
Abstracts
Abstract
Anthony Burgess’s 1962 novella A Clockwork Orange is one of the most popular speculative works of fiction of all time, having been translated over fifty times into more than thirty different languages. Each translator of this work is faced with the challenge of adapting Burgess’s invented anti-language, Nadsat, into their target language. Some translations have managed this more successfully than others. The French translation, by Georges Belmont and Hortense Chabrier, L’Orange Mécanique (1962/1972) is considered particularly successful and remains the standard French translation nearly 50 years on. Previous studies have remarked on the creativity shown by these translators in reconstructing Nadsat in the target language. However, previous work has not closely analysed the consistency that Belmont and Chabrier brought to this task. In this paper, we use corpus linguistics methodologies to examine the construction of French-Nadsat, and compare it to the Nadsat presented in the source text. We identify six categories of French-Nadsat, all of which are in some way analogous with categories identified in English-Nadsat. We then employ corpus techniques which demonstrate the high level of consistency that Belmont and Chabrier used in their translation to ensure that the lexical distinctions present in English-Nadsat are largely preserved in the translation. This paper thus demonstrates the value of corpus methodologies in investigating the consistency of translations of creative texts where a third “language” (L3) is present, an approach that is largely lacking in previous work on the translation of this novel into other languages.
Keywords:
- translation strategies,
- corpora in translation,
- invented languages,
- literary translation,
- speculative fiction
Résumé
Le roman d’Anthony Burgess A Clockwork Orange (1962) qui reste aujourd’hui une oeuvre très appréciée des lecteurs de la fiction spéculative a été traduit plus d’une cinquantaine de fois en plus de trente langues différentes. Chaque traducteur a dû relever le défi que présente la langue inventée par Burgess, le nadsat, et en trouver des équivalents dans la langue cible. Dans le cadre précis de la traduction des termes du nadsat employés dans la version originale, certaines traductions ont mieux réussi que d’autres. La traduction française, assurée par Georges Belmont et Hortense Chabrier, L’Orange Mécanique (1962/1972), est considérée comme une grande réussite et reste à ce jour la seule traduction française disponible. Son succès serait dû en grande partie aux efforts considérables des traducteurs pour recréer le nadsat en français. Dans le présent article, nous appliquons les méthodologies de la linguistique de corpus afin d’analyser la création du nadsat français en le comparant au nadsat anglais tel qu’il se présente dans le texte source. Nous identifions six catégories de la version française du nadsat qui montrent une forte compatibilité avec la version anglaise et qui nous permettent aussi d’apprécier la qualité du travail de traduction de Belmont et Chabrier. Nous proposons également que les méthodes de la linguistique de corpus offrent un moyen novateur d’évaluer des traductions de textes présentant un haut degré de créativité linguistique, qu’il s’agisse d’une forte utilisation de termes argotiques qui s’écartent des normes de la langue ordinaire, ou bien de la présence d’une troisième langue (L3).
Mots-clés :
- stratégies de traduction,
- corpus en traduction,
- langues inventées,
- traduction littéraire,
- fiction spéculative
Resumen
La novela corta de 1962 de Anthony Burgess, A Clockwork Orange (La Naranja Mecánica) es una de las ficciones especulativas más populares del mundo, habiendo sido traducida más de cincuenta veces a más de treinta idiomas distintos. Cada traductor se enfrenta al reto de adaptar el idioma inventado de Burgess, nadsat, a su idioma destino. Algunas traducciones han logrado esto con más éxito que otras. La traducción francesa por Georges Belmont y Hortense Chabrier, L’Orange Mécanique (1962/1972) es considerada particularmente exitosa, y ha continuado siendo la traducción francesa estándar por casi 50 años. Estudios anteriores han comentado sobre la creatividad demostrada por estos traductores en la reconstrucción del nadsat al idioma destino. Sin embrago, no se ha analizado aun la consistencia que Belmont y Chabrier brindaron a la misma. En esta artículo, utilizamos metodologías de lingüística de corpus para examinar la creación del nadsat-francés y lo comparamos al nadsat-inglés tal como ocurre en el texto original. Identificamos seis categorías de nadsat, todas las cuales son análogas a categorías identificadas en el nadsat-inglés. Además, empleamos técnicas de corpus que demuestran el alto nivel de consistencia que Belmont y Chabrier usaron en su traducción para asegurar que las distinciones lexicales presentes en el nadsat-inglés fuesen preservadas en la traducción. Esta ponencia, por ende, demuestra el valor de las metodologías de corpus para investigar la consistencia de traducciones de textos creativos donde un tercer ‘idioma’ (L3) esta presente, un enfoque que está en gran parte carente en trabajos previos acerca de la traducción de esta novela a otros idiomas.
Palabras clave:
- estrategias de traducción,
- corpora en traducción,
- idiomas inventados,
- traducción literaria,
- ficción especulativa
Article body
1. Introduction
1.1. A Clockwork Orange and Nadsat
Although Anthony Burgess (1917-1993) was a prolific novelist, journalist, translator, composer, and polymath, he is primarily known for one short novella, the influential dystopian text A Clockwork Orange[1] (henceforth ACO), first published in 1962. This work attracted worldwide attention thanks to its 1971 film adaptation[2] by Stanley Kubrick; it has since been translated more than 50 times into at least 32 different languages.
Readers of the book (and viewers of the film) are immediately struck by its unusual use of language. This effect is largely due to “Nadsat,” the anti-language (Halliday 1976; Fowler 1979; Janak 2015) Burgess invented for his teenage protagonist and narrator, Alex, and his gang of droogs to describe their rampage across the dystopian landscape they inhabit. An anti-language is a deliberately obscure lexicon used by a group that sets itself up as antithetical to society, in order to communicate with each other and exclude outsiders (Halliday 1976). In the case of Nadsat, the main component contributing to this effect is Russian lexis; the name Nadsat itself reflects this, being a transliteration of the Russian suffix found in the numbers 11-19, making it largely analogous with -teen in English. Another example of this is droog, which is based on the Russian word meaning ‘friend,’ друг. As in the case of droog, most Russian items involve a relatively straightforward transliteration of Russian counterparts of the English word. In other cases, however, the forms and/or the meanings of these items are adapted in various ways. In terms of formal changes, various devices are found, such as truncation – for instance, the Russian человек (chelovek) [person] becomes veck) – and the addition of English suffixes – брат (brat) [brother] becomes bratty. In terms of wordplay based on meaning, Nadsat includes calques such as ptitsa, the Russian word for bird being used in the slang sense of the English word, that is, to refer to a girl or woman. Perhaps the most obvious uses of wordplay, however, are adaptations of transliterated Russian words which then allude to other English words (Maher 2011; Malamatidou 2017; Meteva-Rousseva 2018). The most famous example of these sees the Russian word хорошо [good], which would normally be transliterated khorosho, become horrorshow, indicating that what Alex considers “good” may not coincide with the moral understanding of the average reader.
