2022). Entre les mains des enseignants et des formateurs, ces technologies ambitionnaient de permettre certaines formes sophistiquées de contrôle, de mesures précises ou d’évaluations reposant sur des jeux de critères complexes.
Aujourd’hui, les IA génératives offrent des possibilités nouvelles en matière d’évaluation permettant de se démarquer de l’évaluation à des fins de contrôle ou de certification (Nguyen et al., 2023). C’est notamment le cas en matière d’évaluation formative et d’autoévaluation. Cette approche moins technocentrée consiste à encourager les élèves à pratiquer eux-mêmes l’évaluation des productions automatisées de sorte qu’ils soient à même de déceler les forces et les faiblesses de ces technologies, en testant et en renforçant leurs connaissances en la matière, et en repérant les illusions de forme, les erreurs et les pratiques de désinformation. Cette conception particulière de l’évaluation peut aussi les entraîner à améliorer leurs propres productions afin d’obtenir des résultats de bonne ou d’excellente qualité. Ainsi, Hwang et Chen (2023) proposent, par exemple, d’utiliser les capacités conversationnelles de ChatGPT dans l’enseignement supérieur pour faire de cette application un partenaire de l’étudiant favorisant l’autoévaluation tout au long d’un dialogue avec la machine.
Au fil de cette réflexion, on ne peut que plaider pour que l’usage de ces technologies génératives soit pleinement intégré à la formation et examiné de manière critique. L’expérience tirée de l’usage des calculateurs en ligne[10], des moteurs de recherche généralistes ou spécialisés et de tous les autres outils qui permettent d’obtenir facilement des résultats montre que cette intégration est possible. Les acteurs de l’éducation et de la formation ne pourront pas, de toute manière, faire comme si les IA génératives n’existaient pas.
Tableau récapitulatif des risques et des potentiels liés aux cinq enjeux
Le tableau 1 suivant résume les enjeux présentés dans cet article et tente de mettre en perspective les risques encourus, énoncés dans la partie qui précède, et les potentiels éducatifs et évaluatifs des IA génératives.
L’examen des éléments figurant dans la dernière colonne rappelle que le fait de prendre en considération les enjeux présentés repose sur une véritable évaluation des produits issus de systèmes fondés sur des algorithmes statistiques oeuvrant sur de larges corpus de données. De plus en plus souvent, les productions des IA sont accompagnées de notices indiquant leur origine, par exemple, « Ce texte a été produit par une intelligence artificielle », ou encore de tags invisibles incorporés aux images et aux vidéos générées par des IA. Mais il est encore courant de voir circuler sur les réseaux sociaux des images contrefaites, des textes trompeurs véhiculant des informations susceptibles d’exploiter chez les usagers ce que les psychologues appellent des biais de confirmation ou des biais de croyance à des fins de manipulation.
Les enjeux cités doivent sensibiliser les acteurs de l’éducation à la nécessaire évolution de leurs pratiques d’évaluation, mais aussi de leurs pratiques d’enseignement, dans un contexte où l’existence de ces systèmes ne sera pas contestée, ce qui remet en question l’acceptabilité et/ou la régulation de leur usage en éducation et en formation.
