Abstracts
Résumé
C’est au milieu des années 1980 que sont apparues les premières études expérimentales visant à explorer les processus psycholinguistiques à la base de l’opération de traduction. Partant d’un corpus de données, ces études ont examiné pour la première fois ce qui se passe dans la tête des traducteurs au cours de cette opération mentale particulièrement complexe. Depuis la « psycho-traductologie » s’est établie en tant que nouveau domaine de recherche spécialisé au sein de la traductologie générale. Le présent article se propose de déterminer l’objet et les principales méthodes de ce domaine de recherche en examinant quatre questions : (1) Quels sont les points de départ et les approches caractéristiques de ce domaine de recherche ? (2) Quelles sont les questions auxquelles la psycho-traductologie veut trouver des réponses ? (3) Avec quelles méthodes peut-on collecter des données pertinentes à ces questions ? (4) Avec quelles méthodes peut-on analyser et interpréter les données collectées ?
Mots-clés:
- processus de traduction,
- psycho-traductologie,
- psycholinguistique,
- méthode,
- étude expérimentale
Abstract
About 20 years ago the first empirical studies on the psycholinguistic structure of translation processes appeared. Based on data corpora, these studies investigated for the first time what goes on in the mind of translators while translating. Since then, process-oriented research in translation has developed into a research branch of its own within general translatology. The present article attempts to outline the fundamentals of this new branch of research by discussing four basic questions: (1) What are the characteristic features of process-oriented research in translation? (2) Which research questions is it designed to answer? (3) What methods are appropriate for collecting data relevant to the translation process? (4) What methods are appropriate for the systematic analysis and interpretation of the data collected?
Keywords:
- translation process,
- psycholinguistics,
- method,
- empirical study
Article body
1. Einleitung
Obwohl die Übersetzungswissenschaft mindestens 50 Jahre alt ist obwohl es eine fünfstellige Zahl von Publikationen zum Übersetzen gibt, wie die einschlägigen Bibliographien beweisen, ist die Frage, was beim Übersetzen tatsächlich in den Köpfen der Übersetzer vorgeht, erst relativ spät wissenschaftlich untersucht worden. Wenn in der Übersetzungswissenschaft der “Übersetzungsprozess” beschrieben wird, so handelt es sich auch heute noch oft um theoretische Modellierungen aus linguistischer, semiotischer, kommunikationstheoretischer, text- oder auch literaturwissenschaftlicher Sicht, nicht aber um den Versuch, konkrete Übersetzungsereignisse empirisch zu beschreiben (vgl. Lörscher 1989). Konkrete Übersetzungsprozesse beschreiben heißt eine Antwort auf die Frage suchen: Wie und warum gelangt ein bestimmter Übersetzer zu einem bestimmten Zeitpunkt unter bestimmten situativen Bedingungen bei der Übersetzung eines bestimmten Ausgangstextes zu einem bestimmten Übersetzungsresultat?
Rückblickend betrachtet, scheint der Hauptgrund für die Vernachlässigung dieser psycholinguistischen Dimension des Übersetzers darin bestanden zu haben, dass man nicht wusste, mit welchen wissenschaftlich akzeptierten Methoden man diesen Prozess untersuchen sollte. Erst als Mitte der 80er Jahre drei Wissenschaftler unabhängig voneinander die Idee hatten, Übersetzungsprozesse mit dem Verfahren des Lauten Denkens zu untersuchen (Gerloff 1988, Krings 1986, Lörscher 1991) und diese Idee in kurzer Zeit von zahlreichen anderen Forschern aufgegriffen wurde, war der Startschuss für die Entwicklung einer neuen Forschungsrichtung innerhalb der Übersetzungswissenschaft gefallen.
Heute, rund 20 Jahre später, hat sich die Übersetzungsprozessforschung als kleines, aber aktives Forschungsgebiet etabliert. Zu zahlreichen Einzelfragestellungen wurden interessante Ergebnisse erzielt. Wir wissen heute sehr viel mehr über typische Prozesse von Lernern, semiprofessionellen und professionellen Übersetzern als vor 20 Jahren. Dass die Zeitschrift Meta dieser Thematik ihr Jubiläumsheft widmet, ist ein Zeichen dafür, dass diese Forschungsrichtung heute anerkannt ist und als wichtig angesehen wird. Dennoch zeigt sich, dass viele Fragen noch unbeantwortet sind.
Je mehr Studien in einem Forschungsgebiet erscheinen, desto wichtiger wird es, von Zeit zu Zeit eine Standortbestimmng vorzunehmen. In diesem Beitrag möchte ich dies versuchen, allerdings nicht mit Blick auf die Ergebnisse der Übersetzungsprozessforschung. Dies wäre auf diesen wenigen Seiten kaum möglich. (Ich habe dies auch an anderer Stelle getan, s. Krings 2001, S.66-165; für die Forschung der letzten Jahre siehe auch die Beiträge in diesem Heft und die Arbeiten, auf die in diesen verwiesen wird). Ich möchte vielmehr versuchen, eine grundsätzliche Standortbestimmung der Übersetzungsprozessforschung vornehmen. Dazu gehe ich auf folgende Fragen ein:
Was sind die grundlegenden Merkmale von Übersetzungsprozessforschung?
Welche Fragen will die Übersetzungsprozessforschung beantworten?
Mit welchen Methoden kann man relevante Daten zu Übersetzungsprozessen erheben?
-
Mit welchen Methoden kann man die erhobenen Daten systematisch analysieren?
Beginnen wir aber mit einer kurzen Charakterisierung der Übersetzungsprozessforschung und ihres Selbstverständnisses.
2. Was ist Übersetzungsprozessforschung?
Zu Beginn der Übersetzungsforschung ist nicht selten gefragt worden, wozu eine so detaillierte Untersuchung der Übersetzungsprozesse, wie sie in dieser neuen Forschungsrichtung angestrebt wird, denn überhaupt nützlich sei. Schließlich käme es letztlich doch nur auf die Ergebnisse des Übersetzungsprozesses und deren Qualität und nicht auf die verschlungenen Wege an, die den einzelnen Übersetzer zu diesen Ergebnissen führen. Auch wenn diese Frage heute nur noch selten gestellt wird, kann es nicht schaden, sich noch einmal klar zu machen, welche grundsätzlichen Begründungen für die Übersetzungsprozessforschung ins Feld geführt werden können. Sie können meiner Meinung nach in drei Hauptbegründungen zusammengefasst werden:
-
Die wissenschaftlich-systematische Begründung:
Die Übersetzungsprozessforschung schließt eine Lücke im Erkenntnisprozess über menschliche Sprachverarbeitungsprozesse und leistet damit einen Beitrag zum allgemeinen Ziel von Wissenschaften, ihren Gegenstandsbereich möglichst vollständig und systematisch zu beschreiben und zu erklären.
-
Die angewandt-übersetzungsdidaktische Begründung
Die Übersetzungsprozessforschung liefert wichtige Orientierungsmarken für ein effektives Lehren und Lernen von Übersetzungskompetenz.