However, words based on Russian lexis are not the only component of Nadsat. There is also a very small contingent of words from other languages (for instance, tass comes from French tasse or German tasse, both equivalents of cup) or of doubtful etymology (like lighter [woman]).[3] Further categories can also be identified, as shown by Vincent and Clarke (2017): “Archaisms” involve the use of archaic words or forms such as thou; words classed as “Babytalk” (eggiweg for egg) duplicate the first syllable with an intervening (i)w where necessary; “Compounding” creates words not found in standard English, such as sleepland; the process of “Truncation” shortens words (such as guff for guffaw); “Rhyming Slang” items use rhyme to create items like pretty polly (rhymes with lolly, a slang term for money); a final category is “Creative Morphology,” which sees the use of creative adaptations of English words, either simply to change their form (for example, appetitish), to change the form in order to suggest a double meaning (like with syphilised instead of civilised), or to use a word with a new meaning (namely, cancer to mean cigarette and the derived adjective cancery).
The idea in basing Nadsat largely on a lexis of Russian loanwords was to combine “the two chief political languages of the age” (Burgess 1990: 38) at the height of the Cold War. The aim in so doing was to “brainwash” the reader into learning Russian (Burgess 1990: 38), which acts as a parallel with the brainwashing theme of the novella itself (Maher 2011). The inclusion of other components can be seen partly as a reflection of Burgess’s fondness for wordplay, partly as a reflection of word formation changes in natural languages and therefore as a device to lend verisimilitude to Nadsat, and partly as a nod to other known anti-languages (for instance, rhyming slang). What the combination of these components in Nadsat creates overall is a defamiliarizing effect (Shklovsky 1917/1965; Maher 2010) by drawing the reader’s attention to the language of the text and forcing them to work to decipher Alex’s speech. In so doing, readers are also introduced to his skewed and unfamiliar worldview. This aspect of the book has not, however, always been well understood by critics; the perceived impenetrability of Nadsat led Hyman (1963) to append a glossary together with an introductory note to the first US edition of the book in a move contradictory to Burgess’s express wishes.
1.2. The challenge for translators
As a result of its language experimentation, ACO, and in particular Nadsat, presents a considerable challenge for translators who want to recreate the impact of Burgess’s invented anti-language. Burgess himself (1990: 12) alluded to this difficulty in translating his works, arguing that his “translator must be himself [sic] a committed writer.” This is an interesting point, since it indicates Burgess’s awareness of the complexities of literary translation and of the creativity required to make it successful, an observation echoed by Polizzotti (2018). Indeed, this sort of challenge draws attention to what Eco (2003: 56) refers to as the process of “negotiation” through which translators attempt to “create the same effect in the mind of the reader (obviously according to the translator’s interpretation) as the original text wanted to create.”
Translators of ACO, therefore, need to consider a number of different questions, the answers to which will depend on the characteristics of the target language, their own inclinations and their reaction to the source text (ST). It is important also to bear in mind considerations relating to the target culture and the extent to which this culture may be open to the sort of linguistic innovation seen in the ST (Lefevere 1992; Eco 2003; Maher 2011). The most obvious challenge in translating ACO is how to recreate the defamiliarisation produced by Nadsat, ensuring its presentation as an anti-language reflecting an “antagonistic relationship with the norm society” (Fowler 1979: 142). The success of a translation of ACO should thus not be measured in terms of its accessibility, since the ST is itself deliberately inaccessible (Mäkelä 2015; Malamatidou 2017). These considerations make translations of ACO in general, and of Nadsat in particular, an interesting site for investigating translation strategy, where strategy is seen as an overall consistent approach or orientation to translation which may be realized by means of a number of different “procedures” (Munday 2001/2013). A source-oriented strategy, one that follows the ST by basing it on Russian lexis, or finds some other analogous approach, for example when translating into Slavic languages, tends to be seen as satisfactory (Malamatidou 2017).
1.3. Evaluations of translations of ACO
As we mentioned in Section 1.1, ACO has attracted many translators. Their translations in turn have attracted interest from scholars interested in how these translators deal with the challenge of Nadsat. A common theme of this work is that the treatment of Nadsat is found wanting in various ways.
One set of interesting cases relates to the translation of ACO into Russian and other Slavic languages, such as Polish, which poses obvious problems bearing in mind the Russian influence in the composition of English-Nadsat. Windle (1995) and Ginter (2003) find Boshniak’s translation (Burgess 1962/1991b) unsatisfactory because it opted for a target-oriented strategy, preserving Russian Nadsat words from the ST and transliterating them into Latin script while adding some Russian slang. This approach is similar to that taken by Stiller (Burgess 1962/1999) for his first translation into Polish (Corness 2018; Ginter 2003), which again adapts Russian (and therefore largely cognate) words for its main Nadsat component and has similar weaknesses to Boshniak’s translation, being too “transparent” (Corness 2018). A contrasting strategy is shown by Sinel’shchikov’s Russian translation (Burgess 1962/1991a), which followed Burgess’s suggestion to reverse the languages, writing English words in Cyrillic script (Windle 1995) and Stiller’s “Version A” (Burgess 1962/2001), which also relies on Anglicisms (Corness 2018; Ginter 2003). This source-oriented strategy appears more appropriate for dealing with the problem of Nadsat, but both translations still come in for criticism. In Sinel’shchikov’s case, Windle finds there to be some inconsistency in Nadsat terms which receive this treatment, but the basic issue is that, by 1991, English was not as unfamiliar to the typical Russian reader as Russian was to the English-speaking readers of ACO (Windle 1995). Corness (2018) finds fault with Stiller’s “Version A” translation for over-interpreting the original Nadsat and for an inconsistent treatment of a number of key Nadsat words such as droog. Nevertheless, he sympathizes with Stiller’s difficulties in translating a book that relies heavily on repetition for its effect in Polish, a language that does not tolerate such repetition. The inconsistency that Corness finds in Stiller’s Polish translations is echoed by Janak (2015) with respect to how Nadsat items are treated in Czech and German translations.
Another translation that has attracted some attention is Bossi’s Italian version (Burgess 1962/1972a). This translation takes the target-oriented strategy of avoiding Russian lexis and instead adapts Italian dialect and slang to this end (Maher 2010, 2011). Maher (2011) points out that Bossi’s strategy results in a target text (TT) that is more accessible than the ST, with a resulting reduction in impact, which acts to subvert the aims of the ST. Burgess (1990) himself was critical of this translation for these reasons. A reason for this strategy, proposed by Maher (2011), is that Bossi may have been constrained by Italian norms of the time relating to the acceptability of “transgressive prose.” That is, it was not linguistic but rather poetic factors that proved an obstacle.
In contrast to the mainly critical reception that translations of Nadsat and ACO have had, the French translation has generally attracted positive attention. This translation (Burgess 1962/1972b), entitled L’Orange Mécanique (LOM), was undertaken by Georges Belmont and Hortense Chabrier in 1972. It is notable since Burgess was privy to at least some of its construction—being in relatively regular contact with Belmont (Pochon 2010)—giving the translation a dimension of indirect authorial authority that the translations mentioned above lack. Burgess approved of Belmont and Chabrier’s work on LOM and used them as translators for several of his other novels (Burgess 1990; Bogic 2009/2017). His approval is apparently matched by that of French readers, since it remains the sole French translation of the work, with at least five new editions since 1972.[4] This longevity can be seen in contrast to languages such as Russian and Polish, which, as we have seen, have competing versions, sometimes by the same translator (Windle 1995; Janak 2015; Corness 2018).
