
Article body
Introduction
L’objet principal de cet article est d’offrir une approche du problème de la sélection du mécanisme de vote au sein du conseil des représentants d’une union fédérale. Nous postulons sans expliquer pourquoi (dans cet article) que plusieurs entités autonomes (des pays, des régions, des communes,...) renoncent (on parle alors pudiquement de transferts de compétences) à exercer unilatéralement leur autorité sur tout ou partie des questions de politique économique, sociétale, militaire, diplomatique qui étaient ou qui pourraient relever de leur souveraineté exclusive. Cet article n’est donc pas un article sur le fédéralisme et par conséquent le lecteur ne doit pas s’attendre à y trouver une analyse des gains et bénéfices d’une union fédérale. Nous supposons que l’union fédérale et les questions relevant de ses compétences sont données au départ. De plus, nous supposerons qu’à chaque fois qu’un problème de choix se présente, il se présente de façon binaire, c’est-à-dire que les représentants en charge de prendre la décision n’ont que deux choix possibles : voter pour ou voter contre la proposition formulée. Dans la réalité, l’univers des choix est plus complexe et peut d’ailleurs faire l’objet lui-même de calculs stratégiques[1]. Le modèle que nous avons en tête est donc un modèle très simplifié qui accentue l’affrontement entre deux camps sur chaque question débattue à l’échelon fédéral[2]. En sus de ces simplifications, nous allons nous limiter au cas d’un modèle de décision collective où chaque entité (même si cette entité est elle-même le théâtre de conflits sur les préférences) est représentée par un unique membre dont la préférence reflètera les opinions de son entité (parfois de manière imparfaite ou même biaisée). Pratiquement, il s’agit d’étudier un modèle de « Conseil des ministres » et non un modèle de parlement dont les membres auraient été élus à la proportionnelle et représenteraient donc la diversité des préférences de leur entité d’appartenance[3]. Dans le cas du conseil des ministres, le principe the winner takes all s’applique sans nuances : chaque représentant s’aligne sur la position « dominante » chez ses concitoyens.
Ayant précisé ces limites et réserves, nous pouvons formuler la question fondamentale qui sera au coeur de cet article : étant donné un ensemble d’entités dont certaines décisions, postulées dichotomiques, sont prises par un conseil fédéral où chaque entité est représentée par un unique représentant, quel est le mécanisme de vote le meilleur au regard d’un objectif qui reste à définir ? Il s’agit donc d’une certaine manière d’un problème de mechanism design ou de théorie du choix social dont le champ d’application est circonscrit mais qui couvre un grand nombre de situations réelles. Les auteurs de cet article pensent tout d’abord[4] au conseil de l’Union européeenne, dit Conseil des ministres, qui est une institution (comptant 28 représentants en 2016, et bientôt 27 du fait du retrait annoncé de la Grande Bretagne de l’Union européenne) jouant un rôle de tout premier plan dans la prise de décision des questions européennes. Bien sûr, on ne saurait trop insister sur le fait que le Conseil de l’Union européene ne prend pas seul les décisions[5]. Son pouvoir est contrebalancé par celui du Parlement européen, de la Commission européenne et du Conseil européen. Avant le traité de Lisbonne, le mécanisme de vote était essentiellement un mécanisme majoritaire pondéré avec majorité qualifiée de 260 sur un poids total de 352 (environ 74 %). Les poids de la France et de l’Allemagne y étaient de 29 alors que les poids de la Pologne et de l’Espagne étaient de 27, etc. et celui de Malte de 3. Le traité de Lisbonne a supprimé la pondération arbitraire des voix et instauré un système à double majorité pour l’adoption des décisions. La majorité qualifiée est atteinte si elle regroupe au moins 55 % des États membres représentant au moins 65 % de la population de l’Union européenne. Lorsque le Conseil ne statue pas sur une proposition de la Commission, la majorité qualifiée doit alors atteindre au moins 72 % des États membres représentant au moins 65 % de la population. Un tel système attribue donc une voix à chaque État membre tout en tenant compte de son poids démographique[6]. Ce nouveau système de vote à la majorité qualifiée est applicable depuis le 1er novembre 2014 (mais avec une possibilité d’utilisation du système de vote défini par le traité de Nice au cas par cas jusqu’au 31 mars 2017). Au nom de quelle logique ces poids ont-ils été proposés ? Ce nouveau traité est le nième épisode d’une longue histoire d’âpres discussions et controverses souvent concomitantes aux opérations d’élargissement. Une pétition initiée par des chercheurs a même circulé pour réclamer au nom de la science une représentation des États basée sur la racine carrée de leur population (et non directement sur leur population)[7]. Aujourd’hui mais moins qu’hier le système est complexe car il fait intervenir plusieurs mécanismes de vote qu’une proposition doit passer avec succès pour pouvoir être adoptée : superposer des critères faisant intervenir la population des pays ou leur nombre et des quotas associés rend ainsi plus difficile l’adoption d’une mesure.
À des nuances institutionnelles près, la question ci-dessus se pose dans bien d’autres contextes. Par exemple, elle se pose en France au niveau des structures intercommunales : les communes représentées au sein d’une structure intercommunale n’ont pas toutes le même nombre de délégués et, si tant est que ces délégués votent en bloc par commune, le même poids (voir par exemple Bisson, Bonnet, Lepelley, 2004). Elle se pose aussi indiscutablement au sein des grandes organisations internationales qui prennent des décisions concernant tous les pays membres, comme par exemple le FMI (voir Leech, 2002b). D’une certaine manière, le problème couvert dans cet article est également formellement équivalent à celui d’un pays doté d’un régime présidentiel dominé par deux partis politiques principaux et qui aurait hérité de son histoire une structure fédérale (découpage du pays en États) obligeant l’élection du président à être indirecte et du type « le gagnant d’un État récupère tous les grands électeurs de l’État ». On aura reconnu dans cette description le contexte du collège électoral américain et les modalités d’élection de son président. Même si on maintient le système en l’état, on est en droit de se demander en vertu de quels principes la Californie dispose de 55 grands électeurs alors que le Texas n’en compte que 38 ! On voit donc apparaître au travers de tous ces exemples un dénominateur commun qui prend appui sur la nature de second rang du problème posé : étant donné des frontières naturelles entre entités/districts/États/communes et l’impossibilité conséquente d’organiser un mécanisme de vote direct, quelle est la meilleure façon d’organiser un mécanisme de vote indirect ? Et plus précisement, dans un système de type « conseil des ministres », quel poids doit-on donner à chaque représentant et quel quota doit-on utiliser sachant que le comportement du représentant en réaction aux préférences des membres de son entité est une donnée hors du champ de l’optimisation ? Nous insistons sur le fait qu’au moment où la conception du mécanisme le plus approprié est formulée, l’incertitude concernant les préférences des citoyens des entités n’a pas été levée. Nous ne sommes donc pas à un stade ex post mais à un stade ex ante c’est-à-dire constitutionnel (Rae, 1969; Curtis, 1972; Schofield, 1972) où l’on cherche à mettre en place des règles durables car elles seront utilisées de façon répétée.
Le mot « meilleur » n’est bien sûr pas dépourvu d’ambiguïté. Dans le contexte politique de la dernière illustration, on songe immédiatement à un principe égalitariste (one man, one vote). La voix d’un électeur du Texas doit avoir le même poids que celle d’un électeur de Californie. Similairement, dans le contexte de l’Union européenne, on peut légitimement souhaiter que la voix d’un citoyen polonais compte de la même façon que celle d’un citoyen portugais. Il conviendrait ainsi de faire en sorte que le « pouvoir » d’un électeur (qui reste à ce stade un concept à définir) soit le même quel que soit l’État où il réside. Il reste cependant que dans d’autres contextes, on pourra juger opportun de remplacer cet objectif égalitariste par un objectif utilitariste où les enjeux (stakes) des différents électeurs sont pris en considération[8]. Nous retrouvons de fait, pour juger des qualités d’un mécanisme de vote indirect, un critère très commun en économie publique, à savoir la maximisation de la somme des utilités. On verra alors que la principale implication du critère utilitariste est une version du principe majoritaire où les différentes entités ont des poids différents : le vote majoritaire pondéré. Au nombre des éléments à prendre en compte dans la détermination de la pondération figure naturellement la taille des populations des entités. Une entité plus peuplée devrait jouir d’un poids plus grand mais comment cette prise en compte de la démographie se décline-t-elle dans le détail ? L’idée la plus courante est l’idée de proportionnalité : représenter chaque entité à la hauteur de sa population. La proportionnalité est une idée simple et profonde qui a des racines philosophiques anciennes et nous verrons dans cet article que l’approche développée ici confirme cette intuition de bon sens dans de nombreux cas; en particulier lorsque les préférences des citoyens d’une même entité sont parfaitement corrélées, le vecteur des poids optimaux du point de vue de l’utilitarisme est le vecteur des populations. Naturellement, si les variables poids sont soumises à des contraintes d’intégralité (comme dans le collège électoral américain), il faut arrondir ceux-ci; il y a alors de nombreuses façons de décliner le principe de proportionnalité qui sont loin d’avoir les mêmes propriétés axiomatiques (voir Balinski et Young, 1982; Pukelsheim, 2014). Dans le présent travail, nous nous affranchirons des contraintes entières.
Par ailleurs, il est important de noter que l’objectif utilitariste ne débouche pas nécessairement sur une version aussi simple de la proportionnalité. Il pourra aussi déboucher sur une version dégressive de la proportionnalité lorsque le poids relatif du représentant d’un pays rapporté à sa population décroît en fonction de sa population. Par exemple, nous verrons que dans l’hypothèse extrême où tous les pays sont parfaitement clivés, les poids optimaux dans le cas utilitariste/linéaire évoluent comme la racine carrée de la population. Nous rencontrerons plusieurs autres scénarios qui vont dans cette direction. Notons enfin que dans l’examen d’un problème proche, celui de la détermination du nombre de représentants de chaque pays dans le Parlement européen, le principe de proportionnalité dégressive a fait l’objet d’une étude sous l’autorité d’un panel d’experts qui a débouché sur une règle de proportionnalité dégressive qui se présente comme une solution affine (un poids minimal et une augmentation incrémentale proportionnelle à la population ensuite) appelée « compromis de Cambridge » (Laslier, 2012).
L’article est organisé comme suit. Après avoir présenté formellement le problème de décision collective étudié, la seconde section expose notre scénario canonique, celui de la solution au problème de vote indirect optimal dans le cas où l’objectif est la maximisation de la somme des utilités espérées. Cette solution, dont la version générale est due à Barberà et Jackson (2006), est décrite et comparée à plusieurs autres contributions importantes de même nature. Une discussion de certains aspects de la solution de Barberà et Jackson prolongera son exposé dans la section 2. La section 3 est consacrée à l’examen du problème lorsque nous envisageons d’autres critères que la maximisation de l’utilité pour juger de la pertinence d’une règle de vote indirecte. Dans la section 4, la nature même du modèle canonique est changée : nous présenterons plusieurs contributions pour lesquelles nous abandonnons l’hypothèse de choix dichotomique entre deux options pour des ensembles de décision plus riches.
1. Le mécanisme optimal dans le cas de l’utilitarisme
1.1 Le contexte : électorat aléatoire et mécanisme de vote
Nous souhaitons décrire ici formellement la situation d’une communauté d’entités/districts qui a renoncé à exercer sa souveraineté sur un ensemble de questions. Ces entités peuvent être des pays comme dans le cas de l’Union européenne, ou des États comme dans le cas des États-Unis d’Amérique ou encore des municipalités comme dans le cas des communautés de communes et d’agglomérations françaises. Chaque entité composant cette fédération est peuplée par des individus/citoyens et nous considérons dans cette section comme dans la suivante qu’ultimement, seul le bien-être des citoyens résidant dans ces entités est pris en compte dans l’évaluation de la décision collective. Formellement, la population totale de la « fédération » notée N = {1,2,…,n} est partitionnée en Kdistricts Nk ,k = 1,…,K[9]. Nous noterons nk le nombre de citoyens habitant le district k; on supposera que nk est impair. Ces K districts sont supposés décrire des frontières naturelles et/ou anciennes et nous insistons sur le fait que le redécoupage de ceux-ci n’est pas une variable d’optimisation : la carte des districts est donc exogène.
Nous supposons que les décisions qui s’appliquent à l’échelon fédéral sont prises par un comité composé d’un représentant de chaque district : le comité comprend donc K membres. Nous supposerons par ailleurs que la décision est de nature binaire : pour (codée 1) ou contre (codée 0) une proposition qui est faite pour remplacer le statu quo (et qui, le cas échéant, a été préparée à l’avance en commission). Au sein du comité, les membres devront voter par oui ou par non à la proposition soumise[10]. Nous supposerons que l’abstention n’est pas possible/permise. La décision au sein du conseil est alors décrite par un mécanisme de vote C. Précisément, C est une fonction de {0,1}K dans {0,1}, où C prend la valeur 1 si la proposition est retenue et 0 sinon. Dans le cas où C est monotone, la notion de mécanisme de vote est une notion combinatoire (appelée parfois fonction booléenne) qu’il est commode de décrire de façon équivalente à l’aide de la notion de jeu simple (Shapley,1962; Taylor et Zwicker, 1999), notion importante en théorie des jeux coopératifs et à laquelle est consacré l’appendice.
Outre la carte des districts et les caractéristiques démographiques de ceux-ci, l’input de base est constitué par l’utilité que les différents citoyens retirent de la proposition si elle est retenue ou rejetée. L’espace des états possibles est l’ensemble des profils d’utilités. En normalisant à 0 l’utilité de chaque citoyen dans le cas d’un rejet de la proposition, un état possible est donc un vecteur U = (U1,U2,…,Un) ∈ Rn : le type du citoyen i est un nombre réel Ui décrivant son utilité nette pour l’alternative 1. Une valeur Ui > 0 (respectivement < 0) indique que l’individu i préfère l’option 1 au statu quo 0 (respectivement 0 à 1). Un modèle aléatoire est décrit par une loi de probabilité jointe λ sur l’ensemble des états possibles Rn. Nous noterons Prλ(A) la probabilité de l’événement A ⊆ Rn. On notera λk la marginale du district k et λi la marginale du citoyen i. Le modèle aléatoire λ est dit neutre si pour tout k = 1,…,K et tout ensemble mesurable ![]() ,
, ![]() . Le modèle aléatoire λ est symétrique si pour tout k = 1,…,K et tout ensemble mesurable
. Le modèle aléatoire λ est symétrique si pour tout k = 1,…,K et tout ensemble mesurable ![]() et toute permutation σ de Nk,
et toute permutation σ de Nk, ![]() où
où ![]() tel que u = σ(υ)}. On remarque que si λ est symétrique, alors pour tout k = 1,…,K : E(Uj |Uj ≥ 0) = E(Ui|Ui ≥ 0) et E(Uj|Uj ≤ 0) = E(Ui|Ui ≤ 0) pour tout i, j ∈ Nk. Dans cet article, nous supposerons que les préférences des citoyens sont indépendantes entre districts.
tel que u = σ(υ)}. On remarque que si λ est symétrique, alors pour tout k = 1,…,K : E(Uj |Uj ≥ 0) = E(Ui|Ui ≥ 0) et E(Uj|Uj ≤ 0) = E(Ui|Ui ≤ 0) pour tout i, j ∈ Nk. Dans cet article, nous supposerons que les préférences des citoyens sont indépendantes entre districts.
Le mécanisme de décision comporte donc deux étages (two tier mechanism). Une première fonction décrit comment les préférences des citoyens des différentes entités influencent l’opinion de leurs représentants (notons ici qu’un représentant est décrit par une opinion et non par une utilité). Formellement, ceci est décrit par une fonction m : Rn →{0,1}k; mk (U) = 1 signife que dans le cas du vecteur U, le représentant de l’entité k est en faveur de 1. Nous supposerons que mk ne dépend que du sous-vecteur ![]() . Si le représentant suit l’opinion majoritaire dans son district,
. Si le représentant suit l’opinion majoritaire dans son district, ![]() (on peut alors parler de représentant de type majoritaire). Si en revanche le représentant base son vote sur le critère utilitariste restreint à son district,
(on peut alors parler de représentant de type majoritaire). Si en revanche le représentant base son vote sur le critère utilitariste restreint à son district, ![]() (on peut alors parler de représentant de type utilitariste)[11]. La seconde fonction, notée C ci-dessus, décrit comment les votes des représentants (m1(U),…, mK (U)) = m(U) sont transformés en une décision collective.