Tableau 1
Récapitulatif des risques et des potentiels liés aux cinq enjeux
Conclusion
Cet article s’est proposé d’explorer, notamment à partir de la littérature scientifique récente portant sur les IA génératives, les problèmes que ces dernières posent à l’évaluation mais aussi les perspectives qu’elles ouvrent en matière de pratiques évaluatives (Rudolph et al., 2023). De nombreux spécialistes s’alarment sur la menace que ces IA font peser sur la démocratie du fait de la désinformation possible et du rapport à la connaissance qu’il détériore (Meirieu, 2023). Mais, même si les grands modèles de langage véhiculent des valeurs et des informations qui ne sont pas pleinement contrôlables[11], ce ne sont pas forcément les algorithmes des IA qui sont par eux-mêmes antidémocratiques. Ce sont principalement des humains qui, en misant sur la crédulité de leurs semblables ou sur leur soif de croyance, détournent ces systèmes ou altèrent les données pour produire une désinformation qui ne peut être déjouée sans contrôle et sans effort. Comme le déclare Luc Julia (2019, p. 140), « Le véritable danger de l’IA vient de nous, humains ». Par conséquent, le risque d’accroissement des inégalités n’est pas négligeable (Colin & Marceau, 2021). Pour diminuer ce risque, il faudra que les élèves soient sensibilisés et conscients des forces mais aussi des faiblesses de fonctionnement de ces systèmes, et que les enseignants intègrent ces technologies dans leurs pratiques d’évaluation et de formation pour en faire des alliées. Dans une perspective future, Quinio et Bidan (2022) parlent même de la nécessité de trouver un nouvel équilibre au sein du ménage à trois que forment les élèves, les professeurs et l’IA.
Les productions des IA génératives concernent autant les élèves que les professeurs ou le citoyen ordinaire. Le développement des technologies ne cessera pas de viser des résultats de plus en plus spectaculaires pour agir sur la fibre émotionnelle et pour marquer les esprits (imitation de la voix humaine[12], résolution de problèmes, exploitation des données personnelles que chacun fournit gracieusement et sans forcément en être conscient aux géants de la technologie). En ce sens, si les IA génératives offrent la perspective d’un défi contemporain d’évaluation, il semble que seules l’éducation et la formation des citoyens plus et moins jeunes permettront de relever.
Appendices
Notes
-
[1]
De manière schématique, en IA, l’apprentissage automatique (machine learning) désigne des méthodes statistiques pour apprendre (inférer des règles) directement à partir de données, alors que l’apprentissage profond (deep learning) désigne un sous-ensemble des méthodes d’apprentissage automatique qui recourt à des réseaux de neurones informatiques pour tirer parti d’immenses bases de données, souvent hétérogènes, et qui trouve plus particulièrement ses applications dans la reconnaissance d’images ou dans le traitement du langage (Shinde & Shah, 2018).
-
[2]
L’histoire de l’intelligence artificielle, du Perceptron imaginé par Franck Rosenblatt en 1957 aux algorithmes du XXIe siècle, et plus particulièrement la concurrence scientifique entre l’approche connexionniste et l’approche symbolique de l’IA, sont notamment documentées dans l’article de Cardon et al. (2018) ou dans l’ouvrage de Luc Julia (2019).
-
[3]
L’étiquetage permettant le traitement initial des masses de données, appelé étiquetage des données (data labeling), est une étape préalable indispensable du traitement par apprentissage automatique. Ce travail est effectué manuellement par des millions de personnes peu qualifiées et payées à la tâche, mais peut parfois être réalisé par les utilisateurs d’Internet sommés de cliquer sur une image ou recopier un élément textuel lors d’opérations de contrôle ou d’identification (CAPTCHA) pour prouver qu’ils sont bien humains.
-
[4]
Il existe actuellement des programmes et des méthodes regroupés sous le nom de IA explicables (XIA) qui permettent, à partir des résultats, de remonter le fil du processus de décision des IA prédictives pour juger de leur fiabilité.
-
[5]
Le nom du programme ChatGPT est composé de chat pour discussion/conversation et GPT pour Generative Pre-trained Transformer. ChatGPT, dans ses différentes versions, est un robot conversationnel (ChatBot) qui exploite une IA spécialisée qui repose sur des données issues d’une part de conversations d’entrainement effectuées par des humains et, d’autre part, qui s’enrichit de données apprises (au sens informatique du terme) et restituées selon des procédés statistiques (Ramponi, 2022).