Another notable aspect of LOM is that it includes a “translators’ note” (Belmont and Chabrier 1972), which sets out Belmont and Chabrier’s source-oriented strategy in carrying out the translation. This note specifically mentions the importance of preserving Burgess’s original intention for the work and the consequent recreation of “oddities of vocabulary”[5] (Belmont and Chabrier 1972: 5). In this way, Belmont and Chabrier explicitly draw attention to their commitment to pursuing Burgess’s aesthetic vision, paying careful attention to these “oddities.”[6]
It is perhaps not surprising, then, that Belmont and Chabrier’s translation has generally been positively evaluated. Bogic (2009/2017) notes the creativity of the translation with respect to items such as starry [old], which is translated as viokcha,[7] a word adapted from the French vioc, a term used to refer to an old person or to a parent,[8] and horrorshow, whose French-Nadsat equivalent is tzarrible (tzar + terrible). In a more detailed and wide-ranging study, Pochon (2010) identifies procedures such as the technique of adaptations to French words in the TT that cleverly mirrors a technique Burgess uses in the ST. He also uses a systematic procedure for identifying categories of English-Nadsat items and tracing their translations in LOM. Pochon characterises Belmont and Chabrier’s approach as “more one of ‘translating’ the method of creation of Nadsat rather than the specific items”[9] (Pochon 2010: 98, our emphasis). This chimes with Meteva-Rousseva’s (2018) assessment, whose focus is predominantly on wordplay in ST and in translation.
The one slightly dissenting voice when it comes to the French translation is Malamatidou (2017), whose study, based on a language contact perspective, is not limited to French but examines the translation of Nadsat nouns in translations across several European languages. Malamatidou (2017: 293) is interested in “the interaction of foreign and native linguistic elements, and processes of creative reshaping, as well as the effect that this reshaping might have on the function of Nadsat.” Based on an analysis of the translation of Nadsat nouns in terms of grammatical gender and morphological patterns, she argues that, overall, Belmont and Chabrier relied more than is strictly necessary on the English source text in creating French-Nadsat, with some limitations to its creativity.
1.4. Outstanding issues in analyzing translations of ACO
The fact that studies of the same translation (Malamatidou 2017; Bogic 2009/2017) can come to quite different conclusions regarding aspects such as creativity brings into focus the influence of the analytical approach on the conclusions that can be drawn, as well as leaving open the question of how effective the treatment of French-Nadsat is in LOM. It is important from this perspective to consider the limitations of past studies of Nadsat, whether French or not, and how they might be mitigated.
One area of limitation when it comes to considering translations of English-Nadsat relates to coverage. Most of the studies reviewed above focus predominantly on the treatment of the Russian component of English-Nadsat as the most salient and the largest component of Nadsat. Even where mention is made of other elements such as rhyming slang or compound words (Windle 1995; Corness 2018), this tends to be quite brief. But when translators such as Belmont and Chabrier refer to “oddities of vocabulary” they are not only referring to the use of Russian but to other aspects too.
A further issue that has affected many previous studies is their uncritical acceptance of the accuracy of earlier glossaries, whether the original (Hyman 1963) or those appended to translations, as in LOM.[10] Vincent and Clarke (2017) point out that Hyman’s ignorance of Russian, lack of familiarity with British slang (Hyman was American), and failure to consult appropriate sources (such as the Oxford English Dictionary[11] or A Dictionary of Slang and Unconventional English[12]) resulted in a number of mistakes in his analysis and glossary. As for the French glossary, it seems to have been somewhat carelessly compiled (see Section 3). It appears likely that this carelessness arose from the fact that Belmont and Chabrier agreed with Burgess that a glossary should not be provided. However, studies of Nadsat in translation (such as Pochon 2010; Janak 2015) seem to take it for granted that the glossaries, where provided, are accurate and comprehensive.
Lack of awareness of corpus software and its affordances has also limited some previous work. This type of software can facilitate both comparative work and provide quantitative data, encouraging a more systematic approach. Corness (2018) shows the value of parallel corpus work in investigating different translations of the same item, but, other than Malamatidou (2017), previous work on Nadsat has not availed itself of this technology. This can lead to mistakes of identification. A related issue is the assumption in some studies (see for instance Bogic 2009/2017; Pochon 2010) that an item of English-Nadsat has a straightforward, consistent equivalent in translation. This would appear to be quite a dangerous assumption, bearing in mind the lack of consistency found for example by Corness (2018).
A further affordance of corpus software that has largely been ignored in previous work is the possibility of obtaining frequency and distribution information regarding Nadsat items. Studies that do not have access to this data are limited to statements regarding how many different Nadsat words there are in each category identified. However, it is also important to consider the frequencies and distributions of Nadsat items in the work; a certain category may appear particularly salient, but it may also only occur a few times. In overlooking distributions of Nadsat items across the work, relatively infrequent items or categories may be given undue prominence. It seems more likely that effects are created by pervasive phenomena than by those which are marginal; translators may treat frequently occurring items differently from those that are only found once or twice. If we consider studies of the French translation, Malamatidou (2017) finds that, of the 135 Russian-derived English-Nadsat nouns, 123 have Russian-based equivalents in French-Nadsat. While this is interesting, it does not tell us which nouns have been lost or the overall effect on the frequency of Russian-Nadsat nouns; this may be significant if frequent nouns such as droog are omitted, or negligible if those lost only occur rarely. This difference thus may have a significant or only a minimal impact on the reading of the text.
In summary, previous studies of Nadsat in translation in general have picked out many of its important features. However, they show some limitations, particularly with respect to quantitative findings and the basis upon which the identification of Nadsat is built. Our aim in this paper is to examine the translation of ACO into French through a comparison of English-Nadsat and French-Nadsat. Our choice of this specific translation was motivated not just by the previous generally positive assessment of this translation and by a desire to understand better why this might be, but also by the questions that previous studies have left open, in particular the consistency that Belmont and Chabrier brought to their task with respect to all aspects of Nadsat. A subsidiary aim will also be to show how the use of corpus approaches can bring rigour to the investigation of the translation of key features of a literary work.
2. Analysis of aligned extracts
A brief analysis of comparable extracts from ACO and LOM will allow us to see how Belmont and Chabrier approached the task of recreating Nadsat in the TT. The extract further indicates some of the typical behaviour of the droogs (and hence the typical referents of their anti-language) in its description of violent robberies and muggings. For ease of identification, Nadsat words have been highlighted (this is not done in either ST or TT).
As we can see, this extract includes a high concentration[13] of Nadsat items; in terms of the ST extract, most of these are based on Russian lexis (for example, deng is based on деньги, Russian for money), some with the addition of English inflections (as with smecking). At the same time, it is possible to make an educated guess at what these unfamiliar items refer to (Hyman 1963; Vincent and Clarke 2017); the number of items that pockets can sensibly be full of is somewhat limited.
Comparison of the two extracts shows how the French translators Belmont and Chabrier work to create a corresponding French-Nadsat item for each item identified in the ST extract. However, the number of Russian-derived items in the LOM extract is considerably lower than that in the ACO extract. In the ST extract, only two items are not taken from Russian, the rhyming slang item pretty polly (rhyming with lolly, a slang word meaning ‘money’) and do the ultra-violent. In the TT extract, meanwhile, this number rises to six. It appears that Belmont and Chabrier are able to find satisfactory solutions to non-Russian Nadsat items, with joli lollypop being particularly creative in replicating the rhyming aspect of pretty polly, albeit internally, while suggesting an English derivation (lollypop is not a French word). Based on these extracts, however, they found greater difficulty with the integration of Russian-derived Nadsat words, opting instead to source them from adaptations of French words, much in the way the ST plays with words from English (Hyman 1963; Vincent and Clarke 2017). The translation of deng [money], mouizka, has been created by adapting the French word mouise [poverty] to appear more Russian (Pochon 2010). Viokcha was introduced in Section 1.3 above. Relucher appears to be an adaptation of the French reluquer [to eye up], while se bidonskant (form of the verb se bidonsker) is a creation based on se bidonner [to laugh, to guffaw], to which the addition of sk contributes a Russian flavour.