(on peut alors parler de représentant de type utilitariste)[11]. La seconde fonction, notée C ci-dessus, décrit comment les votes des représentants (m1(U),…, mK (U)) = m(U) sont transformés en une décision collective.
1.2 Le théorème de Barberà et Jackson
Nous allons nous concentrer ici sur un critère d’optimisation particulier, à savoir la maximisation de la somme des utilités espérées. Faute d’espace, nous n’allons pas à ce stade offrir une défense axiomatique de ce critère de choix social[12].
Ex ante, c’est-à-dire avant de découvrir sa propre (dés)utilité pour l’adoption de la proposition, chaque citoyen i évalue son utilité espérée Wi(C,λ) pour le mécanisme C. Avec les notations ci-dessus :
Le bien-être utilitariste est donc égal à :
Le choix optimal ex post est 1 (respectivement 0) lorsque ![]() (respectivement < 0). Ce choix optimal ne sera pas en général réalisé par le mécanisme considéré. Non seulement toute ou partie de l’information sur l’intensité des préférences disparaît mais la délégation finale de la décision à des représentants ouvre la porte à une différence entre le choix des représentants et le choix à l’échelle de la population toute entière. Nous recherchons ici le (les) mécanisme(s) de vote C maximisant l’espérance totale d’utilité, qui s’écrit :
(respectivement < 0). Ce choix optimal ne sera pas en général réalisé par le mécanisme considéré. Non seulement toute ou partie de l’information sur l’intensité des préférences disparaît mais la délégation finale de la décision à des représentants ouvre la porte à une différence entre le choix des représentants et le choix à l’échelle de la population toute entière. Nous recherchons ici le (les) mécanisme(s) de vote C maximisant l’espérance totale d’utilité, qui s’écrit : ![]() .
.
Par définition :
Puisque, par hypothèse, les utilités sont indépendantes entre districts, l’utilité totale espérée s’écrit plus simplement comme suit :
On déduit de cette expression que si l’on peut trouver un mécanisme C maximisant ![]() , pour toute réalisation possible r = (r1,…, rk) ∈ {0,1}K, ce mécanisme C maximisera, a fortiori, la somme pondérée de ces expressions. On remarque immédiatement que ce mécanisme existe et vérifie :
, pour toute réalisation possible r = (r1,…, rk) ∈ {0,1}K, ce mécanisme C maximisera, a fortiori, la somme pondérée de ces expressions. On remarque immédiatement que ce mécanisme existe et vérifie :
Définissons pour chaque district k les poids suivants :
Avec ces notations, les formules (1) ci-dessus s’écrivent :
ou encore :
où ![]() pour tout k = 1,…, K. Dans le cas particulier où
pour tout k = 1,…, K. Dans le cas particulier où ![]() , les choix 0 et 1 définissent le même niveau d’utilité totale espérée. Rappelons également que bien que le mécanisme soit décrit par un vecteur de poids et un quota, ce qui importe avant tout est l’inventaire des coalitions décisives[13]. On peut donc énoncer le théorème suivant :
, les choix 0 et 1 définissent le même niveau d’utilité totale espérée. Rappelons également que bien que le mécanisme soit décrit par un vecteur de poids et un quota, ce qui importe avant tout est l’inventaire des coalitions décisives[13]. On peut donc énoncer le théorème suivant :
Théorème(Barberà et Jackson, 2006)
Si les utilités sont indépendantes entre districts, les mécanismes C qui maximisent l’utilité totale espérée sont représentés par :
Il convient maintenant de comprendre plus en profondeur à quoi ressemble ce mécanisme optimal et le rôle des différentes hypothèses qui ont permis de dériver ce résultat. Ce qui est très surprenant est que le mécanisme optimal est toujours un jeu majoritaire pondéré alors que la classe des jeux simples concevables est beaucoup plus grande, comme l’illustrent les énumérations reportées dans l’appendice.
Nous dirons que le district k est biaisé avec un biais γk > 0 si :
Le biais d’un district définit la différence entre l’utilité totale espérée du district lorsque son représentant vote 1 et l’utilité totale espérée du district lorsque son représentant vote 0. Dans ce cas le mécanisme optimal est décrit par les poids ![]() pour k = 1,…, K et le quota
pour k = 1,…, K et le quota ![]() .
.
On note que dans le cas où le biais est le même dans tous les districts, noté γ, alors le mécanisme de vote s’écrit simplement :
Le vote « pour » de chaque membre k du comité est affecté d’un poids ![]() qui sera noté (sauf mention contraire) wk dans la suite de cet exposé. Le vote pour la proposition l’emporte si la fraction des poids des supporters dépasse un seuil qui dépend du biais. On remarque au passage que si les districts ne sont pas biaisés, c’est-à-dire si γ = 1, alors le seuil correspond au seuil majoritaire ordinaire de 50 %. Dans la suite, nous nous référerons au vecteur comme étant le vecteur de poids de Barbera Jackson.
qui sera noté (sauf mention contraire) wk dans la suite de cet exposé. Le vote pour la proposition l’emporte si la fraction des poids des supporters dépasse un seuil qui dépend du biais. On remarque au passage que si les districts ne sont pas biaisés, c’est-à-dire si γ = 1, alors le seuil correspond au seuil majoritaire ordinaire de 50 %. Dans la suite, nous nous référerons au vecteur comme étant le vecteur de poids de Barbera Jackson.
On notera que le biais peut avoir deux sources différentes. La distribution de probabilité peut elle-même exprimer un biais en faveur de l’une ou l’autre des options (alors que le représentant n’est pas biaisé en faveur d’une option). Par exemple, si le représentant n’est pas biaisé mais si pour tout i, Ui prend les valeurs -γ < -1 et 1 avec la probabilité ![]() , un vote en faveur de la réforme révèle un gain plus faible que la perte attachée à un vote contre la réforme. Il n’est donc pas surprenant en pareil cas de voir le quota être élevé au seuil de
, un vote en faveur de la réforme révèle un gain plus faible que la perte attachée à un vote contre la réforme. Il n’est donc pas surprenant en pareil cas de voir le quota être élevé au seuil de ![]() : pour défaire le statu quo, il faut une majorité qualifiée de taille suffisante. Mais le biais peut résulter du comportement du représentant. Ce sera le cas par exemple si le représentant du district k vote pour la proposition uniquement si tous les citoyens du district k votent de la sorte.
: pour défaire le statu quo, il faut une majorité qualifiée de taille suffisante. Mais le biais peut résulter du comportement du représentant. Ce sera le cas par exemple si le représentant du district k vote pour la proposition uniquement si tous les citoyens du district k votent de la sorte.
Notons enfin que dans le cas où les représentants sont de type majoritaire, les poids de Barberà-Jackson peuvent être négatifs : le mécanisme optimal n’est pas nécessairement monotone si l’espérance de la somme des utilités dans un district est du signe contraire de la décision de son représentant (majoritaire). Par exemple, dans le cas où le district k est tel que nk = 3 et λ est équiprobable sur les vecteurs (1, 1, -3) et (-1, -1, 3) et leurs permutés, on obtient ![]() . Cette situation pathologique intervient exlusivement dans des cas de modèles aléatoires un peu artificiels comme celui présenté ci-dessus[14]. Dans la suite de cet article nous supposerons que les poids de Barbera-Jackson sont positifs.
. Cette situation pathologique intervient exlusivement dans des cas de modèles aléatoires un peu artificiels comme celui présenté ci-dessus[14]. Dans la suite de cet article nous supposerons que les poids de Barbera-Jackson sont positifs.
Nous supposerons aussi que pour tout j ∈ N, λj n’a pas de masse en 0. Par ailleurs, nous allons laisser de côté la question du biais et supposer, sauf mention contraire, que les représentants des districts sont des représentants de type majoritaire. Précisément, pour ce faire, nous supposerons que le modèle aléatoire λ est neutre[15].
On vérifiera en effet que dans ce cas : ![]() ,
,
![]() pour tout i ∈ Nk et
pour tout i ∈ Nk et ![]() pour tout k = 1,…, K. Par ailleurs, une attention particulière sera accordée à plusieurs cas particuliers importants. Au nombre de ceux-ci, figure le cas binaire qui correspond au cas où pour tout i ∈ N, Ui prend deux valeurs symétriques par rapport à 0 (disons 1 et -1)[16]. Dans ce cas, le mécanisme qui maximise l’utilité totale ex post est le mécanisme majoritaire ordinaire (à un seul étage) : l’espérance de l’utilité totale du mécanisme ex post optimal est donc l’espérance de la taille du groupe majoritaire. En revanche, le mécanisme optimal dans le cas où il y a deux étages et où le représentant suit sa majorité peut produire des décisions collectives très différentes du mécanisme majoritaire, même dans le cas où les districts sont équipeuplés et identiques du point de vue de la loi λ.
pour tout k = 1,…, K. Par ailleurs, une attention particulière sera accordée à plusieurs cas particuliers importants. Au nombre de ceux-ci, figure le cas binaire qui correspond au cas où pour tout i ∈ N, Ui prend deux valeurs symétriques par rapport à 0 (disons 1 et -1)[16]. Dans ce cas, le mécanisme qui maximise l’utilité totale ex post est le mécanisme majoritaire ordinaire (à un seul étage) : l’espérance de l’utilité totale du mécanisme ex post optimal est donc l’espérance de la taille du groupe majoritaire. En revanche, le mécanisme optimal dans le cas où il y a deux étages et où le représentant suit sa majorité peut produire des décisions collectives très différentes du mécanisme majoritaire, même dans le cas où les districts sont équipeuplés et identiques du point de vue de la loi λ.
1.3 Comparaison des mécanismes à l’aide des poids de Barberà-Jackson dans le cas neutre
L’utilité totale W(C; λ) évaluée à l’échelle de la fédération est égale à :
Puisque λ est neutre :
on en déduit :
Or,
Nous déduisons également de la neutralité de λ que le second terme du membre droit de cette égalité vaut ![]() . Le premier terme est égal à la probabilité de succès. Puisque
. Le premier terme est égal à la probabilité de succès. Puisque ![]() pour tout k = 1,…, K et que les votes des différents représentants sont indépendants, on déduit de la formule de Penrose[17] (Dubey et Shapley, 1979; Felsenthal et Machover, 1998 : théorème 3.2.16; Laruelle et Valenciano, 2008c : section 3.6) :
pour tout k = 1,…, K et que les votes des différents représentants sont indépendants, on déduit de la formule de Penrose[17] (Dubey et Shapley, 1979; Felsenthal et Machover, 1998 : théorème 3.2.16; Laruelle et Valenciano, 2008c : section 3.6) :
où Bk (C) désigne l’indice de pouvoir de Banzhaf[18] du représentant du district k dans le mécanisme C. En combinant ces expressions, on déduit que :
L’intérêt de cette formule que l’on trouve dans Beisbart et Bovens (2007) est de mettre en évidence le rôle du vecteur des poids de Barberà-Jackson w(λ) = (w1(λ), w2(λ),…,wK(λ)) dans le calcul de l’utilité totale espérée d’un mécanisme Cquelconque au travers du vecteur des indices de Banzhaf des représentants du conseil. Nous savons d’après Barberà et Jackson que cette expression est maximale lorsque C est le jeu majoritaire pondéré avec un seuil de 50 % et le vecteur de poids w. Beisbart et Bovens offrent une preuve alternative du théorème de Barberà et Jackson exploitant cette formule. Mais l’intérêt principal de la relation (3) est de permettre un classement complet de tous les mécanismes et non uniquement de déterminer le meilleur d’entre eux. À l’aide de cette formule, on peut comparer l’utilité totale espérée des différents mécanismes de vote. Cette analyse est le sujet d’une série d’articles importants de Beisbart, Bovens et Hartmann (2005) et Beisbart et Bovens (2007) sur le Conseil des ministres de l’Europe. Signalons que leur analyse est réalisée dans le cas où les représentants sont des représentants utilitaristes mais la formule ci-dessus n’exploite pas cette hypothèse.
Notons finalement que l’on peut, alternativement, présenter la grandeur caractérisant la qualité/performance d’un mécanisme sous la forme d’un « manque à gagner ». Comme nous l’avons déjà signalé, l’idéal utilitaire serait de maximiser ![]() . Dans ce cas, comme
. Dans ce cas, comme ![]() , l’utilité totale espérée maximale est égale à :
, l’utilité totale espérée maximale est égale à :
On peut donc alternativement résumer le coût social du mécanisme C comme étant égal à :
Ce coefficient correspond à ce que Weber (1978, 1995) définit comme étant l’effectivité[19] du mécanisme de vote C. Nous verrons plus loin une autre normalisation utile.
2. De quoi dépendent les poids de Barberà-Jackson[20] ?
Comme nous venons de le voir, les poids de Barberà-Jackson jouent un rôle de premier plan dans l’analyse comparative des mécanismes de vote au sein du conseil fédéral. L’objet principal de cette section est d’identifier les éléments (tels que décrits par la loi λ) qui poussent à donner plus de poids au vote du représentant d’un district. On anticipe qu’un district plus peuplé recevra un poids au moins aussi important qu’un district moins peuplé mais quelle est la nature exacte de cette relation ? L’intuition suggère par ailleurs que le représentant d’un district consensuel recevra plus de poids que celui d’un district clivé. Nous allons maintenant examiner et quantifier ces idées au travers du calcul formel. Après un exercice de détermination empirique des poids dû à Barberà et Jackson, nous considèrerons une famille large de lois de tirage, qui satisfont à la condition d’échangeabilité; comme cas particulier, nous retrouverons deux des distributions les plus célèbres en théorie des choix collectifs, les modèles de culture impartiale (IC, pour Impartial Culture) et de culture impartiale anonyme (IAC, pour Impartial Anonymous Culture). Nous continuerons en étudiant des scénarios dans lesquels chaque district est composé de blocs homogènes de votants. Enfin, nous terminerons par un modèle original où chaque citoyen tire son utilité selon une même loi gaussienne, avec des représentants de type utilitariste.
2.1 Poids et marge de victoire électorale
Nous allons ici donner quelques réponses à la question du calcul des poids dans un modèle λ où l’information cardinale est séparée de l’information ordinale. Cette notion est introduite dans Le Breton et Van der Straeten (2015b). Précisément, nous supposerons que dans chaque district k, un vecteur ![]() est tiré selon une certaine loi de probabilité neutre.
est tiré selon une certaine loi de probabilité neutre.
Indépendamment de Xk, on tire au hasard un vecteur ![]() dans
dans ![]() . On supposera que les nk coordonnées sont indépendantes et identiquement distribuées avec un moment d’ordre 1 fini noté ξk. Pour tout i = 1,…, nk, l’utilité du citoyen i pour l’option 1 est définie par la variable aléatoire :
. On supposera que les nk coordonnées sont indépendantes et identiquement distribuées avec un moment d’ordre 1 fini noté ξk. Pour tout i = 1,…, nk, l’utilité du citoyen i pour l’option 1 est définie par la variable aléatoire :
Dans le cas du modèle aléatoire neutre λ ainsi défini, la corrélation entre les citoyens est exclusivement ordinale, au sens où Xi > 0 informe sur le signe de Ui mais non sur sa valeur. Soit Sk l’ensemble des citoyens de Nk votant pour 1 (les autres votant pour 0). Des hypothèses ci-dessus, on déduit :
 (les électeurs dans Sk votent 1 et les autres votent 0) × (2|Sk|– nk).
(les électeurs dans Sk votent 1 et les autres votent 0) × (2|Sk|– nk).