-
Die standespolitische Begründung
Die Übersetzungsprozessforschung trägt dazu bei, die Komplexität des Übersetzens und damit die Notwendigkeit von Professionalität in Ausbildung und Berufspraxis nachzuweisen.
Neben diesen allgemeinen Begründungen lässt sich die Übersetzungsprozessforschung des weiteren durch eine Reihe von Grundpositionen charakterisieren, die sich als konstitutiv für ihr Selbstverständnis herausgebildet haben und die sie in ihrer Gesamtheit von allen anderen Forschungsrichtungen innerhalb der Übersetzungswissenschaft unterscheiden. Es sind dies vor allem die folgenden: Die Übersetzungsprozessforschung
untersucht alle am Übersetzungsprozess beteiligten kognitiven Prozesse
erweitert dadurch den Gegenstandsbereich der traditionellen Übersetzungswissenschaft
ist deskriptiv, nicht normativ
geht empirisch-induktiv statt theoretisch-deduktiv vor
strebt als Ziel ein differenziertes Modell des Übersetzungsprozesses und seiner Einflussvariablen an.
3. Fragestellungen der Übersetzungsprozessforschung
Eingangs war bereits gesagt worden, dass die Übersetzungsprozessforschung untersucht, wie und warum ein bestimmter Übersetzer zu einem bestimmten Zeitpunkt unter bestimmten situativen Bedingungen bei der Übersetzung eines bestimmten Ausgangstextes zu einem bestimmten Übersetzungsresultat gelangt. Doch es liegt auf der Hand, dass die Übersetzungsprozessforschung diese Frage nicht für jedes einzelne Übersetzungsereignis empirisch untersuchen kann. Sie kann vielmehr (wie jede empirische Forschung) nur einen verschwindend geringen Teil von realen Ereignissen empirisch untersuchen und muss versuchen, in den untersuchten Ereignissen wiederkehrende Elemente, allgemeine Strukturen, Regelmäßigkeiten oder gar Gesetzmäßigkeiten zu entdecken. Oder anders formuliert: sie muss sich um die Verallgemeinerbarkeit ihrer empirisch gewonnenen Beobachtungen bemühen.
Um dem Rechnung zu tragen, muss die Übersetzungsprozessforschung zweierlei tun: Zum einen muss sie möglichst viele Parameter zur Beschreibung von einzelnen Übersetzungsprozessen entwickeln. Und zum zweiten muss sie die wichtigsten Faktoren isolieren, die den Übersetzungsprozess potentiell beeinflussen. Dann kann sie im Rahmen kontrollierter experimenteller Beobachtungen den Einfluss der Faktoren als unabhängige Variablen auf die Prozessparameter als abhängige Variablen untersuchen. Nur so kann sie langfristig zu verallgemeinerbaren Aussagen über die Struktur von Übersetzungsprozessen in Abhängigkeit von seinen relevanten Einflussgrößen kommen.
Aus dieser Grundüberlegung heraus lassen sich für die Übersetzungsprozessforschung folgende Hauptfragestellungen herausarbeiten:
Allgemeine Beschreibung und Teilprozesse: Wie gehen Übersetzer an die komplexe Aufgabe heran, einen Text von einer Sprache in eine andere zu übersetzen und welche Teilprozesse sind dabei zu beobachten?
Dies ist die generelle Frage nach den Prozessparametern. Sie zerfällt in zahlreiche Teilfragen, je nach dem, an welchen Prozessparametern man besonders interessiert ist. Im Mittelpunkt der bisherigen Forschung stand z.B. häufig die Frage nach den Übersetzungsproblemen und den Übersetzungsstrategien: Welche sprachlichen und nichtsprachlichen Probleme treten in Übersetzungsprozessen auf und welche Strategien setzen die Übersetzer zur Lösung dieser Probleme ein? Doch dies sind nur zwei besonders wichtige Teilfragen. Die Zahl der Parameter, die bisher zur Beschreibung von Übersetzungsprozessen entwickelt wurden, geht mittlerweile in die Hunderte (siehe Abschnitt 5 „Methoden der Datenanalyse“).
Auch die Frage nach den potentiell beeinflussenden Faktoren kann wiederum in zahlreiche Einzelfragen zerlegt werden, je nach dem, von welchen Faktoren man vermutet oder bereits weiß, dass sie einen Einfluss auf den Übersetzungsprozess haben. Um diese Faktoren besser zu strukturieren, schlage ich eine heuristische Zusammenfassung in drei große Faktorenbündel vor: Aufgabenfaktoren, Übersetzerfaktoren und Situationsfaktoren (siehe Graphik 1).
Graphik 1
Faktorenmodell des Übersetzungsprozesses

Unter Aufgabenfaktoren fasse ich alle Faktoren zusammen, die mit der Übersetzungsaufgabe im weitesten Sinne zusammenhängen. Die wichtigsten aus meiner Sicht sind:
Sprachenpaar (z.B. Übersetzen in eine sprachsystematisch nah verwandte vs. in eine weit entfernte Sprache: Deutsch – Englisch vs. Deutsch – Japanisch)
Übersetzungsauftrag (translation assignment, z.B. dokumentarische vs. instrumentelle Übersetzung eines Ausgangstextes)
Texttyp und Textsorte (z.B. Gebrauchsanleitungen vs. Verträge vs. Werbetexte vs. Geschäftsberichte usw.)
Fachlichkeit (z.B. juristische vs. technische vs. medizinische Texte; aber auch Texte mit geringem vs. Texte mit hohem Fachlichkeitsgrad)
Übersetzungsrichtung (Übersetzen aus der Fremdsprache in die Muttersprache des jeweiligen Übersetzers vs. umgekehrt)
Unterschiede und Gemeinsamkeiten zwischen dem Übersetzen und benachbarten Aufgaben, insbesondere dem Dolmetschen oder der Nachredaktion von Maschinenübersetzungen
Unter Übersetzerfaktoren fasse ich alle Faktoren zusammen, die mit individuellen Merkmalen der jeweiligen Übersetzer zu tun haben:
Übersetzerische Expertise (nichtprofessionelle Übersetzer vs. semiprofessionelle Übersetzer vs. professionelle Übersetzer; aber auch individuelle Erfahrung mit einzelnen Texttypen, Arten von Übersetzungsaufträgen usw.)
Grad der Sprachbeherrschung bzgl. Ausgangs- und Zielsprache
Art und Umfang von Sach- und Fachkenntnissen bzgl. des Gegenstandes der jeweiligen Übersetzung (domain knowledge)
individuelle übersetzerische Strategiepräferenzen
Der zuletzt genannte Punkt umfasst wiederum eine große Zahl einzelner Faktoren. Fast alle bisherigen empirischen Untersuchungen haben deutliche Anhaltspunkte dafür geliefert, dass es über die drei zuerst genannten Kompetenzunterschiede hinaus markante individuelle Unterschiede im übersetzerischen Verhalten gibt.