This brief analysis gives an indication of the creative efforts undertaken by Belmont and Chabrier to conform to Burgess’s vision in a way that translators of ACO into other languages have not always managed. Nevertheless, there is an indication here that the Russian-ness of Nadsat might be slightly diluted in French-Nadsat, and that, while French words are adapted to make them appear more Russian, the defamiliarisation effect for the French reader seems likely to be smaller than for an English reader. What this analysis cannot show is the extent to which Belmont and Chabrier are consistent in their “translations” of Nadsat items across the whole book, or whether this proportion of Russian-derived French-Nadsat words is maintained. These are questions we address in the following sections.
3. Methods: identifying French-Nadsat in L’Orange Mécanique (LOM)
In terms of identifying French-Nadsat, an obvious starting point is the glossary prepared by Belmont and Chabrier. Unfortunately, as noted in Section 1.4, this is not an entirely reliable document. Belmont and Chabrier do not appear to have taken this task very seriously; their translators’ note, indeed, says that it is provided “for the purposes of entertainment rather than clarification”[14] (Belmont and Chabrier 1972: 5). This may explain why the list contains misspellings and omissions: adin [one] is omitted; groudné [breast] is spelled /groundné/. For this reason, the LOM glossary cannot form the basis for a systematic treatment of French-Nadsat.
Another possibility for investigating Nadsat in LOM would be to use a systematically created list of Nadsat items such as the one introduced in Vincent and Clarke (2017) for English-Nadsat. Using the coupled pairs method (Toury 1995; Munday 1998) of tracking the translations of these items by means of parallel corpus software would show us how English-Nadsat items are translated into French; this is indeed the approach taken by Janak (2015), following Çermáková and Fárová (2010). However, this approach does not provide a full picture of French-Nadsat, since it disregards items created by Belmont and Chabrier to compensate for items that were not readily translatable into French. Our approach instead was to treat the TT as a stand-alone text and French-Nadsat as a variety organically existing in this text and contrasting with the target language and culture. It still allows us to make comparisons with English-Nadsat, but in terms which do not necessarily prioritize features of the ST.
The method used for identifying French-Nadsat follows the corpus-based approach used for the identification of Nadsat in the ST (English-Nadsat) outlined in Vincent and Clarke (2017). The first stage of this process was to obtain a computer-readable version of the French text and upload it into the Sketch Engine[15] online corpus interface. A keyword list was then created based on words which occur unusually frequently in LOM compared to a reference corpus chosen to represent French. The corpus chosen in this case (following the methodology in Vincent and Clarke 2017) was the 10-billion-word Fr-ten-ten[16] corpus. The keyword formula used by Sketch Engine uses the “simple maths” procedure (Kilgarriff 2009) which is based on ratios of normalized frequencies between target and reference corpus. It is thus an effect size metric, rather than a level of confidence metric (Gabrielatos 2018), meaning that it focuses more on the size of the difference than its reliability.
The items retrieved by this keyword analysis procedure were then considered as potentially belonging to French-Nadsat. To decide which items might count as Nadsat we took into account a number of questions. The first was whether the item deviates from standard French. To verify this, a very useful source was the extensive online Trésor de la langue française informatisé,[17] a comprehensive dictionary of 19th and 20th century French; although work on this dictionary finished in 1994 and it is no longer updated, this is not a problem for this study since LOM was completed before this date. A native French language specialist also contributed to the process of identifying French terms from less formal registers.
An important part of the procedure was also to check how a candidate word is used in the TT. Certain items appear at first to be strong Nadsat candidates, but turn out not to be. Examples here include items which are not attributed to the speech of the droogs but to some other group in the book or to society in general, for example mondovision; any word which is presented in LOM as part of common usage cannot be French-Nadsat since the items that the droogs use to communicate with one another must exclude outsiders (Fowler 1979; Burgess 1983; Janak 2015). It was also helpful to check whether the item in question had a counterpart in ACO that had also been identified as a Nadsat word. This, we felt, would represent strong evidence that Belmont and Chabrier considered the item to be Nadsat. In checking such items, we used the AntPConc parallel corpus software[18] with aligned versions of the English and French texts. As in ACO, a number of French-Nadsat items are glossed in the book itself, for example tilt [money], which is introduced thus: un malenky peu de tilt (d’argent, autrement dit) (Burgess 1962/1972b: 14), which is the translation of a malenky bit of cutter (money, that is) (Burgess 1962/2012: 13). Such glosses mark an item as belonging to the Nadsat lexicon. In some cases, it was possible to include words on the basis of previous research, as in the case of sammybéa, which is persuasively analysed by Meteva-Rousseva (2018: 352) as a portmanteau of sammy, short for the Good Samaritan, and a rendering of the abbreviation BA (bonne action) applied to scouts when they do a “good deed.”
The final question to ask was whether a keyword that might potentially be French-Nadsat exhibited similar features to other items already identified as Nadsat. As noted already, previous research has focused on categorizing Nadsat on the basis of word derivations and word formation processes. Typically, examples of this kind show word formation processes in French-Nadsat mirroring those found in English-Nadsat; a French word may have letters added or removed to suggest another word while remaining recognizable (an example of this is milichien—see discussion in Section 4).
This procedure allowed us to formulate categories of French-Nadsat along the lines of those already existing for English-Nadsat without necessarily being constrained to categories identified for that variety. It was then possible to use lists of items to conduct searches using AntConc software[19] and determine frequencies of items and categories, and to use AntPConc to check the consistency of translations from ST to TT. Such searches were based on all forms of a lemma; a search for bolchoï [big], which is the French-Nadsat word whose English-Nadsat equivalent is bolshy, for example, included the forms bolchoï, bolchoïe, bolchoïs, bolchoïes[20] to account for all options of the adjectival paradigm in French. Searches for items also had to take account of a number of apparent misspellings in the text, such as /brachtni/ for bratchni [bastard]. Thus, unless otherwise indicated, the words listed in this paper should be treated as dictionary headwords, including all possible forms found (including orthographic variants).
4. Results
4.1. Categories of items in French-Nadsat compared to English-Nadsat
The analysis of Nadsat items yielded a total of 363 French-Nadsat items (types), divided as indicated in Table 1 into six categories. This figure is very close to the that of 356 English-Nadsat items found in ACO using a comparable methodology (Vincent and Clarke 2017). The slightly higher number for French is partly due to the fact that French, unlike English, makes a formal distinction between nouns and verbs; for example, govoreet [talk] in English-Nadsat can be both a talk and to talk, but in French-Nadsat the noun is govoritt and the verb is govoriter. The similarity between the size of the French-Nadsat lexicon and that of English-Nadsat testifies to Belmont and Chabrier’s commitment to realizing Burgess’s linguistic vision. This finding contrasts with Janak (2015), who provides evidence from Czech and German translations of ACO that non-“Core” Nadsat items may be ignored by translators.