Si l’on définit ![]() ,
,
on remarque que : ![]()
où ![]() est la marge de victoire espérée dans le district k. En résumé, à la constante ξk multiplicative près, le poids de Barberà-Jackson du district k est entièrement déterminé par la marge espérée dans le district. Dans la suite de cette section, nous supposerons que ξk = 1 pour tout k = 1,…, K.
est la marge de victoire espérée dans le district k. En résumé, à la constante ξk multiplicative près, le poids de Barberà-Jackson du district k est entièrement déterminé par la marge espérée dans le district. Dans la suite de cette section, nous supposerons que ξk = 1 pour tout k = 1,…, K.
L’enquête Eurobarometer est une enquête d’opinion qui pose règulièrement les mêmes questions aux citoyens de tous les pays de l’Union européenne. Dans une version document de travail de leur article, Barberà et Jackson (2004) exploitent les réponses à 11 questions dichotomiques[21] extraites de l’enquête datée de décembre 2003 pour obtenir une moyenne empirique de la marge relative de victoire (définie ici comme la valeur moyenne de l’écart absolu entre les opinions favorables et les opinions défavorables ). Ces valeurs d’écart moyen sont reportées dans le tableau 1. La valeur 70,1 pour Chypre indique qu’en moyenne, les citoyens de ce pays ont répondu de manière très consensuelle aux 11 questions posées. À l’inverse, au Royaune-Uni, les écarts sont plus faibles en moyenne (36,6).
Tableau 1
Marges de victoire estimées (UE 27)
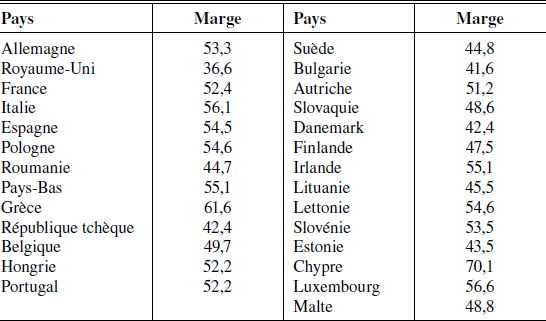
Ainsi, ils obtiennent un proxy sur la manière dont les citoyens européens voteraient sur des questions d’intérêt général qui leur seraient soumises et sur la valeur des poids wk : ils sont obtenus en multipliant la taille de la population par la marge de victoire, et présentés dans le tableau 2. Ainsi, le poids de l’Allemagne 44,1 résulte du produit de sa population (82,3 millions d’habitants) par sa marge. La plupart des pays sont fortement consensuels : Chypre détient le record mais le Royaume-Uni est le plus clivé. À ce jeu, il est le grand perdant. Puisque sa population est en moyenne plus divisée que celle des autres pays sur les questions posées, son poids est nettement inférieur à sa population (59,5 millions × 0,366 = 21,8). Comme le font remarquer Barberà et Jackson, une régression linéaire de la marge sur la population fait apparaître un coefficient de -0,007. Autant dire qu’ici (le Royaume-Uni mis à part) les poids de Barberà-Jackson sont quasi proportionnels aux populations.
Tableau 2
Poids calculés (UE 27)

2.2 Échangeabilité
Pour aller plus loin dans cette direction, il nous faut comprendre les déterminants fondamentaux de la marge de victoire électorale. Nous allons nous limiter ici au cas d’un seul modèle, appelé modèle d’échangeabilité forte par Le Breton et Van der Straeten (2015a,b). L’échangeabilité décrit la situation où la probabilité des différentes situations ne dépend que du nombre d’opinions dans chaque camp et non des noms de ceux qui les expriment.
Formellement, nous dirons que la loi de tirage λk satisfait à une propriété d’échangeabilité forte[22] s’il existe une loi de probabilité Gk sur [0,1] telle que :
où ![]() est le nombre de vote 1 pour toute suite
est le nombre de vote 1 pour toute suite ![]() de -1 et de 1.
de -1 et de 1.
Pour préserver les hypothèses faites jusqu’à présent, nous allons supposer que Gk est symétrique par rapport à ![]() , ce qui implique que son espérance vaut
, ce qui implique que son espérance vaut ![]() . Dans ce cas on obtient :
. Dans ce cas on obtient :
Ce modèle couvre de nombreuses situations différentes. Par exemple, ![]() [23] représente le cas de la corrélation parfaite. À l’opposé,
[23] représente le cas de la corrélation parfaite. À l’opposé, ![]() représente le cas où les préférences des citoyens du district k sont indépendantes entre elles. Dans ce cas binaire, il correspond au modèle IC qui est l’un des modèles probabilistes de référence en théorie du choix social. On peut bien entendu envisager d’autres lois. Un autre exemple très populaire en théorie du choix social est le modèle IAC[24] qui correspond au cas où Gk est la loi uniforme. De ce point de vue, on peut regarder le modèle d’échangeabilité forte comme une version généralisée du modèle IAC[25].
représente le cas où les préférences des citoyens du district k sont indépendantes entre elles. Dans ce cas binaire, il correspond au modèle IC qui est l’un des modèles probabilistes de référence en théorie du choix social. On peut bien entendu envisager d’autres lois. Un autre exemple très populaire en théorie du choix social est le modèle IAC[24] qui correspond au cas où Gk est la loi uniforme. De ce point de vue, on peut regarder le modèle d’échangeabilité forte comme une version généralisée du modèle IAC[25].
Le poids de Barberà-Jackson wk (λ) du district k vaut donc ici :
Dans le cas où ![]() , on obtient :
, on obtient :
En utilisant le fait que :
on en déduit que la marge de victoire espérée de l’alternative 1 lorsqu’elle est majoritaire vaut :
Quand la population du district est grande, on peut utiliser la formule de Stirling pour obtenir
et donc un poids de Barberà-Jackson asymptotiquement égal à :
Cette formule de la racine carrée a fait couler beaucoup d’encre et a donné lieu à une vaste littérature que nous n’allons pas exhaustivement répertorier ici[26]. Notons qu’elle implique une proportionnalité dégressive : le poids d’un citoyen d’un pays peuplé est inférieur à celui d’un pays moins peuplé. Mais pour ce faire, elle suppose que les opinions des citoyens de chaque pays sont complètement indépendantes et n’exhibent donc (dans le cas d’échangeabilité retenu ici) aucune forme de corrélation. Il s’agit d’un cas très spécial et non générique et l’introduction d’une corrélation nous écarte de cette conclusion.
Considérons maintenant le cas examiné dans Le Breton et Van der Straeten où Gk (parfois simplement notée G dans la suite de cette section) est décrite par une densité bêta concave et symétrique g, c’est-à-dire :
Le cas où q = 1 correspond au cas où G est la distribution uniforme sur [0,1] c’est-à-dire le modèle IAC déjà évoqué. La version généralisée considérée ici a été introduite par Berg (1990) qui appelle ![]() le paramètre de cohérence du groupe ou homogénéité. On voit que la corrélation des membres du distict k, noté ψ (q), est en effet liée à la valeur de q comme indiqué ci-dessous :
le paramètre de cohérence du groupe ou homogénéité. On voit que la corrélation des membres du distict k, noté ψ (q), est en effet liée à la valeur de q comme indiqué ci-dessous :
Voici quelques valeurs de cette fonction :
Tableau 3
Corrélation entre les votes

La fonction ψ tend vers ![]() (le cas indépendant) lorsque q tend vers +∞, c’est-à-dire quand la cohésion du groupe tend vers 0.
(le cas indépendant) lorsque q tend vers +∞, c’est-à-dire quand la cohésion du groupe tend vers 0.
En utilisant la formule classique,
![]() pour tout entier m et tout entier l
pour tout entier m et tout entier l
on obtient une expression explicite du poids de Barberà-Jackson du district k :
Lorsque qk = 1, on obtient après simplifications :
alors qu’avec qk = 2, on obtient :
Dans les deux cas, on constate que le ratio  tend vers une constante. De manière genérale, en conjecturant[27] que
tend vers une constante. De manière genérale, en conjecturant[27] que ![]() se comporte asymptotiquement comme
se comporte asymptotiquement comme ![]() lorsque
lorsque ![]() , on obtient, dans le cas d’une loi bêta :
, on obtient, dans le cas d’une loi bêta :
et donc
Par conséquent, le poids du vote du représentant du district k est une fonction linéaire de la population du district et si le paramètre qk est le même pour tout district, on retrouve des poids directement proportionnels à la population. On remarque en outre que le coefficient de proportionnalité ![]() du district k décroît avec qk : plus les préférences sont corrélées, plus les poids de Barberà-Jackson sont élevés. Le tableau ci-dessous présente quelques valeurs de ϕ(q).
du district k décroît avec qk : plus les préférences sont corrélées, plus les poids de Barberà-Jackson sont élevés. Le tableau ci-dessous présente quelques valeurs de ϕ(q).
Tableau 4
Coefficient de proportionnalité

La formule montre aussi que lorsque q tend vers l'infini, alors
Ainsi, quand q tend vers +∞, le coefficient de proportionnalité tend vers 0 comme l’inverse de la racine carrée du coefficient d’homogénéité. Sous réserve que certaines conjectures soient confirmées, les développements ci-dessus suggèrent l’extrême fragilité de la formule de la racine carrée et offrent un regard sur les déterminants du coefficient de proportionnalité.
2.3 Le cas des États composés de blocs
Ces calculs et les conclusions qui leur sont attachées ont été conduits sous l’hypothèse que λ satisfait à la propriété d’échangeabilité forte. On peut mener une analyse similaire sous des hypothèses où la symétrie entre les électeurs du même district est beaucoup moins forte et aboutir à des conclusions identiques. Par exemple, dans la lignée du beau travail précurseur de Penrose (1952), Barberà et Jackson (2006) mais aussi Le Breton et Van der Straeten (2015b)[28] considèrent des districts composés de blocs. Le mot bloc décrit l’idée de corrélations locales : les corrélations entre les préférences d’électeurs sont inexistantes entre les blocs mais fortes au sein des blocs. On retrouve en grande partie l’esprit des résultats obtenus dans le cas d’échangeabilité. Supposons que le district k soit composé de bk blocs équipeuplés de taille tk (donc bktk = nk) et que les préférences au sein de chaque bloc sont parfaitement corrélées. Si le profil des préférences d’un bloc est décrit par la probabilité ![]() , alors on obtient :
, alors on obtient :
En particulier, si le nombre de blocs bk est fixe (indépendant de la taille du district), on retrouve la formule de proportionnalité alors que si la taille tk d’un bloc est fixe, le nombre de blocs augmente indéfiniment avec la taille et on reproduit une formule du type racine carrée. Asymptotiquement on obtient :
2.4 Le cas de représentants utilitaristes
Citons enfin les travaux pionniers de Beisbart, Bovens et Hartmann (2005). Contrairement à ce qui est supposé dans les lignes qui précèdent, ils considèrent un modèle où la possibilité de corrélation cardinale est prise en considération et se focalisent sur le cas où les représentants sont de type utilitariste. Précisément, ils supposent (à des fins calculatoires) que pour tout k = 1, …, K, la loi λk est une loi gaussienne dont toutes les marginales sont égales. Soit μk et Ωk la moyenne et la matrice de variances-covariances de la loi λk. En supposant que λk est non biaisée, c’est-à-dire ici que μk = 0 et que toutes les corrélations sont identiques au sein d’un district, on obtient que ![]() suit une loi gaussienne de moyenne nulle et d’écart type
suit une loi gaussienne de moyenne nulle et d’écart type ![]() où ρk désigne le coefficient de corrélation. On en déduit que le poids de Barberà-Jackson du district k qui est ici le moment d’ordre 1 de la loi gaussienne tronquée
où ρk désigne le coefficient de corrélation. On en déduit que le poids de Barberà-Jackson du district k qui est ici le moment d’ordre 1 de la loi gaussienne tronquée ![]() est égal à
est égal à ![]()
![]() . Lorsque ρk ≠ 0, le poids de Barberà-Jackson du district k est donc asymptotiquement proportionnel à nk.
. Lorsque ρk ≠ 0, le poids de Barberà-Jackson du district k est donc asymptotiquement proportionnel à nk.
La principale leçon qualitative qui découle des arguments développés dans cette section est que la proportionnalité des poids aux populations semble s’imposer génériquement dans le modèle considéré par Barberà et Jackson et que le coefficient de proportionnalité dépendra du caractére plus ou moins consensuel du district. À l’extrême, un district clivé sur tous les sujets (IC) nous écarte donc de la proportionnalité, mais même lorsque ce n’est pas le cas, une forte concentration de la masse de probabilité autour de ![]() sera un indicateur très fort d’une société où les marges de victoire seront très serrées et où donc, finalement, le représentant ne représente pas grand chose au premier ordre. Rien d’étonnant qu’en pareil cas son poids soit affecté de peu de valeur dans le mécanisme optimal[29].
sera un indicateur très fort d’une société où les marges de victoire seront très serrées et où donc, finalement, le représentant ne représente pas grand chose au premier ordre. Rien d’étonnant qu’en pareil cas son poids soit affecté de peu de valeur dans le mécanisme optimal[29].
3. Robustesse aux changements de critères
Dans la section précédente, nous avons dérivé le mécanisme optimal de vote dans le cas où l’objectif poursuivi était la maximisation de l’utilité totale espérée. Nous avons démontré le résultat fondamental de Barberà et Jackson énonçant que ce mécanisme s’apparentait à un mécanisme pondéré majoritaire. Nous avons aussi analysé les arguments qui conduisaient à donner du poids au vote d’un district par rapport aux autres districts. Ce faisant, nous avons cependant passé sous silence un certain nombre de questions que nous allons examiner dans cette section ainsi que les réponses qui leur ont été apportées dans quelques contributions fondamentales.
Nous retiendrons ici le cas binaire particulier mais important évoqué à la fin de la section 2. Rappelons qu’il suppose que pour tout i ∈ N, Ui prend exclusivement les valeurs 1 et -1. Dans ce cas, le poids de Barberà-Jackson wk du district k est égal à l’espérance de la marge du camp victorieux.
3.1 Les objectifs égalitaristes
Dans les sections précédentes, nous avons privilégié le critère de maximisation de la somme des utilités espérées. Ceci ne surprendra pas les économistes tant ce critère est populaire dans leur communauté (même si ici il fait intervenir des espérances d’utilité et non des utilités). En revanche, en science politique, il est plus commun de privilègier un objectif mettant en avant un critère d’égalité. Le plus célèbre d’entre eux, « Un homme, une voix », suggère que le mécanisme doit être choisi de sorte que tous les citoyens jouissent (ex ante) de la même possibilité d’influencer le résultat de la décision collective. Le mot influence dans cette phrase n’a aucune raison de coïncider avec le mot utilité. Intuitivement, on imagine aisément qu’un citoyen influent verra plus souvent que d’autres ses préférences prises en compte dans le choix collectif et jouira donc finalement d’une utilité plus grande, mais la nature exacte de cette relation n’est pas immédiate. Elle dépendra du mécanisme C et du modèle probabiliste λ.
Le critère d’égalisation du pouvoir ou de l’influence était le plus populaire dans la littérature jusqu’à ce que, dans la lignée de la contribution de Barberà et Jackson, les approches utilitaristes se développent. Son origine remonte aux travaux pionners de Penrose (1946, 1952) et Banzhaf (1965). La notion clef est celle de joueur décisif (swing) : un votant est décisif chaque fois qu’il est en mesure de modifier le résultat du scrutin en modifiant l’expression de son bulletin. Le pouvoir ou l’influence d’un votant se définit alors comme sa probabilité a priori de déposer un bulletin décisif dans l’urne; cette même probabilité dépend évidement des hypothèses probabilistes faites sur le comportement de tous les citoyens.