-
[6]
Les grands modèles de langage (GML) sont des modèles sémantiques utilisés dans les robots conversationnels, les traducteurs automatiques et autres programmes de traitement du langage. Ces modèles algorithmiques, en incorporant des corpus de textes de plus en plus volumineux, sont passés de quelques millions de règles à des centaines de milliards (Lin et al., 2024). Ces GML posent un certain nombre de problèmes au sens où les éléments de textes qui permettent de constituer leurs règles peuvent être biaisés par l’origine et la nature même de ces éléments et véhiculer des stéréotypes, des erreurs ou une vision du monde limitée (Yldrim & Paul, 2023).
-
[7]
Par exemple, Google propose Gemini (Generalized Multimodal Intelligence Network), un système concurrent et Microsoft a intégré un robot de type GPT-4 dans son moteur de recherche Bing.
-
[8]
Récemment, au sein de ce courant, se développe une branche nommée Human-Centered AIED (Holmes & Porayska-Pomsta, 2023 ; Nguyen et al., 2022) où les chercheurs abordent des questions d’éthique, de réduction des inégalités, de menace pour la démocratie et de protection des personnes vulnérables.
-
[9]
Selon Julia (2019), les informaticiens parlent de tendance à halluciner pour qualifier la capacité des IA génératives à inventer ou, plus exactement, à élaborer des réponses de toutes pièces à partir de combinaisons statistiques vraisemblables, incluant la requête de l’utilisateur.
-
[10]
Comme dCode (https://www.dcode.fr/solveur-equation) un solveur en ligne qui permet aux élèves de vérifier l’exactitude de leurs manipulations algébriques, ou l’application Photomath qui réalise cette opération sur un téléphone intelligent à partir d’une simple photographie de l’équation.
-
[11]
Certains modèles sont même conçus pour générer des contenus malveillants (Lin et al., 2024).
-
[12]
La société Microsoft a annoncé, au début de l’année 2023 peu après son investissement de 10 milliards de dollars dans la société OpenIA, la sortie d’une version vocale de ChatGPT, VALL-E, capable d’imiter les intonations émotionnelles de la voix. https://www.microsoft.com/en-us/research/project/vall-e-x/
Liste de références
- Agostini, M. & Abernot, Y. (2011). Penser l’évaluation comme une pratique « humanisante ». Penser l’éducation, 29, 5-16. http://cirnef.normandie-univ.fr/wp-content/uploads/2020/02/Penser-Education_n29_v2.pdf
- Alexandre, F., Becker, J., Comte M.-H., Lagarrigue, A., Libau, R., Romero, M. & Viéville, T. (2021) Why, What and How to Help Each Citizen to Understand Artificial Intelligence ? KI - Künstliche Intelligenz, 35, 191-199. https://doi.org/10.1007/s13218-021-00725-7
- Assunção, G., Patrão, B., Castelo-Branco, M. & Menezes, P (2022). An Overview of Emotion in Artificial Intelligence. Transactions On Artificial Intelligence, 3(6). http://dx.doi.org/10.1109/TAI.2022.3159614
- Cardon, D., Cointet, J. & Mazières, A. (2018). La revanche des neurones. L’invention des machines inductives et la controverse de l’intelligence artificielle. Réseaux, (211), 173-220. https://doi.org/10.3917/res.211.0173
- Collin, S. & Marceau, E. (2021). L’intelligence artificielle en éducation : enjeux de justice. Formation et profession, 29(2), 1-4. https://doi.org/10.18162/fp.2021.a230
- Deng, X. & Yu, Z. A. (2023). A Meta-Analysis and Systematic Review of the Effect of Chatbot technology Use in Sustainable Education. Sustainability, 15(4). https://doi.org/10.3390/su15042940
- Dugan, L., Ippolito, D., Kirubarajan, A., Shi, S. & Callison-Burch, C. (2023). Real or fake text ? Investigating human ability to detect boundaries between human-written and machine-generated text. In Proceedings of the AAAI Conference on Artificial Intelligence, 37(11), 12763-12771. https://doi.org/10.1609/aaai.v37i11.26501
- Gaudreau, H. & Lemieux, M. M. (2020). L’intelligence artificielle en éducation : un aperçu des possibilités et des enjeux. Document préparatoire sur l’état et les besoins de l’éducation (2018-2020). Conseil Supérieur de l’Éducation du Québec (2020). Études et recherches, novembre 2020. https://www.cse.gouv.qc.ca/wp-content/uploads/2020/11/50-2113-ER-intelligence-artificielle-en-education.pdf
- Grinbaum, A. (2023). Parole de machines. Dialoguer avec une IA. humenSciences.