We identify six categories of French-Nadsat, as shown in Table 1. An initial point of comparison is between the categories of French-Nadsat and those identified for English-Nadsat in ACO (Vincent and Clarke 2017), which are shown in Table 2. This comparison shows that English-Nadsat has two categories which are not found in French-Nadsat, “Archaisms” and “Rhyming Slang,” while French-Nadsat has “Anglicisms” (the introduction of words based on English lexis, which, naturally, is not a separate category from “Creative Morphology” in English-Nadsat). The overall similarities indicate the effort Belmont and Chabrier made to replicate Nadsat in French. The omission of “Rhyming Slang” (see discussion of pretty polly and joli lollypop in Section 2) is understandable bearing in mind the difficulties of translating both rhyme and meaning and given that it plays quite a minor part in ACO. Nevertheless, the avoidance of archaic forms[21] seems a more significant choice, bearing in mind its contribution to Nadsat and to ACO.
Table 1
Categories of French-Nadsat identified in LOM with type counts

* Figure in LOM glossary
Bearing in mind our earlier comments about the apparent lack of interest shown by Belmont and Chabrier in their glossary, it is also interesting to break down the items listed there according to our categories. The figures in parentheses in Table 1 indicate our categorization as applied to the items in the LOM glossary (we noted 3 errors, not included in the totals above). It is noticeable that in each case we have identified more French-Nadsat items than those listed by Belmont and Chabrier.
Table 2
Categories of English-Nadsat identified in ACO with numbers of types (Vincent and Clarke 2017)[22]
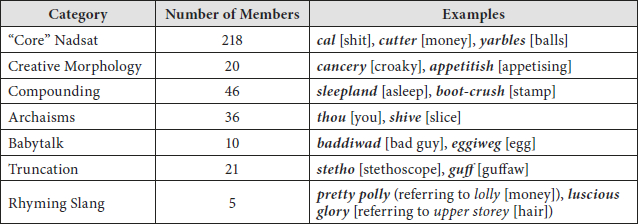
The “Core Nadsat” category of French-Nadsat is predominantly composed of Russian-derived words, such as those introduced in the extract in Section 2. Included are 6 items of indeterminate etymology; these functionally fit into the category since they are not immediately comprehensible to a French reader. An example is tilt, which is used to mean ‘cash’ or ‘money’; while this word exists in French, there is nothing to suggest a connection with the standard meanings of this word. In line with the “Core” Nadsat category for English-Nadsat (Vincent and Clarke 2017), this category includes any words which can be associated with Russian lexis, even where French wordplay may be involved. An example is gloupide, which is a portmanteau of Russian глупый (glupyi) [stupid] and French stupide (Meteva-Rousseva 2018). As in ACO, this category holds the majority of Nadsat types, although the proportion of overall French-Nadsat words is slightly reduced compared to English-Nadsat. This is due to the decision to not always use Russian roots to create French-Nadsat words but to source words from French and adapt them, boosting the number of items in the “Creative Morphology” category (discussed below).
Almost all the words in this “Core” category have counterparts in the “Core” Nadsat items in English-Nadsat. Although the numbers of Nadsat types listed seem quite close in the two varieties, the French-Nadsat figure is inflated due to the difference noted above between English and French morphology.
The second largest category of French-Nadsat in terms of numbers of members is what we have termed “Creative Morphology.” In parallel with the homonymous category of English-Nadsat, which adapts English words, these are words which are based on French lexis but have been altered in some way; sometimes this adaptation suggests a secondary meaning, echoing the strategy employed in ACO with respect to English-Nadsat. A good example of this strategy applied to French-Nadsat is the word milichien [member of militia/police], which is an adaptation from the French word milicien; adding the h refers to chien [dog], thereby indicating the droogs’ antipathy towards authority figures. The greater number of members in French-Nadsat than in English-Nadsat can be attributed to two main sources. The first of these is a number of “Core” items in English-Nadsat that the translators decided to adapt from French words instead. Some examples are shown in Section 2, where we saw that relucher is a consistent translation of the “Core” English-Nadsat viddy [to see], one of the most frequent Nadsat words in ACO.
A major source of members in this category is the creation of new French-Nadsat items (that is, ones whose equivalents in the ST are not Nadsat) such as ricanocher [to grin, to sneer), which is an adaptation of the standard French verb ricaner. Although these inventions mostly occur infrequently in the text, the number of items (around 50% of the words in this category) suggests an attempt by Belmont and Chabrier to compensate for the reduction in the number of Russian-derived words in LOM with what are more recognizable items.
The third largest category of French-Nadsat words uses compounding to create new words. As the difference in the numbers of members indicates, not all compounds in English-Nadsat are replicated in French-Nadsat. At the same time, just under half of the French-Nadsat category are inventions by Belmont and Chabrier for LOM, again indicating a use of compensation to offset the loss of “Core” Nadsat items. Some of these are good examples of the way the translators try to match the black humour of the original; croulebarbe is a combination of crouler [to croak, to die] and barbe [beard] to make a word which translates the ST old age.
The next category, “Anglicisms,” is the only category of French-Nadsat which is not found in English-Nadsat. Such items appear to nod to the original language of the source text and include English words such as drink, with French morphology where necessary. In the case of drinker, this word is consistently used as a translation of peet, based on the Russian word питъ (pit’) [drink]. This category is more mixed than the others in terms of the categories of counterpart items in the ST, most of which are not counted as Nadsat items by Vincent and Clarke (2017). Thus, they appear to have been created in compensation for the loss of some “Core” Nadsat items; examples include dropper and swouisher.
The category of “Babytalk” in English-Nadsat contains creations such as jammiwam which involve reduplication of an initial syllable. A similar process is used in LOM to create items such as conficonfiotte (translating jammiwam), from the first two syllables of the French word confiture, and neuneuf/neunoeuf (translating eggiweg) from French oeuf [egg]. This category has a similar number of members in English-Nadsat and French-Nadsat. Half of these are translated from English-Nadsat counterparts, such as those just mentioned, while others may be found as “Core” items in the ST (tatasse is the translation of tass [cup], truncations (cucubicule translates cubie) or new inventions (siro-siroter translates sipped and sipped). As in English-Nadsat, these items appear to reflect Alex’s youth and immaturity.
The final and smallest category involves the truncation of French words. This creates a small number of items such as alc, short for alcool [alcohol], as well as pé and ème, the words Alex uses to refer to and address his parents (pee and em in the ST).
4.2 Distributions of Nadsat items in ST and TT
The description of the categories of French-Nadsat and their members in Section 4.1 shows the results of Belmont and Chabrier’s source-oriented strategy in terms of categories and numbers of words in each one. What the description does not show, however, is overall frequencies and distributions of Nadsat in LOM. This sort of information is important in terms of the potential impact of translator choices on the reader and also in terms of how it can help us understand how consistent these choices were.