Nous pouvons reprendre les élements de la section 2 pour décrire rapidement les principaux points du raisonnement[30]. Dans le modèle de Penrose-Banzhaf, chaque votant choisit de manière indépendante l’option 1 ou 0 avec probabilité ![]() , ce qui nous ramène au modèle IC. Sous cette hypothèse, toutes les 2n configurations de vote sont équiprobables, et le pouvoir d’un votant i est juste la proportion des configurations des votes des (n-1) autres votants pour lesquelles il est décisif. Ceci définit simplement le pouvoir de Banzhaf (non normalisé) du votant i, noté Bi (C) :
, ce qui nous ramène au modèle IC. Sous cette hypothèse, toutes les 2n configurations de vote sont équiprobables, et le pouvoir d’un votant i est juste la proportion des configurations des votes des (n-1) autres votants pour lesquelles il est décisif. Ceci définit simplement le pouvoir de Banzhaf (non normalisé) du votant i, noté Bi (C) :
Dans le contexte fédéral, il faut prendre en compte le fait que chaque individu i dépose son bulletin dans un district particulier k. Comme chaque représentant suit le souhait de la majorité de ses électeurs et que les votes sont indépendants entre districts, on a :
Dans un mécanisme indirect, le vote de i est décisif dans son district dans
configurations possibles parmi les ![]() possibles. Pour nk grand, ce rapport tend vers
possibles. Pour nk grand, ce rapport tend vers ![]() . D’autre part, si K est grand, qu’aucun district n’a un poids wk trop grand dans l’assemblée et qu’aucun comportement irrégulier n’est observé quant à la répartition de ceux-ci, Penrose affirme que le ratio des indices de pouvoir,
. D’autre part, si K est grand, qu’aucun district n’a un poids wk trop grand dans l’assemblée et qu’aucun comportement irrégulier n’est observé quant à la répartition de ceux-ci, Penrose affirme que le ratio des indices de pouvoir, ![]() entre les représentants des États k et k’ dans le jeu pondéré majoritaire est approximativement égal au rapport de leurs poids respectifs,
entre les représentants des États k et k’ dans le jeu pondéré majoritaire est approximativement égal au rapport de leurs poids respectifs, ![]() . Dès lors, l’égalité des pouvoirs est obtenue si
. Dès lors, l’égalité des pouvoirs est obtenue si
c’est-à-dire, si les poids wk sont proportionnels à ![]() .
.
Ce résultat est connu sous le nom de « Loi de la racine carrée de Penrose » et nous reviendrons sur les conditions de sa validité.
Préconiser l’adoption de poids proportionnels aux racines carrées des populations des États et l’utilisation d’un super quota n’est toutefois pas sans critique. En particulier, Gelman, Katz et Bafumi (2004) en compilant des décennies de données électorales montrent très clairement que les comportements des électeurs américains sont peu en phase avec l’hypothèse IC; plus précisement, ils montrent que les marges de victoire (mesurées en pourcentage) entre les deux grands Partis républicain et démocrate ne dépendent pas de la taille de l’État, alors que le modèle IC suggère des résultats plus serrés dans les États importants. Une réponse immédiate est de se tourner vers d’autres modèles probabilistes a priori. Comme dans la section 2, nous pouvons considérer le modèle IAC. Dans ce cas, la probabilité d’obtenir t voix pour l’option 1 parmi n votes est décrite désormais par :
Comme les votes entre États restent indépendants, l’équation (4) reste valable. Le pouvoir d’un individu j dans l’État k dépend des  configurations des autres votants pour lesquelles les votes pour 1 et 0 s’égalisent (avec nk impair). Ainsi,
configurations des autres votants pour lesquelles les votes pour 1 et 0 s’égalisent (avec nk impair). Ainsi,
Toujours du fait de l’indépendance des votes entre États, comme aucun de ceux-ci n’est biaisé en faveur d’une option a priori, chaque autre État votera pour 0 ou 1 avec une probabilité de ![]() . Dans le jeu entre États, si les conditions en sont vérifiées, l’approximation de Penrose peut s’appliquer : le rapport de pouvoir entre deux États s’approche du rapport des poids, et l’on en déduit
. Dans le jeu entre États, si les conditions en sont vérifiées, l’approximation de Penrose peut s’appliquer : le rapport de pouvoir entre deux États s’approche du rapport des poids, et l’on en déduit
Contrairement à la situation décrite sous l’hypothèse IC, le traitement égal entre les votants est désormais obtenu avec des poids proportionnels aux populations.
3.2 La validité du théorème limite de Penrose
Les deux résultats que nous venons d’évoquer reposent sur une idée commune : le ratio des indices de Banzhaf de deux joueurs est approximativement égal au ratio de leurs poids quand il y a suffisamment de joueurs et qu’aucun ne domine outrageusement l’assemblée. Cette propriété a fait l’objet d’une vaste littérature visant principalement à explorer les conditions de sa validité, qui ne sont pas détaillées dans les travaux de Penrose.
Lorsque K est grand et sous réserve que certaines conditions soient satisfaites, l’approximation (connue sous le nom de théorème limite de Penrose (LPT)) est valide (Lindner et Machover, 2004) dans le cas du quota majoritaire. En pratique, il reste à examiner si ces approximations sont valides « en moyenne »[31] et si elles le sont dans des cas particuliers importants. Chang, Chua et Machover (2006) procèdent à des simulations en tirant au hasard pour de nombreuses valeurs de l’entier K le vecteur w puis en calculant la moyenne et la variance de deux indices mesurant l’écart entre le vecteur de Banzhaf normalisé et le vecteur normalisé des poids. Ils confirment que lorsque le quota est le quota majoritaire, la convergence a lieu lorsque K tend vers des valeurs très grandes mais aussi que cette convergence cesse d’être vraie pour des quotas supérieurs.
Le principe égalitariste pose en réalité un problème très difficile. En pratique, les valeurs de K sont relativement petites et l’objectif égalitariste, dès l’instant où il ne peut pas être satisfait exactement ou presque exactement (il ne faut pas oublier que le problème est ici combinatoire), oblige à se donner un critère de minimisation par rapport à un objectif cible. On pourrait alors se donner comme objectif pour une norme donnée ![]() de déterminer un vecteur de poids w* et un quota q* tel que le vecteur de Banzhaf normalisé
de déterminer un vecteur de poids w* et un quota q* tel que le vecteur de Banzhaf normalisé ![]() résultant du jeu majoritaire pondéré
résultant du jeu majoritaire pondéré ![]() minimise la distance
minimise la distance ![]() . Nous nous sommes limités ici aux jeux majoritaires pondérés mais nous pourrions procéder de manière similaire pour un jeu simple W quelconque et remplacer
. Nous nous sommes limités ici aux jeux majoritaires pondérés mais nous pourrions procéder de manière similaire pour un jeu simple W quelconque et remplacer ![]() par β (W). Le vecteur β* est l’objectif cible, et dans le cas IC ci-dessus
par β (W). Le vecteur β* est l’objectif cible, et dans le cas IC ci-dessus  puisque l’on a vu que le pouvoir d’un État devait être proportionnel à la racine carré de sa population. Ce problème est connu sous le nom de problème de Banzhaf inverse (Alon et Edelman, 2010). Il n’est pas évident de savoir quels sont les vecteurs du simplexe qui peuvent s’écrire comme des vecteurs de Banzhaf normalisés d’un jeu simple adéquatement construit. Il en résulte que la résolution du problème de minimisation ci-dessus n’est pas un problème facile. On peut pour les toutes petites valeurs de K « passer en force » en énumérant au préalable l’ensemble des jeux (les nombres respectifs apparaissent dans l’annexe) mais rapidement (disons pour K ≥ 9) la nécessité de développer des méthodes algorithmiques intelligentes s’impose[32]. Il existe plusieurs contributions à cette littérature[33]. On peut citer par exemple le travail de Kurz (2012a) qui montre comment formuler le problème inverse comme un problème de programmation linéaire avec contraintes entières. Kurz et Napel (2014) utilisent cettte technique de résolution pour comparer (pour trois normes différentes) les performances de trois mécanismes de vote qui ont en commun de prendre comme vecteur de poids w le vecteur cible β* mais diffèrent quant aux quotas respectifs utilisés :
puisque l’on a vu que le pouvoir d’un État devait être proportionnel à la racine carré de sa population. Ce problème est connu sous le nom de problème de Banzhaf inverse (Alon et Edelman, 2010). Il n’est pas évident de savoir quels sont les vecteurs du simplexe qui peuvent s’écrire comme des vecteurs de Banzhaf normalisés d’un jeu simple adéquatement construit. Il en résulte que la résolution du problème de minimisation ci-dessus n’est pas un problème facile. On peut pour les toutes petites valeurs de K « passer en force » en énumérant au préalable l’ensemble des jeux (les nombres respectifs apparaissent dans l’annexe) mais rapidement (disons pour K ≥ 9) la nécessité de développer des méthodes algorithmiques intelligentes s’impose[32]. Il existe plusieurs contributions à cette littérature[33]. On peut citer par exemple le travail de Kurz (2012a) qui montre comment formuler le problème inverse comme un problème de programmation linéaire avec contraintes entières. Kurz et Napel (2014) utilisent cettte technique de résolution pour comparer (pour trois normes différentes) les performances de trois mécanismes de vote qui ont en commun de prendre comme vecteur de poids w le vecteur cible β* mais diffèrent quant aux quotas respectifs utilisés : ![]() et
et ![]() . La qualité des deux dernières méthodes a été découverte par Słomczyński et Życzkowski (2006, 2008, 2014)[34]. Les valeurs obtenues en cherchant numériquement la solution du problème inverse pour l’Europe à 25 et l’Europe à 27 sont compatibles avec une précision de 2 % avec les données obtenues sur la base des populations de l’Union. Ils montrent que dans le cas de l’Europe à 25 les ratios sont tous très voisins de 1 lorsque q est approximativement égal à 62 %[35]. Ils démontrent aussi que ce résultat est robuste dans le sens où il reste vrai pour des vecteurs de populations autres que le vecteur réel de populations.
. La qualité des deux dernières méthodes a été découverte par Słomczyński et Życzkowski (2006, 2008, 2014)[34]. Les valeurs obtenues en cherchant numériquement la solution du problème inverse pour l’Europe à 25 et l’Europe à 27 sont compatibles avec une précision de 2 % avec les données obtenues sur la base des populations de l’Union. Ils montrent que dans le cas de l’Europe à 25 les ratios sont tous très voisins de 1 lorsque q est approximativement égal à 62 %[35]. Ils démontrent aussi que ce résultat est robuste dans le sens où il reste vrai pour des vecteurs de populations autres que le vecteur réel de populations.
L’expression analytique du quota « optimal » (Słomczyński et Życzkowski, 2014) est égale à :
où xk désigne la part de la population du district k dans la population totale. S’il n’est pas connu avec certitude pour pouvoir être utilisé (parce que par exemple les populations des États sont susceptibles d’évoluer) comme c’est le cas dans la formule ci-dessus, on peut par exemple supposer qu’il est tiré au hasard uniformément dans le simplexe. Cette loi de tirage est un cas particulier d’une distribution de Dirichlet P. En faisant la moyenne de q par rapport à P, on obtient :
où :
En s’inspirant de résultats connus énonçant que  , on en déduit que :
, on en déduit que : ![]() .
.
3.3 Utilitarisme et égalitarisme
Rien n’interdit de remplacer le critère utilitariste par un critère utilitariste généralisé dans le sens où les utilités font l’objet d’un rééchelonnement concave de façon à refléter une préférence pour l’égalité. Le travail de Koriyama, Laslier, Macé et Treibich (2013) que nous allons décrire et motiver sur d’autres bases dans la section 4.1 peut être interprété comme une solution de ce problème dans le contexte du modèle aléatoire particulier qu’ils considèrent[36]. En pareil cas, l’objectif serait de maximiser :
où v est une fonction (strictement) concave définie sur R. Plus v est concave, plus l’attention se porte sur l’égalitarisme. Dans le cas où par exemple ![]() avec δ ≥ 0 (v(x) = ln(x) lorsque δ = 1), plus δ est élevé, plus le critère égalitariste prend de l’importance. Lorsque δ tend vers l’infini, le problème ci-dessous est équivalent à la maximisation du critère de Rawls[37] :
avec δ ≥ 0 (v(x) = ln(x) lorsque δ = 1), plus δ est élevé, plus le critère égalitariste prend de l’importance. Lorsque δ tend vers l’infini, le problème ci-dessous est équivalent à la maximisation du critère de Rawls[37] :
On pourrait ainsi de manière générale remplacer la doctrine utilitariste par des principes égalitaristes : un mécanisme C sera égalitariste s’il égalise ex ante les utilités des différents citoyens (Laruelle et Valenciano, 2010). Les deux objectifs, égalitariste et utilitariste, ne débouchent pas nécessairement sur les mêmes recommandations. Par exemple, dans le cas d’un modèle où chaque district a un nombre fixe de blocs, l’optimum utilitariste implique que l’utilité d’un membre d’un pays plus peuplé est plus élevée que celle d’un membre d’un pays moins peuplé. En revanche, comme le notent Barberà et Jackson, dans le cas où le modèle comporte un nombre variable de blocs de taille fixe par pays, les implications de l’optimum utilitariste en matière d’égalisation des utilités sont ambiguës. Barberà et Jackson donnent des exemples montrant que toutes les situations peuvent se produire[38].
3.4 Critères de succès, de déficit majoritaire espéré et d’efficacité majoritaire
Dans les versions égalitaristes et utilitaristes de l’objectif considéré jusqu’à présent, nous avons accordé beaucoup d’importance aux utilités des citoyens concernés par cette décision. Dans la version canonique sans biais du problème, nous avons supposé que l’utilité de l’alternative 1 pouvait prendre deux valeurs : 1 et -1. Dans ce cas, nous avons vu que l’utilité d’un citoyen se confond avec la probabilité de préférer 1 et d’un vote collectif en faveur de 1 moins la probabilité de préférer 0 et d’un vote collectif en faveur de 1. Sachant que la probabilité de préférer 0 est supposée égale à ![]() , l’utilité espérée peut aussi s’écrire comme la probabilité de préférer 1 et d’un vote collectif en faveur de 1 plus la probabilité de préférer 0 et d’un vote collectif en faveur de 0 moins
, l’utilité espérée peut aussi s’écrire comme la probabilité de préférer 1 et d’un vote collectif en faveur de 1 plus la probabilité de préférer 0 et d’un vote collectif en faveur de 0 moins ![]() , c’est-à-dire (à la constante
, c’est-à-dire (à la constante ![]() près) la probabilité de succès. Le critère utilitariste revient donc ici à maximiser la somme de probabilités de succès. Ex post on compte les pour et les contre et on opte pour la décision avec le support le plus grand. Notons que de façon équivalente, on pourrait considérer la qualité d’un mécanisme comme la différence entre l’espérance d’utilité totale du mécanisme majoritaire (qui est ici le mécanisme optimal ex ante et ex post) et l’espérance d’utilité totale pour le mécanisme considéré. La différence entre les deux quantités pour chaque réalisation possible des préférences individuelles vaut 0 dans le cas où le choix public coïncide avec le choix majoritaire et est égal à l’écart entre la taille du groupe de partisans de l’option choisie et la taille du groupe majoritaire dans le cas contraire. Avec cette normalisation, un mécanisme est de meilleure qualité lorsque cette mesure qui correspond au déficit majoritaire espéré (Felsenthal et Machover, 1998, 1999) est la plus petite possible. Notons que cette mesure correspond à une normalisation du critère de l’espérance d’utilité totale différente de celle retenue par Weber et introduite plus haut mais dans le même esprit.
près) la probabilité de succès. Le critère utilitariste revient donc ici à maximiser la somme de probabilités de succès. Ex post on compte les pour et les contre et on opte pour la décision avec le support le plus grand. Notons que de façon équivalente, on pourrait considérer la qualité d’un mécanisme comme la différence entre l’espérance d’utilité totale du mécanisme majoritaire (qui est ici le mécanisme optimal ex ante et ex post) et l’espérance d’utilité totale pour le mécanisme considéré. La différence entre les deux quantités pour chaque réalisation possible des préférences individuelles vaut 0 dans le cas où le choix public coïncide avec le choix majoritaire et est égal à l’écart entre la taille du groupe de partisans de l’option choisie et la taille du groupe majoritaire dans le cas contraire. Avec cette normalisation, un mécanisme est de meilleure qualité lorsque cette mesure qui correspond au déficit majoritaire espéré (Felsenthal et Machover, 1998, 1999) est la plus petite possible. Notons que cette mesure correspond à une normalisation du critère de l’espérance d’utilité totale différente de celle retenue par Weber et introduite plus haut mais dans le même esprit.