- Gérin-Lajoie, S., Hébert, M.-H. & Papi, C. (2021). L’efficacité des pratiques évaluatives. De la recherche aux applications pratiques de formation à distance. Dans F. Lafleur, J.-M. Nolla & G. Samson (dir.), L’évaluation des apprentissages en FAD : Enjeux, modalités et opportunités de formation en enseignement supérieur (p. 115-148). Presses de l’Université du Québec.
- Hadji, C. (1987). Pour une éthique de l’agir évaluationnel. Mesure et évaluation en éducation, 20(2), 7-26. https://www.erudit.org/fr/revues/mee/1997-v20-n2-mee07190/1091380ar/
- Hadji, C. (2012). Faut-il avoir peur de l’évaluation ? De Boeck.
- Holmes, W. & Porayska-Pomsta, K. (dir.). (2023). The ethics of AI in education. Practices, challenges, and debates. Routledge.
- Holmes, W. & Tuomi, I. (2022). State of the art and practice in AI in education. European Journal of Education Research Development and Policy, 4(57), 542-570. https://doi.org/10.1111/ejed.12533
- Hornberger, M., Bewersdorff, A. & Nerdel, C. (2023). What do university students know about Artificial Intelligence ? Development and validation of an AI literacy test. Computers and Education: Artificial Intelligence, 5. https://doi.org/10.1016/j.caeai.2023.100165
- Hwang, G.-J. & Chen, N.-S. (2023). Editorial Position Paper: Exploring the Potential of Generative Artificial Intelligence in Education: Applications, Challenges, and Future Research Directions. Educational Technology & Society, 26(2). https://doi.org/10.30191/ETS.202304_26(2).0014
- Julia, L. (2019). L’intelligence artificielle n’existe pas . First.
- Kambouchner, D., Meirieu, P. & Stiegler, B. (2012). L’école, le numérique et la société qui vient. Fayard.
- Krutka, D. G., Smits, R. M. & Willhelm, T. A. (2021). Don’t Be Evil: Should We Use Google in Schools ? TechTrends 65, 421–431. https://doi.org/10.1007/s11528-021-00599-4
- Ladage, C. & Chevallard, Y. (2011). Enquêter avec l’internet : études pour une didactique de l’enquête. Éducation et didactique, 5(2), 85-116. https://doi.org/10.4000/educationdidactique.1266
- Le Cam, S. & Maupomé, F. (2023). IA génératives de contenus : pour une obligation de transparence des bases de données . Le Droit en, Débat édition du 11 Mai 2023. Dalloz-Actualités. https://www.dalloz-actualite.fr/node/ia-generatives-de-contenus-pour-une-obligation-de-transparence-des-bases-de-donnees
- Lin, Z., Liao, X., Cui, J. & Wang, X. (2024). Malla: Demystifying Real-world Large Language Model Integrated Malicious Services. arXiv. https://doi.org/10.48550/arXiv.2401.03315
- Meirieu, P. (2023). Le danger de ChatGPT n’est pas dans la fraude qu’il permet mais dans le rapport aux connaissances qu’il promeut. Tribune dans le Journal Le Monde du 27/03/2023. https://www.lemonde.fr/idees/article/2023/03/27/philippe-meirieu-pedagogue-le-danger-de-chatgpt-n-est-pas-dans-la-fraude-qu-il-permet-mais-dans-le-rapport-aux-connaissances-qu-il-promeut_6167089_3232.html
- Morissette, J. (2010). Un panorama de la recherche sur l’évaluation formative des apprentissages. Mesure et évaluation en éducation, 33(3), 1-27. https://doi.org/10.7202/1024889ar
- Nguyen, A., Ngan Ngo, H., Hong, Y, Dang, B. & Nguyen, B. T. (2022). Ethical principles for artificial intelligence in education. Education and Information Technologies. https://doi.org/10.1007/s10639-022-11316-w
- Nigam, A., Pasricha, R., Tarishi, S. & Prathamesch, C. (2022). A Systematic Review on AI-based Proctoring Systems: Past, Present and Future. Education and Information Technologies, 26, 6421-6445. https://doi.org/10.1007/s10639-021-10597-x
- Nolla, J.-M. (2021). La lutte contre le plagiat étudiant dans l’évaluation : une réflexion éthique pour soutenir les enseignants en formation à distance. Dans F. Lafleur, J.-M. Nolla & G. Samson (dir.), L’évaluation des apprentissages en FAD : Enjeux, modalités et opportunités de formation en enseignement supérieur (p. 57-73). Presses de l’Université du Québec.