Figure 1
Frequencies of categories of English-Nadsat in ACO (normalised per 10,000 words) (Vincent and Clarke 2017)
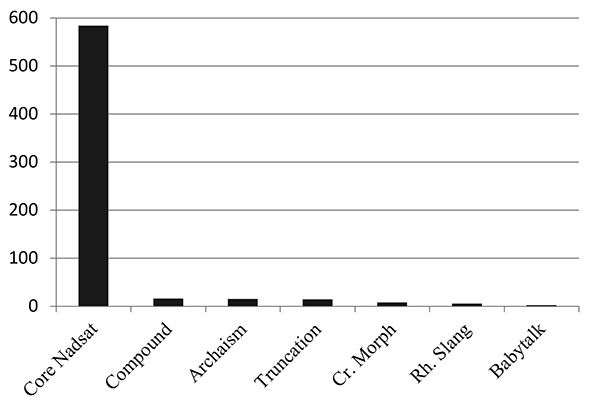
Figure 1 shows overall distributions of items in each category in the ST based on Vincent and Clarke (2017), showing how the “Core” Nadsat category dwarfs the other categories in terms of frequencies in the book. This gives an indication of the importance of “Core” Nadsat to the overall effect of the book, but also of the extent to which the book creates challenges to readers; research has indicated that readers need to understand 95-98% of the running text (Saragi, Nation, et al. 1978) or reading comprehension is significantly hampered.
If we compare distributions of items in ACO with those in the French translation (see Figure 2), we can see that “Core” Nadsat items still predominate, but to a less dramatic extent than in English-Nadsat. The effect will therefore be to make the text seem somewhat easier to read for French readers than for English, since non-“Core” items tend not to be completely foreign, but are associable with existing items in standard French. There are of course dangers in comparing frequencies across translations (Munday 1998), particularly if we bear in mind observations by Polizzotti (2018) that texts in French typically contain more words than their translations (LOM contains 73,376 words compared to the 59,747 in ACO). We would thus not wish to overstate the importance of comparisons of normalised frequencies. Nevertheless, the relative increase of the “Creative Morphology” category is clearly shown and is not unexpected based on our observations in Section 2 and Section 4.1.
Figure 2
Frequencies of categories of French-Nadsat in LOM normalised per 10,000 words

It is interesting to consider which items contribute most to the differences observed between English-Nadsat and French-Nadsat, particularly since these differences are largely attributable to a relatively small set of words. The most obvious change from English-Nadsat to French-Nadsat is in the “Creative Morphology” category. This decision has a large impact because a number of the items here are relatively frequent in the ST: the seven most frequent items in the category are words which in the ST appear as “Core” Nadsat items. These items include three items that we have already seen in the extract analysed in Section 2, relucher, viokcho, and se bidonsker; the various forms of these three words account for more than half of all instances of “Creative Morphology” words. There are various aspects that these items typically have in common: the “Core” English-Nadsat item they are based on is awkward to render in French; an extra layer of wordplay may be involved (for example milichien, discussed above). The procedures used to create these items are thus in line with those used for the creation of Nadsat items in the ST (Pochon 2010).
4.3 Further investigations into consistency of translation
The approach taken in this study also allowed us to compare distributions of Nadsat items across chapters in ST and TT. The results provide an overall impression of how consistently Belmont and Chabrier approached their task and thus of the extent to which their claim to have followed Burgess’s original aims is realized. The distributions of “Core” Nadsat and other Nadsat categories by chapter for ST and TT are shown in Figures 3 and 4.
Figure 3
Distribution of “Core” Nadsat (dark grey) and other Nadsat (light grey) by chapter in ACO

What is striking about these distributions is how they indicate a high degree of similarity in terms of overall variation in frequency of Nadsat by chapter, suggesting that strategies for translation of Nadsat are very consistent across the TT. This similarity is all the more remarkable when we consider that previous work (Windle 1995; Ginter 2003; Janak 2015; Corness 2018) has typically noted translations to be rather inconsistent, inasmuch as these studies have taken this approach; in fact, only Janak (2015) has attempted this on a large scale, focusing solely on “Core” Nadsat. But the similarity of distributions is also surprising when we consider the pressure of normalization typically exerted on translations, which wears away at idiosyncratic linguistic features such as Nadsat, as evidenced by Malamatidou (2017).
While indicative of consistency, Figures 3 and 4 can only give an overall impression of the results of Belmont and Chabrier’s source-oriented translation strategy. This does not tell us whether, or to what extent, the lexical distinctions set up in English-Nadsat are replicated in French-Nadsat. To this end we investigate here a lexical set of some importance to the droogs, Nadsat (and non-Nadsat) terms for money (see Tables 3 and 4).
Figure 4
Distribution of “Core” Nadsat (dark grey) and other Nadsat (light grey) by chapter in LOM

As well as the standard English money, ACO contains three items that refer to money, two of which, pretty polly (“Rhyming Slang”) and deng (“Core” Nadsat) have already been seen above, while the third, cutter, is archaic slang. While money itself has a number of different translations, these three items are almost invariably translated using the same distinct 3 terms in the TT. The only exceptions are two instances of deng, which is also translated as picaille (French slang meaning ‘a coin’) and tilt (“Core” Nadsat, unknown etymology).
Table 3
Lexical items related to money in ACO and their translation equivalents in LOM

If we consider Table 4, it is noticeable that the instances captured in Table 3 are the only times that these items appear in the TT, even though Belmont and Chabrier could have used them more widely. Here we can see a further extra item, tiltot, apparently derived from tilt, which occurs just once in the TT. This analysis provides further evidence of the care taken here by the translators to maintain distinctions between lexical items used in the ST.
Table 4
Lexical items related to money in LOM and their translation equivalents in ACO

This analysis of items relating to money complements the earlier analysis. It cannot prove that Belmont and Chabrier were always consistent, but we can note here that other items checked have shown a similarly high level of consistency and attention to detail. We surmise that this high level of translation consistency would be difficult to achieve without the use of translation aids, such as a list of ST terms and their TT translations, to refer back to during the actual translation process. If preparation notes for the translation of LOM emerge from the archive of Georges Belmont, it may be possible to test this hypothesis in the future.
It is worth noting that the expansion of a domestically-sourced element of French-Nadsat functions somewhat in contradiction to Burgess’s stated concern, when creating the English version of Nadsat, that using current slang “might have a lavender smell by the time the manuscript got to the printers” (Burgess 1990: 27). Additionally, the introduction of an English-based lexical component to Nadsat may have had unforeseen ramifications based on the expansion of English use since Belmont and Chabrier published their translation. Increasing incursion of English lexis into contemporary French has likely eroded the alienating qualities originally intended by the translators.
5. Conclusion
This paper has investigated the French translation of ACO with reference to the invented anti-language Nadsat. In doing so we have sought to overcome some of the weaknesses of previous research into the translation of this work and translations of Nadsat more generally, by exploiting the functionality of freely available corpus software. This has allowed us to go beyond the typical focus on comparisons in terms of numbers and categories of Nadsat types to investigate token distributions across the work. By utilizing a mixed quantitative and qualitative approach, we have been able to evaluate Belmont and Chabrier’s claims of respecting Burgess’s vision for Nadsat in terms of consistency of approach. We have seen the evidence of a systematic approach to the creation of French-Nadsat that brought a high level of consistency to the translation.