Par construction, cette mesure compte le nombre de personnes insatisfaites de la décision publique dès l’instant où ces personnes forment un groupe majoritaire dans la fédération. On pourrait imaginer une mesure plus qualitative où toutes les situations, où le choix majoritaire est pris en défaut, sont affectées du même poids. Dans ce cas, l’objectif que l’on cherche à minimiser est la probabilité qu’une telle situation se produise. Plusieurs mots sont utilisés dans la littérature pour qualifier une telle situation lorsqu’elle apparaît : on parle d’inefficacité majoritaire[39] chez les théoriciens du choix social, de paradoxe du referendum (Nurmi, 1999) ou encore d’élections inversées (Miller, 2012) pour n’en citer que quelques-uns. L’évaluation de cette probabilité pour des mécanismes C indirects donnés a été effectuée par peu d’auteurs car les calculs sont rapidement très difficiles même dans le cas symétrique. Considérons en effet tout d’abord le cas où les populations des différents districts sont toutes égales entre elles disons n1 = … = nk ≡ m et où les poids sont tous égaux avec quota majoritaire. La probabilité P(K, m) de l’événement « le mécanisme C (ainsi défini) produit une élection inversée » a été calculée par May (1949) dans le cas où le modèle λ est le modèle IAC. Il démontre en particulier que cette probabilité tend vers ![]() lorsque K et m tendent vers l’infini. Feix, Lepelley Merlin et Rouet (2004) et Lepelley, Merlin et Rouet (2011) ont retrouvé certains des calculs de May et ont aussi calculé explicitement cette probabilité dans le cas où K = 3, 4 et 5 et où m tend vers l’infini pour les modèles IC et IAC. À l’aide de simulations, ils étudient aussi le cas général, retrouvent sans surprise le résultat de May sous l’hypothèse IAC et montrent que cette probabilité tend vers 21 % lorsque K tend vers l'infini sous IC[40]. Lorsque la population totale n de la fédération est fixe et que les districts sont équipeuplés, la probabilité est nulle dans les cas où K = 1 et K = n. Beisbart et Bovens (2013) ont démontré dans ce contexte que le déficit majoritaire espéré est maximal lorsque le nombre de districts est égal à
lorsque K et m tendent vers l’infini. Feix, Lepelley Merlin et Rouet (2004) et Lepelley, Merlin et Rouet (2011) ont retrouvé certains des calculs de May et ont aussi calculé explicitement cette probabilité dans le cas où K = 3, 4 et 5 et où m tend vers l’infini pour les modèles IC et IAC. À l’aide de simulations, ils étudient aussi le cas général, retrouvent sans surprise le résultat de May sous l’hypothèse IAC et montrent que cette probabilité tend vers 21 % lorsque K tend vers l'infini sous IC[40]. Lorsque la population totale n de la fédération est fixe et que les districts sont équipeuplés, la probabilité est nulle dans les cas où K = 1 et K = n. Beisbart et Bovens (2013) ont démontré dans ce contexte que le déficit majoritaire espéré est maximal lorsque le nombre de districts est égal à ![]() [41].
[41].
Lorsque les districts ne sont pas équipeuplés, la caractérisation du (des) mécanisme(s) minimisant la probabilité de l’inefficience majoritaire/élection inversée est largement ouverte. Cette question a fait l’objet de travaux par Feix et al. (2008)[42], Lahrach et Merlin (2012) et Miller (2012) dans le cas du collège américain. Feix et al. ainsi que Lahrach et Merlin limitent leur exploration aux mécanismes de votes engendrés par des poids wk du type (nk)α où α ≥ 0. Notons que dans le cas où α tend vers l’infini, on est en présence d’un mécanisme dictatorial qui donne tout le pouvoir au représentant du district le plus peuplé. À l’inverse, la valeur α = 0 donne une voix à chaque représentant, indépendamment de la taille du district qu’il représente. Une étude complète du cas K = 3 apparaît dans Feix et al. (2008) pour une classe de modèles probabilistes couvrant IC et IAC. Pour une valeur quelconque de K, ils utilisent des simulations. Il ressort que dans le cas IAC, la règle qui minimise la probabilité du paradoxe du référendum est constamment la règle proportionnelle alors que dans le cas IC, la règle optimale impose une forme de dégressivité avec une valeur de α voisine de 0,4 pour de petites valeurs de K, mais tendant vers 0,5 lorsque K tend vers l’infini. On retrouve ainsi les conclusions qui semblent s’imposer dans la plupart des modèles que nous avons examinés, sans pour autant que l’on puisse ici donner une preuve formelle de l’optimalité de ces solutions (proportionnalité sous l’hypothèse IAC et loi de la racine carrée sous l’hypothèse IC) dans le cadre de la maximisation de l’efficacité majoritaire.
4. Des modèles alternatifs : le cadre du choix public
Le modèle canonique que nous venons de présenter n’est pas, loin de là, la seule route possible pour analyser les modes de scrutins indirects. Les contributions recensées dans cette section vont explorer trois autres pistes qui, à des titres divers, rompent[43] avec le modèle de choix binaire simple.
4.1 L’impact du nombre de décisions à prendre
Nous allons éliminer une fois pour toute à partir de maintenant le facteur ξ et même nous limiter (pour simplifier l’exposé) au cas où l’utilité de l’option 1 prend deux valeurs possibles (1 ou -1) avec la probabilité ![]() . Nous parlerons de succès pour l’électeur i lorsque la décision collective est identique à sa préférence individuelle. Si, comme nous l’avons supposé, l’utilité de la décision 0 est normalisée à 0, l’utilité espérée du citoyen i est égale à la probabilité de succès moins
. Nous parlerons de succès pour l’électeur i lorsque la décision collective est identique à sa préférence individuelle. Si, comme nous l’avons supposé, l’utilité de la décision 0 est normalisée à 0, l’utilité espérée du citoyen i est égale à la probabilité de succès moins ![]() . Notons que si nous avions supposé (en guise de normalisation) que l’utilité de la meilleure alternative de l’électeur i valait 1 et que celle de la moins bonne valait 0, alors l’utilité espérée du citoyen i aurait été égale à la probabilité de succès.
. Notons que si nous avions supposé (en guise de normalisation) que l’utilité de la meilleure alternative de l’électeur i valait 1 et que celle de la moins bonne valait 0, alors l’utilité espérée du citoyen i aurait été égale à la probabilité de succès.
Nous avons insisté sur le fait que l’analyse est menée dans un contexte dichotomique sans préciser cependant le nombre T de décisions de cette nature que le conseil aura à débattre[44]. Cette question est sans importance si nous supposons que les questions sont sans lien entre elles et que l’utilité de chaque électeur est la somme des utilités de chacune des décisions. Si les préférences sur chacune des décisions sont indépendantes et identiquement distribuées selon la loi λ, le mécanisme maximisant l’utilité totale espérée est le mécanisme de Barberà et Jackson. Ici, une conséquence est une suite de longueur T dont les coordonnées valent 0 ou 1. Une fois le mécanisme choisi, la probabilité que la tième coordonnée soit égale à 0 ou 1 dépend du mécanisme et du profil des préférences sur la tième coordonnée. L’utilité d’un citoyen porte donc sur une loterie dont une conséquence est une suite de 0 ou 1 et (du point de vue de chaque citoyen) une suite de succès et d’échecs selon que la décision collective est conforme ou non à son choix. Dans le cas où l’utilité d’une conséquence ne dépend que du nombre de succès t, l’utilité espérée du citoyen i est égale à :
où vi est la fonction de von Neumann-Morgenstern du citoyen i sur l’espace des conséquences pures qui ici est {0,1,…,T} et non {0,1}T et pi est la probabilité de succès du citoyen i (qui, rappelons-le, dépend de λ et du mécanisme C). Si λ est symétrique à l’échelle de chaque district (comme c’est le cas par exemple dans le cas d’échangeabilité), la probabilité pi ne dépend que du district auquel i appartient et sera notée abusivement pk (C) (pk (C) désigne donc la probabilité que sur l’une ou l’autre des T décisions, un citoyen générique du district k soit du bon côté).
Ce modèle général est introduit et exploré par Koriyama et al. (2013). Plus spécifiquement, ils supposent que νi ne dépend pas de i, que les districts sont indépendants entre eux et qu’il existe dans chaque district k un signal aléatoire qui prend les valeurs 0 ou 1 avec probabilité ![]() et que conditionnellement à la valeur de ce signal (0 ou 1), les citoyens de ce district votent (0 ou 1) avec probabilité μ >
et que conditionnellement à la valeur de ce signal (0 ou 1), les citoyens de ce district votent (0 ou 1) avec probabilité μ > ![]() . Ici, μ représente le niveau de corrélation entre les préférences au sein d’un district et est supposé être le même dans tous les districts. Le représentant du district k vote en fonction de la valeur du signal du district k.
. Ici, μ représente le niveau de corrélation entre les préférences au sein d’un district et est supposé être le même dans tous les districts. Le représentant du district k vote en fonction de la valeur du signal du district k.
La somme des utilités attachée au mécanisme C est donc égale à :
où pk (C) désigne la probabilité qu’un citoyen générique du district k soit du bon côté. Le principal objectif du travail de Koriyama et al. est de caractériser le(s) mécanisme(s) C maximisant la somme des utilités. Après avoir noté le caractère combinatoire de leur problème d’optimisation, ils l’écrivent comme un problème d’optimisation continue où la notion de jeu simple est remplacée par la notion de jeu simple probabiliste[45]. Ils démontrent que toutes les solutions du problème d’optimisation induisent le même vecteur p* = (p1*,…, pK*) de fréquences de succès et que nk > nk’ ⇒ pk* > pk’*. En considérant le vecteur des poids w* = (w1*,…, wK*) où wk* est proportionnel à nkU’ (pk*), ils démontrent que si U est croissante et strictement concave[46] alors toute solution du problème d’optimisation est un jeu probabiliste pondéré avec le vecteur de poids w* et le seuil ![]() . Le seul degré de liberté concerne la définition de la règle en cas d’égalité. Ils en déduisent facilement que le vecteur des poids du mécanisme optimal satisfait au principe de proportionnalité dégressive.
. Le seul degré de liberté concerne la définition de la règle en cas d’égalité. Ils en déduisent facilement que le vecteur des poids du mécanisme optimal satisfait au principe de proportionnalité dégressive.
Notons au passage que si v est linéaire alors les poids sont proportionnels aux populations alors que si la concavité est extrême (c’est-à-dire si l’objectif à maximiser est l’utilité espérée minimale) les poids sont tous égaux entre eux et la dégressivité est alors maximale. Le calcul des poids est en général un problème difficile. Macé et Treibich (2012) développent un algorithme itératif : ils partent d’un vecteur de poids initial et le modifient localement de façon intelligente afin d’obtenir un maximum local du problème numérique d’optimisation.
4.2 D’un choix dichotomique au choix sur un intervalle
Un autre modèle différent de celui considéré ici est décrit par le cas où l’ensemble des décisions publiques est un intervalle de la droite réelle et les fonctions d’utilités des citoyens sont supposées unimodales. Dans ce contexte, la notion de représentant majoritaire à l’échelle de chacun des districts est parfaitement définie (c’est l’électeur médian) et on peut reprendre l’analyse ci-dessus sur le plan conceptuel sans changer une virgule aux principales définitions de Barberà et Jackson. Ce modèle a d’abord été proposé par Maaser et Napel (2007), alors qu’ils cherchaient à égaliser la probabilité d’être décisif entre les électeurs de différents districts. Ce même objectif est poursuivi dans Kurz, Maaser et Napel (2017). Le modèle a été aussi repris dans la veine utilitariste dans Maaser et Napel (2012) pour minimiser l’écart entre les positions médianes issues des votes direct et indirect et dans Maaser et Napel (2014) pour rechercher le maximum d’utilité. Dans ce nouveau contexte, l’analogue de la distribution de probabilité l est une distribution aléatoire des points idéaux des différents citoyens (θi)1≤i≤n. Cette distribution définit K points idéaux médians ![]() qui en combinaison avec un vecteur de poids w = (w1,…, wK) définissent le point idéal dans la fédération (le « médian des médians »).
qui en combinaison avec un vecteur de poids w = (w1,…, wK) définissent le point idéal dans la fédération (le « médian des médians »).
Dans leur premier article, Maaser et Napel (2007) testent des règles où les poids wk sont du type (nk)α. Ils montrent, à l’aide de simulations (avec tirage aléatoire des populations des districts et des positions des votants), que la valeur α = 0,5 (ou de très proches valeurs) permet au mieux d’égaliser les probabilités d’être décisif de chacun des électeurs. En particulier, cette nouvelle loi de la racine carrée s’affirme nettement au-delà de K = 15. Cependant, ces résultats sont tributaires de la manière de tirer aléatoirement les points idéaux, qui obéit à la même loi de districts en districts. De fait, il est alors plus facile pour le représentant d’un grand État d’être le pivot de l’assemblée dans ce contexte, car la variance de sa position sera plus faible que celle du représentant d’un petit État. Il occupera donc plus fréquemment qu’on le souhaiterait la position médiane de l’assemblée. Seuls des poids « moins que proportionnels » permettent de rétablir l’équilibre en faveur des États de petite population. L’intérêt de la contribution récente de Kurz, Maaser et Napel (2017) est non seulement de formaliser analytiquement ce raisonnement, mais aussi de montrer qu’il est fragile. Il repose fortement sur le fait que la loi de tirages des points idéaux des votants est partout la même; ainsi, aucun État ne présente de biais idéologique fort. On retrouve ici la même critique que celle que l’on peut adresser au modèle IC dans le cadre dichotomique. Mais dès lors que l’on introduit de l’hétérogénéité parmi les lois de distributions des votants entre les États, l’avantage des grands États disparaît. Il faut alors revenir vers des poids exactement proportionnels aux populations pour rétablir l’égalité de traitement entre tous les électeurs.
Dans leurs autres articles, Maaser et Napel se penchent sur des critères utilitaristes. En supposant une désutilité qui évolue linéairement ou quadratiquement en fonction de la distance au point idéal, on aboutit à deux critères différents d’utilité totale espérée. Dans un cas, le choix public optimal est la valeur médiane des points idéaux dans la population alors que dans le second cas, le choix optimal est la valeur moyenne. Mais dans les deux cas, le choix fédéral n’a aucune raison de coïncider avec ces valeurs. Comme chez Barberà et Jackson, la question est donc de déterminer le vecteur w qui maximise l’utilité espérée totale pour les deux versions. Dans le cas linéaire, Maaser et Napel (2012) appellent déficit démocratique (direct) l’expression ![]() . Ils font une distinction très claire entre le cas appelé IC ci-dessus (indépendance au sein des districts) et le cas IAC généralisé (corrélation plus ou moins forte au sein des districts). À l’exception de quelques intuitions dans des cas simples extrêmes, Maaser et Napel (2014) inventorient les difficultés techniques attachées à leur problème et s’en remettent à des simulations pour découvrir les poids optimaux sous l’hypothèse wk = (nk)α; plus exactement ils s’efforcent donc de découvrir la dégressivité optimale. Dans leurs simulations, ils tirent au hasard des profils de populations et pour une grille de valeurs de α calculent l’espérance de l’utilité totale sachant que les points idéaux sont tirés uniformément dans [0,1]. Dans le cas IC, ils obtiennent des valeurs de α proches de
. Ils font une distinction très claire entre le cas appelé IC ci-dessus (indépendance au sein des districts) et le cas IAC généralisé (corrélation plus ou moins forte au sein des districts). À l’exception de quelques intuitions dans des cas simples extrêmes, Maaser et Napel (2014) inventorient les difficultés techniques attachées à leur problème et s’en remettent à des simulations pour découvrir les poids optimaux sous l’hypothèse wk = (nk)α; plus exactement ils s’efforcent donc de découvrir la dégressivité optimale. Dans leurs simulations, ils tirent au hasard des profils de populations et pour une grille de valeurs de α calculent l’espérance de l’utilité totale sachant que les points idéaux sont tirés uniformément dans [0,1]. Dans le cas IC, ils obtiennent des valeurs de α proches de ![]() pour les deux types de fonctions d’utilité. En revanche, dans le cas d’une corrélation au sein des districts[47] (extrême ou non), la valeur optimale de α reste voisine de 1 dans le cas linéaire mais s’écarte de cette valeur dans le cas quadratique pour se rapprocher de
pour les deux types de fonctions d’utilité. En revanche, dans le cas d’une corrélation au sein des districts[47] (extrême ou non), la valeur optimale de α reste voisine de 1 dans le cas linéaire mais s’écarte de cette valeur dans le cas quadratique pour se rapprocher de ![]() .