Natürlich muss man davon ausgehen, dass auch affektive Faktoren den Übersetzungsprozess beeinflussen, so z.B. die Einstellung des Übersetzers zu seinem Beruf (Identifikation, Motivation), zu einem bestimmten Fachgebiet oder gar zum einzelnen Text. Auch die psychophysische Befindlichkeit während eines Übersetzungsvorgangs (z.B. Wohlbefinden vs. Anspannung) dürfte einen nachhaltigen Einfluss auf die Prozesse haben. Allerdings sind die affektiven Aspekte des Übersetzungsprozesses bisher nicht mit Erfolg untersucht worden. Dies liegt vor allem daran, dass das bisher in der Übersetzungsprozessforschung dominante methodische Verfahren, nämlich das Laute Denken, auf die Erfassung kognitiver Prozesse ausgerichtet ist. Für eine systematische Erfassung affektiver Einflussvariablen müsste dieses mit anderen, dafür besser geeigneten Verfahren kombiniert werden.
Schließlich kann man eine Reihe von Faktoren zu einer dritten Gruppe zusammenfassen, die weder die Übersetzungsaufgabe, noch individuelle Merkmale der Übersetzer betrifft, sondern die mit Merkmalen des übersetzerischen Umfeldes, in dem der Übersetzungsprozess stattfindet, zu tun hat. Ich spreche deshalb von „Situationsfaktoren“:
Einfluss technischer Hilfsmittel (z.B. output-Methode: handschriftliches Übersetzen vs. Diktiergerät vs. Computer)
Verfügbarkeit von Nachschlagewerken und Recherchiermöglichkeiten (ein- und zweisprachige Wörterbücher, Fachwörterbücher, Enzyklopädien, Fachdatenbank, Internet usw.)
Einfluss von maschinellen Übersetzungshilfen (z.B. Terminologieverwaltungssoftware, translation-memory-Systemen oder maschinellen Übersetzungssystemen)
situatives Umfeld: alle weiteren Faktoren, die beim „real-life-Übersetzen“ den Übersetzungsprozess beeinflussen können, z.B. die für eine Übersetzung zur Verfügung stehende Zeit, Möglichkeit zu Kundenkontakten, betriebsinterne Vorschriften für das Übersetzen usw.
Die drei genannten Faktorenbündel betreffen alle Fragen zum Zusammenhang zwischen diesen Faktoren und bestimmten Merkmalen des Übersetzungsprozesses. Eine vierte Dimension der Übersetzungsprozessforschung ergibt sich demgegenüber aus der Frage, wie wiederum diese festgestellten Prozessmerkmale in ihrem Zusammenwirken das Übersetzungsprodukt beeinflussen. Hierzu gehört auch die wichtige Teilfrage, welche Prozessmerkmale zu einer hohen Qualität des Übersetzungsproduktes führen und welche nicht.
Schließlich muss gefragt werden, wie die Ergebnisse aller Forschungen zu den vorausgehenden Fragen zu einer zusammenhängenden Theorie des Übersetzungsprozesses zusammengeführt werden können. Gelingt es, eine solche Theorie in ausreichend detaillierter Form zu entwickeln, dann lässt sich langfristig auch die übersetzungsdidaktische Frage beantworten: Wie groß ist der Aufschlusswert einer zusammenfassenden Theorie des Übersetzungsprozesses für das Lehren und Lernen von Übersetzungskompetenz und welche praktischen Konsequenzen für den Übersetzungsunterricht lassen sich daraus ableiten?
Die hier vorgestellte Liste erfasst nur die wichtigsten Fragenkomplexe. Darüber hinaus sind durchaus noch weitere Fragestellungen denkbar, die für spezielle Formen oder Anwendungen des Übersetzens von Interesse sind; so zum Beispiel die Frage, worin die Unterschiede zwischen Individual- und Teamübersetzungsprozessen bestehen oder welche Unterschiede zwischen dem Übersetzen als einer vorlagegebundenen Form der Textproduktion und den verschiedenen Formen der freien Textproduktion bestehen. Auch die Frage nach Unterschieden zwischen Übersetzungs- und den verschiedenen Formen von Dolmetschprozessen eröffnet lohnende Forschungsfelder.
4. Methoden der Datenerhebung
Einer der wichtigsten Gründe für den späten Beginn der Übersetzungsprozessforschung war, wie bereits weiter oben festgestellt, mangelnde methodische Expertise. Um so wichtiger ist es, sich klar zu machen, dass für die Analyse von Übersetzungsprozessen eine ganze Reihe von Methoden zur Verfügung stehen, auch wenn die Übersetzungsprozessforschung einige wenige dieser Methoden bisher einseitig bevorzugt hat. Ich möchte im Folgenden Versuchen, die grundlegenden Methoden kurz zu skizzieren. In Graphik 2 sind diese Verfahren synoptisch zusammengefasst.Zunächst ist zwischen zwei Grundtypen von Datenerhebungsverfahren zu unterscheiden, je nach dem, ob die Daten periaktional (also zeitlich parallel zum Übersetzungsprozess) oder postaktional (nach Abschluss des Übersetzungsprozesses) erhoben werden. Die erste Gruppe nenne ich „Online-Verfahren“, die zweite „Offline-Verfahren“. Offline-Verfahren können wiederum in zwei Gruppen von Verfahren aufgeteilt werden: Produktanalysen und Verbale Daten.
Graphik 2
Typologie von Datenerhebungsverfahren zur Untersuchung von Übersetzungsprozesses

Reine Produktdaten greifen zum Aufstellen von Hypothesen über den Übersetzungsprozess ausschließlich auf die Übersetzungsprodukte, also die fertigen Übersetzungen in ihrer letztgültigen Form zurück. Solche Verfahren beruhen auf der Annahme, dass von bestimmten Merkmalen der Übersetzungsprodukte (z.B. Übersetzungsfehlern) Rückschlüsse auf bestimmte Merkmale des Übersetzungsprozesses möglich sind (z.B. Übersetzungsprobleme). In rein spekulativer Form sind solche Rückschlüsse fast überall in der vorempirischen Phase der Übersetzungswissenschaft und der Übersetzungsdidaktik zu finden.
Obwohl solche Rückschlüsse als Verfahren der Hypothesengenerierung sicherlich zulässig sind, ist grundsätzlich festzustellen, dass reine Produktdaten zweifellos die unzuverlässigste und am wenigsten aussagekräftige Quelle für die Analyse von Übersetzungsprozessen darstellen. Denn das Übersetzungsprodukt ist im Grunde nichts anderes als die letzte Momentaufnahme in einem komplizierten nicht-linearen Prozess. Diese Nicht-Linearität führt zu einer grundsätzlichen Produkt-Prozess-Ambiguität. Das heißt: Unterschiedliche Prozesse können genauso gut zu identischen wie zu verschiedenen Produkten führen und umgekehrt können identische Produkte sowohl durch gleiche wie durch verschiedene Prozesse entstanden sein. Rückschlüsse allein von Produktmerkmalen auf Prozessmerkmale sind deshalb häufig entweder vage oder mit einer hohen Irrtumswahrscheinlichkeit behaftet.