Clearly, our approach and discussion does not allow us to definitively pronounce on the fidelity of the TT to the ST. However, the ability to identify, isolate, and compare ST and TT Nadsat varieties using corpus methods and ascertain type distributions allows us to speculate more comprehensively about Belmont and Chabrier’s translation strategies and achievements. It is clear that they sought to emulate not merely the alienating effect of the invented lexis of Nadsat, but also its lexical construction procedures and reliance on wordplay. In doing so, they did not limit themselves to copying Burgess’s invention of Nadsat, but attempted to replicate its in-text role as anti-language, using compensation strategies involving the creation of new items, including Anglicisms. We can concur with most previous work on this translation that, from this perspective, this is quite a successful translation, but two limitations emerge from this analysis. The first of these is the omission of an analogous component to the archaisms seen in English-Nadsat, which is surprising, given that it is a distinctive component of the source text. The second is the decrease in the proportion of Russian lexis included in French-Nadsat. As noted earlier, one possible effect of this approach is that the translation may date more quickly. Another is that there is a slight reduction in the challenge to readers of deciphering Nadsat when compared to the ST. Nevertheless French-Nadsat remains a significant achievement.
A further aim in undertaking this study has been to point out the affordances of corpus tools and the uses they can be put to in investigating translation strategies, particularly when it comes to creative use of language. We have seen the usefulness of the key word methodology as an initial step in retrieving creative lexis and the importance of considering each version in its own right. This study also reveals the importance of examining the distributions of items of interest when examining translations of texts which in the original rely on atypical features such as Nadsat and the value of this in tracking distributions across chapters of a work. This method could usefully be adapted to examining translations of texts which feature a large lexis of slang, or notably deviate from standard language use in other ways. Such linguistic features are particularly interesting when considering translation strategies and the consistency with which translators abide by them.
Appendices
Appendices
Appendix 1. References to Burgess’s works (originals and translations)
Burgess, Anthony (1962): A Clockwork Orange. London: William Heinemann.
Burgess, Anthony (1963): A Clockwork Orange. New York: Norton.
Burgess, Anthony (1990): You’ve Had Your Time: Being the Second Part of the Confessions of Anthony Burgess. London: Heinemann.
Burgess, Anthony (1962/1972a): Arancia meccanica [The mechanical orange]. (Translated from English by Floriana Bossi) Turin: Einaudi
Burgess, Anthony (1962/1972b): L’Orange mécanique. (Translated from English by Georges Belmont and Hortense Chabrier) Paris: Robert Laffont.
Burgess, Anthony (17 July 1983): “Codes of Youth.” Review of The Language of the Teenage Revolution by Kenneth Hudson [1983, London/New York: Palgrave Macmillan]. The Observer. p. 26.
Burgess, Anthony (1962/1991a): Zavodnoi apel’sin [A clockwork orange]. (Translated from English by Evgenii Sinel’shchikov) Юность [Youth]. 3-4.
Burgess, Anthony (1962/1991b): Zavodnoi apel’sin [A clockwork orange]. (Translated from English by Vladimir Boshniak) Leningrad: Khudozhestvannaia literatura.
Burgess, Anthony (1962/1999): Mechaniczna pomarańcza [A mechanical orange]. (Translated from English by Robert Stiller) Krakow: Etiuda.
Burgess, Anthony (1962/2001): Nakręcana pomarańcza [A wind-up orange]. (Translated from English by Robert Stiller) Krakow: Etiuda.
Burgess, Anthony (1962/2012): A Clockwork Orange: The Restored Edition. (Edited by Andrew Biswell) London: Penguin Books.
Appendix 2. References to paratextual materials (originals and translations)
Belmont, Georges and Chabrier, Hortense (1972): Note des traducteurs. In: Anthony Burgess. L’Orange mécanique. (Translated from English by Georges Belmont and Hortense Chabrier) Paris: Robert Laffont, 5.
Biswell, Andrew (2012): Nadsat glossary. In: Anthony Burgess. A Clockwork Orange: The Restored Edition. London: Penguin Books, 215-218.
Hyman, Stanley Edgar (1963): Afterword. In: Anthony Burgess. A Clockwork Orange. New York: Norton.
Acknowledgements
We would like to acknowledge the support and collegiality of our colleagues on the Ponying the Slovos research team, particularly Dr. Niall Curry and Dr. Patrick Corness. We also wish to thank Mr. Laurent Binet for his assistance in demystifying French slang terms, and to acknowledge the expert translation help received from Dr. Leimar Garcia-Siino, Dr. Alistair Rolls, and Mr. Yves Buelens. This research was partly based on archival work at the archives of the International Anthony Burgess Foundation in Manchester. The authors wish to thank the Foundation, its archivist, Ms. Anna Edwards, and its director, Prof. Andrew Biswell for their hospitality and assistance. This research arises out of work funded by a seed corn research grant from Coventry University.
Notes
-
[1]
See Appendix for references to Burgess’s works.
-
[2]
A Clockwork Orange (1971): Directed by Kubrick, Stanley. Polaris Productions. United Kingdom/United States.
-
[3]
There is no consensus on how these are to be treated in the literature, but they are included as central Nadsat words by Biswell (2012: 216), the editor of the restored edition of ACO (Burgess 1962/2012), and also by Vincent and Clarke (2017) on the grounds that, like Russian words, they are not immediately comprehensible to English readers.
-
[4]
Buelens, Yves (16 June 2019): personal communication, instant messaging.
-
[5]
Our translation of “certaines curiosités du vocabulaire” in the translators’ note.
-
[6]
Pochon (2010), who comes at the translation from a perspective based on the work of Berman (1995), takes Belmont and Chabrier to task for the addition of this note, believing that it spoils the element of surprise that Nadsat should bring to the reader. However, this ignores the possibility that many readers will not read the translators’ note and that many editions of the ST include similar comments on the features of Nadsat in their introductions.
-
[7]
This is the feminine singular form. Other forms are viokcho, viokchos, and viokchas. This discounts apparent misspellings; these are a minor but interesting feature of both ST and TT. Burgess’s justification for different spellings of certain items was that Nadsat was really a spoken language (Burgess 1983).
-
[8]
Information relating to French terms relies on that provided in the Trésor de la langue française informatisé (see endnote 17).
-
[9]
This is our translation of “l’une des caractéristiques de la traduction de la création lexicale est davantage la ‘traduction’ de la méthode de création que la traduction lexicale à proprement parler.”
-
[10]
In fact, studies (Bogic 2009/2017; Pochon 2010. among others) may not even refer to Hyman, perhaps because his glossary is appended to editions without an acknowledgement of the source. The reliance on this glossary, however, can be inferred by the replication of its mistakes in these studies.
-
[11]
Oxford English Dictionary (2000- ): 3rd ed. Oxford: Oxford University Press. Consulted on 6 March 2020, <https://www.oed.com/>.
-
[12]
Partridge, Eric (1937): A Dictionary of Slang and Unconventional English. London/New York: Routledge.
-
[13]
Vincent and Clarke (2017) find that the concentration of Nadsat in this extract is around double that found in the rest of the work, which may explain the choice of the extract by Bogic (2009/2017), Maher (2010), Ginter (2003), and Janak (2015).
-
[14]
Our translation of “pour amuser plutôt que pour éclairer” in the translators’ note.
-
[15]
Kilgarriff, Adam, Baisa, Vít, and Bušta, Jan (2014): The Sketch Engine: ten years on. Lexicography. 1(1):7-36.