.
4.3 Le cas d’un espace multidimensionnel d’options
Au nombre des autres décisions collectives qu’un conseil fédéral peut être amené à traiter figure la répartition d’un budget entre les différents districts. Dans ce cas, il est raisonnable de supposer que la préférence et donc le vote du représentant du district k dépendront exclusivement et positivement de la part qui échoit au district k. Si au lieu d’un budget, il s’agit d’un « fardeau », la dépendance sera négative. Nous nous limiterons ici au cas d’un budget dont la taille est normalisée à 1 et où les représentants ne font preuve d’aucun altruisme[48]. Une fois choisi le mécanisme de vote C, il faut décrire la manière exacte dont seront prises les décisions car l’espace devient ici multidimensionnel (le simplexe unitaire de dimension K – 1). Plusieurs solutions non coopératives peuvent être envisagées, comme par exemple l’équilibre stationnaire parfait en sous-jeux du modèle de vote séquentiel sur des offres et contre-offres introduit par Baron et Ferejohn (1989), ou coopératives comme le nucléole ou la valeur de Shapley. Sachant comment le choix de w et du quota q influence la solution, le problème revient alors à choisir w et q de manière à maximiser un critère d’utilité sociale[49]. Le problème de mechanism design est posé en ces termes dans Le Breton, Montero et Zaporozhets (2012) qui déterminent le jeu simple optimal dans plusieurs configurations décrivant le conseil des ministres de l’Europe depuis sa création et sous l’hypothèse que le jeu de Baron et Ferejohn est spécifié de telle sorte que l’équilibre coïncide[50] avec le nucléole du jeu coopératif associé. Notons encore une fois que le problème est purement combinatoire et qu’il est difficile car le nombre de possibilités augmente très rapidement avec le nombre K[51]. Il n’est pas nécessaire de se limiter aux jeux majoritaires car ici rien n’établit a priori qu’il faille se limiter à ceux-là. Dans le cas où K = 6 (l’Europe à sa création) ils comparent les 21 jeux simples dirigés et forts (qui coïncident avec les jeux majoritaires et forts) du point de vue de l’utilité totale quadratique (c’est-à-dire la variance de l’écart par rapport à l’égalité parfaite). Sur la base des populations de 1958, ils trouvent que le jeu optimal est le jeu majoritaire de représentation [5; 3, 2, 2, 1, 1, 0] et non le jeu [12; 4, 4, 4, 2, 2, 1] qui avait été retenu. Un exercice de même nature est conduit dans la cas de l’Europe de 1973 mais les 175 428 jeux majoritaires de somme constante ne sont pas étudiés! L’étude suppose que les poids sont proportionnels aux populations et se concentre sur les jeux qui se distinguent les uns des autres en fonction du quota. Ces jeux sont au nombre de 201 et génèrent 33 nucléoles différents. Le quota optimal se situe entre 55,4 % et 56,3 %. Un travail analogue est conduit aussi pour le conseil de 1981. On note au passage que le problème du nucléole inverse (à savoir la réponse à la question : quels sont les vecteurs qui peuvent s’écrire comme le nucléole d’un jeu simple adéquatement construit) est aussi largement ouvert. Le seul résultat disponible est un beau résultat asymptotique dû à Kurz, Nohn et Napel (2014) qui rappelle celui de Penrose.
Les détails du protocole de marchandage vont naturellement avoir une influence considérable sur la nature de la solution comme le démontre le résultat général de Kalandrakis (2006). Les travaux de Laruelle et Valenciano (2007, 2008a,b) dans leur analyse de ce qu’ils appellent « comités de marchandage » intègrent cet élément important. Dans leurs articles, le problème de marchandage est décrit directement dans l’espace des vecteurs d’utilités. Le problème de marchandage qu’ils considèrent est très genéral alors que celui considéré par Baron et Ferejohn et utilisé par Le Breton, Montero et Zaporozhets est décrit par le simplexe et le vecteur 0 comme point de menace[52].
Conclusion
Dans cet article de synthèse, nous avons proposé et exploré un cadre d’analyse formel afin de déterminer le choix optimal du mécanisme de vote du conseil des représentants d’une union fédérale. Nous avons énoncé et commenté le résultat central de Barberà et Jackson qui offre une caractérisation complète du mécanisme optimal dans le cas où l’objectif est utilitariste et où les utilités individuelles sont additives par rapport aux questions discutées par le conseil. Nous avons aussi établi une formule générale permettant de comparer tous les mécanismes entre eux et leur distance de l’optimum. Enfin, nous avons parcouru quelques-unes des principales avenues de la recherche sur ces questions.
Nous aimerions attirer l’attention du lecteur sur le fait que dans toute cette littérature (Barberà et Jackson mais aussi les autres auteurs discutés notamment dans la dernière section), il est supposé que les utilités sont indépendantes entre districts. Une lecture attentive de la preuve du théorème de Barberà et Jackson montre que cette hypothèse joue un rôle majeur dans l’obtention du résultat. Sans cette hypothèse, il n’est pas vrai en général que le mécanisme de vote optimal est un jeu majoritaire pondéré. Peu d’articles ont abordé cette question. À notre connaissance, Beisbart et Hartmann (2010) est l’unique travail qui s’y attaque. Ces auteurs le font dans un cas précis, celui du Conseil de la Communauté européenne et considèrent une spécification gaussienne des utilités. Leur travail consiste principalement, à l’aide de simulations, à comparer les qualités utilitaristes de règles diverses en fonction du niveau de corrélation des utilités entre les pays. Schmitz et Troger (2012), Azrieli et Kim (2014) observent que le mécanisme de vote optimal n’est pas toujours un mécanisme majoritaire pondéré.
Notons que dans cet exposé nous avons passé sous silence la question suivante : la règle de vote est-elle autocontraignante ? Si le mode de décision est une règle majoritaire, la majorité doit être capable d’imposer son choix dans les faits à la minorité. Sinon, celle-ci pourrait faire sécession, réduisant ainsi à néant l’intérêt du maintien d’une fédération. Pour donner un sens à cette question, Maggi et Morelli (2006) décrivent un modèle d’action collective binaire qu’ils considèrent comme un modèle descriptif d’une organisation internationale qui doit se doter d’une règle de vote mais qui ne peut passer sous silence le fait que les individus doivent être incités à suivre la trajectoire d’équilibre.
Enfin, en guise de conclusion et pour faire écho aux questionnements de l’introduction, force est de constater que nous n’avons pas pu trancher complètement le débat entre les tenants de la dégressivité des poids et les partisans de poids proportionnels. Le cadre analytique général a cependant le mérite de mettre l’accent sur les paramètres susceptibles d’influencer la réponse à ces questions au stade constitutionnel : nature exacte de l’espace des décisions (séquence de choix binaires, unidimensionalité, multidimensionalité), préférences individuelles et collectives sur cet espace, informations probabilistes. Par exemple, dans le cas binaire et de l’objectif utilitariste, nous avons mis en évidence que l’hypothèse IC ou l’hypothèse de stricte concavité de l’utilité du succès conduisaient à une proportionalité dégressive des poids, alors qu’à l’inverse l’hypothèse IAC couplée avec la linéarité de l’utilité débouchait sur une régle de proportionnalité où (cependant) le coefficient dépend de la nature consensuelle ou non du pays considéré. On retiendra qu’en tout état de cause, la façon de prendre en compte les comportements/préférences/utilités des électeurs (et de leurs représentants) et de les agréger au travers d’un objectif joue un rôle décisif dans la détermination des poids accordés à chaque État.
Appendices
Annexe
Jeux simples, indice de Banzhaf et indice de Shapley-Shubik
Soit L = {1,…, l} un ensemble d’électeurs. Un mécanisme de vote[53]C sur L est complètement décrit par la liste C–1(1) des coalitions S ⊆ L telles que C(S) = 1 : nous identifions la coalition S au vecteur l(S) défini par lk(S) = 1 ssi k ∈ S. Cette liste W de coalitions définit ce qui est communément appelé un jeu simple dès l’instant où ∅ ∉ W et L ∈ W[54] et W est monotone (S ∈ W et S ⊆ T ⇒ T ∈ W); une coalition S dans W sera appelée ici une coalition gagnante. Un jeu simple est dit propre si S, T ∈ W ⇒ S ∩ T ≠ ∅. Il est fort si pour tout S ⊆ L : S ∈ W ou L \ S ∈ W[55]. Un jeu est symétrique si S ∈ W et ![]() . Au nombre des jeux simples figurent en bonne place les jeux majoritaires pondérés (en particulier le jeu majoritaire ordinaire) et les jeux composés. Un jeu simple (L, W) est un jeu majoritaire pondéré si il existe un vecteur de poids (w1,…, wl)
. Au nombre des jeux simples figurent en bonne place les jeux majoritaires pondérés (en particulier le jeu majoritaire ordinaire) et les jeux composés. Un jeu simple (L, W) est un jeu majoritaire pondéré si il existe un vecteur de poids (w1,…, wl)![]() et un quota q > 0 tels que[56] :
et un quota q > 0 tels que[56] :
Le nombre q désigne le quota nécessaire pour valider la proposition qui est soumise au vote. Dans le corps du papier où L = {1,…, K}, le poids wk désigne le poids du représentant du district k dans le conseil. Si ![]() , le jeu W est propre. Lorsque les poids wi sont des entiers, le quota
, le jeu W est propre. Lorsque les poids wi sont des entiers, le quota  où
où ![]() désigne le premier entier strictement supérieur à x désigne le quota majoritaire et le jeu simple associé est appelé le jeu majoritaire ordinaire. Si
désigne le premier entier strictement supérieur à x désigne le quota majoritaire et le jeu simple associé est appelé le jeu majoritaire ordinaire. Si ![]() est impair, le jeu majoritaire ordinaire W est fort. Lorsque
est impair, le jeu majoritaire ordinaire W est fort. Lorsque ![]() est pair, ce n’est plus nécessairement le cas. Lorsqu’une telle situation se présente[57], un second jeu est utilisé pour départager les ex aequo, par exemple, l’un des joueurs peut être utilisé comme tie breaker. Dans le cas où tous les poids sont égaux à 1 et
est pair, ce n’est plus nécessairement le cas. Lorsqu’une telle situation se présente[57], un second jeu est utilisé pour départager les ex aequo, par exemple, l’un des joueurs peut être utilisé comme tie breaker. Dans le cas où tous les poids sont égaux à 1 et ![]() , on obtient le jeu majoritaire symétrique. Si l est impair, le jeu majoritaire symétrique est fort.
, on obtient le jeu majoritaire symétrique. Si l est impair, le jeu majoritaire symétrique est fort.
Supposons que l’ensemble L soit partitionné en sous-ensembles L1,…, LR et qu’à chacun de ces sous-ensembles Lr soit attaché une famille de coalitions gagnantes Wr. Si en sus des R jeux simples (Lr, Wr), on considère un jeu simple sur M = {1,…, R} dont la famille de coalitions gagnantes est ![]() , on peut définir un nouveau jeu simple noté
, on peut définir un nouveau jeu simple noté ![]() comme suit : S ∈ (W; W1,…,WR) ssi {r ∈ {1,…, R} : S ∩ Lr ∈ Wr} ∈
comme suit : S ∈ (W; W1,…,WR) ssi {r ∈ {1,…, R} : S ∩ Lr ∈ Wr} ∈ ![]() . Ce jeu, appelé jeu composé[58] (Shapley, 1962), décrit formellement l’opération de décision collective à deux étages dans sa forme la plus générale. Si on interprète M comme l’ensemble des représentants des districts, un jeu composé consiste à faire élire dans chaque district un représentant (représentant son district) et à ensuite réunir les représentants entre eux pour un second et ultime vote. Dans l’Union européenne, cela revient à diviser l’Europe en zones avec des règles d’élections propres à chaque zone puis une règle d’élection pour les représentants des zones. Si, au lieu de considérer L = {1,…, K}, on considère L = N, R = K et Lr = Nr, on aboutit au jeu composé où les joueurs sont les électeurs des districts et non leurs représentants. Le jeu simple Wr induit la fonction mr introduite dans la section 2.
. Ce jeu, appelé jeu composé[58] (Shapley, 1962), décrit formellement l’opération de décision collective à deux étages dans sa forme la plus générale. Si on interprète M comme l’ensemble des représentants des districts, un jeu composé consiste à faire élire dans chaque district un représentant (représentant son district) et à ensuite réunir les représentants entre eux pour un second et ultime vote. Dans l’Union européenne, cela revient à diviser l’Europe en zones avec des règles d’élections propres à chaque zone puis une règle d’élection pour les représentants des zones. Si, au lieu de considérer L = {1,…, K}, on considère L = N, R = K et Lr = Nr, on aboutit au jeu composé où les joueurs sont les électeurs des districts et non leurs représentants. Le jeu simple Wr induit la fonction mr introduite dans la section 2.
La notion de jeu de vote est combinatoire. Puisque le problème de ce papier est d’identifier le ou les mécanisme(s) de vote optimal(aux) pour un objectif donné, le problème d’optimisation est donc combinatoire. Il faut explorer un nombre fini de solutions possibles : parler de poids optimaux est donc abusif car il s’agit avant tout[59] de trouver l’ensemble optimal de coalitions gagnantes. Néanmoins la recherche de poids susceptibles d’éclairer la recherche du jeu simple optimal peut s’avérer utile et pertinente. Il est aussi pertinent d’attirer l’attention du lecteur sur le fait que le nombre de jeux simples ou même de certaines familles de jeux simples (jeux propres, forts, propres et forts (appelés à somme constante), complets[60], homogènes,..) croît très rapidement avec le nombre de joueurs. L’énumération des jeux à somme constante est due à von Neumann et Morgenstern (1944) pour l ≤ 5 et Gurk et Isbell (1959) pour l = 6. Isbell (1959) décrit la liste des 135 jeux majoritaires pondérés de somme constante pour l ≤ 7 avec leur unique représentation intégrale minimale; parmi ceux-ci, 38 sont homogènes[61]. Le tableau de la page suivante est empruntée à Krohn et Sudhölter (1995), à l’exception de la colonne l = 9 empruntée à Kurz (2012b). Notons que Krohn et Sudhölter ne supposent pas que ∅ ∉ W, N ∈ W.

L’énumération de tous les jeux simples (incluant les cas extrêmes V(∅) = 1 et V(N) = 0) est connue comme étant le problème de Dedekind. Le tableau ci-dessous reproduit l’énumération pour l ≤ 6.

L’énumération des jeux simples de somme constante est reproduite dans le tableau ci-dessous extrait de Loeb et Conway (2000) pour l ≤ 8.

Les énumérations des deux derniers tableaux comptent des jeux qui sont isomorphiques. En se limitant aux classes d’équivalence, on obtient les chiffres reportés dans le tableau ci-dessous pour l ≤ 6.