Ein erster Schritt in Richtung auf originäre Prozessdaten wird getan, wenn außer den reinen Übersetzungsprodukten auch alle handschriftlich vorliegenden Zwischenprodukte des Übersetzungsprozesses in die Analyse einbezogen werden, konkret also alle Markierungen und Notizen in, am oder zum Ausgangstext, erste Übersetzungsversuche und insbesondere alle Revisionen (Streichungen, Ergänzungen und Änderungen) im Zieltext. Solche Zwischenprodukte fallen bei fast allen Übersetzungsprozessen an und sind unmittelbarer Ausdruck der Nicht-Linearität dieses Prozesses. Sie erweitern die Datengrundlage vom reinen Produkt als singulärer Momentaufnahme in den prozessualen Raum hinein. Trotzdem bringt man mit der Berücksichtigung solcher Zwischenprodukte den Übersetzungsprozess nicht einmal annäherungsweise vollständig ins Blickfeld. Zwischenprodukte liefern lediglich zusätzliche punktuelle Momentaufnahmen, ohne schlüssige Aussagen über den genauen zeitlichen Ablauf des Übersetzungsprozesses zu ermöglichen. Machte beispielsweise eine Revision A die Revision B notwendig oder war es umgekehrt? Oder waren beide Revisionen vielmehr Ausdruck einer umfassenderen Strategieänderung C? Wird am Computer geschrieben, sind meist überhaupt keine Zwischenprodukte dokumentiert, weil die Übersetzer in der Regel nur die Endfassung des Zieltextes abspeichern.
Wiederum ein wenig mehr über die Prozesse erfährt man, wenn man auch andere Übersetzungen des gleichen Übersetzers oder Übersetzungen des gleichen Textes durch andere Übersetzer hinzuzieht. Aber dies sind jeweils nur Verbreiterungen einer Datenbasis, die insgesamt auf Produktdaten beschränkt bleibt.
Eine qualitativer Zuwachs an Information tritt erst ein, wenn verbale Daten hinzugezogen werden. Die Sammelbezeichnung „verbale Daten“ (englisch meistens „verbal-report data“) verweist auf eine Reihe unterschiedlicher Datenerhebungsmethoden, deren gemeinsames Merkmal darin besteht, dass die Versuchspersonen zu Verbalisierungen von Gedanken, Meinungen, Empfindungen, Einstellungen und dgl. aufgefordert werden und dass diese Verbalisierungen als Daten systematisch dokumentiert und analysiert werden. So kann man Übersetzer z.B. bitten, ihre eigenen Übersetzungen retrospektiv zu kommentieren oder sie mit Fragebögen und Interviews zu ausgewählten Aspekten ihres übersetzerischen Vorgehens befragen, sei es im Zusammenhang mit einem spezifischen einzelnen Text (retrosopektive Interviews oder Fragebögen) oder bezüglich ihrer generellen Übersetzungsstrategien (generalisierte Interviews/Fragebögen).
Die methodische Grundlagenforschung in der kognitiven Psychologie hat gezeigt, dass retrospektiv erhobene verbale Daten interessante Einblicke in die Selbstwahrnehmung der eigenen kognitiven Prozesse der Befragten geben können. Sie hat aber auch gezeigt, dass bei retrospektiven verbalen Daten erhebliche Probleme hinsichtlich der Validität der Daten entstehen. Als Grund hierfür wird angeführt, dass bei einem retrospektiven Zugriff die relevanten Informationen über die Prozesse zwischenzeitlich im Langzeitgedächtnis der Versuchspersonen abgespeichert worden sind und dort für die retrospektive Verbalisierung wieder aufgefunden werden müssen, was durch spezielle Abrufprozesse geschieht. Bei diesen Abrufprozessen aus dem Langzeitgedächtnis kann es zu mehreren Arten von Verzerrungen kommen. Die Verzerrungen sind dabei potentiell um so größer, je größer der zeitliche Abstand zwischen Prozess und retrospektiver Verbalisierung ist. Der Verzerrungseffekt kann auch dann schon eintreten, wenn die retrospektive Verbalisierung unmittelbar nach Abschluss der Primäraufgabe (also nach Fertigstellung der Übersetzung) vorgenommen wird. Allerdings kann eine mediengestützte Retrospektion (z.B. Vorspielen einer Videoaufzeichnung der eigenen Übersetzungsprozesse, insbesondere der Schreibbewegungen auf dem Papier oder der Tastatureingaben am Bildschirm) hier eine retrospektive Verbalisierung stützen. Der große Vorteil aller retrospektiven Verfahren ist, dass sie nicht mit den Übersetzungsprozessen selbst interferieren können, weil sie erst nach deren Abschluss beginnen.
Wesentlich näher gelangt man durch Online-Verfahren man an die Übersetzungsprozesse heran. Auch hier sind zwei Hauptgruppen zu unterscheiden, je nach dem, ob ausschließlich Verhaltensbeobachtungen oder – messungen durchgeführt werden, oder ob wiederum verbale Daten erhoben werden.
Die einfachste Form der Verhaltensbeobachtung ist das Beobachtungsprotokoll. Der Forscher beobachtet den Übersetzer beim Übersetzen und notiert nach einem bestimmten Raster alles, was äußerlich beobachtbar ist (z.B. Hilfsmittelbenutzungen, längere Übersetzungspausen, Änderungen im Zieltext usw.). Dieses Verfahren ist heute praktisch veraltet, weil durch Audio- und Videotechnik wesentlich bessere und umfangreichere Dokumentationstechniken zur Verfügung stehen. In Feldforschungen, in denen der Einsatz von Technik nicht möglich oder zu aufwendig ist, kann dieses Verfahren aber in der Explorationsphase einer empirischen Untersuchung auch heute noch sinnvoll sein.
Der Einsatz von Videotechnik erlaubt eine vergleichsweise dichte Erfassung des Übersetzungsverhaltens, so weit es sich in konkreten Handlungen niederschlägt. Dabei sind grundsätzlich zwei Kameraperspektiven sinnvoll: Die Kamera kann von oben auf das Blatt gerichtet werden, auf dem die Versuchspersonen ihre Übersetzung zu Papier bringen. Sie kann dann mit Hilfe des Zooms jede einzelne Schreibbewegung der Versuchspersonen aus nächster Nähe filmen und so die Entstehung des Über-setzungsproduktes zeitlich genau dokumentieren. (Dazu sollte die Kamera über einen eingeblendeten Timecode verfügen.) Zum anderen kann die Kamera von vorne auf die Versuchspersonen gerichtet werden und so alle anderen Handlungen erfassen, insbesondere vor allem die Benutzung von Nachschlagewerken. Am besten werden beide Kameraperspektiven kombiniert und über ein Mischpult synchron zusammengeschnitten (so z.B. bei Krings 2001). Mit dieser Technik können zumindest alle äußerlich beobachtbaren Aspekte des Übersetzungsprozesses minutiös festgehalten werden.