- Opara, E., Adalikwu Mfon-Ette, T. & Tolorunleke C. A., (2023). ChatGPT for Teaching, Learning and Research: Prospects and Challenges. Global Academic Journal of Humanities and Social Sciences, 5(2), 33-40. http://dx.doi.org/10.36348/gajhss.2023.v05i02.001
- Polyportis, A. & Pahos, N. (2024). Understanding students’ adoption of the ChatGPT chatbot in higher education: the role of anthropomorphism, trust, design novelty and institutional policy. Behaviour & Information Technology. https://doi.org/10.1080/0144929X.2024.2317364
- Quinio, B. & Bidan, M. (2023). ChatGPT : Un robot conversationnel peut-il enseigner ? Management & data science, 7(1). https://doi.org/10.36863/mds.a.22060
- Ramponi, M. (2022). How ChatGPT actually works ? AssemblyAI. https://www.assemblyai.com/blog/how-chatgpt-actually-works/
- Rudolph, J., Tan, S. & Tan, S. (2023). ChatGPT: Bullshit spewer or the end of traditional assessment in higher education ? Journal of Applied Learning & Teaching, 6(1). https://doi.org:1037074/4/jalt.2023.6.1.9
- Shinde, P. P. & Shah, S. (2018). A Review of Machine Learning and Deep Learning Applications. 2018 Fourth International Conference on Computing Communication Control and Automation (ICCUBEA), 1-6. https://doi.org/10.1109/ICCUBEA.2018.8697857
- Unesco (2019). Beijing consensus on artificial intelligence and education. International Conference on Artificial Intelligence and Education, Planning Education in the AI Era: Lead the Leap, Beijing, 2019. https://unesdoc.unesco.org/ark:/48223/pf0000368303
- Wang, J., Hu, X., Hou, W., Chen, H., Zheng, R., Wang, Y. & Xie, X. (2023). On the robustness of ChatGpt: An adversarial and out-of-distribution perspective. arXiv:2302.12095. https://doi.org/10.48550/arXiv.2302.12095
- Xia, Q., Chiu, T., Chai, C. S. & Xie, K. (2023). The mediating effects of needs satisfaction on the relationships between prior knowledge and self-regulated learning through artificial intelligence chatbot. British Journal of Education Technology, 1-20. https://doi.org/10.1111/bjet.13305
- Yildrim, I. & Paul, L. A. (2023). From task structures to world models: What do LLMs know ? arXiv. https://doi.org/10.48550/arXiv.2310.04276
- Zhai, X. (2022). ChatGPT User Experience: Implications for Education. SSRN. http://dx.doi.org/10.2139/ssrn.4312418
 10.7202/1091380ar
10.7202/1091380arList of tables
Tableau 1
Récapitulatif des risques et des potentiels liés aux cinq enjeux