Étant donné un jeu simple C = (L, W) et un joueur i ∈ L, on dira qu’une coalition S telle que i ∉ S est un swing pour le joueur i si S ∉ W et S∪ {i} ∈ W. Dans le cas où un joueur compte à son actif de nombreux swings, on peut légitimement conclure qu’il est influent dans le contexte de ce jeu simple. Le nombre de swings du joueur i noté ηi(W) rapporté au nombre total de coalitions ne contenant pas le joueur i définit ce que l’on appelle le pouvoir de Banzhaf[62] du joueur i dans le jeu simple C = (L, W). Dans le texte, il est noté Bi(C). Par conséquent :
Le pouvoir de Shapley-Shubik du joueur i dans le jeu simple C = (L, W) est défini quant à lui par l’expression :
Il correspond à la valeur de Shapley du joueur i dans le jeu simple à utilité transférable dont la fonction caractéristique V est définie par :
Remerciements
Nous tenons à remercier chaleureusement les trois rapporteurs anonymes ainsi que l’éditeur, Arnaud Dellis, de leurs commentaires et remarques constructifs et pertinents. Ils ont aussi identifié des lacunes et des insuffisances sérieuses dans la version précédente. Nous exprimons aussi notre gratitude à Karine Van Der Straeten de nous avoir autorisés à reproduire dans la section 2 de nombreux développements contenus dans un article en préparation, mais non encore diffusé, coécrit avec le premier auteur de cet article (2015a). Vincent Merlin remercie le programme ANR-14-CE24-0007-01 CoCoRICo-CoDec pour son soutien financier.
Notes
-
[1]
La description de telles situations nous obligerait à introduire un modèle explicite de détermination des choix publics à l’échelon fédéral où le rôle des différents acteurs et leur interaction feraient l’objet d’une modélisation spécifique.
-
[2]
Peu de décisions font l’unanimité comme l’illustre l’analyse des votes sur la période 1998-2004 conduite par van Roozendaal, Hosli et Heetman (2012) sur les votes au sein du Conseil des ministres de l’Union européenne. À titre d’illustration, en date du 21 septembre 2015, le Conseil des ministres de l’intérieur de l’Union européenne a voté oui à une large majorité (quatre pays, la Hongrie, la Roumanie, le Slovaquie et la République tchèque ont voté non) à la prise en charge de 120 000 demandeurs d’asile fuyant leurs pays en guerre (Irak, Lybie, Syrie, etc.). Comme nous l’a fait remarquer un de nos arbitres, cette décision n’a pas été suivie d’effet. La question de la mise en oeuvre effective des décisions ayant fait l’objet d’un vote n’est pas abordée dans cet article.
-
[3]
Donner un poids de 100 dans un total de 1000 au représentant du pays à chaque fois qu’il vote n’est pas la même chose que de distribuer du mieux possible dans le parlement ce total de 100 entre les représentants des deux courants dans l’entité concernée.
-
[4]
L’intérêt pour ces questions est loin d’être récent : Theil et Schrage (1977) est un article pionnier à bien des égards.
-
[5]
Le processus de codécision est complexe; voir Napel et Widgren (2006) pour une analyse parmi d’autres.
-
[6]
Le traité de Lisbonne prévoit également une minorité de blocage composée d’au moins quatre États membres représentant plus de 35 % de la population de l’Union.
-
[7]
Il nous est impossible de faire l’inventaire de toutes les contributions sur ce sujet. Citons cependant, sans être exhaustif, Laruelle et Widgren (1998), Felsenthal et Machover (2001, 2003), Leech (2002a), Słomczyński et Życzkowski (2006), Kirsch, Słomczyński et Życzkowski (2007). On doit aussi mentionner le travail récent sur le traité de Lisbonne de Kurz et Napel (2015).
-
[8]
Voir Fleurbaey (2008). Pour une discussion fort instructive du point de vue de la philosophie politique, voir Brighhouse et Fleurbaey (2010).
-
[9]
i.e. N = ∪1≤ k ≤ K Nk et Nk ∩ Nl = ∅ pour k ≠ l.
-
[10]
Le problème du choix social dichotomique à valeurs privées sans transferts monétaires peut être formulé en toute généralité (c’est-à-dire sans exclure a priori la possibilité de révéler partiellement l’intensité des utilités pour les deux options) en utilisant la terminologie et les outils du mechanism design. Les implications de différentes versions des contraintes d’incitation sont explorées dans Schmitz et Tröger (2012) et Azrieli et Kim (2014).
-
[11]
Dans ces deux cas, nous avons supposé que le représentant choisissait 1 dans le cas où la version stricte du critère ne permet pas de conclure.
-
[12]
Le lecteur pourra consulter avec profit Fleurbaey (2008) pour une discussion de cette question dans le contexte de choix social examiné ici.
-
[13]
Nous avons déjà alerté le lecteur sur le fait qu’un mécanisme de vote est un objet combinatoire et que les poids servent uniquement d’auxiliaires de représentation.
-
[14]
Barberà et Jackson n’imposent pas à leur mécanisme d’être monotone. Notons que si un mécanisme n’est pas monotone, il n’est plus dans l’intérêt du représentant de reporter la véritable opinion majoritaire. Notons enfin que d’ordinaire, la définition de la notion de jeu majoritaire pondéré suppose des poids positifs.
-
[15]
La condition
 n’est pas suffisante pour garantir cette propriété. L’un des nos arbitres nous a proposé le contre-exemple λk suivant : un district k de taille 5, dans lequel chacune des 10 coalitions de taille 3 se réalise avec probabilité 3/40, et chacune des coalitions de taille 1 avec probabilité 1/20. Bien que chaque citoyen du district k soit en faveur de 1 une fois sur 2, la majorité l’est 3 fois sur 4.
n’est pas suffisante pour garantir cette propriété. L’un des nos arbitres nous a proposé le contre-exemple λk suivant : un district k de taille 5, dans lequel chacune des 10 coalitions de taille 3 se réalise avec probabilité 3/40, et chacune des coalitions de taille 1 avec probabilité 1/20. Bien que chaque citoyen du district k soit en faveur de 1 une fois sur 2, la majorité l’est 3 fois sur 4. -
[16]
Dans ce cas binaire on voit qu’il n’y a que deux cas possibles pour chaque citoyen (et aussi chaque district) : être du bon côté (voir sa préférence adoptée par le conseil) ou du mauvais côté (voir le conseil prendre la direction opposée). La question de l’intensité de la perte ou du gain a disparu.
-
[17]
Cette formule n’est valide que dans le cas où les votes des représentants sont des variables aléatoires de Bernoulli de paramètre
(Laruelle et Valenciano, 2005; Laruelle, Martinez et Valenciano, 2006; Le Breton et Van Der Straeten, 2015b) -
[18]
Voir l’annexe pour une définition formelle.
-
[19]
Effectivité est notre traduction de effectiveness. Weber considère le cas d’un nombre quelconque d’options (et non seulement deux comme ici) et suppose que l’utilité de chaque citoyen pour chaque option est la réalisation d’une variable aléatoire uniforme sur [0, 1]. La normalisation des utilités est donc différente de celle retenue ici : l’utilité espérée de chacune des deux options vaut
pour chaque individu. Donc l’utilité totale espérée du mécanisme aléatoire est . Weber définit l’effectivité comme le ratio des accroissements respectifs d’utilité totale par rapport au mécanisme aléatoire. D’après Weber (1995) : « The numerator represents the gain from using the voting system over choosing a candidate randomly. The denominator represents the maximum possible gain from any voting system over random selection. Thus, the ratio offers a measure of what share of the ideal gain is captured by a particular voting system. » Ici, notre point de référence n’est pas le mécanisme aléatoire, mais le maintien inconditionnel du statu quo, qui fournit par définition une utilité nulle. -
[20]
Cette section reproduit bon nombre des résultats de Le Breton et Van der Straeten (2015a).
-
[21]
Ces questions, précisées en annexe de Barberà et Jackson (2004), portent sur les thèmes de la défense, de la sécurité et des relations internationales.
-
[22]
La propriété classique d’échangeabilité due à De Finetti est une propriété de symétrie. Précisément, les variables aléatoires
sont échangeables si pour toute suite de -1 et de 1 et pour toute permutation σ de {1, 2,…, nk}. Un résultat élégant dû à De Finetti (Billingsley, 1995 : théorème 35.10) énonce que si le suite est infinie alors échangeabilité et échangeabilité forte coïncident. -
[23]
Pour tout x∈R, δx désigne la masse de Dirac en x.
-
[24]
Cette hypothèse souvent appelée hypothèse d’homogénéité est à la base de la description probabiliste de l’indice de Shapley-Shubik (voir Shapley et Shubik, 1954 et Straffin, 1977). Une définition apparaît dans l’annexe.
-
[25]
Voir également Kirsch et Langner (2014).
-
[26]
Nous avons déjà cité quelques références importantes dans l’introduction générale.
-
[27]
Cette conjecture générale est formulée dans Le Breton et Van der Straeten (2015a).
-
[28]
Citons aussi Le Breton, Lepelley et Smaoui (2016) où la notion de bloc est construite sur la base de corrélations locales de type IAC.
-
[29]
Notons qu’on peut aussi, dans ce contexte, introduire l’idée d’antagonisme (Straffin, Davis et Brams, 1981), à savoir que les corrélations sont parfois négatives au lieu d’être positives.
-
[30]
Nous présentons les jeux simples et l’indice de Banzhaf plus en détail dans l’annexe. Le lecteur pourra trouver ces notions clefs dans de nombreux ouvrages de théorie des jeux (Felsenthal et Machover, 1998) ou encore consulter l’excellente introduction de Gelman, Katz et Bafumi (2004).
-
[31]
Pour sûr, elles ne le sont pas systématiquement (Lindner et Owen, 2007).
-
[32]
Le travail de Laruelle et Widgren (1998) contenait un algorithme de recherche locale. Les niveaux de performance de ces algorithmes ne sont pas toujours bien connus. Sur ce point, voir De Nijs et Wilmer (2012).
-
[33]
On pourra également consulter Leech (2002b, 2003) et De Keijzer, Klos et Zhang (2014).
-
[34]
Voir aussi Kirsch, Slomczynski et Buczkowski (2007), Feix et al. (2007) et Kurth (2008).
-
[35]
Ce résultat est également obtenu par Chang, Chua et Machover (2006) et Beisbart et Bovens (2007) au travers de simulations. Nous renvoyons le lecteur aux commentaires de Beisbart et Bovens pour un examen plus détaillé de ce résultat qui est une mise en garde contre l’application non contrôlée de calculs asymptotiques.
-
[36]
En effet, la section 4 de leur article discute plusieurs interprétations possibles de leur travail. Nous renvoyons le lecteur à la sous-section 4-C de leur article et à leur proposition 6.
-
[37]
Dans le contexte de leur modèle aléatoire, Koriyama, Laslier, Macé et Treibich (2013) démontrent que le mécanisme optimal est le mécanisme où les poids sont tous égaux et le quota est égal au quota majoritaire.
-
[38]
Dans le cas où pour tout k = 1,…K, λk est symétrique, on peut utiliser la formule (3) pour déterminer les utilités des citoyens en fonction de leur district d’appartenance et chercher à les égaliser en choisissant adéquatement le mécanisme C (Beisbart et Bovens, 2007; Laruelle et Valenciano, 2008c).
-
[39]
Traditionnellement, en théorie du choix social, l’efficience majoritaire d’une règle de vote est la probabilité pour celle-ci de choisir le vainqueur de Condorcet lorsqu’il existe. On parle aussi d’efficience de Condorcet. Cette thématique a été portée par de nombreux travaux, que l’on trouvera décrits dans les livres de Gerhlein (2006) et Gerhlein et Lepelley (2010).
-
[40]
Sur ce point, voir également Hinich, Mickelsen et Ordeshook (1972).
-
[41]
Mentionnons également Beisbart et Bowens (2008) qui contient une analyse de plusieurs réformes du collège électoral américain.
-
[42]
Voir également Lepelley, Merlin, Rouet et Vidu (2014).
-
[43]
Rappelons cependant que le travail de Koriyama, Laslier, Macé et Treibich (2013) discuté dans la sous-section 4.1 ci-après peut aussi être vu comme une solution du problème binaire classique dans le cas où l’objectif social est la maximisation d’un critère utilitariste généralisé.
-
[44]
Une analyse approfondie du cas où il y plusieurs décisions apparaît dans la section 4 de Fleurbaey (2008). Sous l’hypothèse que l’utilité est additive, il explore la nature du mécanisme optimal pour des modèles aléatoires de plus en plus généraux.
-
[45]
Voir annexe.
-
[46]
Ils démontrent que U sera strictement concave si υ l’est. En fait, ils démontrent un résultat plus général qui ne suppose pas la symétrie entre les T décisions.
-
[47]
Maaser et Napel introduisent de façon très ingénieuse une mesure statistique de dissimilarité entre les districts.
-
[48]
Nous renvoyons le lecteur à Kauppi et Widgren (2004) pour une stimulante analyse économétrique de cette question.
-
[49]
Notons qu’il n’y a ici aucune incertitude.
-
[50]
Sur le nucléole comme indice de pouvoir et solution d’un jeu de marchandage, voir les travaux précurseurs de Montero (2005, 2006).
-
[51]
Voir annexe.
-
[52]
Le lecteur trouvera dans le chapitre 4 et la section 3 du chapitre 5 de Laruelle et Valenciano (2008c) une présentation synthétique de leurs résultats.
-
[53]
On peut définir un mécanisme de vote probabiliste comme une application C de {0, l}l dans [0, l] où C(r) s’interprète comme la probabilité de choisir 1 lorsque le profil des votes est r.
-
[54]
Le mécanisme n’est pas constant.
-
[55]
Le mécanisme F traite équitablement les deux alternatives si et seulement si le jeu W est propre et fort. En effet soit P un profil tel que F(P) = 1. Par conséquent, si S représente la coalition des joueurs votant 1 alors S ∈ W. Considérons le profil P' où les sélecteurs de S votent maintenant 0 et ceux de L\S votent 1. Puisque W est propre, S ∈ W, L\ S ∉ W c’est-à-dire : F(P') = 0. Si P un profil tel que F(P) = 0, alors S ∉ W. Puisque W est fort, L\ S ∈ W. On en déduit F(P’) = 1. On vérifie réciproquement que si F est neutre alors W est propre et fort.
-
[56]
On dit alors que
est une représentation de (L,W). Elle est dite normalisée si et intégrale si les poids wi sont des nombres entiers. -
[57]
C’est par exemple la cas du collège électoral américain de 2008 avec l = 51 et des poids wi tels que
et donc . En cas d’égalité (269 votes pour chacun des deux candidats), c’est la chambre des représentants (qui comprend 435 membres) qui élit le président. -
[58]
Compound simple games.
-
[59]
Même si dans certains cas (pour de petites valeurs de l) il existe des représentations canoniques uniques.
-
[60]
Dans le jeu simple (L, W), le joueur i est plus désirable que le joueur j si S ∈ W et J ∈ S ⇒ (S\{j})∪{i}∈ W. Si la relation binaire « être plus désirable que » est un préordre total, on dit que le jeu est complet. Si le préordre total est l’ordre naturel des joueurs, on dit que le jeu simple est dirigé.
-
[61]
Une coalition gagnante est minimale si elle est minimale au sens de l’inclusion. Un jeu simple (N, W) est homogène si toutes les coalitions gagnantes minimales sont de même taille.
-
[62]
Qui se distingue du pouvoir de Shapley et Shubik (1954).
 . En cas d’égalité (269 votes pour chacun des deux candidats), c’est la chambre des représentants (qui comprend 435 membres) qui élit le président.
. En cas d’égalité (269 votes pour chacun des deux candidats), c’est la chambre des représentants (qui comprend 435 membres) qui élit le président.Bibliographie
- Alon, N. et P. H. Edelman (2010), « The Inverse Banzhaf Problem », Social Choice and Welfare, 34 : 371-377.
- Azrieli, Y. et S. Kim (2014), « Pareto Efficiency and Optimal Voting Rules », International Economic Review, 55 : 1067-1088.
- Balinski, M. et P. Young (1982), Fair Representation, New Haven, Yale University Press.
- Banzhaf, J.F. (1965), « Weighted Voting Does not Work: a Mathematical Analysis », Rutgers Law Review, 19, 317-343.
- Barberà, S. et M.O. Jackson (2004), « On the Weights of Nations: Assigning Voting Weights in a Heterogeneous Union », Nota di lavoro 76.2004. The Fondazione Eni Enrico Mattei. http://www.feem.it/Feem/Pub/Publications/WPapers/default.htm
- Barberà, S. et M.O. Jackson (2006), « On the Weights of Nations: Assigning Voting Weights in a Heterogeneous Union », Journal of Political Economy, 114 : 317-339.