Eine in jüngerer Zeit immer wichtiger werdende Alternative sind Tastatur- und Bildschirmprotokollprogramme. Dabei handelt es sich um Softwareprodukte, die den gesamten Prozess der Entstehung eines Textes am Bildschirm genau dokumentieren. Hier ist insbesondere das von Arnt Lykke Jakobsen von der Copenhagen Business School entwickelte System „Translog“ zu nennen, das ideal auf die Bedürfnisse der Erhebung von Übersetzungsprozessdaten zugeschnitten ist (Jakobsen 1999, 2002; www.translog.dk). Dieses Programm zeichnet während des Übersetzungsvorgangs alle Tastatureingaben auf, einschließlich der Lösch-, Einfüge-, cut-and-paste-Operationen sowie Cursorbewegungen und Mausklicks. Zu allen aufgezeichneten Operationen dokumentiert es automatisch die genaue Zeit. Das Programm arbeitet dabei im Hintergrund, das heißt, ohne die Übersetzungsprozesse der jeweiligen Versuchsperson in irgendeiner Weise zu behindern. Das Programm macht es auch möglich, sich nach Abschluss der Textproduktion die komplette Aufzeichnung der Schreibprozesse am Bildschirm beliebig oft anzusehen. Es ist somit ein wertvolles Forschungsinstrument, das im übrigen nicht nur zur Analyse von Übersetzungs-, sondern auch von Schreibprozessen eingesetzt werden kann.
In Psychologie und Psycholinguistik weit verbreitet, in der Übersetzungsprozessforschung meines Wissens aber bisher noch nie praktiziert sind Augenbewegungsmessungen (Okulometrie). Die Versuchspersonen setzen dazu eine brillenartige Vorrichtung auf, die es erlaubt, genau zu rekonstruieren, wie sich die Versuchspersonen mit ihren Augen durch einen Text bewegen. Diese Technik könnte interessante Aufschlüsse über die Art der Rezeption des Ausgangstextes und über die beim Übersetzen in großer Zahl notwendigen Sprünge zwischen Ausgangs- und Zieltext liefern.
Ebenfalls in anderen kognitiv orientierten Forschungsgebieten weit verbreitet ist der Einsatz bildgebender Verfahren, mit denen physische Korrelatvorgänge zu kognitiven Prozessen erforscht werden, angefangen vom klassischen Elektroenzephalogramm (EEG) über die Positronenemissionstomographie (PET) bis hin zur Magnetresonanztomographie (MRT) und zum echo planar imaging (EPI). Diese Verfahren liefern Daten über den Ort und die Intensität der Aktivierung von Hirnarealen während der Ausführung einer kognitiven Aufgabe, potentiell also auch des Übersetzens. In der Schreibforschung konnte so z.B. schon 1980 von Glassner nachgewiesen werden, dass unterschiedliche Texttypen zu unterschiedlichen kortikalen Aktivierungsmustern führen können (linkshemiphärische vs. rechtshemiphärische Dominanz). Der Einsatz solcher Verfahren in der Übersetzungsprozessforschung könnte einen Beitrag zur Neurolinguistik des Übersetzungsprozesses leisten. Eine solche ist bisher aber (anders als im Bereich der Schreib- oder Leseforschung) nicht einmal im Ansatz vorhanden. Beim Einsatz solcher Verfahren sind meiner Meinung nach allerdings strenge forschungsethische Maßstäbe anzulegen.
Als letzte und bisher fast ausschließlich praktizierte Datenerhebungsmethoden sind verbale Online-Verfahren zu nennen. Das Laute Denken ist das mit Abstand am häufigsten eingesetzte Verfahren überhaupt. Beim Lauten Denken haben die Versuchspersonen die Aufgabe, ihre Gedanken während des gesamten Übersetzungsprozesses, vom ersten Kontakt mit dem Ausgangstext bis zur Abgabe des endgültigen Übersetzungsproduktes, ohne irgendeine Art von Selektion laut auszusprechen. Diese Verbalisierungen der Versuchspersonen werden dann mit Audio- oder Videotechnik aufgezeichnet und zu vollständigen “Protokollen des Lauten Denkens” (LD-Protokolle, thinking-aloud protocols) verarbeitet. Sie enthalten in der Regel umfangreiches Material zu allen bewusst ablaufenden aufgabenbezogenen kognitiven Prozessen der Versuchspersonen.
Vom Lauten Danken zu unterscheiden ist das sog. Laute Mitsprechen (talk aloud). Dieses ist ein eingeschränktes Lautes Denken, bei dem von den Versuchspersonen verlangt wird, nur das laut auszusprechen, was sie während der Beschäftigung mit der Aufgabe leise zu sich selbst sagen. Anders als beim Lauten Denken verbalisieren die Versuchspersonen in diesem Fall nur solche Gedanken, die konkretes sprachliches Material aus dem Ausgangstext oder dem Zieltext enthalten, während sie beim Lauten Denken auch sehr viele Verbalisierungen vornehmen, in denen die gesamte Problemhaftigkeit des Übersetzungsprozesses in all seinen Aspekten und einzelnen Lösungsschritten thematisiert wird. Obwohl Lautes Denken und lautes Mitsprechen in der methodischen Grundlagenforschung zu verbalen Daten konsequent unterschieden werden und diesen Verfahren unterschiedliche Qualitäten bezüglich der Validität und der Vollständigkeit der Daten zugesprochen werden, vermischen sich beide Verfahren in der Forschungspraxis häufig. Es gibt Anhaltspunkte dafür, dass weniger verbalisierungswillige Versuchspersonen das Laute Denken tendenziell auf ein lautes Mitsprechen reduzieren.
Eine vor allem in jüngerer Zeit häufiger praktizierte interessante Alternative zum Lauten Denken sind Dialogprotokolle. Dabei erhalten jeweils zwei Versuchspersonen die gleiche Übersetzungsaufgabe und müssen diese im Team lösen, also einen gemeinsamen Zieltext erstellen. Die dabei zustandekommenden Dialoge werden als psycholinguistische Daten betrachtet, die Aufschluss über den Verlauf des Problemlösungsprozesses der Versuchspersonen geben. Ein beträchtlicher Vorteil der Dialogprotokolltechnik besteht darin, dass die Versuchspersonen das gemeinsame Übersetzen meist spontan als eine natürlichere Datenerhebungssituation empfinden als das Laute Denken. Untersuchungen zeigen, dass dialogisches Übersetzen in der Regel zu noch umfangreicheren Daten führt als Lautes Denken. Andererseits kann aus der Analyse von Prozessdaten zum dialogischen Übersetzen streng genommen niemals direkt auf individuelle Übersetzungsprozesse geschlossen werden. Sichere Verallgemeinerungen sind mit diesem Verfahren deshalb nur für das interaktive Übersetzen selbst möglich, das in der Praxis allerdings die große Ausnahme ist.