-
[16]
Jakubíček, Miloš, Kilgarriff, Adam, Kovář, Vojtěch, et al. (2013): The TenTen Corpus Family. In: Andrew Hardie and Robbie Love, ed. Corpus Linguistics 2013: Abstract Book. (CL2013: Seventh International Corpus Linguistics Conference, Lancaster, 22-26 July 2013). Lancaster: University Centre for Computer Corpus Research on Language (UCREL), University of Lancaster, 125-127.
-
[17]
Analyse et traitement informatique de la langue française (ATILF) (2002): Trésor de la langue française informatisé. Nancy: CNRS/Université de Lorraine. Consulted on 6 February 2020, <http://atilf.atilf.fr>.
-
[18]
Anthony, Laurence (20 December 2017): AntPConc. Version 1.2.1. Tokyo: Waseda University.
-
[19]
Anthony, Laurence (22 March 2018): AntConc. Version 3.5.4. Tokyo: Waseda University.
-
[20]
It is interesting to note that the English-Nadsat bolshy has connotations of anti-social behaviour that are entirely lacking in the French-Nadsat bolchoï, which is a straightforward transliteration from Russian with no such connotations.
-
[21]
Our reviewer points out that there is an attempt at archaism in the use of vocative Ô, for example in Ô mes frères, an expression that occurs repeatedly in LOM (Burgess 1962/1972b). This form is also found in the ST, but this is the only element of archaism in LOM.
-
[22]
The full lists are provided in Vincent, Benet and Clarke, Jim (20 April 2017): Breaking down Nadsat into Categories. Ponying the Slovos. Consulted on 6 February 2020, <http://ponyingtheslovos.coventry.domains/uncategorized/breaking-down-nadsat-into-categories/>.
Bibliography
- Berman, Antoine (1995): Pour une critique des traductions: John Donne. Paris: Gallimard.
- Bogic, Anna (2009/2017): Anthony Burgess in French Translation: Still ‘as Queer as a Clockwork Orange.’ In: Marc Jeannin, ed. Anthony Burgess and France. Newcastle upon Tyne: Cambridge Scholars Publishing, 215-228.
- Corness, Patrick (2018): A Clockwork Orange in Polish: Robert Stiller’s dystopias. In: Justyna Czaja, Irina Jermaszowa, Monika Wójciak, et al., eds. Słowiańska Wieża Babel Tom II: Język i tożsamość [Slavic Tower of Babel volume II: Language and identity]. Warsaw: Filologia Słowiańska.
- Çermáková, Anna and Fárová, Lenka (2010): Keywords in Harry Potter and their Czech and Finnish Translation Equivalents. In: Frantişek Çermák, Aleş Klegr, and Patrick Corness, eds. InterCorp: Exploring a Multilingual Corpus. Prague: Nakladatelstvi Lidove noviny, 177-188.
- Eco, Umberto (2003): Mouse or Rat? Translation as Negotiation. London: Weidenfeld and Nicholson.
- Fowler, Roger (1979): Anti-language in fiction. Style. 13(3):259-278.
- Gabrielatos, Costas (2018): Keyness analysis: nature, metrics and techniques. In: Charlotte Taylor and Anna Marchi, eds. Corpus Approaches to Discourse: A critical review. London/New York: Routledge, 225-258.
- Ginter, Anna (2003): Slang as the Third Language in the Process of Translation: A Clockwork Orange in Polish and Russian. Стил [Style]. 2:295-306.
- Halliday, Michael A. K. (1976): Anti-languages. American Anthropologist. 78(3):570-584.
- Janak, Petr (2015): Multilingualism in A Clockwork Orange and its translations. Master’s thesis, unpublished. Prague: Univerzita Karlova.
- Kilgarriff, Adam (2009): Simple maths for keywords. In: Michaela Mahlberg, Victorina González-Díaz, and Catherine Smith, eds. Proceedings of the Corpus Linguistics Conference CL2009. (CL2009: Corpus Linguistics Conference, Liverpool, 20-23 July 2009). Consulted on 20 June 2019, http://ucrel.lancs.ac.uk/publications/cl2009/.
- Lefevere, André (1992): Translation, Rewriting, and the Manipulation of Literary Fame. London/New York: Routledge.
- Maher, Brigid (2010): Attitude and intervention: A Clockwork Orange and Arancia meccanica. New Voices in Translation Studies. 6:36-51.
- Maher, Brigid (2011): Recreation and Style: Translating Humorous Literature in Italian and English. Amsterdam/Philadelphia: John Benjamins.
- Malamatidou, Sofia (2017): Creativity in translation through the lens of contact linguistics: A multilingual corpus of A Clockwork Orange. The Translator. 23(3):292-309.
- Mäkelä, Oskari (2015): Constructed fictional language in translation: Conveying Nadsat from A Clockwork Orange to Kellopeliappelsiini. Master’s thesis, unpublished. Vaasa: Vaasan yliopisto.
- Meteva-Rousseva, Elena (2018): Les jeux de mots dans le nadsat d’Anthony Burgess – comment ses traducteurs français ont relevé le défi. In: Esme Winter-Froemel and Alex Demeulenaere, eds. Jeux de mots, textes et contextes. Berlin/Boston: De Gruyter, 339-362.
- Munday, Jeremy (1998): A Computer-assisted Approach to the Analysis of Translation Shifts. Meta. 43(4):542-556.
- Munday, Jeremy (2001/2013): Introducing Translation Studies. 3rd ed. London/New York: Routledge.
- Pochon, Jean (2010): Analyse de la traduction française de L’Orange mécanique: comment traduire la création lexicale? Master’s thesis, unpublished. Geneva: Université de Genève.
- Polizzotti, Mark (2018): Sympathy for the Traitor: A Translation Manifesto. Cambridge: MIT Press.
- Saragi, Thomas, Nation, Paul, and Meister, George (1978): Vocabulary learning and reading. System. 6(2):72-78.
- Shklovsky, Viktor (1917/1965): Art as Technique. In: Lee Lemon and Marion Reis, eds. Russian Formalist Criticism: Four Essays. Lincoln: University of Nebraska Press, 3-24.
- Toury, Gideon (1995): Descriptive Translation Studies and Beyond. Amsterdam/Philadelphia: John Benjamins.
- Vincent, Benet and Clarke, Jim (2017): The language of A Clockwork Orange: A corpus stylistic approach to Nadsat. Language and Literature. 26(3):247-264.
- Windle, Kevin (1995): Two Russian Translations of A Clockwork Orange, or the Homecoming of Nadsat. Canadian Slavonic Papers/Revue Canadienne des Slavistes. 37(1/2):163-185.
 10.7202/003680ar
10.7202/003680arList of figures
Figure 1
Frequencies of categories of English-Nadsat in ACO (normalised per 10,000 words) (Vincent and Clarke 2017)
Figure 2
Frequencies of categories of French-Nadsat in LOM normalised per 10,000 words
Figure 3
Distribution of “Core” Nadsat (dark grey) and other Nadsat (light grey) by chapter in ACO
Figure 4
Distribution of “Core” Nadsat (dark grey) and other Nadsat (light grey) by chapter in LOM
List of tables
Table 1
Categories of French-Nadsat identified in LOM with type counts
* Figure in LOM glossary
Table 2
Categories of English-Nadsat identified in ACO with numbers of types (Vincent and Clarke 2017)[22]
Table 3
Lexical items related to money in ACO and their translation equivalents in LOM
Table 4
Lexical items related to money in LOM and their translation equivalents in ACO