- Baron, D. et Ferejohn, J. (1989), « Bargaining in Legislature », American Political Science Review, 83 : 1181-1206.
- Beisbart, C. et L. Bovens (2007), « Welfarist Evaluations of Decision Rules for Board of Representatives », Social Choice and Welfare, 29 : 581-608.
- Beisbart, C. et L. Bovens (2008), « A Power Measure Analysis of Amendment 36 in Colorado », Public Choice, 124 : 231-246.
- Beisbart, C. et L. Bovens (2013), « Minimizing the Threat of a Positive Majority Deficit in Two-Tier Voting Systems with Equipopulous Units », Public Choice, 145 : 75-94.
- Beisbart, C., L. Bovens et S. Hartmann (2005), « Welfarist Foundations of Alternative Decision Rules in the Council of Ministers », European Union Politics, 6 : 395-419.
- Beisbart, C. et S. Hartmann (2010), « Welfarist Evaluations of Decision Rules under Interstate Utility Dependencies », Social Choice and Welfare, 34 : 315-344.
- Berg, S. (1990), « The Probability of Casting a Decisive Vote : The Effects of a Caucus », Public Choice, 64 : 73-92.
- Billingsley, P. (1995), Probability and Measure, Third Edition, John Wiley.
- Bisson, F., J. Bonnet et D. Lepelley (2004), « La détermination du nombre des délégués au sein des structures intercommunales : une application de l’indice de pouvoir de Banzhaf », Revue d’Economie Régionale et Urbaine, 2 : 259-282.
- Brighhouse, H. et M. Fleurbaey (2010), « Democracy and Proportionality », Journal of Political Philosophy, 18 : 137-155.
- Chang, P.L. Chua, V.C.H. et M. Machover (2006), « LS Penrose’s Limit Theorem: Test by Simulation », Mathematical Social Sciences, 51 : 90-106.
- Curtis, R.B. (1972), « Decision Rules and Collective Values in Constitutional Choice », in Niemi, R. et H. Weisberg (éds), Probability Models of Collective Decision Making, Merrill, Columbus, Ohio.
- De Nijs, F. et D. Wilmer (2012), « Evaluation and Improvement of Laruelle-Widgren Inverse Banzhaf Approximation », mimeo. available at http://arxiv.org/abs/1206.1145.
- de Keijzer, B., T. Klos et Y. Zhang (2014), « Finding Optimal Solutions for Voting Game Design Problems », Journal of Artificial Intelligence Research, 50 : 105-140.
- Dubey, P. et L.S. Shapley (1979), « Mathematical Properties of the Banzhaf Power Index », Mathematics of Operations Research, 4 : 99-131.
- Feix, M.R., D. Lepelley, V. Merlin et J.L. Rouet (2004), « The Probability of Conflicts in a U.S. Presidential Type Election », Economic Theory, 23 : 227-257.
- Feix, M.R., D. Lepelley, V. Merlin et J.L. Rouet (2007), « On the Voting Power of an Alliance and the Subsequent Power of its Members », Social Choice and Welfare, 28 : 181-207.
- Feix, M.R., D. Lepelley, V. Merlin, J.L. Rouet et L. Vidu (2008), « Majority Efficient Representation of the Citizens in a Federal Union », miméo, Université de Caen.
- Felsenthal, D.S. et M. Machover (1998), The Measurement of Voting Power, Edward Edgar, Northampton.
- Felsenthal, D.S. et M. Machover (1999), « Minimizing the Mean Majority Deficit: The Second Square Root Rule », Mathematical Social Sciences, 37 : 25-37.
- Felsenthal, D.S. et M. Machover, M. (2001), « The Treaty of Nice and Qualified Majority Voting », Social Choice and Welfare, 18 : 431-464.
- Felsenthal, D.S. et M. Machover (2003), « Analysis of QM Rules in the Draft Constitution for Europe Proposed by the European Convention », Social Choice and Welfare, 23 : 1-20.
- Fleurbaey, M. (2008), « One Stake, One Vote », miméo.
- Gelman, A., J.N. Katz et J. Bafumi (2004), « Stetard Voting Power Indexes Don’t Work: An Empirical Analysis », British Journal of Political Sciences, 34 : 657-674.
- Gerhlein, W. (2006), Condorcet’s Paradox, Springer.
- Gerhlein, W. et D. Lepelley (2010), Voting Paradox and Group Coherence : The Condorcet Efficiency of Voting Rules, Springer.
- Gurk, H.M. et J.R. Isbell (1959), « Simple Solutions », in Annals of Mathematics Studies,Contributions to the Theory of Games IV, Volume 40, Princeton University Press, p. 247-265.
- Hinich, M.J., R. Mickelsen et P.C. Ordeshook (1972), « The Electoral College Versus a Direct Vote: Policy Bias, Reversals, and Indeterminate Outcomes », Journal of Mathematical Sociology, 4 : 3-35.
- Isbell, J.R. (1959), « On the Enumeration of Majority Games », Mathematical Tables and Other Aids to Computation, 13 : 21-28.
- Kalandrakis, T. (2006), « Proposal Rights and Political Power », American Journal of Political Science, 50 : 441-448.
- Kauppi, H. et M. Widgren (2004), « What Determines EU Decision Making: Needs, Power or Both ? », Economic Policy, 19 : 221-266.
- Kirsch, W. et J. Langner (2014), « The Fate of the Square Root Law for Correlated Voting », in Fara, R, D. Leech et M. Salles (éds), Voting Power and Procedures, Studies in Social Choice and Welfare, Springer, p. 159-176.
- Kirsch, W., W. Slomczynski et K. Buczkowski (2007), « Getting the Votes Right », European Voice, 12.
- Koriyama, Y., J.F. Laslier, A. Macé et R. Treibich (2013), « Optimal Apportionment », Journal of Political Economy, 121 : 584-608.
- Krohn, I. et P. Sudhölter (1995), « Directed and Weighted Majority Games », Mathematical Methods of Operations Research, 42 : 189-216.
- Kurth, M. (2008), « Square Root Voting in the Council of the European Union: Rounding Effects and the Jagiellonian Compromise », Available at http://arxiv.org/abs/0712.2699.
- Kurz, S. (2012a), « On the Inverse Power Index Problem », Optimization, 61 : 989-1011.
- Kurz, S. (2012b), « On Minimum Sum Representations for Weighted Voting Games », Annals of Operations Research, 196 : 361-369.
- Kurz, S et J.F Napel (2014), « Heuristic and Exact Solutions to the Inverse Power Index Problem for Small Voting Bodies », Annals of Operations Research, 215 : 137-163.
- Kurz, S. et S. Napel (2015), « Dimension of the Lisbon Voting Rules in the EU Council A Challenge and New World Record », Optimization Letters, DOI : 10.1007/s11590-015-0917-0
- Kurz, S., N. Maaser, S. Napel et M. Weber (2015), « Mostly Sunny: A Forecast of Tomorrow’s Power Index Research », Homo Oeconomicus, 32 : 133-146.
- Kurz, S., N. Maaser et S. Napel (2016), « On the Democratic Weights of Nations », Journal of Political Economy, à paraître.
- Kurz, S., A. Nohn et S. Napel (2014), « The Nucleolus of Large Majority Games », Economics Letters, 123 : 139-143.
- Lahrach, R. et V. Merlin (2012), « Which Voting Rule Minimizes the Probability of the Referendum Paradox? Lessons from French Data », in Felsenthal, D.S. et M. Machover (éds), Electoral Systems, Paradoxes, Assumptions and Procedures, Studies in Choice and Welfare, Springer, 129-150.
- Laruelle, A., R. Martinez et F. Valenciano (2006), « Success Versus Decisiveness: Conceptual Discussion and Case Study », Journal of Theoretical Politics, 18(2) : 185-205.
- Laruelle, A. et F. Valenciano (2005), « Assessing Success and Decisiveness in Voting Situations », Social Choice and Welfare, 24 : 171-197.
- Laruelle, A. et F. Valenciano (2007), « Bargaining in Committees as an Extension of Nash’s Bargaining Theory », Journal of Economic Theory, 132 : 291-305.
- Laruelle, A. et F. Valenciano (2008a), « Bargaining in Committees of Representatives: The Neutral’s Voting Rule », Journal of Theoretical Politics, 20 : 93-106.
- Laruelle, A. et F. Valenciano (2008b), « Non-Cooperative Foundations of Bargaining Power in Committees », Games and Economic Behavior, 63 : 341-353.
- Laruelle, A. et F. Valenciano (2008c), Voting and Collective Decision-Making : Bargaining and Power, Cambridge University Press, Cambridge.
- Laruelle, A. et F. Valenciano (2010), « Egalitarianism and Utilitarianism in Committes of Representatives », Social Choice and Welfare, 35 : 221-243.
- Laruelle, A. et M. Widgren (1998), « Is the Allocation of Power among EU States Fair? », Public Choice, 94 : 317-340.
- Laslier, J.F. (2012), « Why not Proportional? », Mathematical Social Sciences, 63 : 90-93.
- Le Breton M., D. Lepelley et H. Smaoui (2016), « Correlation, Partitioning and the Probability of Casting a Decisive Vote », Journal of Mathematical Economics, 64 : 11-22.
- Le Breton, M., M. Montero et V. Zaporozhets (2012), « Voting Power in the EU Council of Ministers and Fair Decision Making in Distributive Politics », Mathematical Social Sciences, 63 : 159-173.
- Le Breton, M. et K. VanDer Straeten (2015a), « The Social Cost of Districting », Toulouse School of Economics, en préparation.
- Le Breton, M. et K. Van Der Straeten (2015b), « Influence Versus Utility in the Evaluation of Voting Rules: A New Look at the Penrose Formula », Public Choice, 165 : 103-122.
- Leech, D. (2002a), « Designing the Voting System for the EU Council of Ministers », Public Choice, 113 : 437-464.
- Leech, D. (2002b), « Voting Power in the Governance of the International Monetary Fund », Annals of Operations Research, 109 : 375-397.
- Leech, D. (2003), « Power Indices as an Aid to Institutional Design: The Generalised Apportionment Problem », in Holler, M.J., H. Kliemt, D. Schmidtchen et M. E. Streit (éds), Jahrbuch fur Neue Politische Okonomie, Tubingen : Mohr Siebeck, p. 22.
- Lepelley, D., V. Merlin et J.L. Rouet (2011), « Three Ways to Compute Accurately the Probability of the Referendum Paradox », Mathematical Social Sciences, 62 : 28-33.
- Lepelley, D., V. Merlin, J.L. Rouet et L. Vidu (2014), « Referendum Paradox in a Federal Union with Unequal Populations: The Three State Case », Economics Bulletin, 34 : 2201-2207.
- Lindner, I. et M. Machover (2004), « L.S. Penrose’s Limit Theorem: Proof of Some Special Cases », Mathematical Social Sciences, 47 : 37-49.
- Lindner, I. et M. Machover (2007), « Cases where the Penrose Limit Theorem Does not Hold », Mathematical Social Sciences, 53 : 232-238.
- Loeb, D.E. et A.R. Conway (2000), « Voting Fairly: Transitive Maximal Intersecting Family of Sets », Journal of Combinatorial Theory, Series A, 91 : 386-410.
- Maaser, N. et S. Napel (2007), « Equal Representation in Two-Tier Voting Systems », Social Choice and Welfare, 28 : 401-420.
- Maaser, N. et S. Napel (2012), « A Note on the Direct Democracy Deficit in Two-tier Voting », Mathematical Social Sciences, 63 : 174-180.
- Maaser, N. et S. Napel (2014), « The Mean Voter, the Median Voter and Welfare Maximizing Voting Weights », in Fara, R., D. Leech and M. Salles (éds), Voting Power and Procedures, Studies in Social Choice and Welfare, Springer, p. 159-176.
- Macé, A. et R. Treibich (2012), « Computing the Optimal Weights in a Utilitarian Model of Apportionment », Mathematical Social Sciences, 63 : 41-51.
- Maggi, G. et M. Morelli (2006), « Self-Enforcing Voting in International Organizations », American Economic Review, 96 : 1137-1158.
- May, K. (1949), « Probabilities of Certain Election Results », American Mathematical Monthly, 55 : 203-209.
- Montero, M. (2005), « On the Nucleolus as a Power Index », Homo Oeconomicus, 22 : 551-567.
- Montero, M. (2006), « Noncooperative Foundations of the Nucleolus in Majority Games », Games and Economic Behavior, 54 : 380-397.
- Miller, N.R. (2012), « Election Inversions by the U.S. Electoral College », Chapitre 4, in Felsenthal, D.S. et M. Machover (éds), Electoral Systems, Studies in Social Choice and Welfare, Springer-Verlag, Berlin Heidelberg.
- Napel, S. et M. Widgren (2006), « The Inter-Institutional Distribution of Power in European Union Codecision », Social Choice and Welfare, 27 : 129-154.
- Nurmi, H., (1999), Voting Paradoxes and How to Deal with Them?, Springer-Verlag, Berlin Heidelberg.
- Penrose, L.S. (1946), « The Elementary Statistics of Majority Voting », Journal of the Royal Statistical Society, 109 : 53-57.
- Penrose, L.S., (1952), On the Objective Study of Crowd Behavior, H.K. Lewis et Co, London.
- Pukelsheim, F. (2014), Proportional Representation, Springer-Verlag, Berlin Heidelberg.
- Rae, D.W. (1969), « Decision Rules and Individual Values in Constitutional Choice », American Political Science Review, 63 : 40-56.
- van Roozendaal, P., M.O. Hosli et C. Heetman (2012), « Coalition Formation on Major Policy Dimensions: The Council of the European Union 1998 to 2004 », Public Choice, 153 : 447-467.
- Schofield, N. (1972), « Is Majority Rule Special? », in Niemi, R. et H. Weisberg (éds), Probability Models of Collective Decision Making, Merrill, Columbus, Ohio.
- Shapley, L.S. (1962), « Simple Games: An Outline of the Descriptive Theory », Behavioral Science, 7 : 59-66.
- Shapley, L.S. et M. Shubik (1954), « A Method for Evaluating the Distribution of Power in a Committee System », American Political Science Review, 48 : 787-792.
- Schmitz, P.W. et T. Tröger (2012), « The (Sub-) Optimality of the Majority Rule », Games and Economic Behavior, 74 : 651-665.
- Słomczyński, W. et K. Życzkowski (2006), « Penrose Voting System and Optimal Quota », Acta Physica Polonica, 37 : 3133-3143.
- Słomczyński, W. et K. Życzkowski (2008), « From a Toy Model to the Double Square-root Voting System », Homo Oeconomicus, 24 : 381-399.
- Słomczyński, W. et K. Życzkowski (2014), « Square Root Voting System, Optimal Threshold and p », in Fara, R. D. Leech et M. Salles (éds), Voting Power and Procedures, Studies in Social Choice and Welfare, Springer, p. 127-146.
- Straffin, P.D. (1977), « Homogeneity, Independence and Power Indices », Public Choice, 30 : 107-118.
- Straffin, P.D., M.D. Davis et S.J. Brams (1981), « Power and Satisfaction in an Ideologically Divided Voting Body », in Holler, M.J. (éd.), Power, Voting and Voting Power, Physica-Verlag, Würzburg.
- Taylor, A.D. et W.S. Zwicker (1999), Simple Games, Princeton, Princeton University Press.
- Theil, H. et L. Schrage (1977), « The Apportionment Problem and the European Parliament », European Economic Review, 9 : 247-263.
- Von Neumann, J. et O. Morgenstern (1944), Theory of Games and Economic Behavior, Princeton : Princeton University Press.
- Weber, R.J. (1978), « Comparison of Public Choice Systems », Cowles Foundation Discussion Paper N˚ 498, Yale University.
- Weber, R.J. (1995), « Approval Voting », Journal of Economic Perspectives, 9 : 39-49.
List of tables
Tableau 1
Marges de victoire estimées (UE 27)
Tableau 2
Poids calculés (UE 27)
Tableau 3
Corrélation entre les votes
Tableau 4
Coefficient de proportionnalité