Naturgemäß gibt es in der Fachliteratur eine breite Diskussion über die Vor- und Nachteile der einzelnen Verfahren. Insbesondere ist das am häufigsten praktizierte Verfahren, das Laute Denken, immer Gegenstand kritischer Fragen hinsichtlich seiner methodischen Zulässigkeit gewesen. Hier ist nicht der Platz, um diese Diskussion darzustellen (für eine ausführliche theoretische Diskussion der Vor- und Nachteile verbaler Daten in der Übersetzungsprozessforschung siehe Krings 2001: 214ff.). Es lässt sich allerdings feststellen, dass seit den bahnbrechenden Arbeiten der amerikanischen Kognitionspsychologen K. Anders Ericsson und Herbert A. Simon verbale Daten und insbesondere das Laute Denken als methodisch anerkannt und systematisch begründet gelten. Seitdem sind das Laute Denken und andere Formen von verbalen Daten zu den am häufigsten praktizierten Methoden zur Untersuchung kognitiver Prozesse in der Psychologie und ihren Nachbardisziplinen geworden. Trotzdem liegt es auf der Hand, dass das Laute Denken (wie jedes Datenerhebungsverfahren) einen Einfluss auf die Daten und damit die Forschungsergebnisse haben kann. So habe ich in meiner empirischen Arbeit von 2001 Daten zur gleichen Aufgabe mit Lautem Denken und ohne Lautes Denken erhoben und dabei festgestellt, dass nicht nur die Bearbeitungsgeschwindigkeit in beiden Versuchsgruppen deutlich verschieden war, sondern auch bestimmte Merkmale des übersetzerischen Verhaltens selbst, z.B. die Zahl der Revisionen im Zieltext (S.525ff.). Solche potentiellen Effekte des Verfahrens sind also grundsätzlich in die Interpretation von Daten einzubeziehen.
Die einzige grundsätzliche Möglichkeit, die Effekte einer einzelnen Datenerhebungstechnik auf die Theoriebildung so gering wie möglich zu halten ist die Datentriangulation, also die Bearbeitung gleicher Fragestellungen mit unterschiedlichen Methoden. Datentriangulation kann die potentiellen Verzerrungseffekte der einzelnen Verfahren zwar nicht aufheben, aber reduzieren und langfristig minimieren. Vor diesem Hintergrund ist die bisherige Konzentration der Übersetzungsprozessforschung auf einige wenige Verfahren eher kritisch zu sehen. Ein stärkerer Methodenpluralismus ist dringend wünschbar. Um den Triangulationseffekt voll zum Tragen zu bringen, wird es in Zukunft nötig sein, in stärkerem Maße einen koordinierten Methodenpluralismus zu praktizieren, z.B. dadurch, dass die jeweilige Fragestellung auch innerhalb einzelner empirischer Untersuchungen von vornherein mit verschiedenen Methoden angegangen wird.
5. Methoden der Datenanalyse
In der Datenerhebung gibt es einerseits Verfahren, die sich durch ein sehr hohes Maß an Strukturierung auszeichnen, z.B. geschlossene Fragebögen, und andererseits Verfahren, die einen sehr geringen Strukturierungsgrad haben, z.B. das Laute Denken. Im allgemeinen kann man sagen: Je strukturierter die Datenerhebung ist, desto einfacher ist später die Datenanalyse. Umgekehrt gilt, dass bei Verfahren, die eine relativ unstrukturierte Datenerhebung implizieren, die Datenanalyse besonders strukturiert sein muss, um zu vernünftigen Ergebnissen zu kommen. Dies gilt in ganz besonderem Maße für das von der Übersetzungsprozessforschung bisher so favorisierte Laute Denken, aber auch für retrospektive Verbalisierungen und Dialogprotokolle. Bei diesen Verfahren ist es relativ einfach, Daten zu erheben, aber ausgesprochen schwer, systematische Ergebnisse aus ihnen abzuleiten. Deshalb ist es besonders wichtig, sich Gedanken darüber zu machen, wie man mit solchen Daten systematisch umgeht. Dies möchte ich im folgenden am Beispiel des Lauten Denkens etwas näher erläutern.
Das Laute Denken liefert als Ergebnis einen konstanten und per definitionem unstrukturierten Fluss von sprachlichen Äußerungen der Versuchspersonen, der zudem noch ausgesprochen umfangreich ist. Die Relation zwischen dem Umfang der bearbeiteten Ausgangstexte und dem Umfang der Verbalisierungen erreicht in der Regel eine Größenordnung von 1: 10 bis 1: 20, d. h., eine Seite Ausgangstext elizitiert ein LD-Protokoll im Umfang von 10 bis 20 Seiten. (Bei der Dialogprotokolltechnik liegt der Wert meist noch deutlich höher.) Diese Werte gelten pro Versuchsperson. Bei 10 Versuchspersonen fallen also bereits 100 bis 200 Seiten LD-Protokolle für einen nur einseitigen Text an. Die Analyse von LD-Protokollen ist also schon rein quantitativ sehr aufwendig. (Dies ist auch wahrscheinlich der Grund dafür, warum die Zahl der Versuchspersonen in fast allen Untersuchungen relativ gering ist.).
Das größere Problem ist aber die Unstrukturiertheit der Daten. Der konstante Verbalisierungsfluss der Versuchspersonen ist naturgemäß in keiner Weise auf die Fragestellung des Experimentators bezogen. Die ihn interessierenden Aspekte des Übersetzungsprozesses müssen vielmehr in vielen, methodisch sorgfältig geplanten Schritten aus den Daten herausgefiltert werden. Angesichts der Schwierigkeit dieser Aufgabe ist die Versuchung einer rein selektiv-phänomenologischen Analyse sehr groß: Man geht die Protokolle auf interessante Einzelbeobachtungen durch, die man dann zum Gegenstand der Analyse macht. Dieses Verfahren ist als Grundstufe der Datenanalyse natürlich zulässig bzw. sogar notwendig, aber nur im Sinne einer ersten Exploration als Grundlage für eine systematischere Datenanalyse im nächsten Schritt. Die phänomenologische Analyse ist sozusagen die Nullstufe der Datenanalyse. Beschränkt man sich auf diese, so bleibt die Analyse rein impressionistisch und hat keinerlei generalisierende Aussagekraft. Die Erfahrung zeigt, dass es immer wieder Publikationen zum Übersetzungsprozess gibt, in denen die Forscher auf dieser Analyseebene stehen geblieben sind. Das Entscheidende ist aber die Notwendigkeit der aufsteigenden Abstraktion: Wir können uns nicht damit begnügen, punktuelle Einzelbeobachtungen aneinanderzureihen, sondern wir müssen fragen, was an diesen für eine bestimmte Art von Übersetzungsprozess typisch ist. In Graphik 3 habe ich dargelegt, welche Stufen dieser aufsteigenden Abstraktion es geben kann.
Der erste Schritt nach der phänomenologischen Analyse ist die Bildung von Kategorien, die es ermöglichen, die beobachteten punktuellen Einzelphänomene in Klassen einzuteilen. So können zum Beispiel anhand von LD-Daten Übersetzungsprobleme definiert werden (z.B. Probleme im Verständnis des Ausgangstextes, Probleme beim Auffinden von Wiedergabemöglichkeiten, Probleme, sich zwischen verschiedenen erwogenen Wiedergabemöglichkeiten zu entscheiden usw.). Oder die Übersetzungsprobleme können danach kategorisiert werden, auf welcher sprachlichen Ebene sie angesiedelt sind (unterhalb der Wortebene, Wortebene, Mehrwortebene, Teilsatzebene, Satzebene, Textebene, außertextliche Ebene). Durch die Klassifizierung wird im nächsten Schritt die Quantifizierung möglich, z. B. wieviele Übersetzungsprobleme welcher Art bei welcher Versuchsperson auftreten. Quantifizierung ist einerseits wichtig, um häufige und damit besonders wichtige Prozessmerkmale von solchen zu trennen, die selten und weniger wichtig sind. Außerdem sind Quantifizierungen eine notwendige Voraussetzung für die Überprüfung detaillierter Hypothesen über den Einfluss bestimmter Variablen auf den Übersetzungsprozess. Eine Korrelation liegt vor, wenn ein statistischer Zusammenhang zwischen zwei Variablen (z.B. dem Grad an Übersetzungsexpertise bei einer bestimmten Gruppe von Versuchspersonen und dem Einsatz bestimmten Übersetzungsstrategien) vorliegt. In der induktiven Statistik wird jedoch deutlich zwischen dem Nachweis einer Korrelation und dem Nachweis der Kausalität unterschieden. Ein Nachweis der Kausalität ist nur dann gegeben, wenn ein statistisch signifikanter Einfluss einer unabhängigen Variablen auf eine abhängige Variable nachgewiesen wird und gleichzeitig alle anderen potentiell relevanten Variablen konstant gehalten wurden. Ein solcher Nachweis ist nur im Rahmen sehr sorgfältig geplanter experimenteller Anordnungen mit Versuchs- und Kontrollgruppen zu führen.
Graphik 3
Ebenen der Datenanalyse
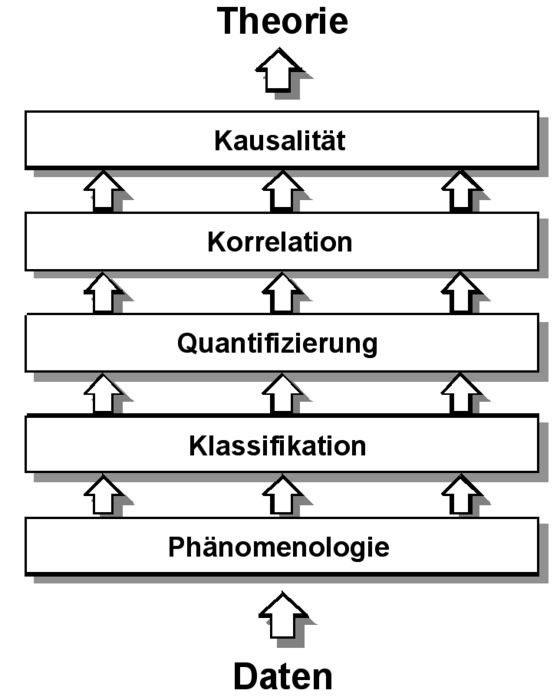
Wenn man sich die bisher vorliegenden empirischen Untersuchungen zum Übersetzungsprozess ansieht, dann sind fast alle Studien auf den Stufen der Phänomenologie, der Klassifikation und der Quantifizierung angesiedelt. Dies ist verständlich, denn es ging ja zunächst darum, überhaupt erst einmal Parameter zur Beschreibung des Übersetzungsprozesses zu entwickeln. Für eine systematische Theoriebildung über den Zusammenhang zwischen den verschiedenen Aufgaben-, Übersetzer- und Umfeldvariablen einerseits und Merkmalen des Übersetzungsprozesses andererseits sind aber in Zukunft mehr experimentelle Studien erforderlich, die Korrelationen feststellen und Kausalzusammenhänge nachweisen.
Ungeachtet dieser Defizite sind in der bisherigen Übersetzungsprozessforschung eine Vielzahl von Parametern zur Beschreibung des Übersetzungsprozesses entwickelt worden. Dabei können wir bei den vorliegenden Ansätzen grundsätzlich zwei Typen unterscheiden. Zum einen solche Arbeiten, die einzelne Parameter definieren und die LD-Protokolle dann ausschließlich nach diesen Parametern durchsuchen (z.B. Typen von Übersetzungsproblemen, Strategietypen, Hilfsmittelbenutzungen, Formen der Aktivierung von Vorwissen usw.). Zum anderen sind dies Arbeiten, die die LD-Protokolle mit Hilfe eines sog. Kodiersystems komplett beschreiben. Beide Verfahren haben spezifische Vor- und Nachteile und es sollte von der Art der Fragestellung abhängig gemacht werden, welches Verfahren angewandt wird. In meiner Arbeit von 1986 war ich z.B. primär an Übersetzungsproblemen und problembezogenen Lösungsstrategien interessiert. Ausgehend von einer datenbezogenen Operationalisierung des Problembegriffs habe ich insgesamt 117 verschiedene Parameter entwickeln können, mit denen Merkmale des Übersetzungsprozesses erfasst wurden (s. Krings 1986: 491ff.). Hier eine Auswahl:
Gesamtzahl der Übersetzungsprobleme pro Versuchsperson
Anteil der Rezeptions-, Rezeptions-Wiedergabe- und Wiedergabeprobleme an der Gesamtzahl der Übersetzungsprobleme pro Versuchsteilnehmer
Grad der Interindividualität der Übersetzungsprobleme
Ausführung der Übersetzungsaufgabe in Form eines oder mehrerer Textdurchgänge (Vorlauf, Hauptlauf, Nachlauf)
Reihenfolge in der Abarbeitung der Übersetzungsprobleme: linear (kontinuierlich) vs. konzentrisch (diskontinuierlich)
Anzahl der satzüberschreitend behandelten Übersetzungsprobleme
Gesamtzahl der Hilfsmittelbenutzungen pro Versuchsperson
Verteilung der Hilfsmittelbenutzungen auf die verschiedenen Hilfsmitteltypen (einsprachiges Wörterbuch, zweisprachiges Wörterbuch, enzyklopädisches Nachschlagewerk usw.)
Durchschnittliche Zahl von Übersetzungsversuchen pro Übersetzungsproblem pro Versuchsperson
Anteil der aus dem zweisprachigen Wörterbuch stammenden Übersetzungsversuche an der Gesamtzahl der Übersetzungsversuche pro Problem
Zahl positiver, negativer, relativer und gleichsetzender Evaluationen von Übersetzungsversuchen usw.
Ein Beispiel für eine ganz andere Fragestellung wäre die Arbeit von Dragsted (2003). Sie will herausfinden, wie der Einsatz eines Translation-Memory-Systems (mit einer satzweisen Präsentation des Ausgangstextes auf dem Bildschirm) die Struktur des Übersetzungsprozesses beeinflusst. Dementsprechend setzt sie Parameter ein, von denen man annahmen kann, dass sie durch dieses technische Hilfsmittel beeinflusst werden:
die Gesamtproduktionszeit der Übersetzung
die Dauer und der relative Anteil der Revisionszeit
das Pausenverhalten der Versuchspersonen vor jedem neuen Satz
die Zahl der Abweichungen von der Satzstruktur des Ausgangstextes im Zieltext (sentence structure alterations, d.h. Zerlegung in Teilsätze oder Verbindung von mehreren kürzeren Sätzen zu einem längeren)
Die ersten drei sind reine Prozessparameter, der letzte ist ein Produktparameter. Die geschickte Kombination von Prozess- und Produktparametern ist für viele Fragestellungen eine wichtige Lösungsstrategie.
Auch bei der zweiten Form der Datenanalyse, der Entwicklung eines Kodiersystems, das auf die gesamten LD-Protokolle angewandt wird, kann eine große Zahl unterschiedlicher Prozessparameter entwickelt werden. So entwickelte Kiraly (1990) 19 Parameter, Lörscher (1991) 22, Gerloff (1988) 76 und Krings (2001) 85. Ein Nachteil der Komplettkodierung der LD-Protokolle ist zweifellos der große Aufwand. Ein Vorteil ist aber, das alle identifizierten Prozesse für das gesamte Datenkorpus quantifiziert werden können. So habe ich beispielsweise für mein Datenkorpus von 2001 die in Graphik 4 dargestellte Verteilung der insgesamt 20579 identifizierten Einzelprozesse auf Hauptprozesstypen feststellen können. Solche Prozessquantifizierungen wurden dann eingesetzt, um systematische Vergleiche zwischen dem Nachredigieren einer Maschinenübersetzung und einem Humanübersetzungsprozess durchzuführen.
Graphik 4
Prozentuale Verteilung von insgesamt 20579 identifizierten Einzelprozessen auf acht Hauptgruppen in Krings (2001)

PROD: auf die Produktion des Zieltextes bezogene Prozesse
WRITE: materielle Schreibprozesse
MON: auf die Bewertung ( monitoring) des Zieltextes bezogene Prozesse
MACHINE: auf die Maschinenübersetzung bezogene Prozesse
REFBOOK: auf Hilfsmittel bezogene Prozesse
SOURCE: auf den Ausgangstext bezogene Prozesse
GLOBTASK: global aufgabenbezogene Prozesse
NONTASK: nicht unmmittelbar aufgabenbezogene Prozesse
5. Perspektiven
Zusammenfassend lässt sich sagen, dass die Übersetzungsprozessforschung in den letzten 25 Jahren viele Wege gefunden hat, um ins Labyrinth des Übersetzens einzudringen und eine erste, noch sehr grobe Kartographie dieses Labyrinths zu erstellen. Dennoch gibt es viele Desiderata für die weitere Forschung. Die wichtigsten möchte ich abschließend nennen. Meiner Meinung nach benötigen wir:
insgesamt mehr Untersuchungen, um die z.T. noch schmale Datenbasis zu verbreitern
mehr Methodenpluralismus
größere Versuchsgruppen
mehr praxistypische Textsorten
mehr Versuche mit Berufsübersetzer/innen als Versuchspersonen
mehr Feldforschung
mehr inferenzstatistische Untersuchungen zum Nachweis von Korrelationen und Kausalzusammenhängen
mehr Grundlagenforschung zu verbalen Daten
mehr Untersuchungen zu Prozessen an der Mensch-Maschine-Schnittstelle (MÜ-Systeme, Terminologieverwaltungssysteme, Translation-Memory-Systeme)
mehr Koordination der einzelnen Projekte
mehr Untersuchungen zu den bisher nicht oder wenig berücksichtigten Sprachen (Italienisch, Spanisch, Russisch, Japanisch, Arabisch u.a.)
Was bis auf den heutigen Tag fehlt, und dies ist eine wichtige Perspektive der Übersetzungsprozessforschung, ist aber vor allem ein groß angelegtes, europäisches oder internationales Projekt mit einer entsprechenden Drittmittelausstattung, das die zahlreichen kleineren Projekte zusammenführt, die Datenbasis der bisherigen Projekte deutlich verbreitert, die vorhanden Hypothesen überprüft und ergänzt und so zu einer breit angelegten integrativen Theoriebildung über die Psycholinguistik des Übersetzens voranschreitet.
Appendices
References
- Dragsted, B. (2003): Segmentation in Translation and Translation Memory Systems. An Empirical Investigation of Cognitive Segmentation and Effects of Integrating a TM System into the Translation System. Unveröffentlichte Dissertation. Kopenhagen, Copenhagen Business School, Department of English.
- Gerloff, P. (1988): From French to English: A Look at the Translation Process in Students, Bilinguals and Professional Translators, Unveröffentlichte Dissertation, Cambridge, MA, Harvard University.
- Hansen, G. (Hrsg.) (1999): Probing the Process in Translation, Methods and Results, Copenhagen, Samfundslitteratur.
- Hansen, G. (Hrsg.) (2002): Empirical Translation Studies, Process and Product. Copenhagen, Samfundslitteratur.
- Jakobsen, A.L. (1999): Logging Target Text Production with Translog, in Hansen (Hrsg.). S.9-20.
- Jakobsen, A.L. (2002): Translation Drafting by Professional Translators and by Translation Students, in Hansen (Hrsg.). S.191-204.
- Kiraly, D. (1990): Towards a More Systematic Approach in Translation Skill Instruction, Unveröffentlichte Dissertation, Urbana-Champaign, University of Illinois.
- Krings, H. P. (1986): Was in den Köpfen von Übersetzern vorgeht, Eine empirische Untersuchung zur Struktur des Übersetzungsprozesses an fortgeschrittenen Französischlernern, Tübingen, Narr.
- Krings, H.P. (1987): The Use of Introspective Data in Translation, in C. Faerch, G. Kasper (Hrsg.): Introspection in Second Language Research. Clevedon, Multilingual Matters, S. 159-176.
- Krings, H.P. (1988): Blick in die black box: Eine Fallstudie zum Übersetzungsprozess bei Berufsübersetzern, in R. Arntz (Hrsg.): Textlinguistik und Fachsprache, Hildesheim, Olms, S. 393-411.
- Krings, H. P. (2001): Repairing Texts, Empirical Investigations of Machine Translation Post-Editing Processes, Kent, Ohio, Kent State University Press.
- Lörscher, W. (1989): Models of the Translation Process, Claim and Reality, in Target 1.1. S. 43-68.
- Lörscher, W. (1991): Translation Performance, Translation Process, and Translation Strategies. A Psycholinguistic Investigation, Tübingen, Narr.
List of figures
Graphik 1
Faktorenmodell des Übersetzungsprozesses
Graphik 2
Typologie von Datenerhebungsverfahren zur Untersuchung von Übersetzungsprozesses
Graphik 3
Ebenen der Datenanalyse
Graphik 4
Prozentuale Verteilung von insgesamt 20579 identifizierten Einzelprozessen auf acht Hauptgruppen in Krings (2001)
PROD: auf die Produktion des Zieltextes bezogene Prozesse
WRITE: materielle Schreibprozesse
MON: auf die Bewertung ( monitoring) des Zieltextes bezogene Prozesse
MACHINE: auf die Maschinenübersetzung bezogene Prozesse
REFBOOK: auf Hilfsmittel bezogene Prozesse
SOURCE: auf den Ausgangstext bezogene Prozesse
GLOBTASK: global aufgabenbezogene Prozesse
NONTASK: nicht unmmittelbar aufgabenbezogene Prozesse